Understanding Task Transfer in Vision-Language Models
Pith reviewed 2026-05-17 06:49 UTC · model grok-4.3
The pith
Finetuning a vision-language model on one perception task produces measurable positive or negative effects on others that can be mapped into a transfer graph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
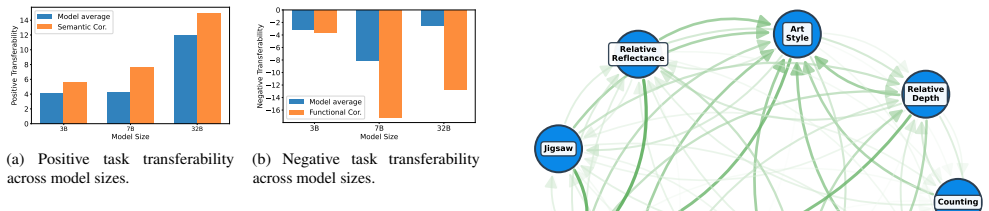
Using the Perfection Gap Factor to normalize performance changes after finetuning and computing Task Transferability to capture both scope and size of those changes, the authors build a task transfer graph from three VLMs evaluated on thirteen perception tasks; the graph reveals previously unobserved patterns of positive and negative transfer, identifies groups of tasks that mutually influence each other, organizes tasks into personas according to their transfer signatures, and demonstrates that the same metric can guide data selection for more efficient model training.
What carries the argument
The task transfer graph, constructed from Perfection Gap Factor scores that measure normalized performance change after finetuning on a source task and Task Transferability scores that combine breadth and magnitude of those changes.
If this is right
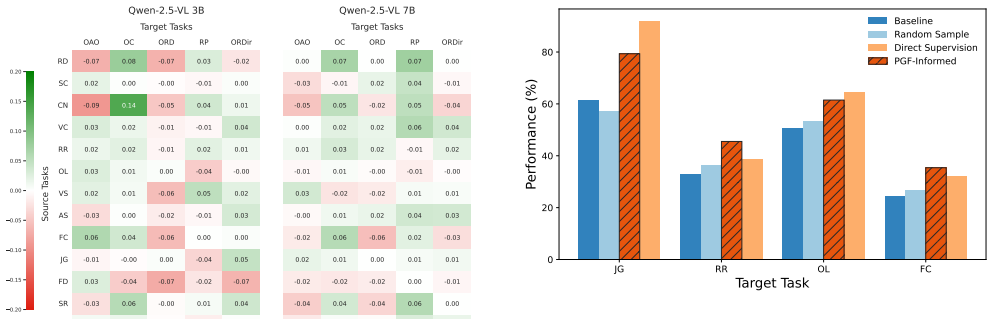
- Selecting a source task with high positive transferability to a target task can improve zero-shot performance without additional labels for the target.
- Avoiding source tasks that produce negative transfer can prevent unintended performance drops on related perception skills.
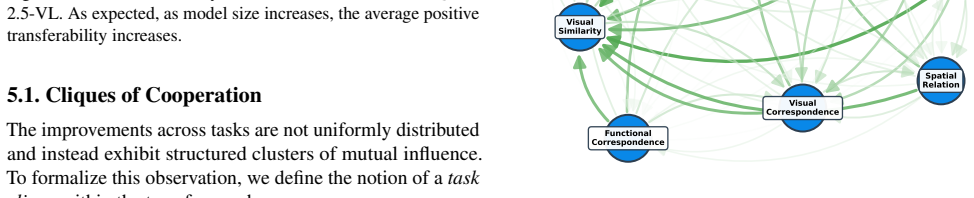
- Tasks that form mutual-influence clusters can be trained together to exploit synergies rather than trained in isolation.
- Persona groupings derived from transfer behavior allow models to be specialized for families of related perception tasks rather than for single tasks.
- PGF-based data selection can reduce the total number of finetuning examples needed while preserving or increasing average performance across the task set.
Where Pith is reading between the lines
- The transfer graph implies that many perception tasks share latent visual features inside current VLMs, so mapping more tasks onto the same graph could reveal larger organizing principles.
- If the patterns persist at larger model scales, practitioners could maintain a shared transfer database to choose pre-training or instruction-tuning data without exhaustive search.
- Extending the graph to include generative or reasoning tasks would test whether the same positive and negative interference rules apply outside pure perception.
- The persona classification could be used to design curricula that progress from low-interference to high-synergy task sequences during continued training.
Load-bearing premise
The thirteen chosen perception tasks and the three open-weight models are representative enough that the observed transfer patterns will hold for other tasks and other models.
What would settle it
Running the identical finetuning and evaluation protocol on a new set of perception tasks or on additional VLMs and obtaining transfer relationships that bear no structural resemblance to the published graph.
Figures





read the original abstract
Vision-Language Models (VLMs) perform well on multimodal benchmarks but lag behind humans and specialized models on visual perception tasks like depth estimation or object counting. Finetuning on one task can unpredictably affect performance on others, making task-specific finetuning challenging. In this paper, we address this challenge through a systematic study of task transferability. We examine how finetuning a VLM on one perception task affects its zero-shot performance on others. We introduce Perfection Gap Factor (PGF), a normalized metric that measures change in performance as a result of task transfer. We utilize PGF to compute Task Transferability, which captures both the breadth and the magnitude of transfer induced by a source task. Using three open-weight VLMs evaluated across 13 perception tasks, we construct a task transfer graph that reveals previously unobserved relationships among perception tasks. Our analysis uncovers patterns of positive and negative transfer, identifies groups of tasks that mutually influence each other, organizes tasks into personas based on their transfer behavior and demonstrates how PGF can guide data selection for more efficient training. These findings highlight both opportunities for positive transfer and risks of negative interference, offering actionable guidance for advancing VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study of task transfer in vision-language models. It finetunes three open-weight VLMs on each of 13 perception tasks, measures zero-shot performance changes on the remaining tasks, and introduces the Perfection Gap Factor (PGF) as a normalized metric of performance delta. From these measurements the authors compute Task Transferability scores, construct a task transfer graph, and report patterns of positive/negative transfer, mutually influencing task clusters, task 'personas,' and potential uses of PGF for data selection.
Significance. If the observed transfer patterns prove robust beyond the chosen models and tasks, the work would supply a practical framework for understanding inter-task interference and synergies in VLM finetuning, with direct implications for more efficient training regimes. The introduction of PGF and the graph-based analysis constitute a concrete, falsifiable contribution to the study of multimodal transfer.
major comments (2)
- [§5] §5 (Experimental Setup and Results): The task transfer graph and all derived claims about previously unobserved relationships, clusters, and personas rest on evaluations using only three open-weight VLMs and a fixed collection of 13 perception tasks. No sensitivity analysis, ablation on model family, or resampling of tasks is reported; therefore it remains possible that the reported positive/negative transfers and mutual-influence structure are artifacts of this narrow experimental slice rather than stable properties of perception tasks in VLMs.
- [§3.2] §3.2 (Definition of PGF): The Perfection Gap Factor is introduced as a normalized metric of performance change, yet the manuscript provides neither the exact formula relating PGF to raw accuracy deltas nor any demonstration that the normalization is independent of the choice of zero-shot baseline. Because Task Transferability is computed directly from PGF values, any dependence on post-hoc baseline selection would propagate into the graph and undermine the central empirical claims.
minor comments (3)
- [Abstract] The abstract refers to 'task personas' without a one-sentence definition or illustrative example; a brief clarification would improve readability for readers unfamiliar with the concept.
- [Figures] Figure captions and axis labels for the task transfer graph should explicitly indicate how edge weights or colors encode positive versus negative transfer to make the reported patterns immediately verifiable from the figure.
- [§4] A short table listing the 13 perception tasks together with their source datasets and evaluation metrics would help readers assess the diversity of the task set.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [§5] §5 (Experimental Setup and Results): The task transfer graph and all derived claims about previously unobserved relationships, clusters, and personas rest on evaluations using only three open-weight VLMs and a fixed collection of 13 perception tasks. No sensitivity analysis, ablation on model family, or resampling of tasks is reported; therefore it remains possible that the reported positive/negative transfers and mutual-influence structure are artifacts of this narrow experimental slice rather than stable properties of perception tasks in VLMs.
Authors: We agree that the experimental scope is limited to three open-weight VLMs and 13 perception tasks, and that the absence of sensitivity analysis or task resampling leaves open the possibility that some observed patterns could be specific to this selection. Our choice of models and tasks was driven by the need for computational tractability while covering a broad range of visual perception capabilities. In the revised manuscript we will add an explicit limitations subsection that discusses the scope of the reported transfer graph and clusters, and we will include a small-scale sensitivity check (e.g., one additional model or a subset of tasks) where feasible. We view this as a partial revision that clarifies rather than fully eliminates the concern. revision: partial
-
Referee: [§3.2] §3.2 (Definition of PGF): The Perfection Gap Factor is introduced as a normalized metric of performance change, yet the manuscript provides neither the exact formula relating PGF to raw accuracy deltas nor any demonstration that the normalization is independent of the choice of zero-shot baseline. Because Task Transferability is computed directly from PGF values, any dependence on post-hoc baseline selection would propagate into the graph and undermine the central empirical claims.
Authors: We will revise Section 3.2 to state the precise mathematical definition of PGF, explicitly showing its relation to raw accuracy deltas and the zero-shot baseline. We will also add a short robustness analysis (main text or appendix) that recomputes Task Transferability under alternative baseline choices and confirms that the resulting graph structure and rankings remain stable. This constitutes a full revision of the presentation and supporting evidence for the metric. revision: yes
Circularity Check
No circularity: PGF and task transferability are direct empirical computations from measured performance deltas
full rationale
The paper defines Perfection Gap Factor (PGF) explicitly as a normalized metric on observed performance changes after finetuning, then derives Task Transferability and the transfer graph by applying this metric to results from 13 tasks across 3 VLMs. This is a data-driven construction with no reduction of outputs to inputs by definition, no fitted parameters renamed as predictions, and no load-bearing self-citations or imported uniqueness theorems. The derivation chain remains self-contained against the experimental measurements; representativeness concerns affect generalizability but do not create circularity in the reported steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Zero-shot performance on a target task can be measured after fine-tuning on a source task without confounding effects from prompt or evaluation protocol changes.
invented entities (2)
-
Perfection Gap Factor (PGF)
no independent evidence
-
Task Transferability
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tal- lyqa: Answering complex counting questions, 2018
Manoj Acharya, Kushal Kafle, and Christopher Kanan. Tal- lyqa: Answering complex counting questions, 2018. 21
work page 2018
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Hpatches: A benchmark and evaluation of hand- crafted and learned local descriptors
Vassileios Balntas, Karel Lenc, Andrea Vedaldi, and Krystian Mikolajczyk. Hpatches: A benchmark and evaluation of hand- crafted and learned local descriptors. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5173–5182, 2017. 21
work page 2017
-
[4]
An information- 8 theoretic approach to transferability in task transfer learning,
Yajie Bao, Yang Li, Shao-Lun Huang, Lin Zhang, Lizhong Zheng, Amir Zamir, and Leonidas Guibas. An information- 8 theoretic approach to transferability in task transfer learning,
-
[5]
Intrinsic images in the wild.ACM Transactions on Graphics (TOG), 33(4): 1–12, 2014
Sean Bell, Kavita Bala, and Noah Snavely. Intrinsic images in the wild.ACM Transactions on Graphics (TOG), 33(4): 1–12, 2014. 21
work page 2014
-
[6]
Tianwei Chen, Noa Garcia, Mayu Otani, Chenhui Chu, Yuta Nakashima, and Hajime Nagahara. Learning more may not be better: Knowledge transferability in vision-and-language tasks.Journal of Imaging, 10(12):300, 2024. 2, 3
work page 2024
-
[7]
Weifeng Chen, Zhao Fu, Dawei Yang, and Jia Deng. Single- image depth perception in the wild.Advances in neural information processing systems, 29, 2016. 21
work page 2016
-
[8]
Qlora: Efficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in neural information processing systems, 36:10088– 10115, 2023. 3
work page 2023
-
[9]
Dreamsim: Learning new dimensions of human visual similarity using synthetic data
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dreamsim: Learning new dimensions of human visual similarity using synthetic data. InAdvances in Neural Information Processing Systems, pages 50742–50768, 2023. 21
work page 2023
-
[10]
There’s a Time and Place for Rea- soning Beyond the Image
Xingyu Fu, Ben Zhou, Ishaan Preetam Chandratreya, Carl V ondrick, and Dan Roth. There’s a Time and Place for Rea- soning Beyond the Image. InProc. of the Annual Meeting of the Association for Computational Linguistics (ACL), 2022. 21
work page 2022
-
[11]
Blink: Multimodal large language mod- els can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language mod- els can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024. 1, 3, 4
work page 2024
-
[12]
Yang Fu and Xiaolong Wang. Category-level 6d object pose estimation in the wild: A semi-supervised learning approach and a new dataset. InAdvances in Neural Information Pro- cessing Systems, 2022. 21
work page 2022
-
[13]
Lvis: A dataset for large vocabulary instance segmentation, 2019
Agrim Gupta, Piotr Dollár, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation, 2019. 2, 21
work page 2019
-
[14]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine-tuning for large models: A comprehensive survey.arXiv preprint arXiv:2403.14608,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
-
[16]
Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning
Maggie Huan, Yuetai Li, Tuney Zheng, Xiaoyu Xu, Seun- gone Kim, Minxin Du, Radha Poovendran, Graham Neubig, and Xiang Yue. Does math reasoning improve general llm capabilities? understanding transferability of llm reasoning. arXiv preprint arXiv:2507.00432, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[17]
The functional correspondence problem
Zihang Lai, Senthil Purushwalkam, and Abhinav Gupta. The functional correspondence problem. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15772–15781, 2021. 21
work page 2021
-
[18]
Llava-onevision: Easy visual task transfer, 2024
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer, 2024. 1
work page 2024
-
[19]
Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models, 2024
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models, 2024. 1
work page 2024
-
[20]
Lawrence Zitnick, and Piotr Dollár
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bour- dev, Ross Girshick, James Hays, Pietro Perona, Deva Ra- manan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015. 2, 21
work page 2015
-
[21]
Visual spatial reasoning.Transactions of the Association for Computational Linguistics, 2023
Fangyu Liu, Guy Edward Toh Emerson, and Nigel Collier. Visual spatial reasoning.Transactions of the Association for Computational Linguistics, 2023. 21
work page 2023
-
[22]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems, pages 34892–34916. Curran Associates, Inc., 2023. 1
work page 2023
-
[23]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 1
work page 2024
-
[24]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathemati- cal reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning,
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning,
- [26]
-
[27]
Minesh Mathew, Dimosthenis Karatzas, and C. V . Jawahar. Docvqa: A dataset for vqa on document images, 2021. 1, 2
work page 2021
-
[28]
Spair- 71k: A large-scale benchmark for semantic correspondence,
Juhong Min, Jongmin Lee, Jean Ponce, and Minsu Cho. Spair- 71k: A large-scale benchmark for semantic correspondence,
-
[29]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1
work page 2021
-
[30]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yux- iong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. InPro- ceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 3505–3506,
-
[31]
M Moein Shariatnia, Rahim Entezari, Mitchell Wortsman, Olga Saukh, and Ludwig Schmidt. How well do contrastively trained models transfer? InFirst Workshop on Pre-training: Perspectives, Pitfalls, and Paths Forward at ICML 2022, 2022. 2, 3
work page 2022
-
[32]
Towards vqa models that can read, 2019
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read, 2019. 1
work page 2019
-
[33]
Anthony Meng Huat Tiong, Junqi Zhao, Boyang Li, Jun- nan Li, Steven CH Hoi, and Caiming Xiong. What are 9 we measuring when we evaluate large vision-language mod- els? an analysis of latent factors and biases.arXiv preprint arXiv:2404.02415, 2024. 2, 3
-
[34]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9568–9578, 2024. 1
work page 2024
-
[35]
Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, 2024
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, 2024. 1, 4
work page 2024
-
[36]
A surprising failure? multimodal llms and the nlvr challenge, 2024
Anne Wu, Kianté Brantley, and Yoav Artzi. A surprising failure? multimodal llms and the nlvr challenge, 2024. 2
work page 2024
-
[37]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025. 6
work page 2025
-
[38]
Mmmu: A massive multi-discipline multi- modal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multi- modal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556–9567, 2024. 1, 2
work page 2024
-
[39]
Taskonomy: Disentangling task transfer learning
Amir R Zamir, Alexander Sax, William Shen, Leonidas J Guibas, Jitendra Malik, and Silvio Savarese. Taskonomy: Disentangling task transfer learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3712–3722, 2018. 2, 3
work page 2018
-
[40]
From recognition to cognition: Visual commonsense reason- ing
Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. From recognition to cognition: Visual commonsense reason- ing. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 2 10 Understanding Task Transfer in Vision-Language Models Supplementary Material Table of Contents A.8. PGF Calculation and Heatmaps . . . . . . . . . . . ....
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.