Beyond Size and Growth: Rethinking Lung Cancer Screening with AI Based Nodule Detection and Diagnosis
Pith reviewed 2026-05-21 17:25 UTC · model grok-4.3
The pith
An integrated AI system detects and assesses malignancy of lung nodules directly from low-dose CT scans, outperforming size and growth based criteria.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
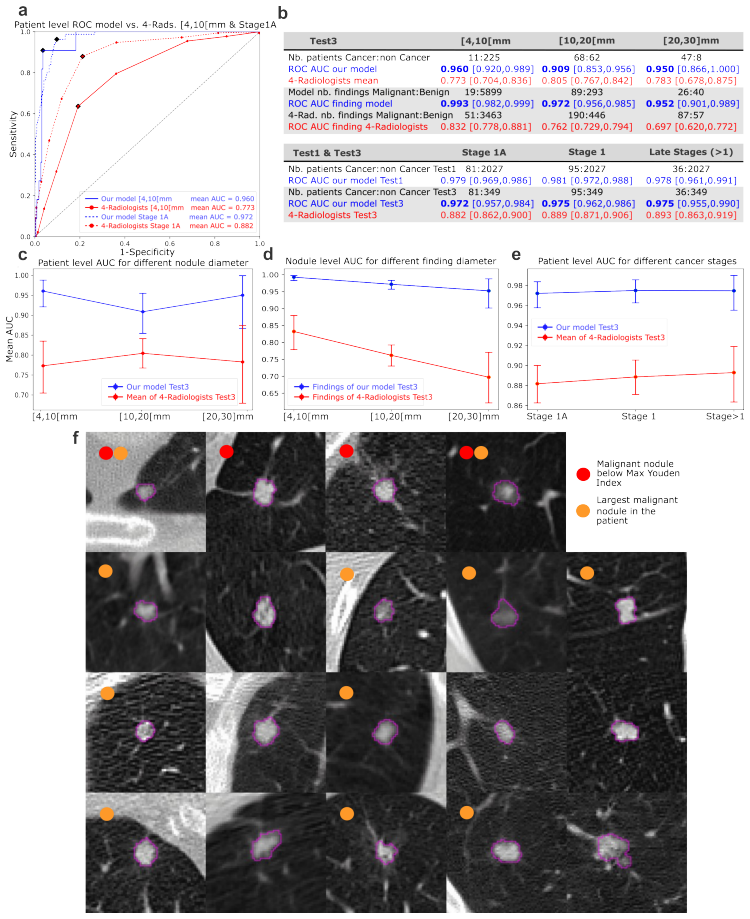
The paper claims that a unified CADe/CADx framework using a Large Ensemble Model (LEM) of shallow deep learning and feature-based models can target malignant nodules directly at the point of clinical decision, achieving superior performance to all growth-based metrics, Lung RADS, European volume and VDT criteria, radiologists, and leading AI models on both internal and external validation while maintaining high sensitivity at low false-positive rates and excelling on small and early-stage cancers.
What carries the argument
The Large Ensemble Model (LEM) that combines ensembles of shallow deep learning and feature-based models within a single unified CADe/CADx framework to perform nodule detection and malignancy assessment directly at the nodule level.
If this is right
- The model maintains high sensitivity at low false positive rates and excels for small and early stage cancers.
- It enables malignancy assessment up to one year earlier than radiologists for indeterminate and slow growing nodules.
- This approach has the potential to streamline lung cancer screening workflows.
- It supports earlier and more actionable clinical decision making by redefining evaluation at the nodule level.
Where Pith is reading between the lines
- If the performance holds, screening programs could move from size-based follow-up intervals to direct malignancy-probability triage.
- Similar direct-assessment models might reduce unnecessary scans for benign nodules while increasing detection of slow-growing malignancies.
- Integration into existing radiology workflows could lower the volume of indeterminate cases requiring human review.
Load-bearing premise
The 69,449 nodule annotations provide accurate ground-truth malignancy labels and the external validation cohort is independent and representative of real-world low-dose CT screening populations.
What would settle it
A prospective trial in an independent screening population where biopsy-confirmed outcomes for nodules flagged as malignant by the model but negative under current size or growth rules show no improvement in early-stage cancer detection rates or survival.
Figures







read the original abstract
Early detection of malignant lung nodules remains constrained by size and growth based screening criteria, often delaying diagnosis. We present an integrated AI system that jointly performs nodule detection and malignancy assessment directly at the nodule level from low dose CT scans, within a unified CADe/CADx framework. Unlike conventional pipelines separating detection and diagnosis, our approach targets malignant nodules directly, redefining evaluation at the point where clinical decisions are made. To address limitations in dataset scale and explainability, the system consists of a Large Ensemble Model (LEM) combining ensembles of shallow deep learning and feature based models. It was trained and evaluated on 25,709 scans with 69,449 annotated nodules, with external validation on an independent cohort. It achieved an AUC of 0.98 internally and 0.945 externally, outperforming all growth based metrics, Lung RADS size based triage, European volume and VDT based screening criteria, radiologists, and leading AI models. The model maintains high sensitivity at low false positive rates, excels for small and early stage cancers, and enables malignancy assessment up to one year earlier than radiologists for indeterminate and slow growing nodules. This approach has the potential to streamline lung cancer screening workflows and support earlier, more actionable clinical decision making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an integrated AI system (Large Ensemble Model, LEM) for joint nodule detection and malignancy assessment directly from low-dose CT scans in a unified CADe/CADx framework. Trained and evaluated on 25,709 scans containing 69,449 annotated nodules with external validation on an independent cohort, it reports AUC 0.98 internally and 0.945 externally, claiming to outperform growth-based metrics, Lung-RADS size triage, European volume/VDT criteria, radiologists, and leading AI models while enabling malignancy assessment up to one year earlier for indeterminate and slow-growing nodules.
Significance. If the performance claims hold under independent, histology-confirmed labels, the work could meaningfully advance lung cancer screening by shifting from size/growth proxies to direct nodule-level malignancy prediction, with potential to reduce diagnostic delays. The scale of the annotated dataset and external validation cohort represent clear strengths that would support broader impact if methodological details are clarified.
major comments (2)
- [Abstract and Methods] Abstract and Methods: The manuscript provides no details on how malignancy ground-truth labels were acquired for the 69,449 nodules (histology confirmation rates, follow-up imaging criteria, expert consensus, or biopsy triggers). This is load-bearing for the central claim of outperforming VDT/growth-based metrics and achieving earlier detection, because labels derived from longitudinal follow-up could embed growth signals and render the reported AUC advantage circular rather than independent of the baselines being compared.
- [Results] Results section: The specific claim that the model enables 'malignancy assessment up to one year earlier than radiologists for indeterminate and slow growing nodules' lacks supporting quantitative evidence such as time-to-detection differences, survival-style curves, or per-nodule follow-up interval analysis; without this, the temporal advantage remains unsubstantiated relative to the radiologist baseline.
minor comments (2)
- [Abstract] Abstract: Comparative performance against 'leading AI models' is stated without naming the models or reporting their AUC values, making the outperformance claim difficult to evaluate at a glance.
- [Methods] Methods: Training/validation splits, statistical testing procedures, and class-imbalance handling are not described, which affects interpretability of the reported AUCs and sensitivity at low false-positive rates.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments in detail below and have made revisions to the manuscript to incorporate clarifications and additional analyses where necessary.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and Methods: The manuscript provides no details on how malignancy ground-truth labels were acquired for the 69,449 nodules (histology confirmation rates, follow-up imaging criteria, expert consensus, or biopsy triggers). This is load-bearing for the central claim of outperforming VDT/growth-based metrics and achieving earlier detection, because labels derived from longitudinal follow-up could embed growth signals and render the reported AUC advantage circular rather than independent of the baselines being compared.
Authors: We agree that detailed information on ground-truth label acquisition is essential to substantiate our claims and to demonstrate that our evaluation is independent of growth-based metrics. In the revised manuscript, we will expand the Methods section to include a comprehensive description of the labeling process. Malignancy labels were obtained through a combination of histology confirmation, expert consensus review by multiple radiologists, and long-term follow-up imaging demonstrating lesion progression or stability patterns indicative of malignancy, with biopsy decisions guided by established clinical protocols. Critically, we ensured that labels were not solely derived from volume doubling time or growth rates to avoid circularity. The model was trained to predict malignancy based on imaging features at the time of the scan, independent of subsequent growth observations. revision: yes
-
Referee: [Results] Results section: The specific claim that the model enables 'malignancy assessment up to one year earlier than radiologists for indeterminate and slow growing nodules' lacks supporting quantitative evidence such as time-to-detection differences, survival-style curves, or per-nodule follow-up interval analysis; without this, the temporal advantage remains unsubstantiated relative to the radiologist baseline.
Authors: We acknowledge that while the abstract and discussion reference the potential for earlier assessment based on the model's ability to identify malignancy in nodules that remained indeterminate under size and growth criteria for extended periods, the Results section would benefit from more explicit quantitative support. In the revision, we will add a new subsection with per-nodule analysis of follow-up intervals. This will include histograms or survival curves illustrating the time from initial detection to malignancy confirmation for nodules where the LEM predicted malignancy at the baseline scan, compared to the time when radiologists would have escalated based on observed growth. Our retrospective analysis of the longitudinal data shows that for a subset of slow-growing malignant nodules, the model provided a positive malignancy prediction up to 12 months prior to the point where growth criteria would have triggered further action. revision: yes
Circularity Check
No circularity: empirical AUCs on held-out cohorts are independent of inputs
full rationale
The paper reports standard supervised learning results: an ensemble model trained on 25,709 scans with 69,449 annotated nodules, evaluated via AUC on internal held-out data (0.98) and an independent external cohort (0.945). These metrics are computed directly from model predictions versus ground-truth labels on separate test sets; no equations, fitted parameters, or self-citations reduce the reported performance numbers to the training inputs by construction. Comparisons to Lung-RADS, VDT, and radiologist baselines are likewise empirical head-to-head evaluations on the same test distributions. The derivation chain is therefore self-contained against external benchmarks, consistent with the reader's assessment that performance numbers are not derived by definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- Ensemble model weights and hyperparameters
axioms (1)
- domain assumption Nodule annotations in the 69,449-nodule dataset accurately reflect true malignancy status
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present an integrated AI system that jointly performs nodule detection and malignancy assessment directly at the nodule level... Large Ensemble Model (LEM) combining ensembles of shallow deep learning and feature based models... AUC of 0.98 internally and 0.945 externally
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
outperforming all growth based metrics, Lung RADS size based triage, European volume and VDT based screening criteria
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Fabian Kuppers, Jan Kronenberger, Amirhossein Shantia, and Anselm Haselhoff. Multivariate Confidence Calibration for Object Detection.2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1322–1330, June 2020. Conference Name: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) ISBN:...
work page 2020
-
[2]
S. Gregory Jennings, Helen T. Winer-Muram, Mark Tann, Jun Ying, and Ian Dowdeswell. Distribution of Stage I Lung Cancer Growth Rates Determined with Serial V olumetric CT Measurements.Radiology, 241(2):554–563, November 2006
work page 2006
-
[3]
Dong Ming Xu, Hester Gietema, Harry de Koning, René Vernhout, Kristiaan Nackaerts, Mathias Prokop, Carla Weenink, Jan-Willem Lammers, Harry Groen, Matthijs Oudkerk, and Rob van Klaveren. Nodule management protocol of the NELSON randomised lung cancer screening trial.Lung Cancer (Amsterdam, Netherlands), 54(2):177–184, November 2006
work page 2006
-
[4]
N. Becker, E. Motsch, M. L. Gross, A. Eigentopf, C. P. Heussel, H. Dienemann, P. A. Schnabel, M. Eichinger, D. E. Optazaite, M. Puderbach, M. Wielpütz, H. U. Kauczor, J. Tremper, and S. Delorme. Randomized Study on Early Detection of Lung Cancer with MSCT in Germany: Results of the First 3 Years of Follow-up After Randomization.Journal of Thoracic Oncolog...
work page 2015
-
[5]
Nancy A. Obuchowski, Brandon D. Gallas, and Stephen L. Hillis. Multi-Reader ROC studies with Split-Plot Designs: A Comparison of Statistical Methods.Academic radiology, 19(12):1508–1517, December 2012. 42/44 6.Zilong He, Yue Li, Weixiong Zeng, Weimin Xu, Jialing Liu, Xiangyuan Ma, Jun Wei, Hui Zeng, Zeyuan Xu, Sina Wang, Chanjuan Wen, Jiefang Wu, Chenya F...
work page 2012
-
[6]
Armato, Geoffrey McLennan, Luc Bidaut, Michael F
Samuel G. Armato, Geoffrey McLennan, Luc Bidaut, Michael F. McNitt-Gray, Charles R. Meyer, Anthony P. Reeves, Binsheng Zhao, Denise R. Aberle, Claudia I. Henschke, Eric A. Hoffman, Ella A. Kazerooni, Heber MacMahon, Edwin J. R. van Beek, David Yankelevitz, Alberto M. Biancardi, Peyton H. Bland, Matthew S. Brown, Roger M. Engelmann, Gary E. Laderach, Danie...
work page 2011
-
[7]
Kiraly, Sujeeth Bharadwaj, Bokyung Choi, Joshua J
Diego Ardila, Atilla P. Kiraly, Sujeeth Bharadwaj, Bokyung Choi, Joshua J. Reicher, Lily Peng, Daniel Tse, Mozziyar Etemadi, Wenxing Ye, Greg Corrado, David P. Naidich, and Shravya Shetty. End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography.Nature Medicine, 25(6):954–961, June 2019
work page 2019
-
[8]
Sylvie Leroy, Jonathan Benzaquen, Andrea Mazzetta, Sylvain Marchand-Adam, Bernard Padovani, Dominique Israel-Biet, Christophe Pison, Pascal Chanez, Jacques Cadranel, Julien Mazières, Vincent Jounieaux, Charlotte Cohen, Véronique Hofman, Marius Ilie, Paul Hofman, and Charles Hugo Marquette. Circulating tumour cells as a potential screening tool for lung ca...
work page 2017
-
[9]
Bankier, Heber MacMahon, Thomas Colby, Pierre Alain Gevenois, Jin Mo Goo, Ann N.C
Alexander A. Bankier, Heber MacMahon, Thomas Colby, Pierre Alain Gevenois, Jin Mo Goo, Ann N.C. Leung, David A. Lynch, Cornelia M. Schaefer-Prokop, Noriyuki Tomiyama, William D. Travis, Johny A. Verschakelen, Charles S. White, and David P. Naidich. Fleischner Society: Glossary of Terms for Thoracic Imaging.Radiology, 310(2):e232558, February
-
[10]
Publisher: Radiological Society of North America
-
[11]
Arnaud Arindra Adiyoso Setio, Alberto Traverso, Thomas de Bel, Moira S. N. Berens, Cas van den Bogaard, Piergiorgio Cerello, Hao Chen, Qi Dou, Maria Evelina Fantacci, Bram Geurts, Robbert van der Gugten, Pheng Ann Heng, Bart Jansen, Michael M. J. de Kaste, Valentin Kotov, Jack Yu-Hung Lin, Jeroen T. M. C. Manders, Alexander Sóñora-Mengana, Juan Carlos Gar...
work page 2017
-
[12]
Greene, Tamara Broderick, Michael M
Benjamin Haibe-Kains, George Alexandru Adam, Ahmed Hosny, Farnoosh Khodakarami, Levi Waldron, Bo Wang, Chris McIntosh, Anna Goldenberg, Anshul Kundaje, Casey S. Greene, Tamara Broderick, Michael M. Hoffman, Jeffrey T. Leek, Keegan Korthauer, Wolfgang Huber, Alvis Brazma, Joelle Pineau, Robert Tibshirani, Trevor Hastie, John P. A. Ioannidis, John Quackenbu...
work page 2020
-
[13]
3D MRI Brain Tumor Segmentation Using Autoencoder Regularization
Andriy Myronenko. 3D MRI Brain Tumor Segmentation Using Autoencoder Regularization. In Alessandro Crimi, Spyridon Bakas, Hugo Kuijf, Farahani Keyvan, Mauricio Reyes, and Theo van Walsum, editors,Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, pages 311–320, Cham, 2019. Springer International Publishing. 15.Michael Baumgartner...
work page 2019
-
[14]
Paul F. Jaeger, Simon A. A. Kohl, Sebastian Bickelhaupt, Fabian Isensee, Tristan Anselm Kuder, Heinz-Peter Schlemmer, and Klaus H. Maier-Hein. Retina U-Net: Embarrassingly Simple Exploitation of Segmentation Supervision for Medical Object Detection, November 2018. arXiv:1811.08661 [cs]. 43/44
-
[15]
U-Net: Convolutional Networks for Biomedical Image Segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Nassir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi, editors,Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pages 234–241, Cham, 2015. Springer International Publishing
work page 2015
-
[16]
Changan Yuan, Yong Wu, Xiao Qin, Shaojie Qiao, Yonghua Pan, Ping Huang, Dunhu Liu, and Nan Han. An effective image classification method for shallow densely connected convolution networks through squeezing and splitting techniques. Applied Intelligence, 49, October 2019
work page 2019
-
[17]
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q. Weinberger. Densely Connected Convolutional Networks. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2261–2269, July 2017. ISSN: 1063-6919
work page 2017
-
[18]
Joost J. M. van Griethuysen, Andriy Fedorov, Chintan Parmar, Ahmed Hosny, Nicole Aucoin, Vivek Narayan, Regina G. H. Beets-Tan, Jean-Christophe Fillion-Robin, Steve Pieper, and Hugo J. W. L. Aerts. Computational Radiomics System to Decode the Radiographic Phenotype.Cancer Research, 77(21):e104–e107, October 2017
work page 2017
-
[19]
Hugo J. W. L. Aerts, Emmanuel Rios Velazquez, Ralph T. H. Leijenaar, Chintan Parmar, Patrick Grossmann, Sara Carvalho, Johan Bussink, René Monshouwer, Benjamin Haibe-Kains, Derek Rietveld, Frank Hoebers, Michelle M. Rietbergen, C. René Leemans, Andre Dekker, John Quackenbush, Robert J. Gillies, and Philippe Lambin. Decoding tumour phenotype by noninvasive...
work page 2014
-
[20]
3D-Morphomics, Morphological Features on CT Scans for Lung Nodule Malignancy Diagnosis
Elias Munoz, Pierre Baudot, Van-Khoa Le, Charles V oyton, Benjamin Renoust, Danny Francis, Vladimir Groza, Jean- Christophe Brisset, Ezequiel Geremia, Antoine Iannessi, Yan Liu, and Benoit Huet. 3D-Morphomics, Morphological Features on CT Scans for Lung Nodule Malignancy Diagnosis. In Sharib Ali, Fons van der Sommen, Bartłomiej Władysław Papie˙ z, Maureen...
work page 2022
-
[21]
XGBoost: A Scalable Tree Boosting System
Tianqi Chen and Carlos Guestrin. XGBoost: A Scalable Tree Boosting System. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, pages 785–794, New York, NY , USA, August 2016. Association for Computing Machinery
work page 2016
-
[22]
A comprehensive review on ensemble deep learning: Opportunities and challenges
Ammar Mohammed and Rania Kora. A comprehensive review on ensemble deep learning: Opportunities and challenges. Journal of King Saud University - Computer and Information Sciences, 35(2):757–774, February 2023
work page 2023
-
[23]
Mikhael, Jeremy Wohlwend, Adam Yala, Ludvig Karstens, Justin Xiang, Angelo K
Peter G. Mikhael, Jeremy Wohlwend, Adam Yala, Ludvig Karstens, Justin Xiang, Angelo K. Takigami, Patrick P. Bourgouin, PuiYee Chan, Sofiane Mrah, Wael Amayri, Yu-Hsiang Juan, Cheng-Ta Yang, Yung-Liang Wan, Gigin Lin, Lecia V . Sequist, Florian J. Fintelmann, and Regina Barzilay. Sybil: A Validated Deep Learning Model to Predict Future Lung Cancer Risk Fro...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.