Recognition: 2 theorem links
· Lean TheoremMultimodal Reinforcement Learning with Adaptive Verifier for AI Agents
Pith reviewed 2026-05-17 03:05 UTC · model grok-4.3
The pith
An adaptive verifier selects scoring functions during multimodal RL to achieve state-of-the-art results on agentic tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
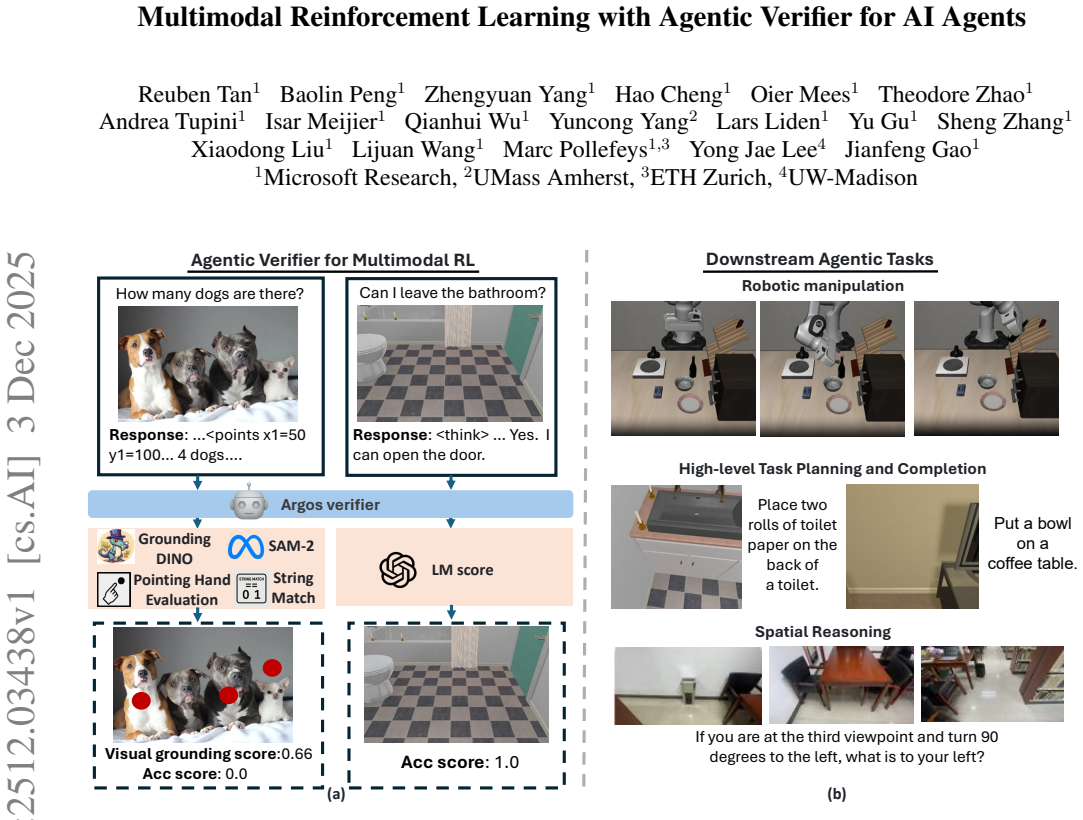
Argos is introduced as a principled reward agent that for each sample selects scoring functions to evaluate final response accuracy, spatiotemporal localization of referred entities and actions, and reasoning process quality. Leveraging Argos across both SFT data curation and RL training yields state-of-the-art results on spatial reasoning, visual hallucination, robotics, and embodied AI benchmarks. Sole reliance on SFT post-training proves insufficient because agents collapse to ungrounded solutions during RL without the online verification; the verifier also mitigates reward-hacking, with effectiveness justified through pareto-optimality.
What carries the argument
Argos, the agentic reward agent that adaptively selects from a pool of teacher-model-derived and rule-based scoring functions to supply fine-grained rewards on accuracy, localization, and reasoning quality.
If this is right
- Models maintain grounded reasoning through the full RL phase rather than reverting to ungrounded outputs after SFT.
- State-of-the-art performance is reached on spatial reasoning, visual hallucination, and embodied robotics benchmarks.
- Reward hacking decreases when the adaptive verifier operates online during multimodal RL.
- The method rests on a pareto-optimality argument that explains why selected scoring functions outperform single outcome signals.
Where Pith is reading between the lines
- Continuous verification during RL appears necessary to preserve grounding once models leave the SFT stage.
- Adaptive selection of reward signals may offer a general route to richer training in other domains that currently rely on sparse final-answer feedback.
Load-bearing premise
A pool of teacher-model and rule-based scoring functions exists that Argos can select from to deliver consistently more informative rewards than outcome signals alone without introducing offsetting biases or artifacts.
What would settle it
Train an otherwise identical model using only final-answer outcome rewards during the RL stage and check whether it matches the reported benchmark scores or still exhibits collapse to ungrounded solutions on the spatial-reasoning and embodied-AI tasks.
Figures

















read the original abstract
Agentic reasoning models trained with multimodal reinforcement learning (MMRL) have become increasingly capable, yet they are almost universally optimized using sparse, outcome-based rewards computed based on the final answers. Richer rewards computed from the reasoning tokens can improve learning significantly by providing more fine-grained guidance. However, it is challenging to compute more informative rewards in MMRL beyond those based on outcomes since different samples may require different scoring functions and teacher models may provide noisy reward signals too. In this paper, we introduce the Argos (Agentic Reward for Grounded & Objective Scoring), a principled reward agent to train multimodal reasoning models for agentic tasks. For each sample, Argos selects from a pool of teacher-model derived and rule-based scoring functions to simultaneously evaluate: (i) final response accuracy, (ii) spatiotemporal localization of referred entities and actions, and (iii) the quality of the reasoning process. We find that by leveraging our agentic verifier across both SFT data curation and RL training, our model achieves state-of-the-art results across multiple agentic tasks such as spatial reasoning, visual hallucination as well as robotics and embodied AI benchmarks. Critically, we demonstrate that just relying on SFT post-training on highly curated reasoning data is insufficient, as agents invariably collapse to ungrounded solutions during RL without our online verification. We also show that our agentic verifier can help to reduce reward-hacking in MMRL. Finally, we also provide a theoretical justification for the effectiveness of Argos through the concept of pareto-optimality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Argos, an adaptive agentic verifier for multimodal reinforcement learning. For each sample, Argos selects from a pool of teacher-model-derived and rule-based scoring functions to evaluate final response accuracy, spatiotemporal localization of referred entities and actions, and reasoning process quality. The authors claim that applying Argos to both SFT data curation and online RL training yields state-of-the-art results on spatial reasoning, visual hallucination, robotics, and embodied AI benchmarks. They further state that SFT on curated data alone is insufficient because agents collapse to ungrounded solutions during RL, that Argos reduces reward-hacking, and that a Pareto-optimality argument justifies its effectiveness.
Significance. If the reported SOTA results hold and the adaptive selection demonstrably supplies more informative rewards than outcome signals or fixed selection without introducing new biases, the work would offer a practical advance in training reliable multimodal agentic models by moving beyond sparse rewards. The observation that online verification during RL is required to prevent collapse would be a useful empirical finding for the community.
major comments (3)
- Abstract: the claim of achieving state-of-the-art results across multiple agentic tasks supplies no quantitative metrics, benchmark scores, baseline comparisons, or error bars, so the magnitude and reliability of the reported gains cannot be assessed from the provided text.
- Experiments section: the central claim that Argos adaptive selection from the scoring pool produces strictly more informative and less noisy rewards than outcome-based signals (and prevents collapse) is load-bearing, yet no ablation isolating adaptive selection against fixed or random selection from the identical pool is described; without this, gains could be driven by curation/filtering effects rather than the verifier.
- Theoretical justification: the Pareto-optimality argument for Argos effectiveness is invoked but the derivation is not shown, leaving open whether it provides independent grounding or reduces to a fitted quantity in the finite-sample RL setting.
minor comments (1)
- Clarify the exact size and composition of the scoring-function pool and whether Argos's selection policy is itself learned or heuristic.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, agreeing where revisions are warranted and providing clarifications where appropriate. We will incorporate changes to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: the claim of achieving state-of-the-art results across multiple agentic tasks supplies no quantitative metrics, benchmark scores, baseline comparisons, or error bars, so the magnitude and reliability of the reported gains cannot be assessed from the provided text.
Authors: We agree that the abstract would be strengthened by including concrete quantitative results. In the revised manuscript, we will update the abstract to report key benchmark scores, baseline comparisons, and references to error bars or statistical significance from the experiments. revision: yes
-
Referee: Experiments section: the central claim that Argos adaptive selection from the scoring pool produces strictly more informative and less noisy rewards than outcome-based signals (and prevents collapse) is load-bearing, yet no ablation isolating adaptive selection against fixed or random selection from the identical pool is described; without this, gains could be driven by curation/filtering effects rather than the verifier.
Authors: We acknowledge the importance of this ablation to isolate the contribution of adaptive selection. We will add experiments comparing adaptive selection against fixed and random selection from the same scoring pool in the revised experiments section to demonstrate that the observed benefits stem from the adaptive mechanism rather than curation alone. revision: yes
-
Referee: Theoretical justification: the Pareto-optimality argument for Argos effectiveness is invoked but the derivation is not shown, leaving open whether it provides independent grounding or reduces to a fitted quantity in the finite-sample RL setting.
Authors: We thank the referee for this observation. The Pareto-optimality argument is intended to provide independent grounding, but we agree that the derivation should be explicitly presented. In the revised manuscript, we will include the full derivation (with discussion of finite-sample considerations) in the appendix or a dedicated theoretical section. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces Argos as a new adaptive verifier that selects from a pool of teacher-derived and rule-based scorers to provide richer rewards in MMRL, with claims of SOTA results, insufficiency of SFT alone, and a theoretical justification via Pareto-optimality. No equations, derivations, or steps are exhibited that reduce by construction to fitted inputs, self-definitions, or self-citation chains; the adaptive selection mechanism and Pareto argument are presented as independent contributions rather than renamings or forced equivalences. Empirical demonstrations and the verifier's design provide external grounding separate from the target outcomes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A pool of teacher-model-derived and rule-based scoring functions can be defined that jointly cover accuracy, spatiotemporal localization, and reasoning quality for arbitrary agentic samples.
- domain assumption Teacher models provide noisy but still useful reward signals that can be improved by adaptive selection.
invented entities (1)
-
Argos (Agentic Reward for Grounded & Objective Scoring)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Argos ... adaptively selects from a pool of teacher-model derived and rule-based scoring functions to simultaneously evaluate: (i) final response accuracy, (ii) spatiotemporal localization ... (iii) the quality of the reasoning process ... theoretical justification ... through the concept of pareto-optimality.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Definition 1 (δ-Pareto Domination) ... Assumption 1 ... σ-sub-Gaussian ... Theorem 1 (Global Pareto Guarantee)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
The paper introduces the Proxy Compression Hypothesis as a unifying framework explaining reward hacking in RLHF as an emergent result of compressing high-dimensional human objectives into proxy reward signals under op...
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in Neural Information Processing Systems, 35:23716–23736,
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Chang Chen, Yi-Fu Wu, Jaesik Yoon, and Sungjin Ahn. Transdreamer: Reinforcement learning with transformer world models.arXiv preprint arXiv:2202.09481, 2022. 3
-
[4]
Train- ing strategies for efficient embodied reasoning
William Chen, Suneel Belkhale, Suvir Mirchandani, Oier Mees, Danny Driess, Karl Pertsch, and Sergey Levine. Train- ing strategies for efficient embodied reasoning. InConfer- ence on Robot Learning, 2025. 8
work page 2025
-
[5]
William Chen, Oier Mees, Aviral Kumar, and Sergey Levine. Vision-language models provide promptable representations for reinforcement learning.Transactions on Machine Learn- ing Research, 2025. 3
work page 2025
-
[6]
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction- finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024. 2
work page 2024
-
[7]
Open X-Embodiment Collaboration, Abhishek Padalkar, Acorn Pooley, Ajinkya Jain, Alex Bewley, Alex Herzog, Alex Irpan, Alexander Khazatsky, Anant Rai, Anikait Singh, Anthony Brohan, Antonin Raffin, Ayzaan Wahid, Ben Burgess-Limerick, Beomjoon Kim, Bernhard Sch ¨olkopf, Brian Ichter, Cewu Lu, Charles Xu, Chelsea Finn, Chenfeng Xu, Cheng Chi, Chenguang Huang...
work page 2024
-
[8]
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tri- pathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art multimodal models.arXiv e-prints, pages arXiv–2409, 2024. 6, 9, 11
work page 2024
-
[9]
Tool-lmm: A large multi-modal model for tool agent learning
Sixun Dong. Tool-lmm: A large multi-modal model for tool agent learning. 2024. 2
work page 2024
-
[10]
Palm-e: An embodied multimodal language model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, et al. Palm-e: An embodied multimodal language model. 2023. 3
work page 2023
-
[11]
Agent ai: Surveying the horizons of multimodal interaction.CoRR, 2024
Zane Durante, Qiuyuan Huang, Naoki Wake, Ran Gong, Jae Sung Park, Bidipta Sarkar, Rohan Taori, Yusuke Noda, Demetri Terzopoulos, Yejin Choi, et al. Agent ai: Surveying the horizons of multimodal interaction.CoRR, 2024. 2
work page 2024
-
[12]
GRIT: Teaching MLLMs to Think with Images
Yue Fan, Xuehai He, Diji Yang, Kaizhi Zheng, Ching-Chen Kuo, Yuting Zheng, Sravana Jyothi Narayanaraju, Xinze Guan, and Xin Eric Wang. Grit: Teaching mllms to think with images.arXiv preprint arXiv:2505.15879, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Com- puter Vision, pages 148–166. Springer, 2024. 7, 1
work page 2024
-
[15]
Gemini: A family of highly capable multimodal models
Google Gemini Team. Gemini: A family of highly capable multimodal models. 2023. 5
work page 2023
-
[16]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnos- tic suite for entangled language hallucination and visual il- lusion in large vision-language models. InProceedings of 10 the IEEE/CVF Conference on Computer Vision and Pattern Recogniti...
work page 2024
-
[17]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Regiongpt: Towards region understanding vision lan- guage model
Qiushan Guo, Shalini De Mello, Hongxu Yin, Wonmin Byeon, Ka Chun Cheung, Yizhou Yu, Ping Luo, and Sifei Liu. Regiongpt: Towards region understanding vision lan- guage model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13796– 13806, 2024. 3
work page 2024
-
[19]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models. arXiv preprint arXiv:2301.04104, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Training Agents Inside of Scalable World Models
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Train- ing agents inside of scalable world models.arXiv preprint arXiv:2509.24527, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Ghil-glue: Hierarchical control with filtered sub- goal images
Kyle Beltran Hatch, Ashwin Balakrishna, Oier Mees, Suraj Nair, Seohong Park, Blake Wulfe, Masha Itkina, Benjamin Eysenbach, Sergey Levine, Thomas Kollar, and Benjamin Burchfiel. Ghil-glue: Hierarchical control with filtered sub- goal images. InProceedings of the IEEE International Con- ference on Robotics and Automation (ICRA), Atlanta, USA,
-
[22]
Breaking the reasoning barrier a survey on llm complex reasoning through the lens of self-evolution
Tao He, Hao Li, Jingchang Chen, Runxuan Liu, Yixin Cao, Lizi Liao, Zihao Zheng, Zheng Chu, Jiafeng Liang, Ming Liu, et al. Breaking the reasoning barrier a survey on llm complex reasoning through the lens of self-evolution. In Findings of the Association for Computational Linguistics: ACL 2025, pages 7377–7417, 2025. 2
work page 2025
-
[23]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guob- ing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Li- hang Pan, et al. Glm-4.1 v-thinking: Towards versatile multi- modal reasoning with scalable reinforcement learning.arXiv e-prints, pages arXiv–2507, 2025. 5
work page 2025
-
[24]
Cheng-Yu Hsieh, Jieyu Zhang, Zixian Ma, Aniruddha Kem- bhavi, and Ranjay Krishna. Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality.Advances in neural information processing systems, 36:31096–31116,
-
[25]
Visual language maps for robot navigation
Chenguang Huang, Oier Mees, Andy Zeng, and Wolfram Burgard. Visual language maps for robot navigation. InPro- ceedings of the IEEE International Conference on Robotics and Automation (ICRA), London, UK, 2023. 3
work page 2023
-
[26]
Chenguang Huang, Oier Mees, Andy Zeng, and Wolfram Burgard. Multimodal spatial language maps for robot navi- gation and manipulation.International Journal of Robotics Research (IJRR), 2025. 3
work page 2025
-
[27]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, and Li Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V Le, Yunhsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision.arXiv preprint, 2021. 2
work page 2021
-
[29]
Joshua Jones, Oier Mees, Carmelo Sferrazza, Kyle Stachow- icz, Pieter Abbeel, and Sergey Levine. Beyond sight: Fine- tuning generalist robot policies with heterogeneous sensors via language grounding. InProceedings of the IEEE Interna- tional Conference on Robotics and Automation (ICRA), At- lanta, USA, 2025. 3
work page 2025
-
[30]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025. 8
work page 2025
-
[31]
Somnath Kumar, Yash Gadhia, Tanuja Ganu, and Akshay Nambi. Mmctagent: Multi-modal critical thinking agent framework for complex visual reasoning.arXiv preprint arXiv:2405.18358, 2024. 2
-
[32]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInterna- tional conference on machine learning, pages 12888–12900. PMLR, 2022. 2
work page 2022
-
[33]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 2
work page 2023
-
[34]
Yunxin Li, Zhenyu Liu, Zitao Li, Xuanyu Zhang, Zhenran Xu, Xinyu Chen, Haoyuan Shi, Shenyuan Jiang, Xintong Wang, Jifang Wang, et al. Perception, reason, think, and plan: A survey on large multimodal reasoning models.arXiv preprint arXiv:2505.04921, 2025. 2
-
[35]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023. 8, 2
work page 2023
-
[36]
Fuxiao Liu, Tianrui Guan, Zongxia Li, Lichang Chen, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hallusion- bench: You see what you think? or you think what you see? an image-context reasoning benchmark challenging for gpt- 4v (ision), llava-1.5, and other multi-modality models.arXiv preprint arXiv:2310.14566, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 2
work page 2023
-
[38]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vi- sion, pages 216–233. Springer, 2024. 3
work page 2024
-
[39]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Run Luo, Lu Wang, Wanwei He, Longze Chen, Jiaming Li, and Xiaobo Xia. Gui-r1: A generalist r1-style vision- language action model for gui agents.arXiv preprint arXiv:2504.10458, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wol- fram Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipu- lation tasks.IEEE Robotics and Automation Letters (RA-L), 7(3):7327–7334, 2022. 3 11
work page 2022
-
[41]
Grounding language with visual affordances over unstruc- tured data
Oier Mees, Jessica Borja-Diaz, and Wolfram Burgard. Grounding language with visual affordances over unstruc- tured data. InProceedings of the IEEE International Con- ference on Robotics and Automation (ICRA), London, UK,
-
[42]
Policy adaptation via language op- timization: Decomposing tasks for few-shot imitation
Vivek Myers, Bill Chunyuan Zheng, Oier Mees, Sergey Levine, and Kuan Fang. Policy adaptation via language op- timization: Decomposing tasks for few-shot imitation. In Conference on Robot Learning, 2024. 3
work page 2024
-
[43]
Mitsuhiko Nakamoto, Oier Mees, Aviral Kumar, and Sergey Levine. Steering your generalists: Improving robotic foun- dation models via value guidance.Conference on Robot Learning (CoRL), 2024. 3
work page 2024
-
[44]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[45]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023. 3
work page 2023
-
[46]
Fast: Efficient action tokenization for vision- language-action models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision- language-action models. InProceedings of Robotics: Sci- ence and Systems, Los Angeles, USA, 2025. 8
work page 2025
-
[47]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, 2021. 2
work page 2021
-
[48]
Real-world humanoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024
Ilija Radosavovic, Tete Xiao, Bike Zhang, Trevor Darrell, Jitendra Malik, and Koushil Sreenath. Real-world humanoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024. 3
work page 2024
-
[49]
Latent plans for task ag- nostic offline reinforcement learning
Erick Rosete-Beas, Oier Mees, Gabriel Kalweit, Joschka Boedecker, and Wolfram Burgard. Latent plans for task ag- nostic offline reinforcement learning. InProceedings of the 6th Conference on Robot Learning (CoRL), Auckland, New Zealand, 2022. 3
work page 2022
-
[50]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess `ı, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Lan- guage models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36:68539–68551,
-
[51]
Robovqa: Multimodal long-horizon reasoning for robotics
Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, De- bidatta Dwibedi, Keerthana Gopalakrishnan, Christine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J Joshi, et al. Robovqa: Multimodal long-horizon reasoning for robotics. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 645–652. IEEE,
-
[52]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junx- iao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf frame- work.arXiv preprint arXiv: 2409.19256, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Koala: Key frame-conditioned long video-llm
Reuben Tan, Ximeng Sun, Ping Hu, Jui-hsien Wang, Hanieh Deilamsalehy, Bryan A Plummer, Bryan Russell, and Kate Saenko. Koala: Key frame-conditioned long video-llm. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 13581–13591, 2024. 3
work page 2024
-
[55]
Shulin Tian, Ruiqi Wang, Hongming Guo, Penghao Wu, Yuhao Dong, Xiuying Wang, Jingkang Yang, Hao Zhang, Hongyuan Zhu, and Ziwei Liu. Ego-r1: Chain-of-tool- thought for ultra-long egocentric video reasoning.arXiv preprint arXiv:2506.13654, 2025. 2
-
[56]
Peter Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Adithya Jairam Vedagiri IYER, Sai Charitha Akula, Shusheng Yang, Jihan Yang, Manoj Middepogu, Ziteng Wang, et al. Cambrian-1: A fully open, vision-centric explo- ration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024. 7, 1
work page 2024
-
[57]
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions.arXiv preprint arXiv:2212.10560, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[58]
Zhenyu Wang, Aoxue Li, Zhenguo Li, and Xihui Liu. Genartist: Multimodal llm as an agent for unified image gen- eration and editing.Advances in Neural Information Pro- cessing Systems, 37:128374–128395, 2024. 2
work page 2024
-
[59]
Blip-3: A family of open large multimodal models
Le Xue, Manli Shu, Anas Awadalla, Jun Wang, An Yan, Senthil Purushwalkam, Honglu Zhou, Viraj Prabhu, Yutong Dai, Michael S Ryoo, et al. Blip-3: A family of open large multimodal models. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 6124–6135,
-
[60]
Magma: A foundation model for multi- modal ai agents
Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, et al. Magma: A foundation model for multi- modal ai agents. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14203–14214, 2025. 8
work page 2025
-
[61]
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, et al. Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents.arXiv preprint arXiv:2502.09560, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, et al. Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents. InForty-second International Conference on Machine Learning, 2025. 8, 2
work page 2025
-
[63]
React: Synergizing rea- soning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing rea- soning and acting in language models. InInternational Con- ference on Learning Representations (ICLR), 2023. 3
work page 2023
-
[64]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, 12 Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality.arXiv preprint arXiv:2304.14178, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Spatial mental modeling from limited views
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chan- drasegaran, Han Liu, Ranjay Krishna, et al. Spatial mental modeling from limited views. InStructural Priors for Vision Workshop at ICCV’25, 2025. 7, 1
work page 2025
-
[66]
Kaining Ying, Fanqing Meng, Jin Wang, Zhiqian Li, Han Lin, Yue Yang, Hao Zhang, Wenbo Zhang, Yuqi Lin, Shuo Liu, et al. Mmt-bench: A comprehensive multimodal bench- mark for evaluating large vision-language models towards multitask agi.arXiv preprint arXiv:2404.16006, 2024. 3
-
[67]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gao- hong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Robotic control via em- bodied chain-of-thought reasoning
Michał Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via em- bodied chain-of-thought reasoning. InConference on Robot Learning, 2024. 8
work page 2024
-
[69]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding.arXiv preprint arXiv:2306.02858, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
Jianrui Zhang, Mu Cai, Tengyang Xie, and Yong Jae Lee. Countercurate: Enhancing physical and semantic visio- linguistic compositional reasoning via counterfactual exam- ples.arXiv preprint arXiv:2402.13254, 2024. 7, 1
-
[71]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Multimodal chain-of- thought reasoning in language models.arXiv preprint arXiv:2302.00923, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[72]
Pareto optimal learning for estimating large language model errors
Theodore Zhao, Mu Wei, J Preston, and Hoifung Poon. Pareto optimal learning for estimating large language model errors. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10513–10529, 2024. 5
work page 2024
-
[73]
TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daum ´e III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. arXiv preprint arXiv:2412.10345, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Denny Zhou, Nathanael Sch ¨arli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models.arXiv preprint arXiv:2205.10625, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[75]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 8 13 Multimodal Reinforcement Learning with Agentic Verifier for AI Agents Supplementa...
work page 2023
-
[78]
The associated image (if any)
-
[79]
A model-generated answer:{generated text} TASK Extract a concise set of referencedentities, objects, and interactionsthat arevisibly present in the image. Focus on themain objectsand their key visible attributes. When descriptive expressions are used, preferexpressive but non-redundant termsthat capture the important visible features (e.g., “seedling with...
-
[80]
The original question:{question}
-
[81]
The associated video frames
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.