Current validation practice undermines surgical AI development
Pith reviewed 2026-05-18 01:38 UTC · model grok-4.3
The pith
Existing validation practices for AI in surgical videos neglect temporal and hierarchical structures, producing misleading results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
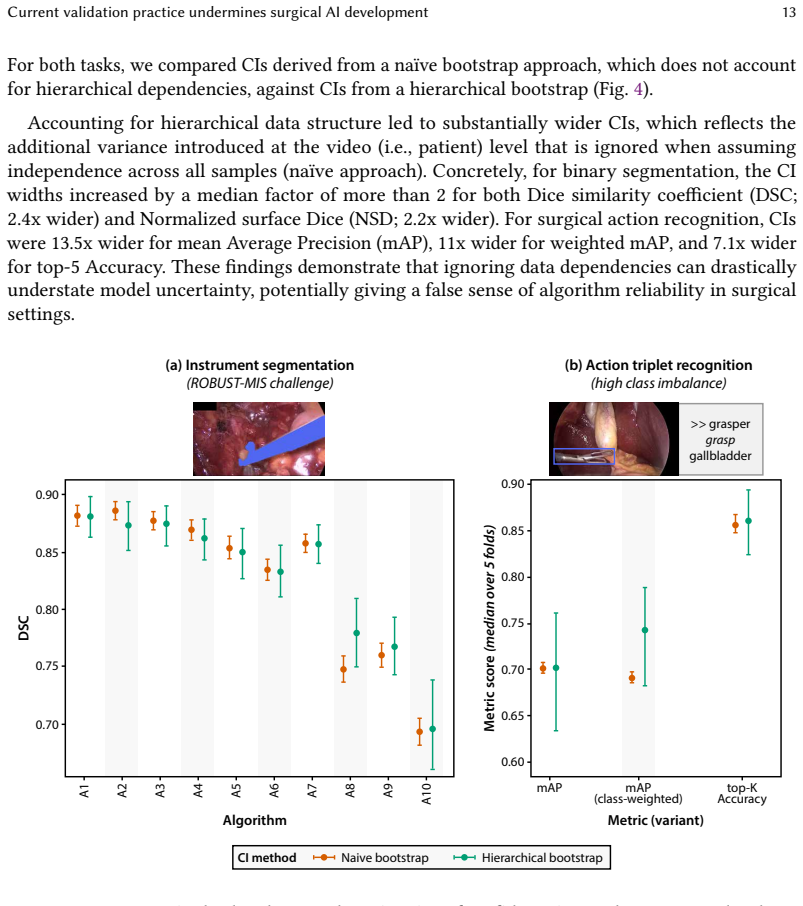
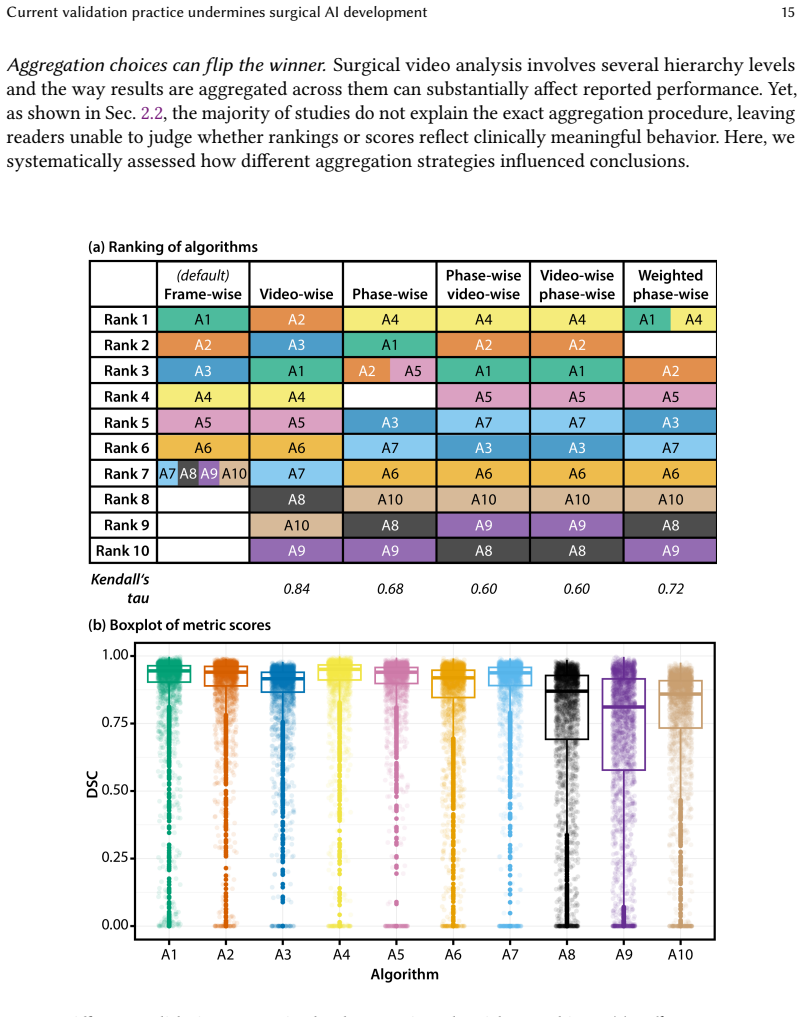
Existing validation practices often neglect the temporal and hierarchical structure of intraoperative videos, producing misleading, unstable, or clinically irrelevant results. Through a multi-stage Delphi process with 92 international experts, a comprehensive catalog of validation pitfalls was created, spanning data issues, metric selection, and aggregation and reporting. A systematic review and experiments on real datasets demonstrate that these pitfalls are widespread and can substantially affect algorithm performance assessments and rankings.
What carries the argument
The catalog of validation pitfalls derived from the Delphi consensus process, categorized into data, metric selection and configuration, and aggregation and reporting.
If this is right
- Adopting the cataloged best practices will improve the stability and clinical relevance of validation results for surgical AI algorithms.
- Accounting for temporal dynamics and hierarchical data structures will prevent understating uncertainty and obscuring failure modes.
- More rigorous validation will support better benchmarking, reporting, regulatory review, and clinical translation of surgical AI.
- Future studies should avoid clinically uninformative aggregation and account for frame dependencies.
Where Pith is reading between the lines
- If the pitfalls catalog is adopted widely, it could accelerate the development of more trustworthy surgical AI by standardizing evaluation methods.
- Similar validation issues may exist in other domains using video data, such as medical imaging or autonomous systems, suggesting broader applicability of the framework.
- Testing the best practices on new datasets could reveal additional pitfalls not captured in the initial consensus.
- Integrating these guidelines into AI development pipelines might reduce the gap between reported performance and real-world clinical utility.
Load-bearing premise
The multi-stage Delphi process with 92 international experts produced a comprehensive and unbiased catalog of all major validation pitfalls without significant selection or consensus bias.
What would settle it
Re-evaluating a set of published surgical AI papers using metrics that properly account for temporal stability and hierarchical structure, and finding that algorithm rankings and reported performance remain unchanged, would challenge the claim that current practices produce misleading results.
Figures




read the original abstract
Surgical data science (SDS) is rapidly advancing, yet clinical adoption of artificial intelligence (AI) in surgery remains limited, with inadequate validation emerging as an important contributing factor. In fact, existing validation practices often neglect the temporal and hierarchical structure of intraoperative videos, producing misleading, unstable, or clinically irrelevant results. In a pioneering, consensus-driven effort, we introduce a comprehensive catalog of validation pitfalls in AI-based surgical video analysis that was derived from a multi-stage Delphi process with 92 international experts. The collected pitfalls span three categories: (1) data (e.g., incomplete annotation, spurious correlations), (2) metric selection and configuration (e.g., neglect of temporal stability, mismatch with clinical needs), and (3) aggregation and reporting (e.g., clinically uninformative aggregation, failure to account for frame dependencies in hierarchical data structures). A systematic review of surgical AI papers reveals that these pitfalls are widespread in current practice, with the majority of studies failing to account for temporal dynamics or hierarchical data structure, or relying on clinically uninformative metrics. Experiments on real surgical video datasets provide empirical evidence that ignoring temporal and hierarchical data structures can substantially understate uncertainty, obscure critical failure modes, and even alter algorithm rankings. To address these shortcomings, we provide a catalogue of best practices compiled in a multi-stage Delphi process. Together, this work provides an evidence-based framework to inform more rigorous validation of surgical video analysis algorithms and to guide future efforts in benchmarking, reporting, regulatory review, and clinical translation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that current validation practices for AI in surgical video analysis frequently neglect the temporal and hierarchical structure of intraoperative videos, yielding misleading, unstable, or clinically irrelevant results. It supports this via a multi-stage Delphi process with 92 international experts that produced a catalog of pitfalls across data, metric selection/configuration, and aggregation/reporting; a systematic review demonstrating high prevalence of these pitfalls in published surgical AI papers; experiments on real datasets showing that standard practices can understate uncertainty, obscure failure modes, and change algorithm rankings; and a companion catalog of best practices.
Significance. If the central claims hold, the work could meaningfully advance validation standards in surgical data science by providing an evidence-based framework that informs benchmarking, reporting, regulatory review, and clinical translation. The Delphi consensus, systematic review of prevalence, and empirical demonstrations of altered uncertainty/rankings are concrete strengths that could help shift community practice.
major comments (2)
- [Experiments] Experiments section: the claim that standard validation produces 'misleading' or 'clinically irrelevant' results rests on showing different uncertainty estimates and algorithm rankings when temporal/hierarchical structure is ignored, but lacks an independent external anchor (e.g., correlation with actual surgical outcomes, complication rates, or blinded expert clinical ratings). Without this, it remains possible that the 'standard' results are stable and appropriate while the adjusted ones introduce new biases; this is load-bearing for the central claim that neglect produces misleading results.
- [Methods / Delphi process] Delphi process description (likely §3 or Methods): the manuscript should explicitly report expert selection criteria, response rates, exact survey items, and any measures taken to mitigate selection or consensus bias. The abstract and summary statements leave these details underspecified, which weakens confidence that the catalog is comprehensive and unbiased.
minor comments (2)
- [Abstract] Abstract: add one sentence summarizing the exact number of papers in the systematic review and the main inclusion criteria.
- [Throughout] Notation and terminology: ensure consistent use of 'temporal stability' vs. 'temporal dynamics' and 'hierarchical data structure' across sections to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which have helped us identify areas for clarification and improvement. We address each major comment below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the claim that standard validation produces 'misleading' or 'clinically irrelevant' results rests on showing different uncertainty estimates and algorithm rankings when temporal/hierarchical structure is ignored, but lacks an independent external anchor (e.g., correlation with actual surgical outcomes, complication rates, or blinded expert clinical ratings). Without this, it remains possible that the 'standard' results are stable and appropriate while the adjusted ones introduce new biases; this is load-bearing for the central claim that neglect produces misleading results.
Authors: We thank the referee for this important observation. Our experiments demonstrate that standard validation (ignoring temporal/hierarchical structure) produces substantially different uncertainty estimates, obscures failure modes visible under structure-aware methods, and alters algorithm rankings. These inconsistencies indicate that standard practices can yield unstable conclusions about model performance, which we view as evidence of potential misleadingness in the absence of a known clinical ground truth. We acknowledge that direct correlation with surgical outcomes or expert ratings would provide the strongest validation of clinical relevance; such data are not available in the public datasets used. We will revise the manuscript to explicitly discuss this limitation, adjust phrasing from 'clinically irrelevant' to 'potentially misleading due to instability and ranking changes,' and add a paragraph on the value of future studies incorporating clinical outcome anchors. revision: partial
-
Referee: [Methods / Delphi process] Delphi process description (likely §3 or Methods): the manuscript should explicitly report expert selection criteria, response rates, exact survey items, and any measures taken to mitigate selection or consensus bias. The abstract and summary statements leave these details underspecified, which weakens confidence that the catalog is comprehensive and unbiased.
Authors: We agree that transparent reporting of the Delphi methodology is essential. The full Methods section describes the multi-stage process with 92 experts, but we will expand it with a dedicated subsection detailing: expert selection criteria (minimum 5 years experience in surgical data science or AI, recruited via international societies and research networks), per-stage response rates, the exact survey items and question wording used in each round, and bias mitigation steps (anonymous voting, independent facilitation, and predefined consensus thresholds). We will also add the full survey instrument as supplementary material to allow readers to assess comprehensiveness and potential bias. revision: yes
Circularity Check
No circularity: claims grounded in external Delphi consensus and review
full rationale
The paper derives its catalog of pitfalls and best practices from a multi-stage Delphi process with 92 international experts and a systematic review of the literature, then supports prevalence claims with that review and empirical sensitivity experiments on external surgical video datasets. No mathematical derivations, equations, fitted parameters, or predictions are described that reduce by construction to the authors' own inputs or prior self-citations. The central argument that current practices produce misleading results rests on external expert input and observed differences in uncertainty estimates rather than any self-referential loop or load-bearing internal citation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A multi-stage Delphi process with international experts yields an unbiased and comprehensive catalog of validation pitfalls.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
existing validation practices often neglect the temporal and hierarchical structure of intraoperative videos, producing misleading, unstable, or clinically irrelevant results
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on real surgical video datasets provide empirical evidence that ignoring temporal and hierarchical data structures can substantially understate uncertainty
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tamer Abdulbaki Alshirbaji, Nour Aldeen Jalal, and Knut Möller. Surgical tool classification in laparoscopic videos using convolutional neural network.Current Directions in Biomedical Engineering, 4(1):407–410, 2018
work page 2018
-
[2]
Muhammad Ahmad, Muhammad Usama, Manuel Mazzara, and Salvatore Distefano. Wavemamba: Spatial-spectral wavelet mamba for hyperspectral image classification.IEEE Geoscience and Remote Sensing Letters, 2024
work page 2024
-
[3]
Deepak Alapatt, Jennifer Eckhoff, Zhiliang Lyu, Yutong Ban, Jean-Paul Mazellier, Sarah Choksi, Kunyi Yang, Quanzheng Li, Filippo Filicori, Xiang Li, et al. The sages critical view of safety challenge: A global benchmark for ai-assisted surgical quality assessment.arXiv preprint arXiv:2509.17100, 2025
-
[4]
Aggregating long-term context for learning laparoscopic and robot-assisted surgical workflows, 2021
Yutong Ban, Guy Rosman, Thomas Ward, Daniel Hashimoto, Taisei Kondo, Hidekazu Iwaki, Ozanan Meireles, and Daniela Rus. Aggregating long-term context for learning laparoscopic and robot-assisted surgical workflows, 2021
work page 2021
-
[5]
Bias in radiology artificial intelligence: causes, evaluation and mitigation, 2024
Imon Banerjee. Bias in radiology artificial intelligence: causes, evaluation and mitigation, 2024
work page 2024
-
[6]
Sophia Bano, Alessandro Casella, Francisco Vasconcelos, Abdul Qayyum, Abdesslam Benzinou, Moona Mazher, Fabrice Meriaudeau, Chiara Lena, Ilaria Anita Cintorrino, Gaia Romana De Paolis, et al. Placental vessel segmentation and registration in fetoscopy: literature review and miccai fetreg2021 challenge findings.Medical Image Analysis, 92: 103066, 2024
work page 2024
-
[7]
Omri Bar, Daniel Neimark, Maya Zohar, Gregory D Hager, Ross Girshick, Gerald M Fried, Tamir Wolf, and Dotan Asselmann. Impact of data on generalization of ai for surgical intelligence applications.Scientific reports, 10(1):22208, 2020
work page 2020
-
[8]
Maximilian Berlet, Thomas Vogel, Daniel Ostler, Tobias Czempiel, M Kähler, Stephan Brunner, Hubertus Feussner, Dirk Wilhelm, and Michael Kranzfelder. Surgical reporting for laparoscopic cholecystectomy based on phase annotation by a convolutional neural network (cnn) and the phenomenon of phase flickering: a proof of concept.International journal of compu...
work page 1991
-
[9]
Max Berniker, Kiran D Bhattacharyya, Kristen C Brown, and Anthony Jarc. A probabilistic approach to surgical tasks and skill metrics.IEEE Transactions on Biomedical Engineering, 69(7):2212–2219, 2021
work page 2021
-
[10]
Tim Boers, Joost van der Putten, Maarten Struyvenberg, Kiki Fockens, Jelmer Jukema, Erik Schoon, Fons van der Sommen, Jacques Bergman, and Peter de With. Improving temporal stability and accuracy for endoscopic video tissue classification using recurrent neural networks.Sensors, 20(15):4133, 2020
work page 2020
-
[11]
Markus Brand, Joel Troya, Adrian Krenzer, Costanza De Maria, Niklas Mehlhase, Sebastian Götze, Benjamin Walter, Alexander Meining, and Alexander Hann. Frame-by-frame analysis of a commercially available artificial intelligence polyp detection system in full-length colonoscopies.Digestion, 103(5):378–385, 2022
work page 2022
-
[12]
Delphi process: a methodology used for the elicitation of opinions of experts
Bernice B Brown. Delphi process: a methodology used for the elicitation of opinions of experts. Technical report, 1968
work page 1968
-
[13]
Finding spurious correlations with function-semantic contrast analysis, 2023
Kirill Bykov, Laura Kopf, and Marina M-C Höhne. Finding spurious correlations with function-semantic contrast analysis, 2023
work page 2023
-
[14]
Matthias Carstens, Shubha Vasisht, Zheyuan Zhang, Iulia Barbur, Annika Reinke, Lena Maier-Hein, Daniel A Hashimoto, and Fiona R Kolbinger. Artificial intelligence for surgical scene understanding: A systematic review and reporting quality meta-analysis.medRxiv, pages 2025–07, 2025
work page 2025
-
[15]
João Cartucho, Alistair Weld, Samyakh Tukra, Haozheng Xu, Hiroki Matsuzaki, Taiyo Ishikawa, Minjun Kwon, Yong Eun Jang, Kwang-Ju Kim, Gwang Lee, et al. Surgt challenge: Benchmark of soft-tissue trackers for robotic surgery.Medical image analysis, 91:102985, 2024
work page 2024
-
[16]
Causality matters in medical imaging.Nature Communications, 11(1): 3673, 2020
Daniel C Castro, Ian Walker, and Ben Glocker. Causality matters in medical imaging.Nature Communications, 11(1): 3673, 2020
work page 2020
-
[17]
Fernando Cervantes-Sanchez, Marianne Maktabi, Hannes Köhler, Robert Sucher, Nada Rayes, Juan Gabriel Avina- Cervantes, Ivan Cruz-Aceves, and Claire Chalopin. Automatic tissue segmentation of hyperspectral images in liver and head neck surgeries using machine learning.Artificial Intelligence Surgery, 1(1):22–37, 2021
work page 2021
-
[18]
Yanqi Cheng, Lihao Liu, Shujun Wang, Yueming Jin, Carola-Bibiane Schönlieb, and Angelica I Aviles-Rivero. Why deep surgical models fail?: Revisiting surgical action triplet recognition through the lens of robustness, 2023
work page 2023
-
[19]
Christopher P Childers and Melinda Maggard-Gibbons. Same data, opposite results?: A call to improve surgical database research.JAMA surgery, 156(3):219–220, 2021
work page 2021
-
[20]
Confidence intervals uncovered: Are we ready for real-world medical imaging ai?, 2024
Evangelia Christodoulou, Annika Reinke, Rola Houhou, Piotr Kalinowski, Selen Erkan, Carole H Sudre, Ninon Burgos, Sofiène Boutaj, Sophie Loizillon, Maëlys Solal, et al. Confidence intervals uncovered: Are we ready for real-world medical imaging ai?, 2024
work page 2024
-
[21]
False promises in medical imaging ai? assessing validity of outperformance claims, 2025
Evangelia Christodoulou, Annika Reinke, Pascaline Andrè, Patrick Godau, Piotr Kalinowski, Rola Houhou, Selen Erkan, Carole H Sudre, Ninon Burgos, Sofiène Boutaj, et al. False promises in medical imaging ai? assessing validity of outperformance claims, 2025. 52 Reinke et al
work page 2025
-
[22]
Gary S Collins, Paula Dhiman, Constanza L Andaur Navarro, Jie Ma, Lotty Hooft, Johannes B Reitsma, Patricia Logullo, Andrew L Beam, Lily Peng, Ben Van Calster, et al. Protocol for development of a reporting guideline (tripod-ai) and risk of bias tool (probast-ai) for diagnostic and prognostic prediction model studies based on artificial intelligence. BMJ ...
work page 2021
-
[23]
Opera: Attention-regularized transformers for surgical phase recognition, 2021
Tobias Czempiel, Magdalini Paschali, Daniel Ostler, Seong Tae Kim, Benjamin Busam, and Nassir Navab. Opera: Attention-regularized transformers for surgical phase recognition, 2021
work page 2021
-
[24]
PhD thesis, Technische Universität München, 2023
Tobias M Czempiel.Symphony of Time: Temporal Deep Learning for Surgical Activity Recognition. PhD thesis, Technische Universität München, 2023
work page 2023
-
[25]
Preetam Prabhu Srikar Dammu and Chirag Shah. Detecting spurious correlations via robust visual concepts in real and ai-generated image classification.arXiv preprint arXiv:2311.01655, 2023
-
[26]
Kubilay Can Demir, Hannah Schieber, Tobias Weise, Daniel Roth, Matthias May, Andreas Maier, and Seung Hee Yang. Deep learning in surgical workflow analysis: a review of phase and step recognition.IEEE Journal of Biomedical and Health Informatics, 27(11):5405–5417, 2023
work page 2023
-
[27]
Olga Dergachyova, David Bouget, Arnaud Huaulmé, Xavier Morandi, and Pierre Jannin. Automatic data-driven real-time segmentation and recognition of surgical workflow.International journal of computer assisted radiology and surgery, 11(6):1081–1089, 2016
work page 2016
-
[28]
Carts: Causality-driven robot tool segmentation from vision and kinematics data, 2022
Hao Ding, Jintan Zhang, Peter Kazanzides, Jie Ying Wu, and Mathias Unberath. Carts: Causality-driven robot tool segmentation from vision and kinematics data, 2022
work page 2022
-
[29]
Bradley Efron and Robert J Tibshirani.An introduction to the bootstrap. Chapman and Hall/CRC, 1994
work page 1994
-
[30]
Sandy Engelhardt, Raffaele De Simone, Peter M Full, Matthias Karck, and Ivo Wolf. Improving surgical training phantoms by hyperrealism: deep unpaired image-to-image translation from real surgeries, 2018
work page 2018
-
[31]
Isabel Funke, Sören Torge Mees, Jürgen Weitz, and Stefanie Speidel. Video-based surgical skill assessment using 3d convolutional neural networks.International journal of computer assisted radiology and surgery, 14(7):1217–1225, 2019
work page 2019
- [32]
-
[33]
Xiaojie Gao, Yueming Jin, Yonghao Long, Qi Dou, and Pheng-Ann Heng. Trans-svnet: Accurate phase recognition from surgical videos via hybrid embedding aggregation transformer, 2021
work page 2021
-
[34]
Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
work page 2020
-
[35]
Negin Ghamsarian, Yosuf El-Shabrawi, Sahar Nasirihaghighi, Doris Putzgruber-Adamitsch, Martin Zinkernagel, Se- bastian Wolf, Klaus Schoeffmann, and Raphael Sznitman. Cataract-1k: cataract surgery dataset for scene segmentation, phase recognition, and irregularity detection.arXiv preprint arXiv:2312.06295, 2023
-
[36]
Patrick Godau, Piotr Kalinowski, Evangelia Christodoulou, Annika Reinke, Minu Tizabi, Luciana Ferrer, Paul F. Jäger, and Lena Maier-Hein. Deployment of image analysis algorithms under prevalence shifts. pages 389–399, 2023
work page 2023
-
[37]
Act-net: Anchor- context action detection in surgery videos, 2023
Luoying Hao, Yan Hu, Wenjun Lin, Qun Wang, Heng Li, Huazhu Fu, Jinming Duan, and Jiang Liu. Act-net: Anchor- context action detection in surgery videos, 2023
work page 2023
-
[38]
Daniel A Hashimoto, Guy Rosman, Elan R Witkowski, Caitlin Stafford, Allison J Navarette-Welton, David W Rattner, Keith D Lillemoe, Daniela L Rus, and Ozanan R Meireles. Computer vision analysis of intraoperative video: automated recognition of operative steps in laparoscopic sleeve gastrectomy.Annals of surgery, 270(3):414–421, 2019
work page 2019
-
[39]
Daniel A Hashimoto, Sai Koushik Sambasastry, Vivek Singh, Sruthi Kurada, Maria Altieri, Takuto Yoshida, Amin Madani, and Matjaz Jogan. A foundation for evaluating the surgical artificial intelligence literature.European Journal of Surgical Oncology, 50(12):108014, 2024
work page 2024
-
[40]
An empirical study on activity recognition in long surgical videos, 2022
Zhuohong He, Ali Mottaghi, Aidean Sharghi, Muhammad Abdullah Jamal, and Omid Mohareri. An empirical study on activity recognition in long surgical videos, 2022
work page 2022
-
[41]
Jonas Hein, Nicola Cavalcanti, Daniel Suter, Lukas Zingg, Fabio Carrillo, Lilian Calvet, Mazda Farshad, Nassir Navab, Marc Pollefeys, and Philipp Fürnstahl. Next-generation surgical navigation: Marker-less multi-view 6dof pose estimation of surgical instruments.Medical Image Analysis, page 103613, 2025
work page 2025
-
[42]
Cholecseg8k: a semantic segmen- tation dataset for laparoscopic cholecystectomy based on cholec80
W-Y Hong, C-L Kao, Y-H Kuo, J-R Wang, W-L Chang, and C-S Shih. Cholecseg8k: a semantic segmentation dataset for laparoscopic cholecystectomy based on cholec80.arXiv preprint arXiv:2012.12453, 2020
-
[43]
Arnaud Huaulmé, Kanako Harada, Quang-Minh Nguyen, Bogyu Park, Seungbum Hong, Min-Kook Choi, Michael Peven, Yunshuang Li, Yonghao Long, Qi Dou, et al. Peg transfer workflow recognition challenge report: Do multimodal data improve recognition?Computer Methods and Programs in Biomedicine, 236:107561, 2023
work page 2023
-
[44]
Arnaud Huaulmé, Krystel Nyangoh Timoh, Victor Jan, Sonia Guerin, and Pierre Jannin. Global versus local kinematic skills assessment on robotic-assisted hysterectomies.IEEE Transactions on Medical Robotics and Bionics, 2024
work page 2024
-
[45]
Andrew J Hung, Paul J Oh, Jian Chen, Saum Ghodoussipour, Christianne Lane, Anthony Jarc, and Inderbir S Gill. Experts vs super-experts: differences in automated performance metrics and clinical outcomes for robot-assisted radical prostatectomy.BJU international, 123(5):861–868, 2019. Current validation practice undermines surgical AI development 53
work page 2019
-
[46]
N Jiang, M Wang, R Bi, G Wu, S Zhu, and Y Liu. Risk factors for bad splits during sagittal split ramus osteotomy: a retrospective study of 964 cases.British Journal of Oral and Maxillofacial Surgery, 59(6):678–682, 2021
work page 2021
-
[47]
Yueming Jin, Qi Dou, Hao Chen, Lequan Yu, Jing Qin, Chi-Wing Fu, and Pheng-Ann Heng. Sv-rcnet: workflow recognition from surgical videos using recurrent convolutional network.IEEE transactions on medical imaging, 37(5): 1114–1126, 2017
work page 2017
-
[48]
Yueming Jin, Yonghao Long, Cheng Chen, Zixu Zhao, Qi Dou, and Pheng-Ann Heng. Temporal memory relation network for workflow recognition from surgical video.IEEE Transactions on Medical Imaging, 40(7):1911–1923, 2021
work page 1911
-
[49]
Matjaž Jogan, Sruthi Kurada, Shubha Vasisht, Vivek Singh, and Daniel A Hashimoto. Quality over quantity? the role of data quality and uncertainty for ai in surgery.Global Surgical Education-Journal of the Association for Surgical Education, 3(1):79, 2024
work page 2024
-
[50]
Leo Joskowicz, D Cohen, N Caplan, and Jacob Sosna. Inter-observer variability of manual contour delineation of structures in ct.European radiology, 29(3):1391–1399, 2019
work page 2019
-
[51]
Denise Junger, Sina Mailin Frommer, and Oliver Burgert. State-of-the-art of situation recognition systems for intraoperative procedures.Medical & Biological Engineering & Computing, 60(4):921–939, 2022
work page 2022
-
[52]
Denuka Kankanamge, Chandana Wijeweera, Zehurn Ong, T Preda, Terry Carney, Mike Wilson, and Veronica Preda. Artificial intelligence based assessment of minimally invasive surgical skills using standardised objective metrics–a narrative review.The American Journal of Surgery, 241:116074, 2025
work page 2025
-
[53]
Hasan Kassem, Deepak Alapatt, Pietro Mascagni, Alexandros Karargyris, and Nicolas Padoy. Federated cycling (fedcy): Semi-supervised federated learning of surgical phases.IEEE transactions on medical imaging, 42(7):1920–1931, 2022
work page 1920
-
[54]
A new measure of rank correlation.Biometrika, 30(1-2):81–93, 1938
Maurice G Kendall. A new measure of rank correlation.Biometrika, 30(1-2):81–93, 1938
work page 1938
-
[55]
Danyal Z Khan, Alexandra Valetopoulou, Adrito Das, John G Hanrahan, Simon C Williams, Sophia Bano, Anouk Borg, Neil L Dorward, Santiago Barbarisi, Lucy Culshaw, et al. Artificial intelligence assisted operative anatomy recognition in endoscopic pituitary surgery.NPJ Digital Medicine, 7(1):314, 2024
work page 2024
-
[56]
Physical imaging parameter variation drives domain shift.Scientific Reports, 12(1):21302, 2022
Oz Kilim, Alex Olar, Tamás Joó, Tamás Palicz, Péter Pollner, and István Csabai. Physical imaging parameter variation drives domain shift.Scientific Reports, 12(1):21302, 2022
work page 2022
-
[57]
Pelphix: Surgical phase recognition from x-ray images in percutaneous pelvic fixation, 2023
Benjamin D Killeen, Han Zhang, Jan Mangulabnan, Mehran Armand, Russell H Taylor, Greg Osgood, and Mathias Unberath. Pelphix: Surgical phase recognition from x-ray images in percutaneous pelvic fixation, 2023
work page 2023
-
[58]
Kadir Kirtac, Nizamettin Aydin, Joël L Lavanchy, Guido Beldi, Marco Smit, Michael S Woods, and Florian Aspart. Surgical phase recognition: From public datasets to real-world data.Applied Sciences, 12(17):8746, 2022
work page 2022
-
[59]
Dani Kiyasseh, Runzhuo Ma, Taseen F Haque, Brian J Miles, Christian Wagner, Daniel A Donoho, Animashree Anandkumar, and Andrew J Hung. A vision transformer for decoding surgeon activity from surgical videos.Nature biomedical engineering, 7(6):780–796, 2023
work page 2023
-
[60]
Martin Knoche, Stefan Hörmann, and Gerhard Rigoll. Susceptibility to image resolution in face recognition and trainings strategies.arXiv preprint arXiv:2107.03769, 2021
-
[61]
Burak Koçak, Fadime Köse, Ali Keleş, Abdurrezzak Şendur, İsmail Meşe, and Mehmet Karagülle. Adherence to the checklist for artificial intelligence in medical imaging (claim): an umbrella review with a comprehensive two-level analysis.Diagn Interv Radiol, 2025
work page 2025
-
[62]
Lisa M Koch, Christian F Baumgartner, and Philipp Berens. Distribution shift detection for the postmarket surveillance of medical ai algorithms: a retrospective simulation study.NPJ Digital Medicine, 7(1):120, 2024
work page 2024
-
[63]
Florian Kofler, Ivan Ezhov, Fabian Isensee, Fabian Balsiger, Christoph Berger, Maximilian Koerner, Beatrice Demiray, Julia Rackerseder, Johannes Paetzold, Hongwei Li, et al. Are we using appropriate segmentation metrics? identifying correlates of human expert perception for cnn training beyond rolling the dice coefficient.Machine Learning for Biomedical I...
work page 2023
-
[64]
Fiona R Kolbinger, Franziska M Rinner, Alexander C Jenke, Matthias Carstens, Stefanie Krell, Stefan Leger, Marius Distler, Jürgen Weitz, Stefanie Speidel, and Sebastian Bodenstedt. Anatomy segmentation in laparoscopic surgery: comparison of machine learning and human expertise–an experimental study.International Journal of Surgery, 109 (10):2962–2974, 2023
work page 2023
-
[65]
Fiona R Kolbinger, Sebastian Bodenstedt, Matthias Carstens, Stefan Leger, Stefanie Krell, Franziska M Rinner, Thomas P Nielen, Johanna Kirchberg, Johannes Fritzmann, Jürgen Weitz, et al. Artificial intelligence for context-aware surgical guidance in complex robot-assisted oncological procedures: An exploratory feasibility study.European Journal of Surgica...
work page 2024
-
[66]
Strategies to improve real-world applicability of laparoscopic anatomy segmentation models, 2024
Fiona R Kolbinger, Jiangpeng He, Jinge Ma, and Fengqing Zhu. Strategies to improve real-world applicability of laparoscopic anatomy segmentation models, 2024
work page 2024
-
[67]
Fiona R Kolbinger, Max Kirchner, Kevin Pfeiffer, Sebastian Bodenstedt, Alexander C Jenke, Julia Barthel, Matthias Carstens, Karolin Dehlke, Sophia Dietz, Sotirios Emmanouilidis, et al. Appendix300: A multi-institutional laparoscopic appendectomy video dataset for computational modeling tasks.medRxiv, pages 2025–09, 2025. 54 Reinke et al
work page 2025
-
[68]
Xiaowen Kong, Yueming Jin, Qi Dou, Ziyi Wang, Zerui Wang, Bo Lu, Erbao Dong, Yun-Hui Liu, and Dong Sun. Accurate instance segmentation of surgical instruments in robotic surgery: model refinement and cross-dataset evaluation.International journal of computer assisted radiology and surgery, 16(9):1607–1614, 2021
work page 2021
-
[69]
Robust consistent video depth estimation, 2021
Johannes Kopf, Xuejian Rong, and Jia-Bin Huang. Robust consistent video depth estimation, 2021
work page 2021
-
[70]
Georgii Kostiuchik, Lalith Sharan, Benedikt Mayer, Ivo Wolf, Bernhard Preim, and Sandy Engelhardt. Surgical phase and instrument recognition: how to identify appropriate dataset splits.International Journal of Computer Assisted Radiology and Surgery, 19(4):699–711, 2024
work page 2024
-
[71]
Joël L Lavanchy, Sanat Ramesh, Diego Dall’Alba, Cristians Gonzalez, Paolo Fiorini, Beat P Müller-Stich, Philipp C Nett, Jacques Marescaux, Didier Mutter, and Nicolas Padoy. Challenges in multi-centric generalization: phase and step recognition in roux-en-y gastric bypass surgery.International journal of computer assisted radiology and surgery, 19(11):2249...
work page 2024
-
[72]
Artificial intelligence in surgery: evolution, trends, and future directions
Huiyang Li, Zhuoqi Han, Haixiao Wu, Elmar R Musaev, Yile Lin, Shu Li, Alexander D Makatsariya, Vladimir P Chekhonin, Wenjuan Ma, and Chao Zhang. Artificial intelligence in surgery: evolution, trends, and future directions. International Journal of Surgery, 111(2):2101–2111, 2025
work page 2025
-
[73]
Skit: a fast key information video transformer for online surgical phase recognition, 2023
Yang Liu, Jiayu Huo, Jingjing Peng, Rachel Sparks, Prokar Dasgupta, Alejandro Granados, and Sebastien Ourselin. Skit: a fast key information video transformer for online surgical phase recognition, 2023
work page 2023
-
[74]
Tyler J Loftus, Maria S Altieri, Jeremy A Balch, Kenneth L Abbott, Jeff Choi, Jayson S Marwaha, Daniel A Hashimoto, Gabriel A Brat, Yannis Raftopoulos, Heather L Evans, et al. Artificial intelligence–enabled decision support in surgery: state-of-the-art and future directions.Annals of Surgery, 278(1):51–58, 2023
work page 2023
-
[75]
Andreea Roxana Luca, Tudor Florin Ursuleanu, Liliana Gheorghe, Roxana Grigorovici, Stefan Iancu, Maria Hlusneac, and Alexandru Grigorovici. Impact of quality, type and volume of data used by deep learning models in the analysis of medical images.Informatics in Medicine Unlocked, 29:100911, 2022
work page 2022
-
[76]
Jonathon Luiten, Aljosa Osep, Patrick Dendorfer, Philip Torr, Andreas Geiger, Laura Leal-Taixé, and Bastian Leibe. Hota: A higher order metric for evaluating multi-object tracking.International journal of computer vision, 129(2): 548–578, 2021
work page 2021
-
[77]
Amin Madani, Babak Namazi, Maria S Altieri, Daniel A Hashimoto, Angela Maria Rivera, Philip H Pucher, Allison Navarrete-Welton, Ganesh Sankaranarayanan, L Michael Brunt, Allan Okrainec, et al. Artificial intelligence for intra- operative guidance: using semantic segmentation to identify surgical anatomy during laparoscopic cholecystectomy. Annals of surge...
work page 2022
-
[78]
Usman Mahmood, Robik Shrestha, David DB Bates, Lorenzo Mannelli, Giuseppe Corrias, Yusuf Emre Erdi, and Christopher Kanan. Detecting spurious correlations with sanity tests for artificial intelligence guided radiology systems.Frontiers in digital health, 3:671015, 2021
work page 2021
-
[79]
Lena Maier-Hein, Swaroop S Vedula, Stefanie Speidel, Nassir Navab, Ron Kikinis, Adrian Park, Matthias Eisen- mann, Hubertus Feussner, Germain Forestier, Stamatia Giannarou, et al. Surgical data science for next-generation interventions.Nature Biomedical Engineering, 1(9):691–696, 2017
work page 2017
-
[80]
Lena Maier-Hein, Martin Wagner, Tobias Ross, Annika Reinke, Sebastian Bodenstedt, Peter M Full, Hellena Hempe, Diana Mindroc-Filimon, Patrick Scholz, Thuy Nuong Tran, et al. Heidelberg colorectal data set for surgical data science in the sensor operating room.Scientific data, 8(1):101, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.