The More, the Merrier: Contrastive Fusion for Higher-Order Multimodal Alignment
Pith reviewed 2026-05-17 05:00 UTC · model grok-4.3
The pith
Contrastive Fusion aligns individual modalities with their fused combinations to capture higher-order dependencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
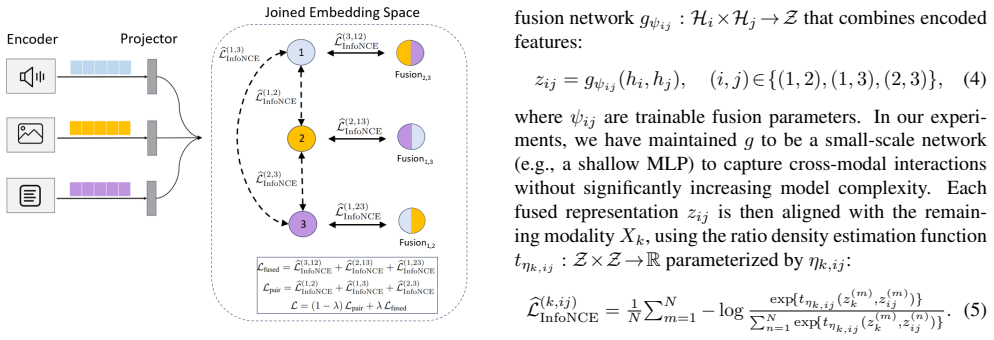
ConFu extends traditional pairwise contrastive objectives with an additional fused-modality contrastive term, encouraging the joint embedding of modality pairs with a third modality. This formulation enables ConFu to capture higher-order dependencies, such as XOR-like relationships, that cannot be recovered through pairwise alignment alone, while still maintaining strong pairwise correspondence.
What carries the argument
Contrastive Fusion (ConFu), a framework that embeds both individual modalities and their fused combinations into a unified representation space and aligns them through an added fused-modality contrastive term.
If this is right
- Enables unified one-to-one and two-to-one retrieval within a single contrastive framework.
- Maintains competitive performance on retrieval and classification while capturing cross-modal complementarity.
- Captures higher-order dependencies that pairwise alignment alone cannot recover.
- Scales with increasing multimodal complexity on both synthetic and real-world benchmarks.
Where Pith is reading between the lines
- The same fused-term idea could be applied to settings with four or more modalities to test whether even richer interactions become accessible.
- A single trained model might replace separate pairwise and multi-way retrieval pipelines in deployed multimodal systems.
- Similar extensions of contrastive objectives could be tried in self-supervised vision or language models where fusion of views is already common.
- The approach suggests a general template for adding higher-order terms without breaking existing pairwise fidelity.
Load-bearing premise
The additional fused-modality contrastive term successfully encodes higher-order interactions without requiring specific fusion operators or post-hoc adjustments that might not generalize beyond the evaluated benchmarks.
What would settle it
On synthetic data constructed with explicit higher-order XOR dependencies, ConFu shows no retrieval or classification gain over a standard pairwise contrastive baseline.
Figures












read the original abstract
Learning joint representations across multiple modalities remains a central challenge in multimodal machine learning. Prevailing approaches predominantly operate in pairwise settings, aligning two modalities at a time. While some recent methods aim to capture higher-order interactions among multiple modalities, they often overlook or insufficiently preserve pairwise relationships, limiting their effectiveness on single-modality tasks. In this work, we introduce Contrastive Fusion (ConFu), a framework that jointly embeds both individual modalities and their fused combinations into a unified representation space, where modalities and their fused counterparts are aligned. ConFu extends traditional pairwise contrastive objectives with an additional fused-modality contrastive term, encouraging the joint embedding of modality pairs with a third modality. This formulation enables ConFu to capture higher-order dependencies, such as XOR-like relationships, that cannot be recovered through pairwise alignment alone, while still maintaining strong pairwise correspondence. We evaluate ConFu on synthetic and real-world multimodal benchmarks, assessing its ability to exploit cross-modal complementarity, capture higher-order dependencies, and scale with increasing multimodal complexity. Across these settings, ConFu demonstrates competitive performance on retrieval and classification tasks, while supporting unified one-to-one and two-to-one retrieval within a single contrastive framework. We release our code and dataset at https://github.com/estafons/confu.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Contrastive Fusion (ConFu), a multimodal alignment framework that extends standard pairwise contrastive objectives with an additional fused-modality contrastive term. This term aligns modality pairs with a third modality in a unified embedding space, with the stated goal of capturing higher-order dependencies (e.g., XOR-like relations) that pairwise methods cannot recover, while preserving strong pairwise performance. The approach is evaluated on synthetic and real-world multimodal benchmarks for retrieval and classification tasks, including unified one-to-one and two-to-one retrieval, with code and data released.
Significance. If the fused term demonstrably encodes irreducible higher-order interactions beyond what can be recovered from summed pairwise InfoNCE losses, the method could meaningfully advance multimodal representation learning by balancing higher-order complementarity with pairwise fidelity. The public release of code and dataset supports reproducibility and further testing of the higher-order claim.
major comments (3)
- [§3] §3 (Method), fused-modality contrastive term: The central claim that this term captures XOR-like higher-order dependencies unrecoverable by pairwise alignment alone is load-bearing. The abstract and high-level description state that the term 'encourages the joint embedding of modality pairs with a third modality,' but without an explicit equation for the fusion operator (concatenation, element-wise product, attention, etc.) and the resulting loss, it is unclear whether the composite objective introduces non-pairwise statistics or simply reweights existing pairwise signals. A concrete derivation or proof sketch showing that the fused term induces irreducible triple-wise mutual information would be required.
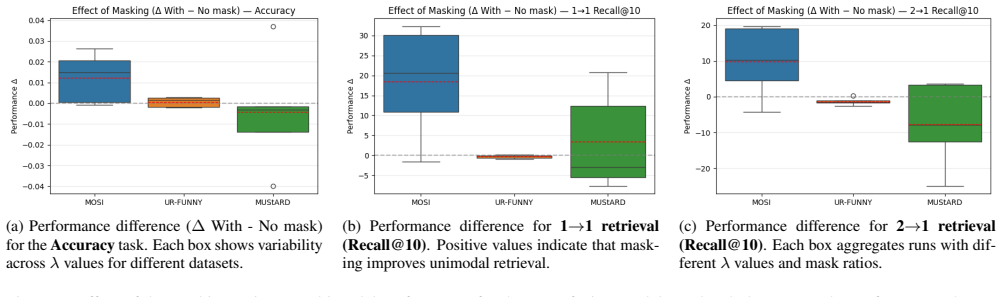
- [§4.1] §4.1 (Synthetic experiments), XOR-like dependency tests: The paper asserts that ConFu captures higher-order relations 'that cannot be recovered through pairwise alignment alone.' However, if the fusion operator is linear or element-wise, any observed gain on synthetic XOR tasks could be an artifact of the particular fusion chosen rather than a property of the contrastive objective. An ablation replacing the fused term with an equivalent sum of pairwise terms (or reporting the effective rank of the interaction) is needed to substantiate the claim.
- [§4.2] §4.2–4.3 (Real-world benchmarks), scaling with multimodal complexity: The evaluation claims ConFu scales with increasing numbers of modalities and supports two-to-one retrieval. It is unclear whether the reported gains on retrieval and classification hold after controlling for the total number of contrastive pairs or the effective batch size introduced by the fused term. A controlled comparison that matches the number of negative samples across baselines would strengthen the scaling claim.
minor comments (3)
- [§3] Notation for the fused embedding (e.g., how f(m_i, m_j) is defined) should be introduced earlier and used consistently in the loss equations.
- [Figure 2] Figure 2 (or equivalent diagram of the ConFu architecture) would benefit from explicit arrows or labels showing which pairs participate in the fused contrastive term versus the standard pairwise terms.
- [Abstract] The abstract mentions 'synthetic and real-world multimodal benchmarks' but does not list the exact datasets or tasks in the first paragraph; adding this would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications and indicating the revisions we will implement to address the concerns raised.
read point-by-point responses
-
Referee: [§3] §3 (Method), fused-modality contrastive term: The central claim that this term captures XOR-like higher-order dependencies unrecoverable by pairwise alignment alone is load-bearing. The abstract and high-level description state that the term 'encourages the joint embedding of modality pairs with a third modality,' but without an explicit equation for the fusion operator (concatenation, element-wise product, attention, etc.) and the resulting loss, it is unclear whether the composite objective introduces non-pairwise statistics or simply reweights existing pairwise signals. A concrete derivation or proof sketch showing that the fused term induces irreducible triple-wise mutual information would be required.
Authors: We concur that the method section would benefit from more explicit mathematical details. In the revised manuscript, we will add the precise definition of the fusion operator, which involves concatenating the embeddings of the modality pair and applying a linear projection to obtain the fused representation, along with the complete formulation of the fused-modality contrastive loss. We will also include a short illustrative derivation demonstrating that the fused term can encode joint dependencies not captured by pairwise terms in the context of the XOR example. However, a general proof of inducing irreducible triple-wise mutual information is a deeper theoretical issue that we will note as a direction for future work rather than claim to fully resolve here. revision: partial
-
Referee: [§4.1] §4.1 (Synthetic experiments), XOR-like dependency tests: The paper asserts that ConFu captures higher-order relations 'that cannot be recovered through pairwise alignment alone.' However, if the fusion operator is linear or element-wise, any observed gain on synthetic XOR tasks could be an artifact of the particular fusion chosen rather than a property of the contrastive objective. An ablation replacing the fused term with an equivalent sum of pairwise terms (or reporting the effective rank of the interaction) is needed to substantiate the claim.
Authors: This is a valuable suggestion to bolster the empirical support for our claims. We will incorporate an ablation experiment in the updated version of the paper. Specifically, we will compare ConFu against a variant where the fused term is substituted by an additional sum of pairwise contrastive losses, and report the results on the synthetic XOR dependency tests to show that the performance improvement is attributable to the fused objective rather than just increased pairwise signals. revision: yes
-
Referee: [§4.2] §4.2–4.3 (Real-world benchmarks), scaling with multimodal complexity: The evaluation claims ConFu scales with increasing numbers of modalities and supports two-to-one retrieval. It is unclear whether the reported gains on retrieval and classification hold after controlling for the total number of contrastive pairs or the effective batch size introduced by the fused term. A controlled comparison that matches the number of negative samples across baselines would strengthen the scaling claim.
Authors: We agree that ensuring fair comparison in terms of computational resources is important. In the revised manuscript, we will add a set of controlled experiments where the total number of negative samples is matched between ConFu and the baseline methods by appropriately scaling the batch sizes or the number of negatives sampled. This will allow us to confirm that the observed gains in retrieval and classification tasks are not solely due to the additional contrastive pairs introduced by the fused term. revision: yes
- A complete theoretical derivation proving that the fused-modality contrastive term induces irreducible triple-wise mutual information that cannot be recovered from pairwise terms.
Circularity Check
No significant circularity detected
full rationale
The paper defines ConFu as an explicit extension of standard pairwise contrastive losses by adding a fused-modality term, then evaluates the resulting model on synthetic and real benchmarks. No step in the provided abstract or described framework reduces a claimed higher-order capability to a quantity fitted from the same evaluation data, nor does any load-bearing premise rest on a self-citation chain that itself lacks independent verification. The derivation remains self-contained: the loss is stated, the fusion is introduced as part of the method, and performance is measured externally.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contrastive loss functions can produce semantically meaningful joint embeddings when applied to paired multimodal data.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ConFu extends traditional pairwise contrastive objectives with an additional fused-modality contrastive term... bL(k,ij) InfoNCE ... L = (1-λ)Lpair + λLfused
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Towards Multimodal Sarcasm Detection (An _Obviously_ Perfect Paper)
Santiago Castro, Devamanyu Hazarika, Ver ´onica P ´erez- Rosas, Roger Zimmermann, Rada Mihalcea, and Sou- janya Poria. Towards multimodal sarcasm detec- tion (an obviously perfect paper).arXiv preprint arXiv:1906.01815, 2019. 5
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[2]
Mustafa Chasmai, Alexander Shepard, Subhransu Maji, and Grant Van Horn. The inaturalist sounds dataset.Advances in Neural Information Processing Systems, 37:132524– 132544, 2024. 4
work page 2024
-
[3]
Valor: Vision-audio-language omni-perception pretraining model and dataset,
Sihan Chen, Xingjian He, Longteng Guo, Xinxin Zhu, Wein- ing Wang, Jinhui Tang, and Jing Liu. Valor: Vision-audio- language omni-perception pretraining model and dataset. arXiv preprint arXiv:2304.08345, 2023. 2
-
[4]
Sihan Chen, Handong Li, Qunbo Wang, Zijia Zhao, Mingzhen Sun, Xinxin Zhu, and Jing Liu. Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset.Advances in Neural Information Processing Sys- tems, 36:72842–72866, 2023. 2
work page 2023
-
[5]
Gramian multimodal representation learning and alignment.arXiv preprint arXiv:2412.11959,
Giordano Cicchetti, Eleonora Grassucci, Luigi Sigillo, and Danilo Comminiello. Gramian multimodal representation learning and alignment.arXiv preprint arXiv:2412.11959,
-
[6]
Giordano Cicchetti, Eleonora Grassucci, and Danilo Com- miniello. A triangle enables multimodal alignment beyond cosine similarity.arXiv preprint arXiv:2509.24734, 2025. 2, 5, 6, 7, 8, 3
-
[7]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision- language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023. 5
work page 2023
-
[8]
What to align in multimodal con- trastive learning?arXiv preprint arXiv:2409.07402, 2024
Benoit Dufumier, Javiera Castillo-Navarro, Devis Tuia, and Jean-Philippe Thiran. What to align in multimodal con- trastive learning?arXiv preprint arXiv:2409.07402, 2024. 8
-
[9]
Exploit- ing temporal information for dcnn-based fine-grained object classification
ZongYuan Ge, Chris McCool, Conrad Sanderson, Peng Wang, Lingqiao Liu, Ian Reid, and Peter Corke. Exploit- ing temporal information for dcnn-based fine-grained object classification. In2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), pages 1–6. IEEE, 2016. 4, 5, 6
work page 2016
-
[10]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 15180–15190, 2023. 1, 2
work page 2023
-
[11]
Audioclip: Extending clip to image, text and au- dio
Andrey Guzhov, Federico Raue, J ¨orn Hees, and Andreas Dengel. Audioclip: Extending clip to image, text and au- dio. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 976–980. IEEE, 2022. 1, 2
work page 2022
-
[12]
Md Kamrul Hasan, Wasifur Rahman, Amir Zadeh, Jianyuan Zhong, Md Iftekhar Tanveer, Louis-Philippe Morency, et al. Ur-funny: A multimodal language dataset for understanding humor.arXiv preprint arXiv:1904.06618, 2019. 5
-
[13]
Reconboost: boosting can achieve modal- ity reconcilement
Cong Hua, Qianqian Xu, Shilong Bao, Zhiyong Yang, and Qingming Huang. Reconboost: boosting can achieve modal- ity reconcilement. InProceedings of the 41st International Conference on Machine Learning. JMLR.org, 2024. 8
work page 2024
-
[14]
Yu Huang, Junyang Lin, Chang Zhou, Hongxia Yang, and Longbo Huang. Modality competition: What makes joint training of multi-modal network fail in deep learn- ing?(provably). InInternational Conference on Machine Learning, pages 9226–9259. PMLR, 2022. 1, 7
work page 2022
-
[15]
Free spoken digit dataset.https : / / github
Zoran Jackson. Free spoken digit dataset.https : / / github . com / Jakobovski / free - spoken - digit-dataset, 2017. Accessed: YYYY-MM-DD. 6
work page 2017
-
[16]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR,
-
[17]
Balancing multimodal training through game-theoretic regularization
Konstantinos Kontras, Thomas Strypsteen, Christos Chatzichristos, Paul Pu Liang, Matthew B Blaschko, and Maarten De V os. Balancing multimodal training through game-theoretic regularization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. 8
-
[18]
Konstantinos Kontras, Christos Chatzichristos, Matthew B. Blaschko, and Maarten De V os. Improving multimodal learning with multi-loss gradient modulation. In35th British Machine Vision Conference 2024, BMVC 2024, Glasgow, UK, November 25-28, 2024. BMV A, 2024. 8
work page 2024
-
[19]
Multibench: Multiscale benchmarks for multimodal representation learning
Paul Pu Liang, Yiwei Lyu, Xiang Fan, Zetian Wu, Yun Cheng, Jason Wu, Leslie Yufan Chen, Peter Wu, Michelle A Lee, Yuke Zhu, et al. Multibench: Multiscale benchmarks for multimodal representation learning. InThirty-fifth Con- ference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), 2021. 5, 6
work page 2021
-
[20]
Paul Pu Liang, Zihao Deng, Martin Q Ma, James Y Zou, Louis-Philippe Morency, and Ruslan Salakhutdinov. Factor- ized contrastive learning: Going beyond multi-view redun- dancy.Advances in Neural Information Processing Systems, 36:32971–32998, 2023. 8, 1
work page 2023
-
[21]
Bryan Lim, Sercan ¨O Arık, Nicolas Loeff, and Tomas Pfister. Temporal fusion transformers for interpretable multi-horizon time series forecasting.International journal of forecasting, 37(4):1748–1764, 2021. 2
work page 2021
-
[22]
Umt: Unified multi-modal transformers for joint video moment retrieval and highlight detection
Ye Liu, Siyuan Li, Yang Wu, Chang-Wen Chen, Ying Shan, and Xiaohu Qie. Umt: Unified multi-modal transformers for joint video moment retrieval and highlight detection. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3042–3051, 2022. 2 9
work page 2022
-
[23]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 4
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Balanced multimodal learning via on-the-fly gradient modulation
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. Balanced multimodal learning via on-the-fly gradient modulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8238– 8247, 2022. 8
work page 2022
-
[25]
Karol J. Piczak. ESC: Dataset for Environmental Sound Classification. InProceedings of the 23rd Annual ACM Con- ference on Multimedia, pages 1015–1018. ACM Press. 5, 6
-
[26]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1
work page 2021
-
[27]
Contrasting with symile: Simple model- agnostic representation learning for unlimited modalities
Adriel Saporta, Aahlad Manas Puli, Mark Goldstein, and Ra- jesh Ranganath. Contrasting with symile: Simple model- agnostic representation learning for unlimited modalities. Advances in Neural Information Processing Systems, 37: 56919–56957, 2024. 2, 5, 6, 7, 8, 3
work page 2024
-
[28]
The multiinforma- tion function as a tool for measuring stochastic dependence
Milan Studen `y and Jirina Vejnarov ´a. The multiinforma- tion function as a tool for measuring stochastic dependence. InLearning in graphical models, pages 261–297. Springer,
-
[29]
Gemma Team. Gemma. 2024. 5
work page 2024
-
[30]
Exploring fine- grained audiovisual categorization with the ssw60 dataset
Grant Van Horn, Rui Qian, Kimberly Wilber, Hartwig Adam, Oisin Mac Aodha, and Serge Belongie. Exploring fine- grained audiovisual categorization with the ssw60 dataset. In European Conference on Computer Vision, pages 271–289. Springer, 2022. 4, 5, 6
work page 2022
-
[31]
Centralnet: a multilayer approach for mul- timodal fusion
Valentin Vielzeuf, Alexis Lechervy, St ´ephane Pateux, and Fr´ed´eric Jurie. Centralnet: a multilayer approach for mul- timodal fusion. InProceedings of the European conference on computer vision (ECCV) workshops, pages 0–0, 2018. 5
work page 2018
-
[32]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Per- ona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011. 4, 7
work page 2011
-
[33]
Decou- pling common and unique representations for multimodal self-supervised learning
Yi Wang, Conrad M Albrecht, Nassim Ait Ali Braham, Chenying Liu, Zhitong Xiong, and Xiao Xiang Zhu. Decou- pling common and unique representations for multimodal self-supervised learning. InEuropean Conference on Com- puter Vision, pages 286–303. Springer, 2024. 8
work page 2024
-
[34]
Zehan Wang, Yang Zhao, Haifeng Huang, Jiageng Liu, Aox- iong Yin, Li Tang, Linjun Li, Yongqi Wang, Ziang Zhang, and Zhou Zhao. Connecting multi-modal contrastive repre- sentations.Advances in Neural Information Processing Sys- tems, 36:22099–22114, 2023. 1, 8
work page 2023
-
[35]
Zehan Wang, Ziang Zhang, Xize Cheng, Rongjie Huang, Luping Liu, Zhenhui Ye, Haifeng Huang, Yang Zhao, Tao Jin, Peng Gao, et al. Freebind: Free lunch in unified multimodal space via knowledge fusion.arXiv preprint arXiv:2405.04883, 2024. 2
-
[36]
Zehan Wang, Ziang Zhang, Hang Zhang, Luping Liu, Rongjie Huang, Xize Cheng, Hengshuang Zhao, and Zhou Zhao. Omnibind: Large-scale omni multimodal representa- tion via binding spaces.arXiv preprint arXiv:2407.11895,
-
[37]
Satosi Watanabe. Information theoretical analysis of multi- variate correlation.IBM Journal of research and develop- ment, 4(1):66–82, 1960. 3
work page 1960
-
[38]
Diagnos- ing and re-learning for balanced multimodal learning
Yake Wei, Siwei Li, Ruoxuan Feng, and Di Hu. Diagnos- ing and re-learning for balanced multimodal learning. In European Conference on Computer Vision, pages 71–86. Springer, 2024. 8
work page 2024
-
[39]
Xeno-canto: Sharing wildlife sounds from around the world.https: //www.xeno-canto.org/, 2008
Xeno-canto Foundation for Nature Sounds. Xeno-canto: Sharing wildlife sounds from around the world.https: //www.xeno-canto.org/, 2008. 5
work page 2008
-
[40]
mplug-2: A modularized multi-modal foundation model across text, image and video
Haiyang Xu, Qinghao Ye, Ming Yan, Yaya Shi, Jiabo Ye, Yuanhong Xu, Chenliang Li, Bin Bi, Qi Qian, Wei Wang, et al. mplug-2: A modularized multi-modal foundation model across text, image and video. InInternational Con- ference on Machine Learning, pages 38728–38748. PMLR,
-
[41]
Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding
Le Xue, Mingfei Gao, Chen Xing, Roberto Mart ´ın-Mart´ın, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 1179–1189, 2023. 1, 2
work page 2023
-
[42]
Ulip-2: Towards scalable multimodal pre-training for 3d understanding
Le Xue, Ning Yu, Shu Zhang, Artemis Panagopoulou, Jun- nan Li, Roberto Mart´ın-Mart´ın, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, et al. Ulip-2: Towards scalable multimodal pre-training for 3d understanding. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27091–27101, 2024. 1, 2
work page 2024
-
[43]
Chih-Hsuan Yang, Benjamin Feuer, Talukder Jubery, Zi Deng, Andre Nakkab, Md Zahid Hasan, Shivani Chiranjeevi, Kelly Marshall, Nirmal Baishnab, Asheesh Singh, et al. Biotrove: A large curated image dataset enabling ai for bio- diversity.Advances in Neural Information Processing Sys- tems, 37:102101–102120, 2024. 4
work page 2024
-
[44]
Yuan Yuan, Zhaojian Li, and Bin Zhao. A survey of mul- timodal learning: Methods, applications, and future.ACM Computing Surveys, 57(7):1–34, 2025. 1
work page 2025
-
[45]
MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos
Amir Zadeh, Rowan Zellers, Eli Pincus, and Louis-Philippe Morency. Mosi: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos.arXiv preprint arXiv:1606.06259, 2016. 5
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[46]
Ziang Zhang, Zehan Wang, Luping Liu, Rongjie Huang, Xize Cheng, Zhenhui Ye, Huadai Liu, Haifeng Huang, Yang Zhao, Tao Jin, et al. Extending multi-modal contrastive rep- resentations.Advances in Neural Information Processing Systems, 37:91880–91903, 2024. 1, 2, 8
work page 2024
-
[47]
Uni3d: Exploring unified 3d representation at scale.arXiv preprint arXiv:2310.06773,
Junsheng Zhou, Jinsheng Wang, Baorui Ma, Yu-Shen Liu, Tiejun Huang, and Xinlong Wang. Uni3d: Exploring unified 3d representation at scale.arXiv preprint arXiv:2310.06773,
-
[48]
Bin Zhu, Bin Lin, Munan Ning, Yang Yan, Jiaxi Cui, HongFa Wang, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zongwei Li, et al. Languagebind: Extending video-language pretrain- ing to n-modality by language-based semantic alignment. arXiv preprint arXiv:2310.01852, 2023. 1, 2 10 THE MORE, THE MERRIER: CONTRASTIVE FUSION FOR HIGHER-ORDER MULTIMODAL ALIGNMENT Su...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.