State Space Models for Bioacoustics: A Comparative Evaluation with Transformers
Pith reviewed 2026-05-17 02:38 UTC · model grok-4.3
The pith
BioMamba matches Transformer accuracy on wildlife sound tasks while using far less VRAM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
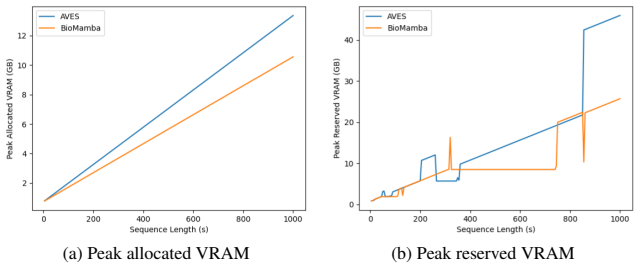
BioMamba is a Mamba-based audio representation model pre-trained via self-supervised learning on a large corpus of wildlife sounds. When tested on the BEANS benchmark, it reaches performance levels comparable to the state-of-the-art Transformer model AVES across diverse classification and detection tasks while significantly lowering VRAM consumption. The results indicate that the Mamba architecture offers a computationally efficient route for real-world environmental monitoring applications.
What carries the argument
BioMamba, a Mamba state-space architecture adapted for self-supervised audio representation of wildlife sounds.
If this is right
- Bioacoustic classification and detection tasks become feasible on devices with lower memory capacity than required by Transformers.
- Continuous environmental monitoring can run for longer periods or with more sensors under the same hardware constraints.
- Self-supervised pre-training on large audio corpora succeeds with Mamba for wildlife sound data.
- Mamba provides a direct alternative to Transformer models for scaling bioacoustic analysis in practice.
Where Pith is reading between the lines
- Mamba's linear scaling with sequence length may particularly suit the long recordings typical in bioacoustics.
- Efficiency gains could extend to other audio domains where memory limits currently constrain Transformer use.
- The approach invites direct comparisons on additional benchmarks to test whether the memory advantage holds across varied audio tasks.
Load-bearing premise
The reported VRAM reduction and accuracy parity result from the Mamba architecture itself rather than from differences in training details, model scale, or hardware setup.
What would settle it
A side-by-side retraining of both BioMamba and AVES from scratch on identical data splits, hyperparameters, and hardware while measuring exact VRAM usage and task accuracy.
Figures
read the original abstract
In this study, we evaluate the efficacy of the Mamba architecture bioacoustics by introducing BioMamba, a Mamba-based audio representation model for wildlife sounds. We pre-train a BioMamba using self-supervised learning on a large audio corpus and evaluate it on the BEANS benchmark across diverse classification and detection tasks. Compared to the state-of-the-art Transformer-based model (AVES), BioMamba achieves comparable performance while significantly reducing VRAM consumption. Our results demonstrate Mamba's potential as a computationally efficient alternative for real-world environmental monitoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BioMamba, a Mamba-based state-space model for bioacoustic audio representations. It is pre-trained via self-supervised learning on a large audio corpus and evaluated on the BEANS benchmark for diverse classification and detection tasks involving wildlife sounds. The central empirical claim is that BioMamba achieves performance comparable to the Transformer-based AVES model while consuming significantly less VRAM, positioning Mamba as a computationally efficient alternative for environmental monitoring applications.
Significance. If the comparison is shown to be controlled and the VRAM reduction is reproducible, the work would establish state-space models as viable, lower-memory substitutes for Transformers in bioacoustics, with direct implications for deploying representation models on edge devices for real-time wildlife monitoring. The introduction of a new pre-trained model (BioMamba) and its systematic evaluation on the established BEANS benchmark would add a useful data point to the growing literature on efficient sequence models for audio.
major comments (2)
- [Abstract, §4] Abstract and §4 (Results): the headline claim that BioMamba 'achieves comparable performance while significantly reducing VRAM consumption' is stated without any numerical values, tables, error bars, or statistical comparisons to AVES. This absence leaves the central empirical result without visible quantitative support in the provided text.
- [§3] §3 (Methods): the manuscript does not state whether the AVES baseline was re-trained from scratch using the identical self-supervised recipe, optimizer schedule, batch size, audio preprocessing pipeline, and hardware stack employed for BioMamba. Without this control, both the accuracy parity and the reported VRAM reduction cannot be unambiguously attributed to the Mamba architecture rather than implementation or training differences.
minor comments (2)
- [Abstract] The abstract refers to 'a large audio corpus' without naming the dataset or its size; this detail should be supplied in §2 or §3 for reproducibility.
- [§2] Notation for model dimensions, state-space parameters, and audio feature extraction is introduced without a dedicated table or equation block; adding a summary table of hyperparameters would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps clarify the presentation of our empirical results and experimental controls. We address each major comment below and outline the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Results): the headline claim that BioMamba 'achieves comparable performance while significantly reducing VRAM consumption' is stated without any numerical values, tables, error bars, or statistical comparisons to AVES. This absence leaves the central empirical result without visible quantitative support in the provided text.
Authors: We agree that the abstract and results would benefit from explicit quantitative support. In the revised manuscript we will update the abstract to report key metrics (e.g., mean accuracy across BEANS tasks and relative VRAM reduction) and will expand §4 to include the full comparison table with per-task scores, standard deviations, and direct VRAM measurements for both models. Statistical comparisons will be added where sample sizes permit. revision: yes
-
Referee: [§3] §3 (Methods): the manuscript does not state whether the AVES baseline was re-trained from scratch using the identical self-supervised recipe, optimizer schedule, batch size, audio preprocessing pipeline, and hardware stack employed for BioMamba. Without this control, both the accuracy parity and the reported VRAM reduction cannot be unambiguously attributed to the Mamba architecture rather than implementation or training differences.
Authors: We acknowledge the need for explicit methodological transparency. The AVES performance numbers are taken from the original AVES publication on the same BEANS tasks; re-training the full Transformer from scratch under identical conditions was not feasible within our compute budget. VRAM measurements, however, were obtained by running both models on the identical hardware and preprocessing pipeline. We will revise §3 to state these facts clearly, add a limitations paragraph discussing the implications, and include inference-time VRAM figures obtained under controlled conditions. revision: partial
Circularity Check
No circularity: empirical comparison without derivation chain
full rationale
The paper performs an empirical evaluation of BioMamba (Mamba-based) against AVES (Transformer) on the BEANS benchmark after self-supervised pre-training. No equations, derivations, or mathematical claims are present that could reduce predictions to fitted inputs or self-citations by construction. The central result (comparable accuracy at lower VRAM) rests on reported experimental measurements rather than any self-definitional or load-bearing self-citation structure. This is a standard self-contained empirical study; external benchmarks and direct comparisons provide independent grounding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-supervised learning on a large unlabeled audio corpus produces representations useful for downstream bioacoustics tasks
invented entities (1)
-
BioMamba
no independent evidence
Reference graph
Works this paper leans on
-
[1]
https://kaggle.com/birdsong-recognition
Cornell birdcall identification. https://kaggle.com/birdsong-recognition
-
[2]
Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A frame- work for self-supervised learning of speech representations.Advances in Neural Information Processing Systems (NeurIPS), 33:12449–12460, 2020
work page 2020
-
[3]
Hawaiian islands cetacean and ecosystem assessment survey (hiceas) towed array data
NOAA Pacific Islands Fisheries Science Center. Hawaiian islands cetacean and ecosystem assessment survey (hiceas) towed array data. edited and annotated for the 9th international workshop on detection, classification, localization, and density estimation of marine mammals using passive acoustics (dclde 2022), 2022
work page 2022
-
[4]
Vggsound: A large-scale audio-visual dataset
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. Vggsound: A large-scale audio-visual dataset. In2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 721–725, 2020
work page 2020
-
[5]
Lauren M. Chronister, Tessa A. Rhinehart, Aidan Place, and Justin Kitzes. An annotated set of audio recordings of eastern north american birds containing frequency, time, and species information.Ecology, 102(6):e03329, 2021
work page 2021
-
[6]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
work page 2022
-
[7]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
work page 2019
-
[9]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
work page 2021
-
[10]
Hansford, Amanda Hoepfner, Heidi Ma, Jessica V
Emmanuel Dufourq, Ian Durbach, James P. Hansford, Amanda Hoepfner, Heidi Ma, Jessica V . Bryant, Christina S. Stender, Wenyong Li, Zhiwei Liu, Qing Chen, Zhaoli Zhou, and Samuel T. Turvey. Automated detection of hainan gibbon calls for passive acoustic monitoring.Remote Sensing in Ecology and Conservation, 7(3):475–487, 2021
work page 2021
-
[11]
SSAST: Self-supervised audio spectrogram transformer
Yuan Gong, Cheng-I Lai, Yu-An Chung, and James Glass. SSAST: Self-supervised audio spectrogram transformer. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 10699–10709, 2022. 6
work page 2022
-
[12]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Aves: Animal vocalization encoder based on self-supervision
Masato Hagiwara. Aves: Animal vocalization encoder based on self-supervision. In2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, June 2023
work page 2023
-
[14]
Beans: The benchmark of animal sounds
Masato Hagiwara, Benjamin Hoffman, Jen-Yu Liu, Maddie Cusimano, Felix Effenberger, and Katie Zacarian. Beans: The benchmark of animal sounds. InICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, June 2023
work page 2023
-
[15]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
work page 2016
-
[16]
Shawn Hershey, Sourish Chaudhuri, Daniel P. W. Ellis, Jort F. Gemmeke, Aren Jansen, R. Chan- ning Moore, Manoj Plakal, Devin Platt, Rif A. Saurous, Bryan Seybold, Malcolm Slaney, Ron J. Weiss, and Kevin Wilson. Cnn architectures for large-scale audio classification. In2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), ...
work page 2017
-
[17]
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. Hubert: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM Trans. Audio, Speech and Lang. Proc., 29:3451–3460, October 2021
work page 2021
-
[18]
Xilin Jiang, Yinghao Aaron Li, Adrian Nicolas Florea, Cong Han, and Nima Mesgarani. Speech slytherin: Examining the performance and efficiency of mamba for speech separation, recognition, and synthesis. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
work page 2025
-
[19]
Humbugdb: A large-scale acoustic mosquito dataset
Ivan Kiskin, Marianne Sinka, Adam Cobb, Waqas Rafique, Lawrence Wang, Davide Zilli, Benjamin Gutteridge, Rinita Dam, Theodoros Marinos, Yunpeng Li, Dickson Msaky, Emmanuel Kaindoa, Gerard Killeen, Eva Herreros-Moya, Kathy Willis, and Stephen J Roberts. Humbugdb: A large-scale acoustic mosquito dataset. InProceedings of the Neural Information Processing Sy...
work page 2021
-
[20]
Reformer: The Efficient Transformer
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[21]
Velev, Rahul Dodhia, Juan Lav- ista Ferres, and T
Jack LeBien, Ming Zhong, Marconi Campos-Cerqueira, Julian P. Velev, Rahul Dodhia, Juan Lav- ista Ferres, and T. Mitchell Aide. A pipeline for identification of bird and frog species in tropical soundscape recordings using a convolutional neural network.Ecological Informatics, 59:101113, 2020
work page 2020
-
[22]
Jamba: A Hybrid Transformer-Mamba Language Model
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, et al. Jamba: A hybrid transformer-mamba language model.arXiv preprint arXiv:2403.19887, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Few-shot bioacoustic event detection: A new task at the dcase 2021 challenge
Veronica Morfi, Inês Nolasco, Vincent Lostanlen, Shubhr Singh, Ariana Strandburg-Peshkin, Lisa F Gill, Hanna Pamula, David Benvent, and Dan Stowell. Few-shot bioacoustic event detection: A new task at the dcase 2021 challenge. InDCASE, pages 145–149, 2021
work page 2021
-
[24]
Da Mu, Zhicheng Zhang, Haobo Yue, Zehao Wang, Jin Tang, and Jianqin Yin. Seld-mamba: Selective state-space model for sound event localization and detection with source distance estimation.arXiv preprint arXiv:2408.05057, 2024
-
[25]
Yosef Prat, Mor Taub, Ester Pratt, and Yossi Yovel. An annotated dataset of egyptian fruit bat vocalizations across varying contexts and during vocal ontogeny.Scientific data, 4(1):1–7, 2017. 7
work page 2017
-
[26]
The watkins marine mammal sound database: an online, freely accessible resource
Laela Sayigh, Mary Ann Daher, Julie Allen, Helen Gordon, Katherine Joyce, Claire Stuhlmann, and Peter Tyack. The watkins marine mammal sound database: an online, freely accessible resource. InProceedings of Meetings on Acoustics, volume 27, page 040013. Acoustical Society of America, 2016
work page 2016
-
[27]
Siavash Shams, Sukru Samet Dindar, Xilin Jiang, and Nima Mesgarani. SSAMBA: Self- supervised audio representation learning with mamba state space model.arXiv preprint arXiv:2405.11831, 2024
-
[28]
Linformer: Self-Attention with Linear Complexity
Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity.arXiv preprint arXiv:2006.04768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[29]
Sophia Yin and Brenda McCowan. Barking in domestic dogs: context specificity and individual identification.Animal behaviour, 68(2):343–355, 2004
work page 2004
-
[30]
Mamba in Speech: Towards an Alternative to Self-Attention,
Xiangyu Zhang, Jianbo Ma, Mostafa Shahin, Beena Ahmed, and Julien Epps. Mamba in speech: Towards an alternative to self-attention.arXiv preprint arXiv:2405.12609, 2024. 8
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.