Revisiting Entropy in Reinforcement Learning for Large Reasoning Models
Pith reviewed 2026-05-17 23:28 UTC · model grok-4.3
The pith
Tokens with positive advantages drive entropy collapse during RLVR training of large reasoning models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
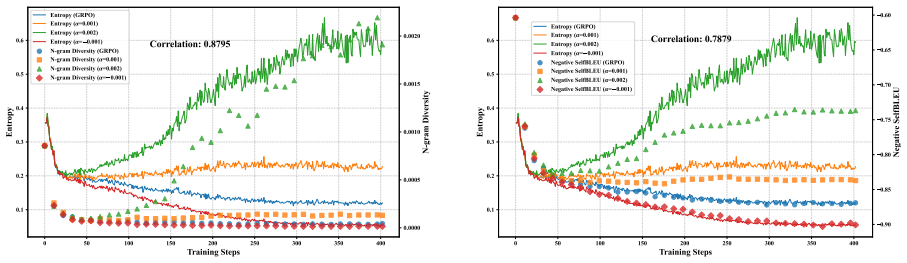
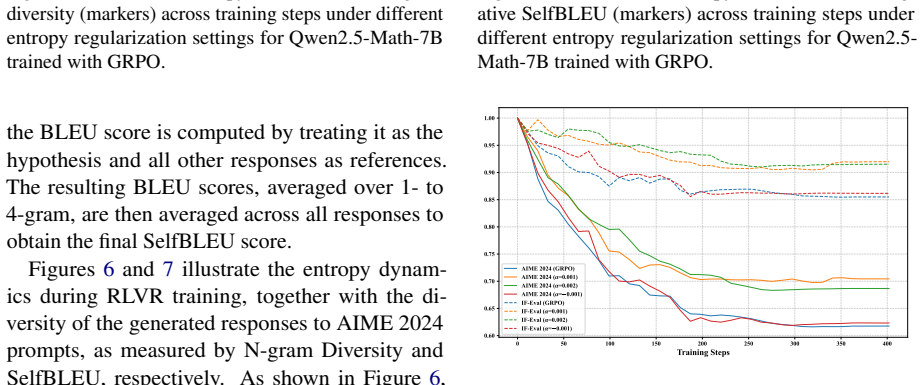
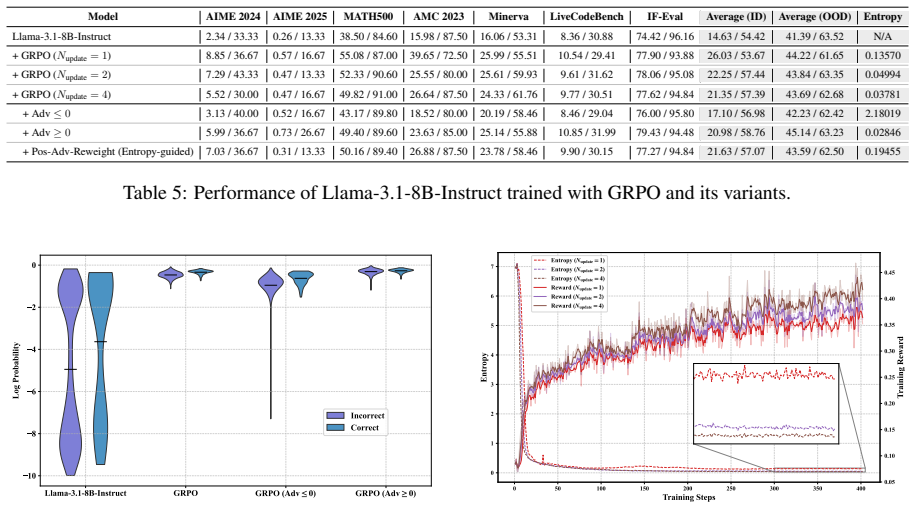
Tokens with positive advantages are the primary drivers of entropy collapse. By reweighting the loss contributions of these tokens during RLVR training, model entropy can be regulated to avoid premature convergence to local minima, with the approach maintaining overall optimization stability and final performance.
What carries the argument
Positive-Advantage Reweighting, a loss adjustment that scales the contribution of tokens with positive advantages to control entropy decay.
If this is right
- Adjusting clipping thresholds can slow entropy collapse.
- Limiting off-policy updates helps retain higher entropy.
- More diverse training data sustains response variety.
- Reweighting positive-advantage tokens prevents collapse while keeping final performance competitive.
Where Pith is reading between the lines
- The same reweighting idea might extend to other RL objectives that do not rely on verifiable rewards.
- Sustained entropy could improve model calibration on tasks requiring uncertainty estimates.
- Combining this method with data-curation strategies might further increase reasoning diversity.
Load-bearing premise
Reweighting loss contributions for positive-advantage tokens preserves overall optimization stability and final performance without introducing new biases or training instabilities.
What would settle it
An experiment showing that Positive-Advantage Reweighting still produces entropy collapse or lowers benchmark scores compared with standard RLVR would disprove the central claim.
Figures















read the original abstract
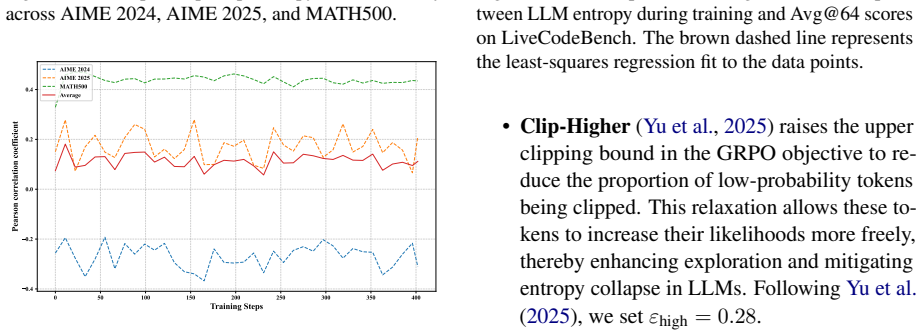
Reinforcement learning with verifiable rewards (RLVR) has emerged as a prominent paradigm for enhancing the reasoning capabilities of large language models (LLMs). However, the entropy of LLMs usually collapses during RLVR training, leading to premature convergence to suboptimal local minima and hindering further performance improvement. Although various approaches have been proposed to mitigate entropy collapse, a comprehensive study of entropy in RLVR remains lacking. To bridge this gap, we conduct extensive experiments to investigate the entropy dynamics of LLMs trained with RLVR and analyze how model entropy correlates with response diversity, calibration, and performance across various benchmarks. Our results identify three key factors that influence entropy: the clipping thresholds in the optimization objective, the number of off-policy updates, and the diversity of the training data. Furthermore, through both theoretical analysis and empirical validation, we demonstrate that tokens with positive advantages are the primary drivers of entropy collapse. Motivated by this insight, we propose Positive-Advantage Reweighting, a simple yet effective approach that regulates model entropy by adjusting the loss weights assigned to tokens with positive advantages during RLVR training, while maintaining competitive performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines entropy collapse during reinforcement learning with verifiable rewards (RLVR) for large language models. It reports experiments correlating entropy with response diversity, calibration, and benchmark performance, identifies three influencing factors (clipping thresholds, off-policy update count, and training data diversity), and claims via theoretical decomposition and empirical validation that tokens with positive advantages are the primary drivers of entropy collapse. Motivated by this, the authors propose Positive-Advantage Reweighting to adjust loss weights on positive-advantage tokens and thereby regulate entropy while preserving competitive performance.
Significance. If the central claim holds after proper isolation of effects, the work supplies a useful mechanistic account of entropy dynamics in RLVR and a lightweight practical intervention. The combination of theoretical analysis with extensive experiments across benchmarks is a strength; the reweighting method is simple enough to be adopted if shown to avoid new instabilities.
major comments (2)
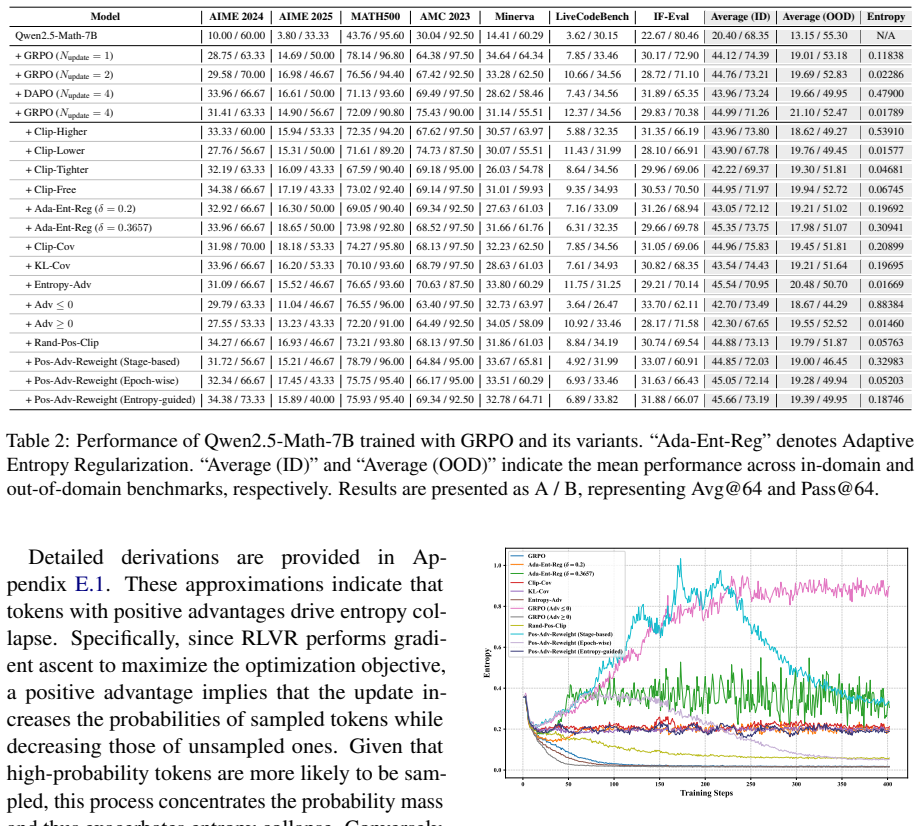
- [Empirical validation] Empirical sections: aggregate entropy curves are shown while clipping thresholds and off-policy steps are varied together. The claim that positive-advantage tokens dominate requires a ceteris-paribus ablation that holds clipping and update count fixed while zeroing or sign-flipping advantages on the positive subset; without it the primary-driver designation remains vulnerable to the three confounding factors the paper itself lists.
- [Theoretical analysis] Theoretical analysis: the decomposition of the policy-gradient entropy term by sign(advantage) is presented, yet no quantitative comparison (e.g., relative magnitude bounds or per-token contribution ratios) demonstrates that the positive-advantage component exceeds the negative-advantage and clipping/off-policy contributions. This step is load-bearing for the 'primary drivers' assertion.
minor comments (2)
- [Abstract] Abstract: the phrase 'extensive experiments' would be clearer if the specific benchmarks, number of runs, and statistical reporting (e.g., standard errors) were mentioned.
- [Method] Notation: the definition of advantage and the exact reweighting formula should be stated once in a single equation block rather than scattered across text and pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, providing clarifications on our empirical and theoretical support for the role of positive-advantage tokens while committing to targeted revisions that strengthen the isolation of effects and quantitative evidence.
read point-by-point responses
-
Referee: [Empirical validation] Empirical sections: aggregate entropy curves are shown while clipping thresholds and off-policy steps are varied together. The claim that positive-advantage tokens dominate requires a ceteris-paribus ablation that holds clipping and update count fixed while zeroing or sign-flipping advantages on the positive subset; without it the primary-driver designation remains vulnerable to the three confounding factors the paper itself lists.
Authors: We agree that simultaneous variation of factors in some aggregate plots leaves room for stronger isolation. Within individual training runs we already condition entropy statistics on advantage sign while holding other hyperparameters constant for that run, which provides partial control. To directly respond to the request, we will add a dedicated ablation section in which clipping thresholds and off-policy update counts are fixed at reference values while we zero or sign-flip the advantages of the positive-advantage token subset only. The resulting entropy trajectories and performance metrics will be reported to confirm the dominant contribution of positive-advantage tokens. These new results will appear in the revised manuscript. revision: yes
-
Referee: [Theoretical analysis] Theoretical analysis: the decomposition of the policy-gradient entropy term by sign(advantage) is presented, yet no quantitative comparison (e.g., relative magnitude bounds or per-token contribution ratios) demonstrates that the positive-advantage component exceeds the negative-advantage and clipping/off-policy contributions. This step is load-bearing for the 'primary drivers' assertion.
Authors: The decomposition isolates the entropy term according to sign(advantage) and shows that positive-advantage tokens produce updates that systematically reduce entropy. We acknowledge that explicit numerical comparisons were not included. In the revision we will compute and tabulate the relative magnitudes of the positive- versus negative-advantage components at multiple training checkpoints, together with per-token contribution ratios and direct comparisons against the magnitude of clipping and off-policy effects. These quantitative results will be added to the theoretical section to substantiate the primary-driver claim. revision: yes
Circularity Check
No significant circularity; theoretical decomposition and empirical factors are independently validated
full rationale
The paper's central claim—that positive-advantage tokens drive entropy collapse—is supported by a combination of theoretical analysis of the policy-gradient entropy term and separate empirical experiments that vary clipping thresholds, off-policy update counts, and data diversity. No equation or derivation reduces the result to a fitted parameter or self-referential definition by construction. The three confounding factors are explicitly identified and controlled in the experimental design rather than assumed away, and the Positive-Advantage Reweighting method is presented as a motivated intervention rather than a tautological restatement of the observations. The derivation chain remains self-contained against external benchmarks and does not rely on load-bearing self-citations or ansatz smuggling.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
tokens with positive advantages are the primary drivers of entropy collapse
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Rebellious Student: Reversing Teacher Signals for Reasoning Exploration with Self-Distilled RLVR
RLRT augments GRPO by reinforcing tokens on correct student rollouts that the teacher would not have predicted, outperforming standard self-distillation and exploration baselines on Qwen3 models.
-
Flexible Entropy Control in RLVR with a Gradient-Preserving Perspective
Dynamic clipping strategies based on importance sampling regions enable precise entropy management in RLVR, mitigating collapse and improving benchmark performance.
Reference graph
Works this paper leans on
-
[1]
Reasoning with exploration: An entropy per- spective.CoRR, abs/2506.14758. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. 2025. The entropy mechanism of rein- forcement learning for reasoning language...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning.CoRR, abs/2501.12948. Jia Deng, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, and Ji-Rong Wen. 2025. Decomposing the entropy- performance exchange: The missing keys to un- locking effective reinforcement learning.CoRR, abs/2508.02260. Jujie He, Jiacai Liu, Chris Yuhao Liu, Rui ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Ce-gppo: Coordinating entropy via gradient- preserving clipping policy optimization in reinforce- ment learning.Preprint, arXiv:2509.20712. Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Fengxiang Tang, Flood Sun...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Judgebench: A benchmark for evaluating LLM-as-a-judge.arXiv preprint arXiv:2407.11969, 2024a
Reasoning or memorization? unreliable results of reinforcement learning due to data contamination. CoRR, abs/2507.10532. An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jian- hong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. 2024. Qwen2.5-math tech- ni...
-
[5]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO: an open-source LLM reinforcement learning system at scale.CoRR, abs/2503.14476. Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, Yifan Zhou, Yang Chen, Chen Zhang, Yutao Fan, Zihu Wang, Songtao Huang, Yue Liao, Hongru Wang, Mengyue Yang, and 6 oth- ers. 2025. The landscap...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
with the AdamW optimizer, employing a 1We initially intended to train Llama-3.1-8B with GRPO, as it is a pretrained model that has not undergone instruction tuning, similar to Qwen2.5-Math-7B. However, during prelim- inary experiments, we observed that Llama-3.1-8B frequently generated endlessly repetitive responses during training, which substantially sl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.