Recognition: 2 theorem links
· Lean TheoremLearning Reachability of Energy Storage Arbitrage
Pith reviewed 2026-05-17 00:05 UTC · model grok-4.3
The pith
A stopping-time reward with SoC target penalty, trained end-to-end with price forecasts, makes storage arbitrage reach target charge levels more reliably while raising profits and cutting their variance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
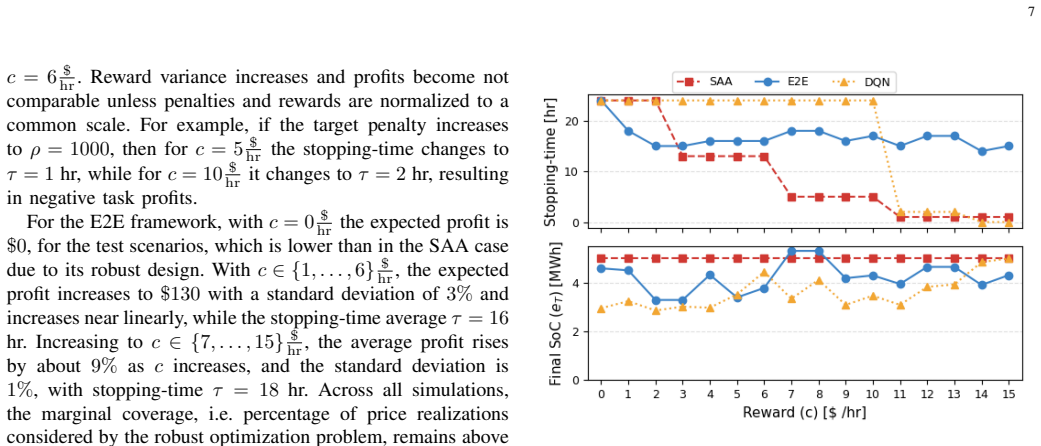
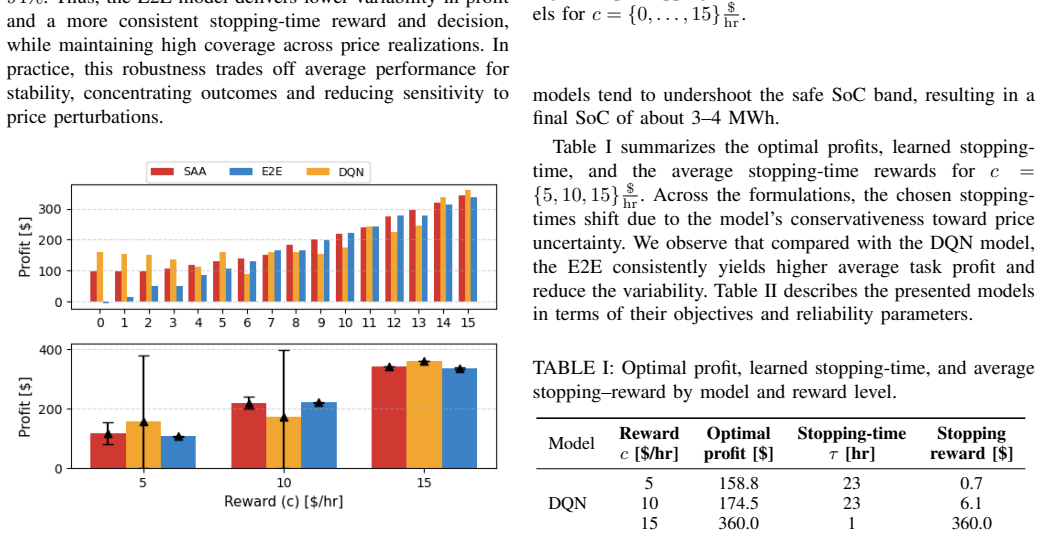
We introduce a stopping-time reward that, together with a state-of-charge (SoC) range target penalty, aligns arbitrage incentives with system reliability by rewarding storage that maintains sufficient SoC before critical hours. We formulate the problem as an online optimization with a chance-constrained terminal SoC and embed it in an end-to-end (E2E) learning framework, jointly training the price predictor and control policy. The proposed design enhances reachability of target SoC ranges, improves profit under volatile conditions, and reduces its standard deviation.
What carries the argument
Stopping-time reward plus SoC range target penalty inside a chance-constrained online optimization that is solved jointly with the price predictor in an end-to-end training loop.
If this is right
- Storage reaches target SoC ranges more reliably before critical hours.
- Arbitrage profits rise under volatile price conditions.
- Profit standard deviation falls, producing more stable returns.
- Myopic early discharge is reduced because future reliability value is explicitly rewarded.
Where Pith is reading between the lines
- The same stopping-time construction could be applied to other energy-limited assets such as pumped hydro or thermal storage.
- End-to-end training may prove useful for any sequential energy-market decision where forecast error and control interact strongly.
- Grid operators might be able to lower reserve margins if storage policies become more consistently reliable.
- Testing the method on price data from multiple markets would check whether the reliability gains generalize beyond the training distribution.
Load-bearing premise
Jointly training the price predictor and control policy under the new stopping-time reward produces out-of-sample policies that exceed myopic reliability without hidden forecast errors or constraint violations.
What would settle it
On unseen volatile price sequences, the learned policy reaches the target SoC range less often than the myopic baseline or records lower average profit together with higher variance.
Figures

read the original abstract
Power systems face increasing weather-driven variability and, therefore, increasingly rely on flexible but energy-limited storage resources. Energy storage can buffer this variability, but its value depends on intertemporal decisions under uncertain prices. Without accounting for the future reliability value of stored energy, batteries may act myopically, discharging too early or failing to preserve reserves during critical hours. This paper introduces a stopping-time reward that, together with a state-of-charge (SoC) range target penalty, aligns arbitrage incentives with system reliability by rewarding storage that maintains sufficient SoC before critical hours. We formulate the problem as an online optimization with a chance-constrained terminal SoC and embed it in an end-to-end (E2E) learning framework, jointly training the price predictor and control policy. The proposed design enhances reachability of target SoC ranges, improves profit under volatile conditions, and reduces its standard deviation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a stopping-time reward together with a state-of-charge (SoC) range target penalty to align energy-storage arbitrage incentives with system reliability needs. The problem is cast as an online optimization with a chance-constrained terminal SoC and is solved inside an end-to-end learning framework that jointly trains a price predictor and the control policy. The central claim is that the resulting policies improve reachability of target SoC ranges, raise profit under volatile price conditions, and reduce profit standard deviation relative to myopic baselines.
Significance. If the empirical claims are substantiated, the work would offer a concrete mechanism for embedding future reliability value into storage arbitrage decisions, which is relevant for power systems with rising weather-driven variability. The end-to-end training of predictor and policy is a methodological strength when it demonstrably improves out-of-sample reliability without hidden constraint violations.
major comments (2)
- [Abstract and §4] Abstract and §4 (results): the manuscript states that the design 'enhances reachability of target SoC ranges, improves profit under volatile conditions, and reduces its standard deviation' yet reports no numerical values, error bars, baseline comparisons, ablation studies, or out-of-sample violation rates. This absence is load-bearing for the central claim.
- [§3.2 and §3.3] §3.2 (stopping-time reward) and §3.3 (chance constraint): the reward is defined directly in terms of the target SoC range and critical-hour timing. Without reported out-of-sample terminal-SoC histograms or empirical violation frequencies compared to the prescribed probability level, it is unclear whether the learned policy produces independent reliability gains or merely reproduces the fitted target inside the training distribution.
minor comments (1)
- [§3] Notation for the stopping-time reward and the chance-constraint parameter should be introduced once with a clear reference to the equation number on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results): the manuscript states that the design 'enhances reachability of target SoC ranges, improves profit under volatile conditions, and reduces its standard deviation' yet reports no numerical values, error bars, baseline comparisons, ablation studies, or out-of-sample violation rates. This absence is load-bearing for the central claim.
Authors: We acknowledge the validity of this observation. The current version of the manuscript presents the results primarily through figures without accompanying numerical summaries in the text or abstract. To strengthen the substantiation of our claims, we have revised §4 to include a new table that reports specific numerical values for profit, standard deviation, reachability rates, and violation frequencies, along with comparisons to baselines and error bars from repeated experiments. Ablation studies are also added to isolate the effects of the proposed components. These changes make the empirical support explicit. revision: yes
-
Referee: [§3.2 and §3.3] §3.2 (stopping-time reward) and §3.3 (chance constraint): the reward is defined directly in terms of the target SoC range and critical-hour timing. Without reported out-of-sample terminal-SoC histograms or empirical violation frequencies compared to the prescribed probability level, it is unclear whether the learned policy produces independent reliability gains or merely reproduces the fitted target inside the training distribution.
Authors: This is a fair point regarding the need to verify generalization. While the chance-constrained formulation is intended to provide probabilistic guarantees, we recognize that explicit out-of-sample validation is crucial. In the revised manuscript, we have added terminal SoC histograms and empirical violation rate calculations on held-out test data. The results show that the violation frequencies are consistent with the prescribed levels and that the policy achieves improved reachability even under volatile price conditions not seen during training, indicating genuine reliability improvements rather than overfitting to the training distribution. revision: yes
Circularity Check
No circularity: reward and chance constraints are explicit design choices, not tautological reductions
full rationale
The paper defines a stopping-time reward plus SoC range penalty and chance-constrained terminal SoC as part of an end-to-end learning objective, then reports empirical improvements in reachability, profit, and variance on (presumably) held-out price paths. No equation or claim reduces a 'prediction' or 'result' to a fitted input by construction; the learning optimizes the stated objective and the performance claims rest on out-of-sample evaluation rather than algebraic identity. Self-citations, if present, are not load-bearing for the central empirical result. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- SoC range target
axioms (1)
- domain assumption Future prices are uncertain and benefit from a learned predictor
invented entities (1)
-
stopping-time reward
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
max E[ sum lambda_t (d_t - c_t) + sum r_t z_t ] s.t. chance constraint on terminal SoC and monotonic stopping z_t
-
IndisputableMonolith/Foundation/Atomicity.leanatomic_tick unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
stopping-time reward and reachability of SoC target band E_ell
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D. Bienstock, Y . Dvorkin, C. Guo, R. Mieth, and J. Wang, “Risk- aware security-constrained unit commitment: Taming the curse of real- time volatility and consumer exposure,”IEEE Transactions on Energy Markets, Policy and Regulation, 2024
work page 2024
-
[2]
2023 special report on battery storage,
CAISO, “2023 special report on battery storage,” CAISO, Tech. Rep., 2024
work page 2023
-
[3]
1186nprr-36 puct report 041124,
PUCT, “1186nprr-36 puct report 041124,” PUCT, Tech. Rep., 2024
work page 2024
-
[4]
Pg&e launches seasonal aggregation of versatile energy (save) virtual power plant program,
Pacific Gas and Electric Company, “Pg&e launches seasonal aggregation of versatile energy (save) virtual power plant program,” PG&E Corpo- ration, Oakland, CA, Mar. 2025
work page 2025
-
[5]
Estimating the value of electricity storage in pjm: Arbitrage and some welfare effects,
R. Sioshansi, P. Denholm, T. Jenkin, and J. Weiss, “Estimating the value of electricity storage in pjm: Arbitrage and some welfare effects,”Energy economics, vol. 31, no. 2, pp. 269–277, 2009
work page 2009
-
[6]
Operational valuation of energy storage under multi-stage price uncertainties,
B. Xu, M. Korp ˚as, and A. Botterud, “Operational valuation of energy storage under multi-stage price uncertainties,” in2020 59th IEEE Conference on Decision and Control (CDC). IEEE, 2020, pp. 55–60
work page 2020
-
[7]
Ensuring profitability of energy storage,
Y . Dvorkin, R. Fernandez-Blanco, D. S. Kirschen, H. Pand ˇzi´c, J.-P. Watson, and C. A. Silva-Monroy, “Ensuring profitability of energy storage,”IEEE Transactions on Power Systems, vol. 32, no. 1, pp. 611– 623, 2016
work page 2016
-
[8]
Arbitrage analysis for different energy storage technologies and strategies,
X. Zhang, C. C. Qin, E. Loth, Y . Xu, X. Zhou, and H. Chen, “Arbitrage analysis for different energy storage technologies and strategies,”Energy Reports, vol. 7, pp. 8198–8206, 2021
work page 2021
-
[9]
Pricing impacts of state of charge management options for electric storage resources,
N. G. Singhal and E. G. Ela, “Pricing impacts of state of charge management options for electric storage resources,” in2020 IEEE Power & Energy Society General Meeting (PESGM). IEEE, 2020, pp. 1–6
work page 2020
-
[10]
Energy storage arbitrage under day-ahead and real-time price uncertainty,
D. Krishnamurthy, C. Uckun, Z. Zhou, P. R. Thimmapuram, and A. Botterud, “Energy storage arbitrage under day-ahead and real-time price uncertainty,”IEEE Transactions on Power Systems, vol. 33, no. 1, pp. 84–93, 2017
work page 2017
-
[11]
Arbitraging variable efficiency energy storage using analytical stochastic dynamic programming,
N. Zheng, J. Jaworski, and B. Xu, “Arbitraging variable efficiency energy storage using analytical stochastic dynamic programming,”IEEE Transactions on Power Systems, vol. 37, no. 6, pp. 4785–4795, 2022
work page 2022
-
[12]
Chance- constrained generic energy storage operations under decision-dependent uncertainty,
N. Qi, P. Pinson, M. R. Almassalkhi, L. Cheng, and Y . Zhuang, “Chance- constrained generic energy storage operations under decision-dependent uncertainty,”IEEE Transactions on Sustainable Energy, vol. 14, no. 4, pp. 2234–2248, 2023
work page 2023
-
[13]
Chance-Constrained Energy Storage Pricing for Social Welfare Maximization
N. Qi, N. Zheng, and B. Xu, “Chance-constrained energy storage pricing for social welfare maximization,”arXiv preprint arXiv:2407.07068, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
M. Zhang, W. Li, S. S. Yu, K. Wen, and S. Muyeen, “Day-ahead optimization dispatch strategy for large-scale battery energy storage considering multiple regulation and prediction failures,”Energy, vol. 270, p. 126945, 2023
work page 2023
-
[15]
B. Cheng and W. B. Powell, “Co-optimizing battery storage for the frequency regulation and energy arbitrage using multi-scale dynamic programming,”IEEE Transactions on Smart Grid, vol. 9, no. 3, pp. 1997–2005, 2016
work page 1997
-
[16]
Online auc- tions and generalized secretary problems,
M. Babaioff, N. Immorlica, D. Kempe, and R. Kleinberg, “Online auc- tions and generalized secretary problems,”ACM SIGecom Exchanges, vol. 7, no. 2, pp. 1–11, 2008
work page 2008
-
[17]
Some problems of optimal stopping,
M. H. DeGroot, “Some problems of optimal stopping,”Journal of the Royal Statistical Society Series B: Statistical Methodology, vol. 30, no. 1, pp. 108–122, 1968
work page 1968
-
[18]
Risk-averse stochastic program- ming: Time consistency and optimal stopping,
A. Pichler, R. P. Liu, and A. Shapiro, “Risk-averse stochastic program- ming: Time consistency and optimal stopping,”Operations Research, vol. 70, no. 4, pp. 2439–2455, 2022
work page 2022
-
[19]
Time consistency of dynamic risk measures,
A. Shapiro, “Time consistency of dynamic risk measures,”Operations Research Letters, vol. 40, no. 6, pp. 436–439, 2012
work page 2012
-
[20]
T. R. Bielecki, I. Cialenco, and H. Liu, “Time consistency of dynamic risk measures and dynamic performance measures generated by distor- tion functions,”Stochastic Models, vol. 41, no. 2, pp. 180–207, 2025
work page 2025
-
[21]
Optimal algorithms for k- search with application in option pricing,
J. Lorenz, K. Panagiotou, and A. Steger, “Optimal algorithms for k- search with application in option pricing,”Algorithmica, vol. 55, no. 2, pp. 311–328, 2009
work page 2009
-
[22]
Online algorithms for the general k-search problem,
W. Zhang, Y . Xu, F. Zheng, and M. Liu, “Online algorithms for the general k-search problem,”Information processing letters, vol. 111, no. 14, pp. 678–682, 2011
work page 2011
-
[23]
P. Harsha and M. Dahleh, “Optimal management and sizing of energy storage under dynamic pricing for the efficient integration of renewable energy,”IEEE Transactions on Power Systems, vol. 30, no. 3, pp. 1164– 1181, 2014
work page 2014
-
[24]
Energy storage arbitrage in real-time markets via reinforcement learning,
H. Wang and B. Zhang, “Energy storage arbitrage in real-time markets via reinforcement learning,” in2018 IEEE Power & Energy Society General Meeting (PESGM). IEEE, 2018, pp. 1–5
work page 2018
-
[25]
Learning the operation of energy storage systems from real trajectories of demand and renewables,
A. Castellano and J. A. Bazerque, “Learning the operation of energy storage systems from real trajectories of demand and renewables,” in 2020 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT). IEEE, 2020, pp. 1–5
work page 2020
-
[26]
J. Cao, D. Harrold, Z. Fan, T. Morstyn, D. Healey, and K. Li, “Deep reinforcement learning-based energy storage arbitrage with accurate lithium-ion battery degradation model,”IEEE Transactions on Smart Grid, vol. 11, no. 5, pp. 4513–4521, 2020
work page 2020
-
[27]
Safe policies for reinforcement learning via primal-dual methods,
S. Paternain, M. Calvo-Fullana, L. F. Chamon, and A. Ribeiro, “Safe policies for reinforcement learning via primal-dual methods,”IEEE Transactions on Automatic Control, vol. 68, no. 3, pp. 1321–1336, 2022
work page 2022
-
[28]
Natural policy gradient primal-dual method for constrained markov decision processes,
D. Ding, K. Zhang, T. Basar, and M. Jovanovic, “Natural policy gradient primal-dual method for constrained markov decision processes,” Advances in Neural Information Processing Systems, vol. 33, pp. 8378– 8390, 2020
work page 2020
-
[29]
Constrained policy optimization,
J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained policy optimization,” inInternational conference on machine learning. PMLR, 2017, pp. 22–31
work page 2017
-
[30]
Projection-based constrained policy optimization,
T.-Y . Yang, J. Rosca, K. Narasimhan, and P. J. Ramadge, “Projection-based constrained policy optimization,”arXiv preprint arXiv:2010.03152, 2020
-
[31]
Set propagation techniques for reachability analysis,
M. Althoff, G. Frehse, and A. Girard, “Set propagation techniques for reachability analysis,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 4, no. 1, pp. 369–395, 2021
work page 2021
-
[32]
Reachability analysis and its application to the safety as- sessment of autonomous cars,
M. Althoff, “Reachability analysis and its application to the safety as- sessment of autonomous cars,” Ph.D. dissertation, Technische Universit¨at M¨unchen, 2010
work page 2010
-
[33]
Data-driven reachabil- ity with scenario optimization and the holdout method,
E. Dietrich, R. Devonport, S. Tu, and M. Arcak, “Data-driven reachabil- ity with scenario optimization and the holdout method,”arXiv preprint arXiv:2504.06541, 2025
-
[34]
Sampling-based reachability analysis: A random set theory approach with adversarial sampling,
T. Lew and M. Pavone, “Sampling-based reachability analysis: A random set theory approach with adversarial sampling,” inConference on robot learning. PMLR, 2021, pp. 2055–2070
work page 2021
-
[35]
Probabilistic reachability analysis of stochastic control systems,
S. Jafarpour, Z. Liu, and Y . Chen, “Probabilistic reachability analysis of stochastic control systems,”IEEE Transactions on Automatic Control, 2025
work page 2025
-
[36]
Confor- mal predictive programming for chance constrained optimization,
Y . Zhao, X. Yu, M. Sesia, J. V . Deshmukh, and L. Lindemann, “Confor- mal predictive programming for chance constrained optimization,”arXiv preprint arXiv:2402.07407, 2024
-
[37]
Learning decision-focused uncertainty sets in robust optimization,
I. Wang, C. Becker, B. Van Parys, and B. Stellato, “Learning decision-focused uncertainty sets in robust optimization,”arXiv preprint arXiv:2305.19225, 2023
-
[38]
Online search with predictions: Pareto-optimal algorithm and its applications in energy markets,
R. Lee, B. Sun, M. Hajiesmaili, and J. C. Lui, “Online search with predictions: Pareto-optimal algorithm and its applications in energy markets,” inProceedings of the 15th ACM International Conference on Future and Sustainable Energy Systems, 2024, pp. 386–407. 9
work page 2024
-
[39]
Electricity price prediction for energy storage system arbitrage: A decision-focused approach,
L. Sang, Y . Xu, H. Long, Q. Hu, and H. Sun, “Electricity price prediction for energy storage system arbitrage: A decision-focused approach,”IEEE Transactions on Smart Grid, vol. 13, no. 4, pp. 2822–2832, 2022
work page 2022
-
[40]
A. Lechowicz, N. Christianson, J. Zuo, N. Bashir, M. Hajiesmaili, A. Wierman, and P. Shenoy, “The online pause and resume problem: Optimal algorithms and an application to carbon-aware load shifting,” Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 7, no. 3, pp. 1–32, 2023
work page 2023
-
[41]
Online optimization with predictions and switching costs: Fast algorithms and the fundamental limit,
Y . Li, G. Qu, and N. Li, “Online optimization with predictions and switching costs: Fast algorithms and the fundamental limit,”IEEE Transactions on Automatic Control, vol. 66, no. 10, pp. 4761–4768, 2020
work page 2020
-
[42]
Task-based end-to-end model learning in stochastic optimization,
P. Donti, B. Amos, and J. Z. Kolter, “Task-based end-to-end model learning in stochastic optimization,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[43]
End-to-end conformal calibration for optimization under uncertainty,
C. Yeh, N. Christianson, A. Wu, A. Wierman, and Y . Yue, “End-to-end conformal calibration for optimization under uncertainty,”arXiv preprint arXiv:2409.20534, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.