Recognition: 2 theorem links
· Lean TheoremTempR1: Improving Temporal Understanding of MLLMs via Temporal-Aware Multi-Task Reinforcement Learning
Pith reviewed 2026-05-17 02:15 UTC · model grok-4.3
The pith
TempR1 strengthens multimodal large language models' grasp of time in videos and questions through a multi-task reinforcement learning framework that trains on diverse temporal patterns at once.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TempR1 is a temporal-aware multi-task reinforcement learning framework that curates a multi-task corpus exposing the model to diverse temporal structures and semantics, builds upon the Group Relative Policy Optimization algorithm to achieve stable cross-task optimization, categorizes temporal tasks into three correspondence types between predicted intervals and ground-truth instances, and designs tailored localization rewards for each type, attaining state-of-the-art performance across multiple benchmarks while producing a strong synergistic effect from joint optimization that enhances both generalization and single-task performance.
What carries the argument
The three-category reward design for predicted-versus-ground-truth interval correspondence inside a multi-task GRPO optimization loop.
If this is right
- State-of-the-art results on temporal localization, action detection, and time-sensitive question answering benchmarks.
- Synergistic gains that improve both generalization to new temporal patterns and performance on any single task.
- A scalable training paradigm that reduces the need for separate models per temporal skill.
- More robust handling of fine-grained temporal dependencies in long-form video analysis.
Where Pith is reading between the lines
- The same reward categorization could be adapted to improve spatial or causal reasoning tasks in multimodal models.
- Joint training might lower the volume of task-specific labels needed if the interval rewards transfer across domains.
- Real-world deployment on noisy or uncurated video streams would test whether the observed synergies persist outside benchmark conditions.
Load-bearing premise
The curated multi-task corpus and three-category reward design will produce stable cross-task gains without negative transfer or overfitting to the chosen temporal patterns.
What would settle it
A controlled experiment showing that joint multi-task training causes performance drops on one or more individual temporal benchmarks relative to single-task training baselines.
Figures



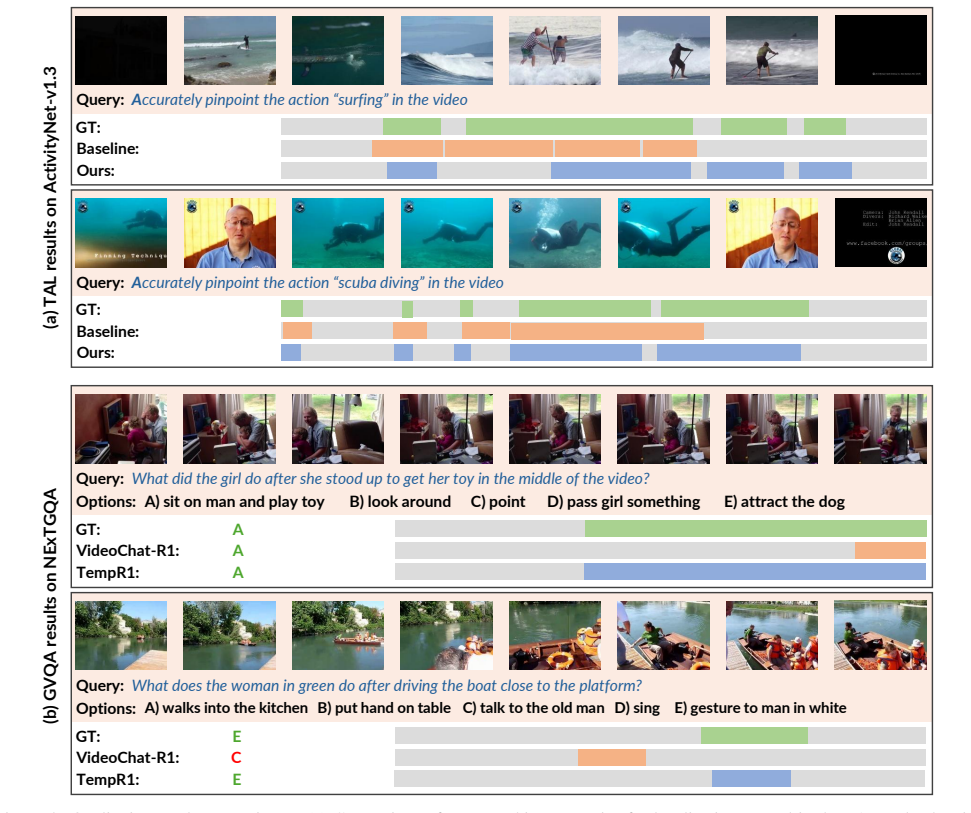
read the original abstract
Enhancing the temporal understanding of Multimodal Large Language Models (MLLMs) is essential for advancing long-form video analysis, enabling tasks such as temporal localization, action detection, and time-sensitive question answering. While reinforcement learning (RL) has recently been explored for improving temporal reasoning, existing approaches are often confined to limited task types and data, restricting their generalization across diverse temporal understanding scenarios. To address this challenge, we present TempR1, a temporal-aware multi-task reinforcement learning framework that systematically strengthens MLLMs' temporal comprehension. We curate a multi-task corpus that exposes the model to diverse temporal structures and semantics, and build upon the Group Relative Policy Optimization (GRPO) algorithm to achieve stable and effective cross-task optimization. Specifically, we categorize temporal tasks into three correspondence types between predicted intervals and ground-truth instances, and design tailored localization rewards for each, enabling TempR1 to capture fine-grained temporal dependencies and adapt to different temporal patterns. Extensive experiments demonstrate that TempR1 attains state-of-the-art performance across multiple benchmarks. Moreover, its joint optimization over complementary tasks yields a strong synergistic effect, enhancing both generalization and single-task performance, establishing a scalable and principled paradigm for temporal reasoning in MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TempR1, a temporal-aware multi-task reinforcement learning framework for Multimodal Large Language Models (MLLMs). It curates a multi-task corpus exposing the model to diverse temporal structures and employs Group Relative Policy Optimization (GRPO) with tailored localization rewards for three categories of predicted-versus-ground-truth interval correspondences. The central claims are that TempR1 achieves state-of-the-art performance across multiple benchmarks and that joint optimization over complementary tasks produces a synergistic effect improving both generalization and single-task performance.
Significance. If the empirical results and absence of negative transfer are substantiated, the work would offer a scalable paradigm for temporal reasoning in MLLMs by moving beyond single-task RL limitations, with potential benefits for long-form video analysis tasks such as localization and time-sensitive QA.
major comments (2)
- Abstract: the assertion of SOTA performance and a 'strong synergistic effect' from joint optimization lacks any reference to quantitative tables, ablation results, or cross-task performance metrics, rendering the central empirical claims unverifiable from the provided text and undermining assessment of whether the curated corpus and three-category rewards actually deliver stable gains without negative transfer under GRPO.
- Abstract: the three-category reward design for interval correspondence is described only at a high level ('tailored localization rewards for each'); without details on reward magnitude normalization, per-category coverage, or monitoring for gradient interference, the claim that this design avoids negative transfer or overfitting to chosen temporal patterns cannot be evaluated and is load-bearing for the synergistic-effect result.
minor comments (1)
- Abstract: the phrasing 'establishing a scalable and principled paradigm' is forward-looking and should be tempered to reflect that the manuscript demonstrates an approach rather than a fully established paradigm.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major comment below and indicate the specific revisions we will make to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: Abstract: the assertion of SOTA performance and a 'strong synergistic effect' from joint optimization lacks any reference to quantitative tables, ablation results, or cross-task performance metrics, rendering the central empirical claims unverifiable from the provided text and undermining assessment of whether the curated corpus and three-category rewards actually deliver stable gains without negative transfer under GRPO.
Authors: We agree that the abstract would be strengthened by explicit cross-references to the supporting empirical evidence. In the revised version we will update the abstract to include concise pointers such as 'as demonstrated in Tables 1–3 and Section 4.3' for the SOTA results and 'detailed ablation in Section 4.4 showing cross-task gains without negative transfer' for the synergistic effect. These additions will make the central claims directly verifiable while preserving the abstract’s brevity. revision: yes
-
Referee: Abstract: the three-category reward design for interval correspondence is described only at a high level ('tailored localization rewards for each'); without details on reward magnitude normalization, per-category coverage, or monitoring for gradient interference, the claim that this design avoids negative transfer or overfitting to chosen temporal patterns cannot be evaluated and is load-bearing for the synergistic-effect result.
Authors: The abstract necessarily summarizes the approach at a high level; the full reward formulations for the three correspondence categories are already specified in Section 3.2. To directly address the concern, we will expand Section 3.2 (and add a short paragraph in the abstract if space allows) with explicit details on reward magnitude normalization, per-category coverage statistics from the multi-task corpus, and the monitoring protocol used during GRPO training to detect and mitigate gradient interference. These additions will allow readers to evaluate the design’s contribution to stable joint optimization. revision: yes
Circularity Check
No circularity: empirical RL method with external benchmarks
full rationale
The paper describes an empirical framework that curates a multi-task corpus, defines three-category localization rewards, and applies GRPO for joint optimization. Performance claims rest on experimental results across standard benchmarks rather than any closed mathematical derivation. No equations are presented that reduce a claimed prediction or synergistic effect back to fitted reward parameters or self-referential definitions. The approach is self-contained against external evaluation and does not invoke load-bearing self-citations or uniqueness theorems from the authors' prior work.
Axiom & Free-Parameter Ledger
free parameters (1)
- Tailored localization rewards per correspondence type
axioms (1)
- domain assumption Joint optimization over complementary temporal tasks produces synergistic generalization gains
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we categorize temporal tasks into three correspondence types between predicted intervals and ground-truth instances, and design tailored localization rewards for each
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
R(TAL)loc = Rnum + Rmatch with DP-based matching and exp(-|Npred-Ngt|/...)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Localizing mo- ments in video with natural language
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing mo- ments in video with natural language. InProceedings of the IEEE international conference on computer vision, pages 5803–5812, 2017. 5
work page 2017
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 1, 2, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Sule Bai, Mingxing Li, Yong Liu, Jing Tang, Haoji Zhang, Lei Sun, Xiangxiang Chu, and Yansong Tang. Univg-r1: Reasoning guided universal visual grounding with reinforce- ment learning.arXiv preprint arXiv:2505.14231, 2025. 3
-
[5]
Dense events grounding in video
Peijun Bao, Qian Zheng, and Yadong Mu. Dense events grounding in video. InProceedings of the AAAI Conference on Artificial Intelligence, pages 920–928, 2021. 1, 2
work page 2021
-
[6]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InProceed- ings of the ieee conference on computer vision and pattern recognition, pages 961–970, 2015. 1, 2, 6, 7
work page 2015
-
[7]
Flashvtg: Feature layering and adaptive score handling network for video temporal grounding
Zhuo Cao, Bingqing Zhang, Heming Du, Xin Yu, Xue Li, and Sen Wang. Flashvtg: Feature layering and adaptive score handling network for video temporal grounding. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 9226–9236. IEEE, 2025. 2, 5
work page 2025
-
[8]
Scaling rl to long videos.arXiv preprint arXiv:2507.07966, 2025
Yukang Chen, Wei Huang, Baifeng Shi, Qinghao Hu, Han- rong Ye, Ligeng Zhu, Zhijian Liu, Pavlo Molchanov, Jan Kautz, Xiaojuan Qi, et al. Scaling rl to long videos.arXiv preprint arXiv:2507.07966, 2025. 3
-
[9]
Visrl: Intention-driven visual perception via reinforced reasoning
Zhangquan Chen, Xufang Luo, and Dongsheng Li. Visrl: Intention-driven visual perception via reinforced reasoning. arXiv preprint arXiv:2503.07523, 2025
-
[10]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025. 6, 7
work page 2025
-
[12]
Tall: Temporal activity localization via language query
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. Tall: Temporal activity localization via language query. In Proceedings of the IEEE international conference on com- puter vision, pages 5267–5275, 2017. 1, 2, 5, 6
work page 2017
-
[13]
Chaohong Guo, Xun Mo, Yongwei Nie, Xuemiao Xu, Chao Xu, Fei Yu, and Chengjiang Long. Tar-tvg: Enhancing vlms with timestamp anchor-constrained reasoning for temporal video grounding.arXiv preprint arXiv:2508.07683, 2025. 2, 5, 6
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Trace: Temporal grounding video llm via causal event modeling
Yongxin Guo, Jingyu Liu, Mingda Li, Qingbin Liu, Xi Chen, and Xiaoying Tang. TRACE: Temporal Grounding Video LLM via Causal Event Modeling.arXiv preprint arXiv:2410.05643, 2024. 2, 5
-
[16]
Vtimellm: Empower llm to grasp video moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. Vtimellm: Empower llm to grasp video moments. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 14271–14280, 2024. 2, 5
work page 2024
-
[17]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Zhenpeng Huang, Xinhao Li, Jiaqi Li, Jing Wang, Xi- angyu Zeng, Cheng Liang, Tao Wu, Xi Chen, Liang Li, and Limin Wang. Online Video Understanding: A Comprehen- sive Benchmark and Memory-Augmented Method.arXiv preprint arXiv:2501.00584, 2024. 2
-
[19]
Haroon Idrees, Amir R Zamir, Yu-Gang Jiang, Alex Gorban, Ivan Laptev, Rahul Sukthankar, and Mubarak Shah. The thumos challenge on action recognition for videos “in the wild”.Computer Vision and Image Understanding, 155:1– 23, 2017. 1
work page 2017
-
[20]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Knowing where to focus: Event-aware transformer for video grounding
Jinhyun Jang, Jungin Park, Jin Kim, Hyeongjun Kwon, and Kwanghoon Sohn. Knowing where to focus: Event-aware transformer for video grounding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13846–13856, 2023. 2, 5
work page 2023
-
[22]
Dense-captioning events in videos
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In Proceedings of the IEEE international conference on com- puter vision, pages 706–715, 2017. 1, 2, 6, 7
work page 2017
-
[23]
Detecting mo- ments and highlights in videos via natural language queries
Jie Lei, Tamara L Berg, and Mohit Bansal. Detecting mo- ments and highlights in videos via natural language queries. Advances in Neural Information Processing Systems, 34: 11846–11858, 2021. 1, 2, 5, 6
work page 2021
-
[24]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Unmasked teacher: Towards training-efficient video foundation models
Kunchang Li, Yali Wang, Yizhuo Li, Yi Wang, Yinan He, Limin Wang, and Yu Qiao. Unmasked teacher: Towards training-efficient video foundation models. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 19948–19960, 2023. 2 9
work page 2023
-
[26]
Pandeng Li, Chen-Wei Xie, Hongtao Xie, Liming Zhao, Lei Zhang, Yun Zheng, Deli Zhao, and Yongdong Zhang. Mo- mentdiff: Generative video moment retrieval from random to real.Advances in neural information processing systems, 36:65948–65966, 2023. 2
work page 2023
-
[27]
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning.arXiv preprint arXiv:2504.06958, 2025. 2, 5, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Ground- inggpt: Language enhanced multi-modal grounding model
Zhaowei Li, Qi Xu, Dong Zhang, Hang Song, Yiqing Cai, Qi Qi, Ran Zhou, Junting Pan, Zefeng Li, Vu Tu, et al. Ground- inggpt: Language enhanced multi-modal grounding model. InProceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 6657–6678, 2024. 2
work page 2024
-
[29]
Video-llava: Learning united visual repre- sentation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual repre- sentation by alignment before projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 5971–5984, 2024. 2
work page 2024
-
[30]
Univtg: Towards unified video- language temporal grounding
Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shra- man Pramanick, Difei Gao, Alex Jinpeng Wang, Rui Yan, and Mike Zheng Shou. Univtg: Towards unified video- language temporal grounding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2794–2804, 2023. 2, 5
work page 2023
-
[31]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1, 2
work page 2023
-
[32]
Umt: Unified multi-modal transformers for joint video moment retrieval and highlight detection
Ye Liu, Siyuan Li, Yang Wu, Chang-Wen Chen, Ying Shan, and Xiaohu Qie. Umt: Unified multi-modal transformers for joint video moment retrieval and highlight detection. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3042–3051, 2022. 2, 5
work page 2022
-
[33]
r 2-tuning: Ef- ficient image-to-video transfer learning for video temporal grounding
Ye Liu, Jixuan He, Wanhua Li, Junsik Kim, Donglai Wei, Hanspeter Pfister, and Chang Wen Chen. r 2-tuning: Ef- ficient image-to-video transfer learning for video temporal grounding. InEuropean Conference on Computer Vision, pages 421–438. Springer, 2024. 2
work page 2024
-
[34]
TempCompass: Do Video LLMs Really Understand Videos?
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcom- pass: Do video llms really understand videos?arXiv preprint arXiv:2403.00476, 2024. 6, 7
work page internal anchor Pith review arXiv 2024
-
[35]
Ye Liu, Zongyang Ma, Zhongang Qi, Yang Wu, Ying Shan, and Chang W Chen. E.T. Bench: Towards Open-Ended Event-Level Video-Language Understanding.Advances in Neural Information Processing Systems, 37:32076–32110,
-
[36]
Visual-RFT: Visual Reinforcement Fine-Tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual- rft: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
MUSEG: Reinforcing Video Temporal Understanding via Timestamp-Aware Multi-Segment Grounding
Fuwen Luo, Shengfeng Lou, Chi Chen, Ziyue Wang, Chen- liang Li, Weizhou Shen, Jiyue Guo, Peng Li, Ming Yan, Ji Zhang, et al. Museg: Reinforcing video temporal un- derstanding via timestamp-aware multi-segment grounding. arXiv preprint arXiv:2505.20715, 2025. 2, 5, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
WonJun Moon, Sangeek Hyun, Su Been Lee, and Jae-Pil Heo. Correlation-guided query-dependency calibration in video representation learning for temporal grounding.CoRR,
-
[39]
Query-dependent video representa- tion for moment retrieval and highlight detection
WonJun Moon, Sangeek Hyun, SangUk Park, Dongchan Park, and Jae-Pil Heo. Query-dependent video representa- tion for moment retrieval and highlight detection. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 23023–23033, 2023. 2, 5
work page 2023
-
[40]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Rein- forcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Re- casens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Mateusz Malinowski, Yi Yang, Carl Doersch, et al. Per- ception test: A diagnostic benchmark for multimodal video models.Advances in Neural Information Processing Sys- tems, 36:42748–42761, 2023. 6, 7
work page 2023
-
[42]
Chatvtg: Video temporal grounding via chat with video dialogue large language models
Mengxue Qu, Xiaodong Chen, Wu Liu, Alicia Li, and Yao Zhao. Chatvtg: Video temporal grounding via chat with video dialogue large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1847–1856, 2024. 2, 5
work page 2024
-
[43]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
work page 2021
-
[44]
Timechat: A time-sensitive multimodal large lan- guage model for long video understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large lan- guage model for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14313–14323, 2024. 2, 5
work page 2024
-
[45]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the Lim- its of Mathematical Reasoning in Open Language Models. arXiv preprint arXiv:2402.03300, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generaliz- able r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Fengyuan Shi, Weilin Huang, and Limin Wang. End-to-end dense video grounding via parallel regression.Computer Vi- sion and Image Understanding, 242:103980, 2024. 2, 6
work page 2024
-
[48]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232, 2024. 2
work page 2024
-
[49]
Tr- detr: Task-reciprocal transformer for joint moment retrieval and highlight detection
Hao Sun, Mingyao Zhou, Wenjing Chen, and Wei Xie. Tr- detr: Task-reciprocal transformer for joint moment retrieval and highlight detection. InProceedings of the AAAI Confer- ence on Artificial Intelligence, pages 4998–5007, 2024. 2 10
work page 2024
-
[51]
Hierarchical semantic correspondence net- works for video paragraph grounding
Chaolei Tan, Zihang Lin, Jian-Fang Hu, Wei-Shi Zheng, and Jianhuang Lai. Hierarchical semantic correspondence net- works for video paragraph grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18973–18982, 2023. 2, 6, 7
work page 2023
-
[52]
Hierarchical semantic correspondence net- works for video paragraph grounding
Chaolei Tan, Zihang Lin, Jian-Fang Hu, Wei-Shi Zheng, and Jianhuang Lai. Hierarchical semantic correspondence net- works for video paragraph grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18973–18982, 2023. 2
work page 2023
-
[53]
Canhui Tang, Zifan Han, Hongbo Sun, Sanping Zhou, Xu- chong Zhang, Xin Wei, Ye Yuan, Huayu Zhang, Jinglin Xu, and Hao Sun. Tspo: Temporal sampling policy optimization for long-form video language understanding.arXiv preprint arXiv:2508.04369, 2025. 3
-
[54]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Qi Wang, Yanrui Yu, Ye Yuan, Rui Mao, and Tianfei Zhou. Videorft: Incentivizing video reasoning capability in mllms via reinforced fine-tuning.arXiv preprint arXiv:2505.12434,
-
[56]
InternVideo: General Video Foundation Models via Generative and Discriminative Learning
Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, et al. Internvideo: General video foundation models via generative and discriminative learning.arXiv preprint arXiv:2212.03191, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[57]
Internvideo2: Scaling foundation models for mul- timodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. Internvideo2: Scaling foundation models for mul- timodal video understanding. InEuropean Conference on Computer Vision, pages 396–416. Springer, 2024. 2
work page 2024
-
[58]
Internvideo2: Scaling video foundation models for multimodal video understanding
Yueqian Wang, Xiaojun Meng, Jianxin Liang, Yuxuan Wang, Qun Liu, and Dongyan Zhao. Hawkeye: Training video- text llms for grounding text in videos.arXiv preprint arXiv:2403.10228, 2024. 2, 5
-
[59]
Yuxuan Wang, Yueqian Wang, Pengfei Wu, Jianxin Liang, Dongyan Zhao, Yang Liu, and Zilong Zheng. Effi- cient temporal extrapolation of multimodal large language models with temporal grounding bridge.arXiv preprint arXiv:2402.16050, 2024. 2
-
[60]
Time-R1: Post-Training Large Vision Language Model for Temporal Video Grounding
Ye Wang, Ziheng Wang, Boshen Xu, Yang Du, Kejun Lin, Zihan Xiao, Zihao Yue, Jianzhong Ju, Liang Zhang, Dingyi Yang, et al. Time-r1: Post-training large vision lan- guage model for temporal video grounding.arXiv preprint arXiv:2503.13377, 2025. 2, 5, 6, 7
work page internal anchor Pith review arXiv 2025
-
[61]
Jiaer Xia, Yuhang Zang, Peng Gao, Yixuan Li, and Kaiyang Zhou. Visionary-r1: Mitigating shortcuts in vi- sual reasoning with reinforcement learning.arXiv preprint arXiv:2505.14677, 2025. 3
-
[62]
Can i trust your answer? visually grounded video question answering
Junbin Xiao, Angela Yao, Yicong Li, and Tat-Seng Chua. Can i trust your answer? visually grounded video question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13204– 13214, 2024. 1, 2, 6, 7, 8
work page 2024
-
[63]
Yicheng Xiao, Zhuoyan Luo, Yong Liu, Yue Ma, Heng- wei Bian, Yatai Ji, Yujiu Yang, and Xiu Li. Bridging the gap: A unified video comprehension framework for mo- ment retrieval and highlight detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18709–18719, 2024. 2
work page 2024
-
[64]
arXiv preprint arXiv:2109.14084 , year=
Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. Videoclip: Contrastive pre-training for zero-shot video-text understanding.arXiv preprint arXiv:2109.14084, 2021. 2
-
[65]
Ziang Yan, Xinhao Li, Yinan He, Zhengrong Yue, Xiangyu Zeng, Yali Wang, Yu Qiao, Limin Wang, and Yi Wang. Videochat-r1. 5: Visual test-time scaling to reinforce mul- timodal reasoning by iterative perception.arXiv preprint arXiv:2509.21100, 2025. 2, 5, 6
-
[66]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xi- angpeng Wei, Hao Zhou, Jingjing Li...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Xiangyu Zeng, Kunchang Li, Chenting Wang, Xinhao Li, Tianxiang Jiang, Ziang Yan, Songze Li, Yansong Shi, Zhen- grong Yue, Yi Wang, et al. Timesuite: Improving mllms for long video understanding via grounded tuning.arXiv preprint arXiv:2410.19702, 2024. 2, 5
-
[68]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding.arXiv preprint arXiv:2306.02858, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[69]
Sc-captioner: Improving image captioning with self- correction by reinforcement learning
Lin Zhang, Xianfang Zeng, Kangcong Li, Gang Yu, and Tao Chen. Sc-captioner: Improving image captioning with self- correction by reinforcement learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23145–23155, 2025. 3
work page 2025
-
[70]
Tinyllava-video-r1: Towards smaller lmms for video reasoning
Xingjian Zhang, Siwei Wen, Wenjun Wu, and Lei Huang. Tinyllava-video-r1: Towards smaller lmms for video reason- ing.arXiv preprint arXiv:2504.09641, 2025. 3
-
[71]
Hacs: Human action clips and segments dataset for recognition and temporal localization
Hang Zhao, Antonio Torralba, Lorenzo Torresani, and Zhicheng Yan. Hacs: Human action clips and segments dataset for recognition and temporal localization. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision, pages 8668–8678, 2019. 6
work page 2019
-
[72]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. 7 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Rethinking the video sampling and reasoning strategies for temporal sentence grounding
Jiahao Zhu, Daizong Liu, Pan Zhou, Xing Di, Yu Cheng, Song Yang, Wenzheng Xu, Zichuan Xu, Yao Wan, Lichao Sun, et al. Rethinking the video sampling and reasoning strategies for temporal sentence grounding. InFindings of the Association for Computational Linguistics: EMNLP 2022, pages 590–600, 2022. 5 12
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.