REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Reasoning in Long-Form Video Understanding
Pith reviewed 2026-05-17 22:16 UTC · model grok-4.3
The pith
REVISOR lets multimodal models reflect on both text and specific video segments to improve long-form video reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
REVISOR is a tool-augmented multimodal reflection framework that enables MLLMs to build introspective processes spanning textual rethinking and visual segment rethinking with cross-modal interaction; the Dual Attribution Decoupled Reward mechanism, integrated into GRPO training, enforces causal alignment between reasoning steps and selected video evidence, thereby raising long-form video understanding accuracy on VideoMME, LongVideoBench, MLVU, and LVBench without supplementary supervised fine-tuning or external models.
What carries the argument
The REVISOR framework that adds visual segment rethinking and cross-modal interaction to reflection, anchored by the Dual Attribution Decoupled Reward (DADR) inside GRPO training.
If this is right
- MLLMs achieve higher accuracy on long-video tasks involving dynamic visual content.
- Reasoning chains become more grounded in actual video segments rather than text alone.
- Performance gains appear across VideoMME, LongVideoBench, MLVU, and LVBench without extra supervised data.
- The approach works using only the base MLLM and reinforcement learning with the DADR reward.
Where Pith is reading between the lines
- Similar multimodal reflection could be tested on long audio or multi-turn image sequences where temporal evidence matters.
- The DADR alignment idea might reduce cases where models cite irrelevant video frames while still answering correctly.
- Extending the visual rethinking loop to even longer videos could reveal where cross-modal interaction becomes the main bottleneck.
Load-bearing premise
Adding visual segment rethinking and cross-modal interaction during reflection will overcome the limits of text-only reflection on long videos, and the DADR reward will create genuine causal links to relevant video evidence rather than spurious correlations.
What would settle it
An ablation that removes the visual segment rethinking module and measures whether accuracy on VideoMME and LongVideoBench stays the same or rises.
Figures











read the original abstract
Self-reflection mechanisms that rely on purely text-based rethinking processes perform well in most multimodal tasks. However, when directly applied to long-form video understanding scenarios, they exhibit clear limitations. The fundamental reasons for this lie in two points: (1)long-form video understanding involves richer and more dynamic visual input, meaning rethinking only the text information is insufficient and necessitates a further rethinking process specifically targeting visual information; (2) purely text-based reflection mechanisms lack cross-modal interaction capabilities, preventing them from fully integrating visual information during reflection. Motivated by these insights, we propose REVISOR (REflective VIsual Segment Oriented Reasoning), a novel framework for tool-augmented multimodal reflection. REVISOR enables MLLMs to collaboratively construct introspective reflection processes across textual and visual modalities, significantly enhancing their reasoning capability for long-form video understanding. To ensure that REVISOR can learn to accurately review video segments highly relevant to the question during reinforcement learning, we designed the Dual Attribution Decoupled Reward (DADR) mechanism. Integrated into the GRPO training strategy, this mechanism enforces causal alignment between the model's reasoning and the selected video evidence. Notably, the REVISOR framework significantly enhances long-form video understanding capability of MLLMs without requiring supplementary supervised fine-tuning or external models, achieving impressive results on four benchmarks including VideoMME, LongVideoBench, MLVU, and LVBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes REVISOR, a framework for tool-augmented multimodal reflection in MLLMs that extends beyond text-based self-reflection by incorporating visual segment rethinking and cross-modal interactions. It introduces the Dual Attribution Decoupled Reward (DADR) integrated into GRPO training to enforce causal alignment between reasoning traces and question-relevant video segments. The work claims that this approach significantly improves long-form video understanding on benchmarks including VideoMME, LongVideoBench, MLVU, and LVBench, without requiring additional supervised fine-tuning or external models.
Significance. If the empirical gains hold and DADR demonstrably produces causal alignment rather than amplified correlations, the framework could meaningfully advance multimodal reasoning for dynamic, long-form video inputs by addressing documented shortcomings of purely textual reflection. The explicit avoidance of supplementary SFT and external models is a positive attribute that could improve accessibility and reproducibility.
major comments (2)
- [Abstract] Abstract: The assertion that DADR 'enforces causal alignment' between reasoning and selected video evidence is load-bearing for the central claim that multimodal reflection overcomes text-only limitations. However, the manuscript provides no description of controls (counterfactual segment masking, intervention on attribution scores, or direct comparison to a non-decoupled reward) that would distinguish genuine introspective alignment from improved heuristic retrieval of question-relevant segments. If gains on VideoMME and LongVideoBench arise from the latter, the claimed advance is not supported.
- [§4] The DADR formulation and its integration with GRPO (likely §4): It is unclear how the decoupled reward is computed to isolate causal effects from spurious correlations already present in the video encoder. Without ablations that isolate the contribution of the dual attribution mechanism, it is difficult to verify that the observed improvements stem from introspective multimodal reasoning rather than enhanced segment selection heuristics.
minor comments (2)
- The abstract would be strengthened by including at least one key quantitative result (e.g., absolute accuracy gains or relative improvement on VideoMME) to substantiate the 'impressive results' claim.
- [§3] Notation for the visual segment rethinking process and cross-modal interaction steps should be introduced with explicit definitions or pseudocode to improve clarity for readers unfamiliar with the exact operationalization.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The concerns regarding the strength of the causal claims for DADR and the need for clearer ablations are important. We respond to each major comment below and indicate the changes we will make in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that DADR 'enforces causal alignment' between reasoning and selected video evidence is load-bearing for the central claim that multimodal reflection overcomes text-only limitations. However, the manuscript provides no description of controls (counterfactual segment masking, intervention on attribution scores, or direct comparison to a non-decoupled reward) that would distinguish genuine introspective alignment from improved heuristic retrieval of question-relevant segments. If gains on VideoMME and LongVideoBench arise from the latter, the claimed advance is not supported.
Authors: We appreciate the referee pointing out that the current wording and supporting evidence for causal alignment could be strengthened. The DADR is constructed by decomposing the reward into separate attribution terms for the reasoning trace and the selected visual segments before they are combined in the GRPO objective; this decomposition is intended to reduce the influence of correlations already captured by the video encoder. We acknowledge that the manuscript does not contain explicit counterfactual interventions such as segment masking or direct comparisons against a non-decoupled reward. In the revision we will change the abstract phrasing from 'enforces causal alignment' to 'promotes causal alignment' and add a paragraph in the discussion section that explicitly notes the absence of such interventional controls as a limitation while describing how the dual formulation differs from standard heuristic retrieval. We will also include a new ablation that replaces DADR with a single-attribution reward to quantify the contribution of the decoupling step. revision: partial
-
Referee: [§4] The DADR formulation and its integration with GRPO (likely §4): It is unclear how the decoupled reward is computed to isolate causal effects from spurious correlations already present in the video encoder. Without ablations that isolate the contribution of the dual attribution mechanism, it is difficult to verify that the observed improvements stem from introspective multimodal reasoning rather than enhanced segment selection heuristics.
Authors: We agree that the current description of the reward computation leaves room for ambiguity. The dual attribution is realized by computing two separate scalar scores—one for the alignment between the generated reasoning tokens and the question, and one for the alignment between the selected video segments and the same reasoning trace—then combining them with a weighting factor inside the GRPO advantage estimate. This structure is meant to penalize cases where segment selection succeeds only because of encoder biases rather than because the segments support the reasoning. To improve clarity we will expand §4 with the explicit equations for both attribution scores and their integration into the GRPO loss. In addition, we will add an ablation study that disables the dual structure (i.e., uses only a single combined attribution reward) and reports the resulting drop in performance on VideoMME and LongVideoBench, thereby isolating the effect of the decoupling mechanism. revision: yes
Circularity Check
No circularity: novel framework construction with no self-referential reductions
full rationale
The paper presents REVISOR as a new tool-augmented multimodal reflection framework motivated by two explicit limitations of text-only reflection in long-form video. It introduces the DADR reward integrated into GRPO to enforce alignment between reasoning traces and selected segments. No equations, derivations, or fitted parameters are described in the provided text that would reduce the claimed gains on VideoMME/LongVideoBench to quantities defined by the inputs themselves. The architecture and reward design are offered as an independent construction rather than a renaming or self-citation chain. This matches the reader's assessment that no derivations reduce claimed gains to fitted parameters.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Purely text-based reflection is insufficient for long-form video because visual input is richer and more dynamic.
- domain assumption Cross-modal interaction during reflection is required to integrate visual information.
invented entities (2)
-
REVISOR framework
no independent evidence
-
Dual Attribution Decoupled Reward (DADR)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
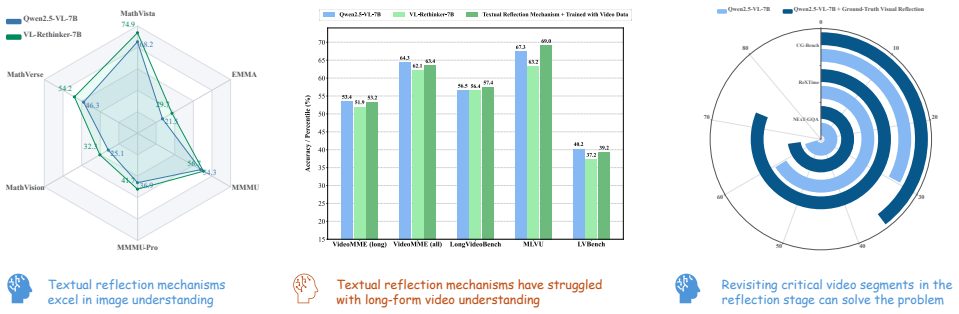
Dual Attribution Decoupled Reward (DADR) … enforces causal alignment between the model’s reasoning and the selected video evidence
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage reasoning framework … initial inference … reflective reasoning … visual toolbox
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Video-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy Distillation
Video-OPD uses on-policy distillation from a frontier teacher to turn sparse episode rewards into dense step-wise signals for more efficient post-training of MLLMs on temporal video grounding.
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 6, 7, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Guo Chen, Yicheng Liu, Yifei Huang, Yuping He, Baoqi Pei, Jilan Xu, Yali Wang, Tong Lu, and Limin Wang. Cg- bench: Clue-grounded question answering benchmark for long video understanding.arXiv preprint arXiv:2412.12075,
-
[4]
Jr-Jen Chen, Yu-Chien Liao, Hsi-Che Lin, Yu-Chu Yu, Yen- Chun Chen, and Frank Wang. Rextime: A benchmark suite for reasoning-across-time in videos.Advances in Neural In- formation Processing Systems, 37:28662–28673, 2024. 4, 6
work page 2024
-
[5]
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Zhenyu Tang, Li Yuan, et al. Sharegpt4video: Improving video understand- ing and generation with better captions.Advances in Neural Information Processing Systems, 37:19472–19495, 2024. 6
work page 2024
-
[6]
Datasets and recipes for video temporal grounding via reinforcement learning
Ruizhe Chen, Tianze Luo, Zhiting Fan, Heqing Zou, Zhaopeng Feng, Guiyang Xie, Hansheng Zhang, Zhuochen Wang, Zuozhu Liu, and Zhang Huaijian. Datasets and recipes for video temporal grounding via reinforcement learning. InProceedings of the 2025 Conference on Em- pirical Methods in Natural Language Processing: Industry Track, pages 983–992, 2025. 7, 9, 2
work page 2025
-
[7]
Yukang Chen, Wei Huang, Baifeng Shi, Qinghao Hu, Han- rong Ye, Ligeng Zhu, Zhijian Liu, Pavlo Molchanov, Jan Kautz, Xiaojuan Qi, et al. Scaling rl to long videos.arXiv preprint arXiv:2507.07966, 2025. 6
-
[8]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025. 2, 7
work page 2025
-
[10]
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, and Noah D Goodman. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars.arXiv preprint arXiv:2503.01307, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Tall: Temporal activity localization via language query
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. Tall: Temporal activity localization via language query. In Proceedings of the IEEE international conference on com- puter vision, pages 5267–5275, 2017. 7
work page 2017
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 1, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Vtimellm: Empower llm to grasp video moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. Vtimellm: Empower llm to grasp video moments. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 14271–14280, 2024. 7, 2
work page 2024
-
[14]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Look again, think slowly: Enhancing vi- sual reflection in vision-language models
Pu Jian, Junhong Wu, Wei Sun, Chen Wang, Shuo Ren, and Jiajun Zhang. Look again, think slowly: Enhancing vi- sual reflection in vision-language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 9262–9281, 2025. 9
work page 2025
-
[16]
Training Language Models to Self-Correct via Reinforcement Learning
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, et al. Training language models to self-correct via reinforcement learning.arXiv preprint arXiv:2409.12917, 2024. 1, 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
imove: Instance-motion-aware video understanding
Jiaze Li, Yaya Shi, Zongyang Ma, Haoran Xu, Huihui Xiao, Ruiwen Kang, Fan Yang, Tingting Gao, Di Zhang, et al. imove: Instance-motion-aware video understanding. In Findings of the Association for Computational Linguistics: ACL 2025, pages 23959–23975, 2025. 7, 2
work page 2025
-
[19]
Videochat- flash: Hierarchical compression for long-context video mod- eling, 2025
Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chent- ing Wang, Yu Qiao, Yali Wang, and Limin Wang. Videochat- flash: Hierarchical compression for long-context video mod- eling, 2025. 6
work page 2025
-
[20]
Yansheng Li, Linlin Wang, Tingzhu Wang, Xue Yang, Jun- wei Luo, Qi Wang, Youming Deng, Wenbin Wang, Xian Sun, Haifeng Li, et al. Star: A first-ever dataset and a large-scale benchmark for scene graph generation in large-size satel- lite imagery.IEEE Trans. Pattern Anal. Mach. Intell, 47(3): 1832–1849, 2025. 6
work page 2025
-
[21]
Keyvideollm: Towards large-scale video keyframe selection, 2024
Hao Liang, Jiapeng Li, Tianyi Bai, Xijie Huang, Linzhuang Sun, Zhengren Wang, Conghui He, Bin Cui, Chong Chen, and Wentao Zhang. Keyvideollm: Towards large-scale video keyframe selection, 2024. 9
work page 2024
-
[22]
Video-llava: Learning united visual repre- sentation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual repre- sentation by alignment before projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 5971–5984, 2024. 6
work page 2024
-
[23]
Jingyang Lin, Jialian Wu, Ximeng Sun, Ze Wang, Jiang Liu, Yusheng Su, Xiaodong Yu, Hao Chen, Jiebo Luo, Zicheng Liu, et al. Unleashing hour-scale video train- ing for long video-language understanding.arXiv preprint arXiv:2506.05332, 2025. 6
-
[24]
Videomind: A chain-of-lora agent for long video reasoning, 2025
Ye Liu, Kevin Qinghong Lin, Chang Wen Chen, and Mike Zheng Shou. Videomind: A chain-of-lora agent for long video reasoning, 2025. 9
work page 2025
-
[25]
Nvila: Efficient frontier visual lan- guage models
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, et al. Nvila: Efficient frontier visual lan- guage models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4122–4134, 2025. 6
work page 2025
-
[26]
Large language model guided tree-of-thought
Jieyi Long. Large language model guided tree-of-thought. arXiv preprint arXiv:2305.08291, 2023. 1
-
[27]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hal- linan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: It- erative refinement with self-feedback.Advances in Neural Information Processing Systems, 36:46534–46594, 2023. 1, 9
work page 2023
-
[29]
Yuanbin Man, Ying Huang, Chengming Zhang, Bingzhe Li, Wei Niu, and Miao Yin. Adacm 2: On understanding ex- tremely long-term video with adaptive cross-modality mem- ory reduction, 2025. 9
work page 2025
-
[30]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, et al. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforce- ment learning.arXiv preprint arXiv:2503.07365, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Jiahao Meng, Xiangtai Li, Haochen Wang, Yue Tan, Tao Zhang, Lingdong Kong, Yunhai Tong, Anran Wang, Zhiyang Teng, Yujing Wang, et al. Open-o3 video: Grounded video reasoning with explicit spatio-temporal evidence.arXiv preprint arXiv:2510.20579, 2025. 6, 9
-
[32]
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Re- casens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Mateusz Malinowski, Yi Yang, Carl Doersch, et al. Per- ception test: A diagnostic benchmark for multimodal video models.Advances in Neural Information Processing Sys- tems, 36:42748–42761, 2023. 6
work page 2023
-
[33]
Timechat: A time-sensitive multimodal large lan- guage model for long video understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large lan- guage model for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14313–14323, 2024. 7, 2
work page 2024
-
[34]
Weiming Ren, Wentao Ma, Huan Yang, Cong Wei, Ge Zhang, and Wenhu Chen. Vamba: Understanding hour- long videos with hybrid mamba-transformers.arXiv preprint arXiv:2503.11579, 2025. 6
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of math- ematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generaliz- able r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Bal- akrishnan Varadarajan, Florian Bordes, et al. Longvu: Spa- tiotemporal adaptive compression for long video-language understanding.arXiv preprint arXiv:2410.17434, 2024. 6, 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Hybridflow: A flexible and efficient rlhf frame- work
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf frame- work. InProceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025. 6
work page 2025
-
[39]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of con- text.arXiv preprint arXiv:2403.05530, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Thinking with video: Video generation as a promising multimodal reasoning paradigm,
Jingqi Tong, Yurong Mou, Hangcheng Li, Mingzhe Li, Yongzhuo Yang, Ming Zhang, Qiguang Chen, Tianyi Liang, Xiaomeng Hu, Yining Zheng, Xinchi Chen, Jun Zhao, Xu- anjing Huang, and Xipeng Qiu. Thinking with video: Video generation as a promising multimodal reasoning paradigm,
-
[41]
Zhongwei Wan, Zhihao Dou, Che Liu, Yu Zhang, Dongfei Cui, Qinjian Zhao, Hui Shen, Jing Xiong, Yi Xin, Yifan Jiang, et al. Srpo: Enhancing multimodal llm reasoning via reflection-aware reinforcement learning.arXiv preprint arXiv:2506.01713, 2025. 1, 9
-
[42]
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning.arXiv preprint arXiv:2504.08837, 2025. 1, 6, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Lvbench: An extreme long video understanding benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiao- han Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. Lvbench: An extreme long video understanding benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958–22967, 2025. 2, 7
work page 2025
-
[44]
Videoagent: Long-form video understanding with large language model as agent, 2024
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung- Levy. Videoagent: Long-form video understanding with large language model as agent, 2024. 9
work page 2024
-
[45]
Time-R1: Post-Training Large Vision Language Model for Temporal Video Grounding
Ye Wang, Ziheng Wang, Boshen Xu, Yang Du, Kejun Lin, Zihan Xiao, Zihao Yue, Jianzhong Ju, Liang Zhang, Dingyi Yang, et al. Time-r1: Post-training large vision lan- guage model for temporal video grounding.arXiv preprint arXiv:2503.13377, 2025. 6, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Videochat-a1: Think- ing with long videos by chain-of-shot reasoning, 2025
Zikang Wang, Boyu Chen, Zhengrong Yue, Yi Wang, Yu Qiao, Limin Wang, and Yali Wang. Videochat-a1: Think- ing with long videos by chain-of-shot reasoning, 2025. 9
work page 2025
-
[47]
Videotree: Adaptive tree-based video representation for llm reasoning on long videos, 2025
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, and Mohit Bansal. Videotree: Adaptive tree-based video representation for llm reasoning on long videos, 2025. 9
work page 2025
-
[48]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Informa- tion Processing Systems, 37:28828–28857, 2024. 2, 7
work page 2024
-
[49]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9777–9786, 2021. 6
work page 2021
-
[50]
Can i trust your answer? visually grounded video question answering
Junbin Xiao, Angela Yao, Yicong Li, and Tat-Seng Chua. Can i trust your answer? visually grounded video question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13204– 13214, 2024. 4, 7
work page 2024
-
[51]
Yuan Xie, Tianshui Chen, Zheng Ge, and Lionel Ni. Video- mtr: Reinforced multi-turn reasoning for long video under- standing.arXiv preprint arXiv:2508.20478, 2025. 6
-
[52]
Ziang Yan, Xinhao Li, Yinan He, Zhengrong Yue, Xiangyu Zeng, Yali Wang, Yu Qiao, Limin Wang, and Yi Wang. Videochat-r1. 5: Visual test-time scaling to reinforce mul- timodal reasoning by iterative perception.arXiv preprint arXiv:2509.21100, 2025. 9
-
[53]
Ziang Yan, Zhilin Li, Yinan He, Chenting Wang, Kunchang Li, Xinhao Li, Xiangyu Zeng, Zilei Wang, Yali Wang, Yu Qiao, et al. Task preference optimization: Improving multi- modal large language models with vision task alignment. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 29880–29892, 2025. 7, 2
work page 2025
-
[54]
Look-back: Implicit visual re-focusing in mllm reasoning.arXiv preprint arXiv:2507.03019, 2025
Shuo Yang, Yuwei Niu, Yuyang Liu, Yang Ye, Bin Lin, and Li Yuan. Look-back: Implicit visual re-focusing in mllm reasoning.arXiv preprint arXiv:2507.03019, 2025. 9
-
[55]
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, et al. R1-onevision: Advancing gen- eralized multimodal reasoning through cross-modal formal- ization.arXiv preprint arXiv:2503.10615, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Gen- erative frame sampler for long video understanding, 2025
Linli Yao, Haoning Wu, Kun Ouyang, Yuanxing Zhang, Caiming Xiong, Bei Chen, Xu Sun, and Junnan Li. Gen- erative frame sampler for long video understanding, 2025. 9
work page 2025
-
[57]
CLEVRER: CoLlision Events for Video REpresentation and Reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning. arXiv preprint arXiv:1910.01442, 2019. 6
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[58]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gao- hong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Jinghan Zhang, Xiting Wang, Fengran Mo, Yeyang Zhou, Wanfu Gao, and Kunpeng Liu. Entropy-based explo- ration conduction for multi-step reasoning.arXiv preprint arXiv:2503.15848, 2025. 1
-
[60]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision.arXiv preprint arXiv:2406.16852, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Zi- wei Liu, and Chunyuan Li. Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Mlvu: Benchmarking multi-task long video understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, et al. Mlvu: Benchmarking multi-task long video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13691– 13701, 2025. 2, 7 REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Rea...
work page 2025
-
[63]
8.1, we present the detailed experimental setup for experiments involving the REVISOR framework
More Experimental Details on REVISOR In Sec. 8.1, we present the detailed experimental setup for experiments involving the REVISOR framework. Sec. 8.2 outlines the composition of the training data for the RE- VISOR framework. Sec. 8.3 then presents supplementary experimental results, including comprehensive results on the Temporal Video Grounding task and...
work page 2088
-
[64]
Training Qwen2.5-VL-7B with Textual Re- flection Mechanism on Video Data To ensure a fair comparison, we train a Qwen2.5-VL-7B model equipped with a text-based self-reflection mecha- nism using the datasets listed in Fig. 6. Specifically, unlike REVISOR, the text-reflection model generates only textual output during the reflection phase. Apart from this d...
-
[65]
Case Study of REVISOR Framework Improved Video Reasoning Capability.REVISOR can significantly enhance the long-form video understanding capabilities of MLLMs. Fig. 7, Fig. 8, and Fig. 9 re- spectively demonstrate these improvements from three per- spectives: more precise detail capture, more comprehensive scene understanding, and more accurate object coun...
-
[66]
Prompt Templates of REVISOR The complete prompt template used during the training of the REVISOR framework consists of three primary compo- nents: the system prompt, the initial reasoning stage, and the reflective reasoning stage. Fig. 12 illustrates the tem- plates for both the initial reasoning and reflective reasoning stages, while Fig. 13 presents the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.