Rethinking Generative Image Pretraining: How Far Are We From Scaling Up Next-Pixel Prediction?
Pith reviewed 2026-05-21 18:12 UTC · model grok-4.3
The pith
Next-pixel prediction for images is primarily limited by compute rather than data, becoming feasible within five years.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
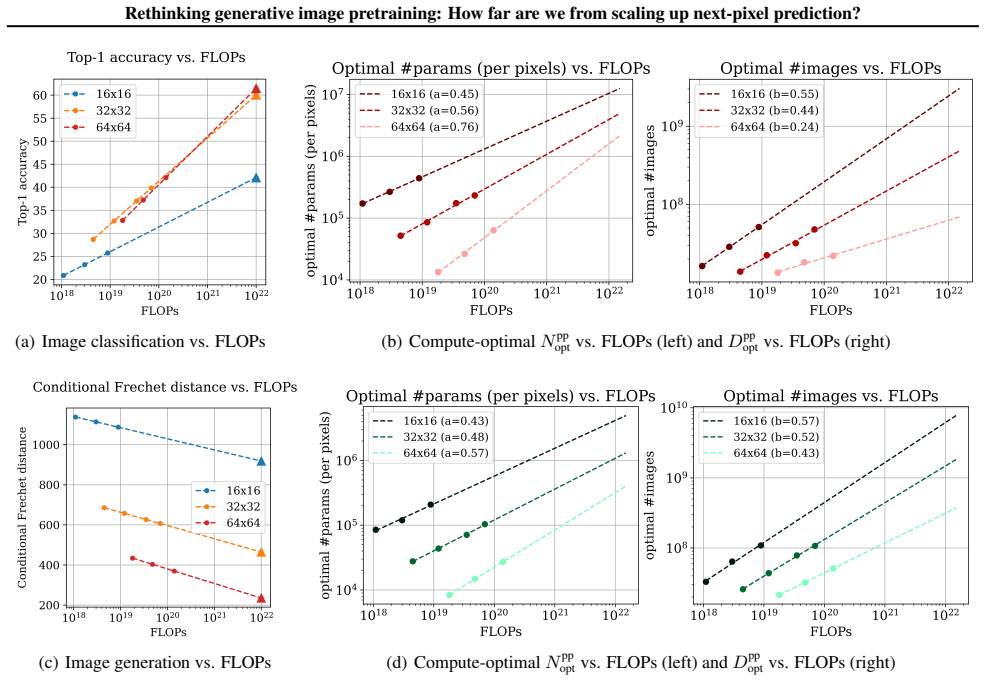
The central discovery is that scaling next-pixel prediction requires task-specific strategies: at fixed low resolution, generation tasks demand data sizes that grow three to five times faster than for classification tasks, while higher resolutions favor much larger models over additional data. Projecting these trends reveals compute as the key bottleneck, with annual growth rates suggesting that practical pixel-by-pixel image modeling will be achievable in the next five years.
What carries the argument
IsoFlops profiles that train families of Transformers while holding total compute fixed to reveal optimal model and data scaling for next-pixel prediction objectives.
If this is right
- Generation performance at 32x32 benefits from allocating more of the compute budget to data rather than model parameters compared to classification.
- As resolution increases, optimal configurations shift toward larger models and relatively smaller datasets.
- The dominant constraint on scaling autoregressive vision models is the available compute rather than data volume.
- With compute budgets expanding four to five times each year, next-pixel prediction at high resolutions becomes realistic within five years.
Where Pith is reading between the lines
- Unified models that handle both vision and language through next-token prediction may become more viable as compute scales.
- Efforts in vision pretraining could focus more on efficient use of compute rather than amassing ever-larger image collections.
- Similar scaling analyses could be applied to other sequential prediction tasks like video frame modeling.
Load-bearing premise
The scaling relationships between model size, data size, and performance measured at 32x32 resolution will hold without major changes when applied to higher resolutions and larger scales.
What would settle it
A direct test would be to measure the optimal scaling ratios at 128x128 or higher resolution and check whether they match the extrapolations from the 32x32 experiments, or to see if data efficiency improves or worsens differently than predicted.
Figures



read the original abstract
This paper investigates the scaling properties of autoregressive next-pixel prediction, a simple, end-to-end yet under-explored framework for unified vision models. Starting with images at resolutions of 32x32, we train a family of Transformers using IsoFlops profiles across compute budgets up to 7e19 FLOPs and evaluate three distinct target metrics: next-pixel prediction objective, ImageNet classification accuracy, and generation-based completion measured by Fr'echet Distance. First, optimal scaling strategy is critically task-dependent. At a fixed resolution of 32x32 alone, the optimal scaling properties for image classification and image generation diverge, where generation optimal setup requires the data size grow three to five times faster than for the classification optimal setup. Second, as image resolution increases, the optimal scaling strategy indicates that the model size must grow much faster than data size. Surprisingly, by projecting our findings, we discover that the primary bottleneck is compute rather than the amount of training data. As compute continues to grow four to five times annually, we forecast the feasibility of pixel-by-pixel modeling of images within the next five years.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates scaling properties of autoregressive next-pixel prediction for unified vision models using Transformer architectures. Experiments begin at 32x32 resolution with IsoFLOP training profiles up to 7e19 FLOPs and evaluate three metrics: next-pixel prediction loss, ImageNet classification accuracy, and Fréchet Distance for generative completion. Key findings are that optimal scaling is task-dependent at fixed 32x32 (generation requires data to scale 3-5 times faster than classification), that higher resolutions favor faster growth in model size than data size, and that projecting these trends identifies compute (not data) as the dominant bottleneck, forecasting feasibility of pixel-by-pixel image modeling within five years given 4-5x annual compute growth.
Significance. If the reported scaling relationships and bottleneck identification generalize beyond the tested regime, the work would provide useful empirical guidance for scaling generative pretraining in vision and highlight the promise of simple next-pixel objectives. The breadth of compute budgets and multi-metric evaluation across prediction, classification, and generation strengthens the empirical contribution. The five-year forecast, if substantiated with additional validation, could shape research priorities toward compute-efficient scaling of autoregressive vision models.
major comments (2)
- Abstract: The five-year feasibility forecast and claim that compute is the primary bottleneck are obtained by projecting fitted scaling coefficients from the 32x32 IsoFLOP experiments; the manuscript provides neither the exact functional forms of the scaling fits, error bars on the measurements, nor validation of the extrapolation assumptions, leaving the central projection unverified.
- Abstract: The statement that 'as image resolution increases, the optimal scaling strategy indicates that the model size must grow much faster than data size' is presented without scaling curves, exponent fits, or IsoFLOP tables for any resolution above 32x32; this absence is load-bearing for the compute-dominance diagnosis and the five-year timeline.
minor comments (2)
- The manuscript would benefit from explicit equations for the fitted scaling laws, inclusion of error bars on all reported scaling plots, and a clear statement of data exclusion criteria used in the fits.
- Clarify how the three-to-five-times faster data growth for generation versus classification at 32x32 was quantitatively derived from the IsoFLOP profiles.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the presentation of our scaling projections and their empirical basis. We address the major comments point by point below, proposing targeted revisions to improve transparency while preserving the core contributions of the work.
read point-by-point responses
-
Referee: Abstract: The five-year feasibility forecast and claim that compute is the primary bottleneck are obtained by projecting fitted scaling coefficients from the 32x32 IsoFLOP experiments; the manuscript provides neither the exact functional forms of the scaling fits, error bars on the measurements, nor validation of the extrapolation assumptions, leaving the central projection unverified.
Authors: We agree that greater transparency is needed for the projection methodology. In the revised manuscript, we will add an appendix section that reports the exact functional forms of the fitted scaling laws (power-law relationships between optimal model size, data size, and compute budget derived from the IsoFLOP profiles), includes error bars obtained via bootstrap resampling across training runs, and provides a validation analysis that holds out intermediate compute budgets to assess extrapolation accuracy within the 32x32 regime. These additions will allow independent verification of the five-year forecast under the stated 4-5x annual compute growth assumption. revision: yes
-
Referee: Abstract: The statement that 'as image resolution increases, the optimal scaling strategy indicates that the model size must grow much faster than data size' is presented without scaling curves, exponent fits, or IsoFLOP tables for any resolution above 32x32; this absence is load-bearing for the compute-dominance diagnosis and the five-year timeline.
Authors: The indicated trend for higher resolutions is an extrapolation from the observed task-dependent optimal data-to-model ratios at 32x32, combined with established scaling principles that larger input dimensionality favors increased model capacity over data volume. We acknowledge that direct IsoFLOP curves or tables at resolutions above 32x32 are not included. In revision, we will expand the discussion to detail the extrapolation procedure, including any supporting assumptions or small-scale diagnostic runs, and rephrase the abstract claim to emphasize that it is a projected indication rather than a direct measurement. This will strengthen the grounding for the compute-bottleneck conclusion without requiring new large-scale experiments at higher resolutions. revision: partial
Circularity Check
Five-year feasibility forecast and compute-bottleneck claim reduce to extrapolation of scaling coefficients fitted at 32x32
specific steps
-
fitted input called prediction
[Abstract]
"Surprisingly, by projecting our findings, we discover that the primary bottleneck is compute rather than the amount of training data. As compute continues to grow four to five times annually, we forecast the feasibility of pixel-by-pixel modeling of images within the next five years."
The scaling laws, optimal data-vs-model growth rates, and task-dependent behaviors are all measured and fitted on the 32x32 IsoFLOP runs. Labeling the direct extrapolation of those fitted coefficients as a 'discovery' of the bottleneck and a quantitative five-year forecast makes the claimed prediction equivalent to re-applying the same fitted model to new compute and resolution values.
full rationale
The paper trains models and fits scaling relationships exclusively at 32x32 resolution, then invokes those same fitted relationships to 'project' both the identification of compute as the dominant bottleneck and the five-year timeline for pixel-by-pixel modeling. Because the projection step simply extends the empirically tuned exponents and optimal data-vs-model ratios to unseen regimes (higher resolution and future compute budgets) without new measurements or external validation, the headline forecast is statistically forced by the input fits rather than independently derived.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Power-law scaling relationships observed at 32x32 continue to govern behavior at higher resolutions and larger compute budgets
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We follow the IsoFlops profile approach in (Hoffmann et al., 2022) to conduct the scaling law study... Nopt ∝ C^0.55 and Dopt ∝ C^0.45... as image resolution increases, the optimal scaling strategy indicates that the model size must grow much faster than data size.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Surprisingly, by projecting our findings, we discover that the primary bottleneck is compute rather than the amount of training data.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Agarwal, N., Ali, A., Bala, M., Balaji, Y ., Barker, E., Cai, T., Chattopadhyay, P., Chen, Y ., Cui, Y ., Ding, Y ., et al. Cosmos world foundation model platform for physical AI. arXiv:2501.03575,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Anil, R., Dai, A. M., Firat, O., Johnson, M., Lepikhin, D., Passos, A., Shakeri, S., Taropa, E., Bailey, P., Chen, Z., et al. Palm 2 technical report. arXiv:2305.10403,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models. arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Scaling Laws for Autoregressive Generative Modeling
Henighan, T., Kaplan, J., Katz, M., Chen, M., Hesse, C., Jackson, J., Jun, H., Brown, T. B., Dhariwal, P., Gray, S., et al. Scaling laws for autoregressive generative modeling. arXiv:2010.14701,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., and Dean, J. Distilling the knowl- edge in a neural network. arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[7]
Li, T., Sun, Q., Fan, L., and He, K. Fractal generative models. arXiv:2502.17437,
-
[8]
GLU Variants Improve Transformer
Shazeer, N. GLU variants improve transformer. arXiv:2002.05202,
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[9]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y ., Chen, S., Zhang, S., Peng, B., Luo, P., and Yuan, Z. Autoregressive model beats diffusion: Llama for scalable image generation. arXiv:2406.06525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Gemma: Open Models Based on Gemini Research and Technology
Team, G., Mesnard, T., Hardin, C., Dadashi, R., Bhupatiraju, S., Pathak, S., Sifre, L., Rivi`ere, M., Kale, M. S., Love, J., et al. Gemma: Open models based on gemini research and technology. arXiv:2403.08295,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.