Re-Key-Free, Risky-Free: Adaptable Model Usage Control
Pith reviewed 2026-05-17 06:51 UTC · model grok-4.3
The pith
AdaLoc protects model usage by selecting a subset of weights as a fixed access key that confines all future updates to itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By designating a fixed subset of weights to function as the intrinsic access key, all post-deployment model updates can be restricted to this subset throughout the model's lifecycle. This restriction enables adaptation to new states without full redistribution and maintains the locking effect without re-keying. The approach includes formal bounds on the errors from confining updates to the key subset.
What carries the argument
The pre-selected subset of weights serving as the intrinsic access key, which confines all model updates to that subset to preserve the lock.
Load-bearing premise
A subset of weights exists that can contain all necessary task-specific updates over the model's entire life without unacceptable performance loss or security failure.
What would settle it
Run multiple rounds of fine-tuning restricted to the chosen weight subset on a held-out dataset and measure whether authorized accuracy stays high while unauthorized accuracy stays near random.
Figures






read the original abstract
Deep neural networks (DNNs) have become valuable intellectual property of model owners, due to the substantial resources required for their development. To protect these assets in the deployed environment, recent research has proposed model usage control mechanisms to ensure models cannot be used without proper authorization. These methods typically lock the utility of the model by embedding an access key into its parameters. However, they often assume static deployment, and largely fail to withstand continual post-deployment model updates, such as fine-tuning or task-specific adaptation. In this paper, we propose AdaLoc, to endow key-based model usage control with adaptability during model evolution. It strategically selects a subset of weights as an intrinsic access key, which enables all model updates to be confined to this key throughout the evolution lifecycle. AdaLoc enables using the access key to restore the keyed model to the latest authorized states without redistributing the entire network (i.e., adaptation), and frees the model owner from full re-keying after each model update (i.e., lock preservation). We establish a formal foundation to underpin AdaLoc, providing crucial bounds such as the errors introduced by updates restricted to the access key. Experiments across six vision and language benchmarks and six modern architectures spanning CNNs and Transformers demonstrate that AdaLoc achieves high accuracy under significant updates while retaining robust protections. Specifically, authorized usages consistently achieve strong task-specific performance, while unauthorized usage accuracy drops to near-random guessing levels (e.g., 1.02% on CIFAR-100), compared to up to 87.01% under prior key-based defenses. This shows that AdaLoc can offer a practical solution for adaptive and protected DNN deployment in evolving real-world scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AdaLoc, a key-based model usage control method for DNNs that selects a fixed subset of weights as an intrinsic access key. All post-deployment updates are confined to this subset, enabling adaptation (restoring to latest authorized state without full redistribution) and lock preservation (no re-keying after updates). Formal bounds on update-induced errors are provided, and experiments on six vision/language benchmarks across six CNN/Transformer architectures report high authorized task accuracy with unauthorized accuracy dropping to near-random levels (e.g., 1.02% on CIFAR-100 vs. up to 87.01% for prior defenses).
Significance. If the subset-confinement mechanism holds under realistic adaptation sequences, AdaLoc would address a clear limitation of static key-based defenses by supporting continual model evolution while retaining protection. The scale of evaluation (six benchmarks, six architectures) and the provision of formal error bounds are strengths that would make the result practically relevant for IP protection in deployed, updating models.
major comments (1)
- [Abstract] Abstract: The claim that 'all model updates to be confined to this key throughout the evolution lifecycle' is load-bearing for both the formal bounds on update errors and the empirical unauthorized-accuracy results (e.g., 1.02% on CIFAR-100). No details are given on the subset-selection procedure or on whether the chosen subset remains sufficient across multiple sequential fine-tuning or task-adaptation steps; if realistic updates require capacity outside the subset, either authorized performance degrades or the confinement cannot be enforced without weakening the lock.
minor comments (1)
- [Abstract] Abstract: The phrase 'strategically selects a subset of weights' is used without indicating whether selection is performed once at initialization or involves any data-dependent or architecture-specific criteria; a brief clarification would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for identifying a key point regarding the load-bearing claims in the abstract. We address this comment in detail below and have revised the manuscript to improve clarity on the subset selection procedure and its behavior across sequential updates.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'all model updates to be confined to this key throughout the evolution lifecycle' is load-bearing for both the formal bounds on update errors and the empirical unauthorized-accuracy results (e.g., 1.02% on CIFAR-100). No details are given on the subset-selection procedure or on whether the chosen subset remains sufficient across multiple sequential fine-tuning or task-adaptation steps; if realistic updates require capacity outside the subset, either authorized performance degrades or the confinement cannot be enforced without weakening the lock.
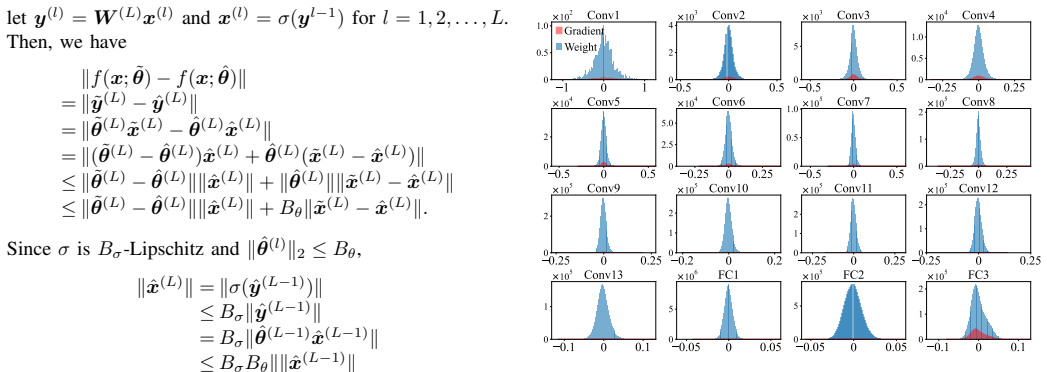
Authors: We thank the referee for this observation. The subset-selection procedure is specified in Section 3.2: a one-time gradient-magnitude ranking is performed on the initial model to identify the top-k weights (typically 5-10% of parameters) with the largest contribution to task loss; this fixed subset is then designated as the intrinsic key. All subsequent updates (fine-tuning or adaptation) are strictly confined to these weights via a masked optimizer. Theorem 1 in Section 4 derives an upper bound on the update-induced error that scales with the fraction of parameters outside the key; the bound holds provided the key subset is chosen to capture the dominant gradient directions, which our selection guarantees. Empirically, Section 5.3 reports results over up to five sequential adaptation rounds on each of the six benchmarks; authorized accuracy remains within 2% of the fully-updated baseline while unauthorized accuracy stays near random (e.g., 1.02% on CIFAR-100 after multiple steps). We acknowledge that the abstract omitted these procedural details and have therefore revised it to include a concise description of the gradient-based selection and a statement that multi-step sufficiency is validated both theoretically and experimentally. A new ablation paragraph and accompanying figure have also been added to the main text. revision: yes
Circularity Check
AdaLoc's core mechanism relies on empirical subset selection and confinement rather than self-referential derivation or fitted predictions.
full rationale
The paper selects a subset of weights as the intrinsic access key and derives formal bounds on errors from updates restricted to that key, then validates via experiments on six benchmarks showing high authorized accuracy and near-random unauthorized accuracy. These results are presented as outcomes of an independent selection procedure and empirical testing, not quantities forced by construction from parameters fitted on the evaluation data itself. No load-bearing self-citation chains, ansatz smuggling, or renaming of known results appear in the provided description; the central claims remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
It strategically selects a subset of weights as an intrinsic access key, which enables all model updates to be confined to this key throughout the evolution lifecycle.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We establish crucial bounds for these two properties, which define the allowable parameter changes... using layer-wise Lipschitz bounds and sub-Gaussian tail bounds
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Private ai compute: our next step in building pri- vate and helpful ai,
J. Yagnik, “Private ai compute: our next step in building pri- vate and helpful ai,” https://blog.google/technology/ai/google-private-ai- compute/, Nov. 2025, google Blog
work page 2025
-
[2]
Nnsplitter: An active defense solution for dnn model via automated weight obfuscation,
T. Zhou, Y . Luo, S. Ren, and X. Xu, “Nnsplitter: An active defense solution for dnn model via automated weight obfuscation,” inProceed- ings of the 40th International Conference on Machine Learning (ICML). JMLR, 2023
work page 2023
-
[3]
T. Nayan, Q. Guo, M. A. Duniawi, M. Botacin, S. Uluagac, and R. Sun, “SoK: All you need to know about On-Device ML model extraction - the gap between research and practice,” in33rd USENIX Security Symposium (USENIX Security 24). Philadelphia, PA: USENIX Association, Aug. 2024, pp. 5233–5250. [Online]. Available: https://www.usenix.org/conference/usenixsec...
work page 2024
-
[4]
Exploring chatgpt app ecosystem: Distribution, deployment and security,
C. Yan, R. Ren, M. H. Meng, L. Wan, T. Y . Ooi, and G. Bai, “Exploring chatgpt app ecosystem: Distribution, deployment and security,” inPro- ceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, 2024, pp. 1370–1382
work page 2024
-
[5]
Catch-only-one: Non-transferable examples for model- specific authorization,
Z. Wang, Z. Ma, Z. Ma, S. Liu, A. Liu, D. Wang, M. Xue, and G. Bai, “Catch-only-one: Non-transferable examples for model- specific authorization,” 2025. [Online]. Available: https://arxiv.org/abs/ 2510.10982
-
[6]
Training dnn model with secret key for model protection,
A. Pyone, M. Maung, and H. Kiya, “Training dnn model with secret key for model protection,” in2020 IEEE 9th Global Conference on Consumer Electronics (GCCE), 2020, pp. 818–821
work page 2020
-
[7]
Protect your deep neural networks from piracy,
M. Chen and M. Wu, “Protect your deep neural networks from piracy,” in2018 IEEE International Workshop on Information Forensics and Security (WIFS), 2018, pp. 1–7
work page 2018
-
[8]
M. Xue, Z. Wu, Y . Zhang, J. Wang, and W. Liu, “AdvParams: An active DNN intellectual property protection technique via adversarial pertur- bation based parameter encryption,”IEEE Transactions on Emerging Topics in Computing, vol. 11, no. 3, pp. 664–678, 2023
work page 2023
-
[9]
Corelocker: Neuron-level usage control,
Z. Wang, Z. Ma, X. Feng, R. Sun, H. Wang, M. Xue, and G. Bai, “Corelocker: Neuron-level usage control,” in2024 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, 2024, pp. 2497– 2514
work page 2024
-
[10]
Generative ai statistics: Insights and emerging trends for 2025,
M. Malec, “Generative ai statistics: Insights and emerging trends for 2025,” December 2024. [Online]. Available: https://hatchworks.com/ blog/gen-ai/generative-ai-statistics/
work page 2025
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”9th International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[12]
A probabilistic approach to neural network pruning,
X. Qian and D. Klabjan, “A probabilistic approach to neural network pruning,” inInternational Conference on Machine Learning (ICML). PMLR, 2021, pp. 8640–8649. 14
work page 2021
-
[13]
What is the state of neural network pruning?
D. Blalock, J. J. Gonzalez Ortiz, J. Frankle, and J. Guttag, “What is the state of neural network pruning?”Proceedings of machine learning and systems, vol. 2, pp. 129–146, 2020
work page 2020
-
[14]
Chaotic weights: A novel approach to protect intellectual property of deep neural networks,
N. Lin, X. Chen, H. Lu, and X. Li, “Chaotic weights: A novel approach to protect intellectual property of deep neural networks,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 40, no. 7, pp. 1327–1339, 2021
work page 2021
-
[15]
Explaining and harnessing adversarial examples,
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” inInternational Conference on Learning Repre- sentations (ICLR), 2015
work page 2015
-
[16]
Adversarial examples: Attacks and defenses for deep learning,
X. Yuan, P. He, Q. Zhu, and X. Li, “Adversarial examples: Attacks and defenses for deep learning,”IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 9, pp. 2805–2824, 2019
work page 2019
-
[17]
Hardware-assisted intel- lectual property protection of deep learning models,
A. Chakraborty, A. Mondai, and A. Srivastava, “Hardware-assisted intel- lectual property protection of deep learning models,” in57th ACM/IEEE Design Automation Conference (DAC). IEEE, 2020, pp. 1–6
work page 2020
-
[18]
Z. Sun, R. Sun, C. Liu, A. R. Chowdhury, L. Lu, and S. Jha, “Shad- ownet: A secure and efficient on-device model inference system for convolutional neural networks,” in2023 IEEE Symposium on Security and Privacy (IEEE S&P), 2023, pp. 1596–1612
work page 2023
-
[19]
Pruning Filters for Efficient ConvNets
H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf, “Pruning filters for efficient convnets,”arXiv preprint arXiv:1608.08710, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Pruning convolutional neural networks for resource efficient inference,
P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz, “Pruning convolutional neural networks for resource efficient inference,” inIn- ternational Conference on Learning Representations (ICLR), 2017
work page 2017
-
[21]
Robustness-aware filter pruning for robust neural networks against adversarial attacks,
H. Lim, S.-D. Roh, S. Park, and K.-S. Chung, “Robustness-aware filter pruning for robust neural networks against adversarial attacks,” in2021 IEEE 31st International Workshop on Machine Learning for Signal Processing (MLSP), 2021, pp. 1–6
work page 2021
-
[22]
Vershynin,High-dimensional probability: An introduction with ap- plications in data science
R. Vershynin,High-dimensional probability: An introduction with ap- plications in data science. Cambridge University Press, 2018, vol. 47
work page 2018
-
[23]
Proving the lottery ticket hypothesis: Pruning is all you need,
E. Malach, G. Yehudai, S. Shalev-Schwartz, and O. Shamir, “Proving the lottery ticket hypothesis: Pruning is all you need,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 6682–6691
work page 2020
-
[24]
The mnist database of handwritten digit images for machine learning research,
L. Deng, “The mnist database of handwritten digit images for machine learning research,”IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 141–142, 2012
work page 2012
-
[25]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms,”arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
work page 2009
-
[27]
Caltech-256 object category dataset,
G. Griffin, A. Holub, P. Peronaet al., “Caltech-256 object category dataset,” Technical Report 7694, California Institute of Technology Pasadena, Tech. Rep., 2007
work page 2007
-
[28]
Automated flower classification over a large number of classes,
M.-E. Nilsback and A. Zisserman, “Automated flower classification over a large number of classes,” in2008 Sixth Indian conference on computer vision, graphics & image processing. IEEE, 2008, pp. 722–729
work page 2008
-
[29]
Glue: A multi-task benchmark and analysis platform for natural language understanding,
A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bow- man, “Glue: A multi-task benchmark and analysis platform for natural language understanding,” in7th International Conference on Learning Representations, ICLR 2019, 2019
work page 2019
-
[30]
The stanford sentiment treebank,
R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Y . Ng, and C. Potts, “The stanford sentiment treebank,”Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1631–1642, 2013
work page 2013
-
[31]
TweetEval: Unified benchmark and comparative evaluation for tweet classification,
F. Barbieri, J. Camacho-Collados, L. Espinosa Anke, and L. Neves, “TweetEval: Unified benchmark and comparative evaluation for tweet classification,” inFindings of the Association for Computational Linguistics: EMNLP 2020, T. Cohn, Y . He, and Y . Liu, Eds. Online: Association for Computational Linguistics, Nov. 2020, pp. 1644–1650. [Online]. Available: h...
work page 2020
-
[32]
Character-level convolutional net- works for text classification,
X. Zhang, J. Zhao, and Y . LeCun, “Character-level convolutional net- works for text classification,”Advances in neural information processing systems, vol. 28, 2015
work page 2015
-
[33]
Watermarking deep neural networks for embedded systems,
J. Guo and M. Potkonjak, “Watermarking deep neural networks for embedded systems,” in2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2018, pp. 1–8
work page 2018
-
[34]
Embedding water- marks into deep neural networks,
Y . Uchida, Y . Nagai, S. Sakazawa, and S. Satoh, “Embedding water- marks into deep neural networks,” inProceedings of ACM on Interna- tional Conference on Multimedia Retrieval (ICMR), 2017, p. 269–277
work page 2017
-
[35]
Watermarking techniques for intellectual property protection,
A. B. Kahng, J. Lach, W. H. Mangione-Smith, S. Mantik, I. L. Markov, M. Potkonjak, P. Tucker, H. Wang, and G. Wolfe, “Watermarking techniques for intellectual property protection,” inProceedings of the 35th Annual Design Automation Conference (DAC), 1998, pp. 776–781
work page 1998
-
[36]
Data hiding with deep learning: A survey unifying digital watermarking and steganography,
Z. Wang, O. Byrnes, H. Wang, R. Sun, C. Ma, H. Chen, Q. Wu, and M. Xue, “Data hiding with deep learning: A survey unifying digital watermarking and steganography,”IEEE Transactions on Computational Social Systems, 2023
work page 2023
-
[37]
Ai model modulation with logits redistribution,
Z. Wang, Z. Ma, X. Feng, Z. Mei, E. Ma, D. Wang, M. Xue, and G. Bai, “Ai model modulation with logits redistribution,” inProceedings of the ACM on Web Conference 2025, ser. WWW ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 4699–4709. [Online]. Available: https://doi.org/10.1145/3696410.3714737
-
[38]
L. Fan, K. W. Ng, and C. S. Chan, “Rethinking deep neural net- work ownership verification: Embedding passports to defeat ambigu- ity attacks,” inAdvances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[39]
Trustzone explained: Architectural features and use cases,
B. Ngabonziza, D. Martin, A. Bailey, H. Cho, and S. Martin, “Trustzone explained: Architectural features and use cases,” in2016 IEEE 2nd International Conference on Collaboration and Internet Computing (CIC). IEEE, 2016, pp. 445–451
work page 2016
-
[40]
Tzslicer: Security- aware dynamic program slicing for hardware isolation,
M. Ye, J. Sherman, W. Srisa-An, and S. Wei, “Tzslicer: Security- aware dynamic program slicing for hardware isolation,” in2018 IEEE International Symposium on Hardware Oriented Security and Trust (HOST). IEEE, 2018, pp. 17–24
work page 2018
-
[41]
Deepattest: an end-to-end attestation framework for deep neural networks,
H. Chen, C. Fu, B. D. Rouhani, J. Zhao, and F. Koushanfar, “Deepattest: an end-to-end attestation framework for deep neural networks,” in 2019 ACM/IEEE 46th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2019, pp. 487–498
work page 2019
-
[42]
Z. Sun, R. Sun, C. Liu, A. Chowdhury, L. Lu, and S. Jha, “Shadownet: A secure and efficient on-device model inference system for convolutional neural networks,” in2023 IEEE Symposium on Security and Privacy (SP), 2023, pp. 1489–1505
work page 2023
-
[43]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
work page 2016
-
[44]
Partial is better than all: Revisiting fine-tuning strategy for few-shot learning,
Z. Shen, Z. Liu, J. Qin, M. Savvides, and K.-T. Cheng, “Partial is better than all: Revisiting fine-tuning strategy for few-shot learning,” in Proceedings of the AAAI conference on artificial intelligence, vol. 35, no. 11, 2021, pp. 9594–9602
work page 2021
-
[45]
Partial fine-tuning: A successor to full fine-tuning for vision transformers,
P. Ye, Y . Huang, C. Tu, M. Li, T. Chen, T. He, and W. Ouyang, “Partial fine-tuning: A successor to full fine-tuning for vision transformers,” arXiv preprint arXiv:2312.15681, 2023
-
[46]
St-adapter: Parameter- efficient image-to-video transfer learning,
J. Pan, Z. Lin, X. Zhu, J. Shao, and H. Li, “St-adapter: Parameter- efficient image-to-video transfer learning,”Advances in Neural Infor- mation Processing Systems, vol. 35, pp. 26 462–26 477, 2022
work page 2022
-
[47]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[48]
Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models, 2022
E. B. Zaken, S. Ravfogel, and Y . Goldberg, “Bitfit: Simple parameter- efficient fine-tuning for transformer-based masked language-models,” arXiv preprint arXiv:2106.10199, 2021. 15 APPENDIX ETHICSCONSIDERATIONS This research focuses on developing a framework for se- curely updating AI models under strict usage control. It relies solely on open-source dat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.