SynthAgent: Adapting Web Agents with Synthetic Supervision
Pith reviewed 2026-05-17 23:21 UTC · model grok-4.3
The pith
SynthAgent adapts web agents to new sites by refining synthetic tasks and trajectories to cut hallucinations and noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
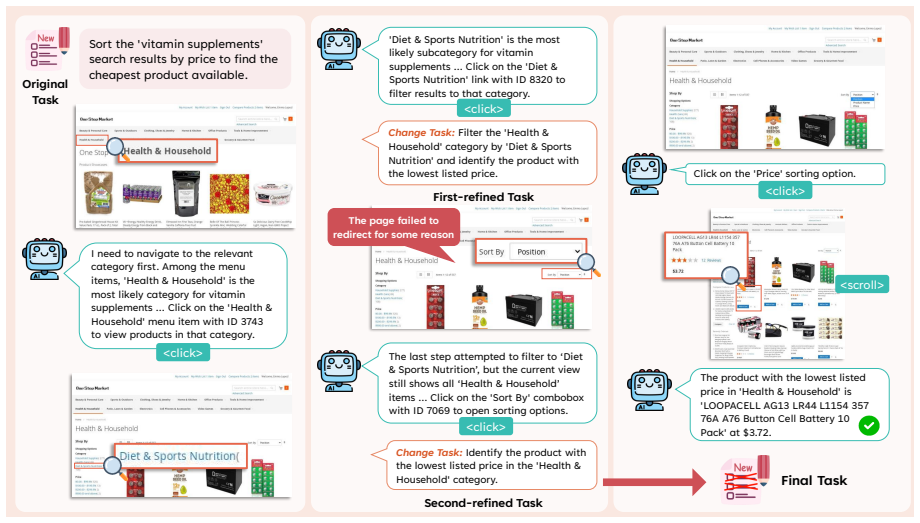
By first synthesizing diverse tasks through categorized exploration of web elements, then refining tasks only on detected conflicts during collection and refining trajectories afterward with global context, SynthAgent produces supervision data that allows open-source web agents to adapt successfully to previously unseen websites.
What carries the argument
Dual refinement: conflict-triggered task refinement during trajectory collection plus global-context trajectory refinement after collection, which together reduce hallucinations and misalignments while keeping task variety.
If this is right
- Fine-tuned agents achieve higher success rates on target websites than agents trained on existing synthetic methods.
- Task refinement during collection preserves consistency while removing hallucinations that would otherwise make tasks impossible to execute.
- Trajectory refinement with global context reduces redundant or misaligned actions that degrade learning.
- The entire pipeline runs without any human demonstrations or environment-specific real data.
Where Pith is reading between the lines
- The same refinement logic could be tested on non-web agent domains such as mobile interfaces or API agents where synthetic trajectories are also noisy.
- If the method scales, organizations could adapt agents to internal tools or client sites with far less manual data labeling.
- Future work might measure how much each refinement step contributes separately by ablating one at a time on the same base tasks.
Load-bearing premise
The refinements reliably remove unexecutable tasks and noisy actions without discarding the diversity needed for genuine generalization to new websites.
What would settle it
Train an agent on SynthAgent data and an identical agent on unrefined synthetic data, then test both on a fresh website; if the two agents achieve statistically indistinguishable success rates, the value of the dual refinement steps is falsified.
Figures




read the original abstract
Web agents struggle to adapt to new websites due to the scarcity of environment specific tasks and demonstrations. Recent works have explored synthetic data generation to address this challenge, however, they suffer from data quality issues where synthesized tasks contain hallucinations that cannot be executed, and collected trajectories are noisy with redundant or misaligned actions. In this paper, we propose SynthAgent, a fully synthetic supervision framework that aims at improving synthetic data quality via dual refinement of both tasks and trajectories. Our approach begins by synthesizing diverse tasks through categorized exploration of web elements, ensuring efficient coverage of the target environment. During trajectory collection, tasks are refined only when conflicts with observations are detected, which mitigates hallucinations while preserving task consistency. After collection, we conduct trajectory refinement with global context to mitigate potential noise or misalignments. Finally, we fine-tune open-source web agents on the refined synthetic data to adapt them to the target environment. Experimental results demonstrate that SynthAgent outperforms existing synthetic data methods, validating the importance of high-quality synthetic supervision. The code is publicly available at https://github.com/aiming-lab/SynthAgent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SynthAgent, a fully synthetic supervision framework for adapting web agents to new websites. It synthesizes diverse tasks via categorized exploration of web elements, refines tasks only upon detected conflicts to mitigate hallucinations while preserving consistency, performs global-context trajectory refinement to reduce noise and misalignments, and fine-tunes open-source agents on the resulting data. The central claim is that this dual-refinement pipeline yields higher-quality supervision than prior synthetic methods, as evidenced by superior agent performance on target environments.
Significance. If the refinements can be shown to measurably improve task executability and trajectory alignment beyond what data volume or base-model choice alone would achieve, the work would offer a practical, scalable route to environment-specific adaptation for web agents without human annotation. Public code release aids reproducibility and allows direct verification of the pipeline.
major comments (2)
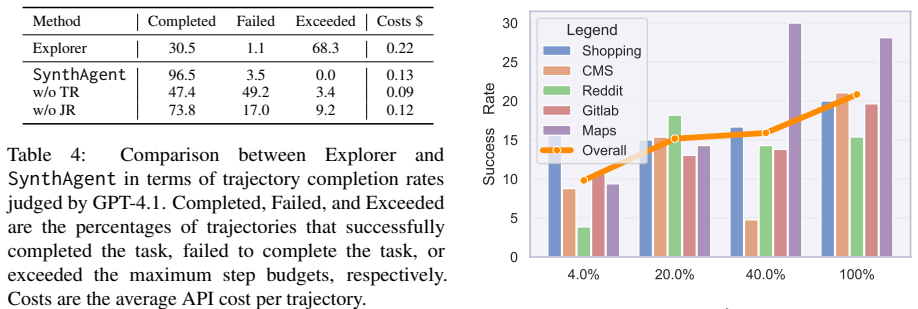
- [Abstract and Experiments section] The abstract and introduction assert outperformance over existing synthetic data methods, yet no concrete metrics, baseline names, dataset sizes, or statistical significance tests are reported. The Experiments section must supply these details together with controls that isolate the contribution of dual refinement from confounding factors such as data volume or evaluation-website overlap.
- [Sections 3.2–3.3 (Task and Trajectory Refinement) and Experiments] The central claim that task refinement (only on conflicts) plus global-context trajectory refinement produces higher-quality supervision rests on the assumption that these steps reduce unexecutable tasks and misaligned actions. No independent quantification—such as pre/post oracle success rates on the synthetic tasks themselves or counts of hallucinated elements removed—is provided; only end-to-end agent success rates after fine-tuning are shown. This leaves the load-bearing quality-improvement argument unsupported.
minor comments (1)
- [Section 3.1] Notation for the categorized exploration process and the conflict-detection condition could be made more precise to facilitate re-implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the changes we will make to improve clarity and evidence in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments section] The abstract and introduction assert outperformance over existing synthetic data methods, yet no concrete metrics, baseline names, dataset sizes, or statistical significance tests are reported. The Experiments section must supply these details together with controls that isolate the contribution of dual refinement from confounding factors such as data volume or evaluation-website overlap.
Authors: We agree that the Experiments section would benefit from more explicit reporting. In the revision we will add a table listing all baseline methods with their exact dataset sizes, report mean success rates with standard deviations, include statistical significance results (e.g., paired t-tests or Wilcoxon tests), and present two new controls: (1) an ablation varying synthetic data volume while keeping the dual-refinement pipeline fixed, and (2) explicit confirmation that none of the evaluation websites appear in the training data. revision: yes
-
Referee: [Sections 3.2–3.3 (Task and Trajectory Refinement) and Experiments] The central claim that task refinement (only on conflicts) plus global-context trajectory refinement produces higher-quality supervision rests on the assumption that these steps reduce unexecutable tasks and misaligned actions. No independent quantification—such as pre/post oracle success rates on the synthetic tasks themselves or counts of hallucinated elements removed—is provided; only end-to-end agent success rates after fine-tuning are shown. This leaves the load-bearing quality-improvement argument unsupported.
Authors: The referee is correct that direct, independent measures of refinement quality are currently absent. We will add a dedicated analysis subsection that reports: the fraction of tasks triggering conflict-based refinement, the number of hallucinated elements removed (via oracle inspection on a held-out sample), and pre/post-refinement executability rates measured by an oracle policy. These results will be presented before the end-to-end fine-tuning experiments to directly support the quality claim. revision: yes
Circularity Check
No circularity: empirical pipeline with external validation
full rationale
The manuscript describes an empirical pipeline for synthetic task generation, conflict-triggered task refinement, global-context trajectory refinement, and subsequent fine-tuning of web agents. No equations, derivations, fitted parameters, or first-principles results are presented that reduce to the inputs by construction. Claims rest on end-to-end experimental comparisons against prior synthetic methods on held-out websites, which constitute independent external benchmarks rather than self-referential reductions. Self-citations, if present, are not load-bearing for any central premise.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SynthAgent, a fully synthetic supervision framework that aims at improving synthetic data quality via dual refinement of both tasks and trajectories... categorized exploration... task refinement triggered by explicit conflict detection... trajectory refinement with global context
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experimental results demonstrate that SynthAgent outperforms existing synthetic data methods
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mind2Web: Towards a Generalist Agent for the Web
Mind2web: Towards a generalist agent for the web.Preprint, arXiv:2306.06070. Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Gra- ham Neubig. 2023. Pal: Program-aided language models.Preprint, arXiv:2211.10435. Yifei Gao, Junhong Ye, Jiaqi Wang, and Jitao Sang
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu
Websynthesis: World-model-guided mcts for efficient webui-trajectory synthesis.Preprint, arXiv:2507.04370. Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. 2024. Scaling synthetic data cre- ation with 1,000,000,000 personas.arXiv preprint arXiv:2406.20094. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zh...
-
[3]
WebSailor: Navigating Super-human Reasoning for Web Agent
Websailor: Navigating super-human reasoning for web agent.arXiv preprint arXiv:2507.02592. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harri- son Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
InThe Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Bang Liu, Xinfeng Li, Jiayi Zhang, Jinlin Wang, Tanjin He, Sirui Hong, Hongzhang Liu, Shaokun Zhang, Kaitao Song, Kunlun Zhu, and 1 others
-
[5]
Advances and challenges in foundation agents: From brain-inspired intelligence to evolution- ary, collaborative, and safe systems.arXiv preprint arXiv:2504.01990. Xing Han Lu, Zden ˇek Kasner, and Siva Reddy. 2024. WebLINX: Real-world website navigation with multi- turn dialogue. InForty-first International Conference on Machine Learning. Zhengxi Lu, Yuxi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Os-genesis: Automating gui agent trajectory construction via reverse task synthesis.Preprint, arXiv:2412.19723. Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https:// github.com/tatsu-lab/stanford_alpaca. Qwen Team...
-
[7]
WizardLM: Empowering large pre-trained language models to follow complex instructions
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094. Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. 2023. Wizardlm: Empowering large lan- guage models to follow complex instructions.arXiv preprint a...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Fully explore the current page and its content to understand its functionality and layout
-
[9]
Categorize ALL provided {element_num} elements into different categories (list[dict]) based on their natural purpose
-
[10]
Add a {const_uninteractive_category} category (list[int]) for non-interactive elements that cannot be CLICK, TYPE, or HOVER
-
[11]
action": choose from [CLICK, TYPE, HOVER],
For each category (except {const_uninteractive_category}), decide: { "action": choose from [CLICK, TYPE, HOVER], "element_id": id_of_element (int), "value": if TYPE, provide text to type; else ”, "low-level_instruction": concise description of the action } Example low-level instructions: - "Click on the ’Add to Cart’ button next to the product to add it t...
-
[12]
Provide an appropriate and meaningful value for "value" if the action is TYPE. Examples: - For a search box, generate a realistic search query. - For a textbox, generate plausible text according to context. **Output Requirements** Return ONLY a JSON dictionary (no commentary) with the following format: { "Analysis": "your analysis of the current page stat...
-
[13]
Click on the ’Add to Cart’ button next to the product to add it to your shopping cart
Sub-Instruction: Create a natural language instruction for the current action based on the interface changes it caused. The instruction should be concise, clear, and actionable, incorporating specific details critical to the task, such as elements, file names, timestamps, or other relevant content visible in the screenshots. For example: - "Click on the ’...
-
[14]
Analysis: Carefully analyze the before-and-after screenshots step by step, focusing on the changes caused by the action. Then, examine key elements in both screenshots and consider possible operations based on these elements. For example: "The previous screen displayed the main interface of a shopping website, featuring multiple product categories and sev...
-
[15]
summarize the information about a product
High-Level Instruction: Based on the before-and-after screenshots, the action, and the analysis, generate a high-level task that you believe can be completed within the current interface. There are three types of tasks: - Information seeking: The user wants to obtain certain information from the webpage, such as product details, reviews, map information, ...
work page 2025
- [16]
-
[17]
Current Page (only current view, not full page, you may need to scroll to see more): - URL: {url} - Accessibility Tree (Page Context): {page_context} - Elements (addressable in this view): {elements} - Screenshot (only current view, not full page): {img_info}
-
[18]
History of Actions ({hint_for_history}): {previous_state_action} **Critical Rules for Success**
-
[19]
Issue only actions valid for the current observation (elements, accessibility tree, screenshot)
-
[20]
Propose ONE atomic action per item in your Potential-Actions list; actions must be independently executable
-
[21]
Prefer element IDs from the current Elements list for CLICK/TYPE/HOVER
-
[22]
Provide meaningful non-empty value if action∈{TYPE, SCROLL, GOTO, NONE, STOP}
-
[23]
If the task is complete, use NONE with the final answer in value; do not propose further actions
-
[24]
Be concise, avoid redundant/risky actions; each action must advance the task
-
[25]
If the task is hallucinated/low-quality/impossible, cautiously choose STOP based on observations/history. Pseudo-code for deciding STOP: if high_level_task lacks required info→STOP if high_level_task contains hallucinations→STOP if task is inappropriate/harmful→STOP if multiple (≥3) similar attempts already failed→STOP else→consider NON-STOP actions
-
[26]
First write a "state_observation_summary", then do step-by-step "reasoning", then decide "next_action"
-
[27]
Expect MULTIPLE steps; choose the next action that changes state; continue iteratively
-
[28]
You MUST actively decide the next step; do not choose NONE/STOP unless certain of finish/impossibility
- [29]
-
[30]
Actively explore alternatives before STOP if current approach stalls
-
[31]
Elements (addressable in this view)
Choose elements strictly from "Elements (addressable in this view)"; justify this choice in "reasoning"
-
[32]
If the page doesn’t change after an action, consider SCROLL to reveal more elements
-
[33]
Special note: when typing a date, use "MM/DD/YYYY". **Output Requirements** Return ONLY a JSON dictionary (no commentary) with: { "state_observation_summary": "1–3 sentence summary of the current state relevant to the task", "reasoning": "step-by-step reasoning to decide the next action; include rule-based justification and STOP check", "next_action": { "...
-
[34]
What is the most expensive product in the ’Electronics’ category?
**Information Seeking** — User aims to retrieve specific information from the website. - Examples: - "What is the most expensive product in the ’Electronics’ category?" - "What are the top 5 posts in the ’Technology’ forum?" - "Summarize the reviews for the product ’iPhone 11’."
-
[35]
Go to the billing page to check the latest transactions
**Site Navigation** — User aims to reach a specific page or site state. - Examples: - "Go to the billing page to check the latest transactions." - "Navigate to the ’Contact Us’ page and fill out the form to express interest in joining the company." - "Find the wiki page of ’the youngest person to receive a Nobel Prize’."
-
[36]
Create a user account with username ’bob2134’ and password ’128nxc18zxv’
**Content Modification** — User aims to change site content or settings. - Examples: - "Create a user account with username ’bob2134’ and password ’128nxc18zxv’." - "Post a new article titled ’The Future of AI’ in the ’Technology’ forum." - "Create a code repo named ’Agent’ and add a README with the text ’This is a code repo for an intelligent agent.’" ##...
-
[37]
**Invalid or Inconsistent Goal** — target entity/page/action does not exist, cannot be located, or conflicts with observed facts
-
[38]
**Insufficient Executable Details** — essential parameters are missing and cannot be inferred
-
[39]
### When NOT to REFINE- Goal is valid and consistent with observations
**Stalled or Repetitive Execution** — three or more consecutive actions show no meaningful change, or same error repeats. ### When NOT to REFINE- Goal is valid and consistent with observations. - Essential parameters are available or can be inferred. - Actions show measurable progress. - No persistent or repetitive failures detected. ### How to REFINE If ...
-
[40]
**Concretize Missing Details** — add essential parameters from history or observation
-
[41]
**Align with Reality** — replace hallucinated entities with actual ones found on the site
-
[42]
**Downscope the Goal** — adjust to the next achievable milestone
-
[43]
**Preserve Task Type** — keep within same category unless required otherwise. ## Goal Ensure the refined task is either already completed or highly likely to complete within the next 1–2 steps. ## Output Requirements - Format: JSON dictionary only, no commentary. - Fields:- "Analysis": Step-by-step reasoning. - "Need-to-Refine": "yes" or "no". - "High-Lev...
-
[44]
Previous High-Level-Tasks (oldest to newest): <start_previous_high_level_tasks> {previous_high_level_tasks} <end_previous_high_level_tasks>
-
[45]
History of Actions ({hint_for_history}): <start_action> {previous_state_action} <end_action>
-
[46]
Current Page (only current view): - URL: "{curr_url}" - Page Context: <start_context> {curr_state_context} <end_context> - Screenshot: "{img_info}" — You ONLY need to return a JSON dictionary formatted as follows (no commentary): { "Analysis": "step-by-step reasoning", "Need-to-Refine": "yes or no", "High-Level-Task": "refined task if yes, otherwise empty...
-
[47]
Goal Alignment (0–25): Steps relevant to the high-level task
-
[48]
Logical Order (0–25): Steps follow a coherent and sensible sequence
-
[49]
Efficiency (0–25): Avoids redundant or unnecessary actions
-
[50]
task": "<exact high-level task string>
Success Likelihood (0–25): Likely to end successfully with NONE (non-empty value). Note: The score is advisory; the final decision (keep/refine/drop) depends on qualitative judgment. — ### Decision Policy - Always ensure kept/refined trajectories end with a NONE action and non-empty value. - If refining, reorder or delete existing steps (do not add new on...
-
[51]
**Intent Variety (0–25):** Do the tasks represent different user intents (e.g., information seeking vs. navigation vs. modification)?
-
[52]
**Action Diversity (0–25):** Do the tasks require different types of GUI interactions (e.g., clicking, typing, scrolling, submitting forms)?
-
[53]
score": <int>, // 0–100 total diversity score
**Goal Coverage (0–25):** Do the tasks explore different meaningful aspects or functionalities of the environment?4. **Redundancy Minimization (0–25):** Are there minimal duplicate or near-duplicate tasks (i.e., no rephrasing of the same goal)? — ## Output Requirement (STRICT) Return ONLY one JSON object (no extra text, no code fences): { "score": <int>, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.