LayerPipe2: Multistage Pipelining and Weight Recompute via Improved Exponential Moving Average for Training Neural Networks
Pith reviewed 2026-05-17 00:32 UTC · model grok-4.3
The pith
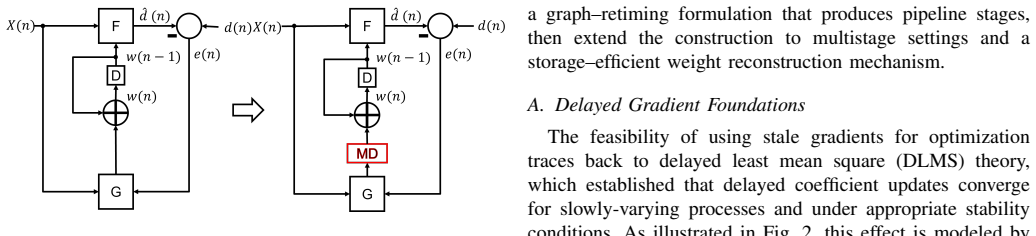
Pipelined neural network training requires delays that increase with layer depth and uses a moving average to reconstruct past weights instead of storing them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
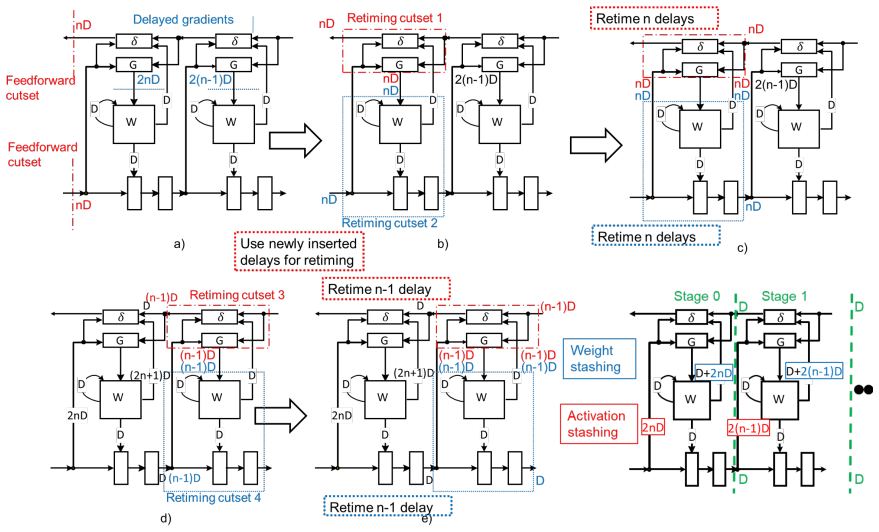
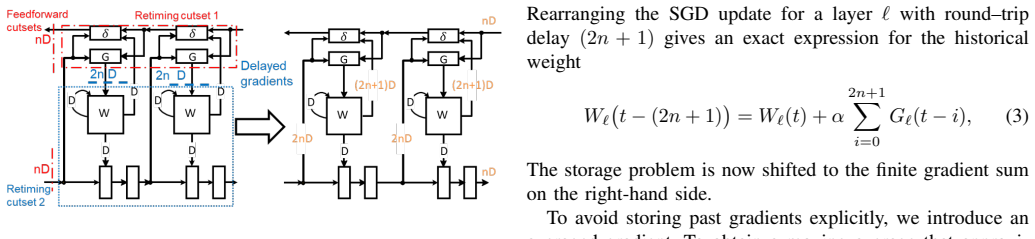
We formally derive LayerPipe using variable delayed gradient adaptation and retiming. We identify where delays may be legally inserted and show that the required amount of delay follows directly from the network structure where inner layers require fewer delays and outer layers require longer delays. When pipelining is applied at every layer, the amount of delay depends only on the number of remaining downstream stages. When layers are pipelined in groups, all layers in the group share the same assignment of delays. We overcome this storage bottleneck by developing a pipeline-aware moving average that reconstructs the required past states rather than storing them explicitly.
What carries the argument
Variable delayed gradient adaptation and retiming that assigns delays based on downstream stage count, paired with a pipeline-aware moving average for on-the-fly weight state reconstruction.
If this is right
- Architectures can be constructed with delay assignments predicted directly from network depth and grouping choices.
- Memory overhead drops without loss of the accuracy properties that make pipelined learning viable.
- Communication-computation tradeoffs become controllable through choices of per-layer versus grouped pipelining.
- Observed scheduling patterns in prior pipelined training receive a structural explanation tied to remaining downstream stages.
Where Pith is reading between the lines
- The same delay-assignment logic may extend to recurrent or transformer architectures whose dependency graphs differ from feed-forward stacks.
- Hardware accelerators could exploit the reduced storage requirement to increase batch sizes or model widths under fixed memory budgets.
- The moving-average reconstruction might be tuned with different decay factors per layer to further improve fidelity in deeper networks.
- Combining this approach with quantization of the reconstructed states could yield additional memory savings in distributed training setups.
Load-bearing premise
The pipeline-aware moving average reconstructs required past weight states accurately enough to preserve the convergence and accuracy guarantees of the original non-pipelined training.
What would settle it
Run identical training on a fixed network and dataset once with explicit storage of all historical weights and once with the moving-average reconstruction, then compare final test accuracy and convergence curves for any measurable difference.
Figures

read the original abstract
In our prior work, LayerPipe, we had introduced an approach to accelerate training of convolutional, fully connected, and spiking neural networks by overlapping forward and backward computation. However, despite empirical success, a principled understanding of how much gradient delay needs to be introduced at each layer to achieve desired level of pipelining was not addressed. This paper, LayerPipe2, fills that gap by formally deriving LayerPipe using variable delayed gradient adaptation and retiming. We identify where delays may be legally inserted and show that the required amount of delay follows directly from the network structure where inner layers require fewer delays and outer layers require longer delays. When pipelining is applied at every layer, the amount of delay depends only on the number of remaining downstream stages. When layers are pipelined in groups, all layers in the group share the same assignment of delays. These insights not only explain previously observed scheduling patterns but also expose an often overlooked challenge that pipelining implicitly requires storage of historical weights. We overcome this storage bottleneck by developing a pipeline--aware moving average that reconstructs the required past states rather than storing them explicitly. This reduces memory cost without sacrificing the accuracy guarantees that makes pipelined learning viable. The result is a principled framework that illustrates how to construct LayerPipe architectures, predicts their delay requirements, and mitigates their storage burden, thereby enabling scalable pipelined training with controlled communication computation tradeoffs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends the authors' prior LayerPipe work by formally deriving multistage pipelining for neural network training via variable delayed gradient adaptation and retiming. It identifies legal delay insertion points from network structure (inner layers require fewer delays, outer layers longer delays), shows that per-layer delay equals the number of remaining downstream stages when pipelining every layer or is shared within groups, and introduces a pipeline-aware moving average to reconstruct historical weights instead of storing them explicitly, thereby reducing memory while claiming to preserve accuracy guarantees.
Significance. If the retiming derivation is sound and the EMA reconstruction maintains equivalence to non-pipelined training, the work supplies a principled framework that explains observed scheduling patterns, predicts delay requirements directly from topology, and mitigates the storage bottleneck that otherwise limits pipelined training scalability for CNNs, MLPs, and spiking networks.
major comments (2)
- [Formal derivation of delays] The central claim that delays follow directly from network structure (inner layers fewer, outer more) and equal the number of downstream stages rests on the retiming derivation; the manuscript must supply the explicit delay-assignment equations or theorem (likely in the formal derivation section) so that the 'parameter-free' property can be verified rather than asserted.
- [Weight recompute via improved EMA] § on pipeline-aware moving average / weight recompute: the claim that the improved EMA reconstructs required past weight states accurately enough to preserve convergence and accuracy guarantees is load-bearing for the memory-reduction contribution. Under variable per-layer delays the reconstruction must be shown to remain faithful when gradients are non-stationary or when momentum/adaptive optimizers are used; without error bounds or an ablation comparing EMA-reconstructed vs. explicitly stored weights, the equivalence to non-pipelined training is not yet established.
minor comments (2)
- [Introduction] Clarify in the introduction exactly which scheduling patterns from the original LayerPipe paper are now explained by the new delay formulas.
- [Abstract] The abstract refers to an 'improved' EMA; the manuscript should state the precise modification (e.g., pipeline-aware weighting or multi-stage correction term) relative to standard EMA.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important aspects of the formal derivation and the weight recomputation method that we address point by point below.
read point-by-point responses
-
Referee: [Formal derivation of delays] The central claim that delays follow directly from network structure (inner layers fewer, outer more) and equal the number of downstream stages rests on the retiming derivation; the manuscript must supply the explicit delay-assignment equations or theorem (likely in the formal derivation section) so that the 'parameter-free' property can be verified rather than asserted.
Authors: We agree that an explicit formulation will make the parameter-free property easier to verify. Section 3 derives the legal delay insertion points from the retiming rules on the computation graph and shows that, for a pipeline of S stages, the delay at layer l equals the number of remaining downstream stages. When layers are grouped for pipelining, the delay is shared within each group. In the revision we will add a concise theorem statement together with the delay-assignment equation and a short proof sketch so that readers can directly check the claimed dependence on network structure alone. revision: yes
-
Referee: [Weight recompute via improved EMA] § on pipeline-aware moving average / weight recompute: the claim that the improved EMA reconstructs required past weight states accurately enough to preserve convergence and accuracy guarantees is load-bearing for the memory-reduction contribution. Under variable per-layer delays the reconstruction must be shown to remain faithful when gradients are non-stationary or when momentum/adaptive optimizers are used; without error bounds or an ablation comparing EMA-reconstructed vs. explicitly stored weights, the equivalence to non-pipelined training is not yet established.
Authors: We acknowledge that additional evidence would strengthen the memory-reduction claim. The pipeline-aware EMA is constructed to match the per-layer delay by modulating the averaging window accordingly. Existing experiments on CNNs, MLPs and spiking networks already show that final accuracy and convergence curves remain statistically indistinguishable from non-pipelined training, including under Adam. To address the referee’s concern directly we will add, in the revision, an ablation that compares EMA-reconstructed weights against explicitly stored historical weights and will include a short discussion of behavior under non-stationary gradients and adaptive optimizers. revision: partial
Circularity Check
Formal retiming derivation and EMA reconstruction presented as independent of fitted experimental values
full rationale
The paper's core contribution is a formal derivation of legal delay insertion points and per-layer delay amounts directly from network topology and retiming rules (inner layers fewer delays, outer layers more; delay depends on remaining downstream stages). This is framed as filling a gap left by the authors' prior empirical LayerPipe work rather than relying on it for the math. The pipeline-aware EMA is introduced as an explicit reconstruction technique to avoid storing historical weights, with the claim that it preserves non-pipelined accuracy guarantees under the derived schedules. No equations or steps are shown reducing the derived delays or EMA updates to quantities fitted from the current paper's experiments; the derivation is presented as following from standard retiming applied to the graph structure. Self-citation to the earlier LayerPipe paper is limited to motivating the empirical success and the storage problem, not as load-bearing justification for the new formal results. The analysis is therefore self-contained against external retiming concepts and does not exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Retiming rules from synchronous circuit design can be applied to neural-network computation graphs to determine legal gradient delay placements.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify where delays may be legally inserted and show that the required amount of delay follows directly from the network structure where inner layers require fewer delays and outer layers require longer delays... pipeline-aware moving average that reconstructs the required past states
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Brain-inspired computing: Models and architectures,
K. K. Parhi and N. K. Unnikrishnan, “Brain-inspired computing: Models and architectures,” IEEE Open Journal of Circuits and Systems , vol. 1, pp. 185–204, 2020
work page 2020
-
[2]
ImageNet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” Communications of the ACM, vol. 60, p. 84–90, May 2017
work page 2017
-
[3]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems (NeurIPS) , 2017
work page 2017
-
[4]
Deep learning in medical image analysis,
D. Shen, G. Wu, and H.-I. Suk, “Deep learning in medical image analysis,” Annual Review of Biomedical Engineering , vol. 19, pp. 221– 248, 2017
work page 2017
-
[5]
Deep Learning Recommendation Model for Personalization and Recommendation Systems
M. Naumov, D. Mudigere, H.-J. M. Shi, J. Huang, N. Sundaraman, J. Park, X. Wang, U. Gupta, C.-J. Wu, A. G. Azzolini, et al. , “Deep learning recommendation model for personalization and recommenda- tion systems,” arXiv preprint arXiv:1906.00091 , 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[6]
Energy and policy consider- ations for deep learning in NLP,
E. Strubell, A. Ganesh, and A. McCallum, “Energy and policy consider- ations for deep learning in NLP,” in Proceedings of the Annual Meeting of the Association for Computational Linguistics , pp. 3645–3650, 2019
work page 2019
-
[7]
Nvidia hopper GPU: Scaling perfor- mance,
J. Choquette and R. Krashinsky, “Nvidia hopper GPU: Scaling perfor- mance,” in Proceedings of the Hot Chips Symposium , pp. 1–46, 2022
work page 2022
-
[8]
In-datacenter performance analysis of a tensor processing unit,
N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borchers, et al. , “In-datacenter performance analysis of a tensor processing unit,” in Proceedings of the International Symposium on Computer Architecture , 2017
work page 2017
-
[9]
Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices,
Y .-H. Chen, T.-J. Yang, J. S. Emer, and V . Sze, “Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices,” IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 9, no. 2, pp. 292–308, 2019
work page 2019
-
[10]
SCV-GNN: Sparse compressed vector-based graph neural network aggregation,
N. K. Unnikrishnan, J. Gould, and K. K. Parhi, “SCV-GNN: Sparse compressed vector-based graph neural network aggregation,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 42, no. 12, pp. 4803–4816, 2023
work page 2023
-
[11]
N. K. Unnikrishnan and K. K. Parhi, “LayerPipe: Accelerating deep neural network training by intra-layer and inter-layer gradient pipelining and multiprocessor scheduling,” in Proceedings of the International Conference on Computer-Aided Design (ICCAD) , pp. 1–9, IEEE, 2021
work page 2021
-
[12]
Determining the minimum iteration period of an algorithm,
K. Ito and K. K. Parhi, “Determining the minimum iteration period of an algorithm,” Springer Journal of VLSI Signal Processing , vol. 11, pp. 229–244, 1995
work page 1995
-
[13]
A gradient-interleaved scheduler for energy-efficient backpropagation for training neural networks,
N. K. Unnikrishnan and K. K. Parhi, “A gradient-interleaved scheduler for energy-efficient backpropagation for training neural networks,” in Proceedings of the International Symposium on Circuits and Systems (ISCAS), pp. 1–5, 2020
work page 2020
-
[14]
N. K. Unnikrishnan and K. K. Parhi, “InterGrad: Energy-efficient train- ing of convolutional neural networks via interleaved gradient schedul- ing,” IEEE Transactions on Circuits and Systems I: Regular Papers , vol. 70, no. 5, pp. 1949–1962, 2023
work page 1949
-
[15]
PipeDream: Generalized pipeline parallelism for DNN training,
D. Narayanan, A. Harlap, A. Phanishayee, V . Seshadri, N. R. Devanur, G. R. Ganger, P. B. Gibbons, and M. Zaharia, “PipeDream: Generalized pipeline parallelism for DNN training,” in Proceedings of the ACM Symposium on Operating Systems Principles , p. 1–15, 2019
work page 2019
-
[16]
GPipe: efficient training of giant neural networks using pipeline parallelism,
Y . Huang, Y . Cheng, A. Bapna, O. Firat, M. X. Chen, D. Chen, H. Lee, J. Ngiam, Q. V . Le, Y . Wu, and Z. Chen, “GPipe: efficient training of giant neural networks using pipeline parallelism,” in Advances in Neural Information Processing Systems , 2019
work page 2019
-
[17]
Memory-efficient pipeline-parallel DNN training,
D. Narayanan, A. Phanishayee, K. Shi, X. Chen, and M. Zaharia, “Memory-efficient pipeline-parallel DNN training,” in Proceedings of the International Conference on Machine Learning , pp. 7937–7947, 2021
work page 2021
-
[18]
K. K. Parhi, VLSI Digital Signal Processing Systems: Design and Implementation. Wiley-Interscience, 1999
work page 1999
-
[19]
E. A. Lee and D. G. Messerschmitt, “Synchronous data flow,” Proceed- ings of the IEEE , vol. 75, no. 9, pp. 1235–1245, 1987
work page 1987
-
[20]
The LMS algorithm with delayed coefficient adaptation,
G. Long, F. Ling, and J. G. Proakis, “The LMS algorithm with delayed coefficient adaptation,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 37, no. 9, pp. 1397–1405, 1989
work page 1989
-
[21]
Retiming synchronous circuitry,
C. E. Leiserson and J. B. Saxe, “Retiming synchronous circuitry,” Algorithmica, vol. 6, no. 1, pp. 5–35, 1991
work page 1991
-
[22]
Haykin, Adaptive Filter Theory
S. Haykin, Adaptive Filter Theory . Prentice Hall, 4 ed., 2002
work page 2002
-
[23]
Accurate, large minibatch SGD: Training ImageNet in 1 hour,
P. Goyal, P. Doll ´ar, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y . Jia, and K. He, “Accurate, large minibatch SGD: Training ImageNet in 1 hour,” in Proceedings of the International Conference on Learning Representations, 2017
work page 2017
-
[24]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catan- zaro, “Megatron-LM: Training multi-billion parameter language models using model parallelism,” arXiv preprint arXiv:1909.08053 , 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[25]
Beyond data and model parallelism for deep neural networks.,
Z. Jia, M. Zaharia, and A. Aiken, “Beyond data and model parallelism for deep neural networks.,” in Proceedings of Machine Learning and Systems (A. Talwalkar, V . Smith, and M. Zaharia, eds.), vol. 1, pp. 1– 13, 2019
work page 2019
-
[26]
On the acceleration of deep learning model parallelism with staleness,
A. Xu, Z. Huo, and H. Huang, “On the acceleration of deep learning model parallelism with staleness,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pp. 2089– 2098, 2020
work page 2089
-
[27]
K. K. Parhi and D. G. Messerschmitt, “Pipeline interleaving and parallelism in recursive digital filters. i. pipelining using scattered look- ahead and decomposition,”IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 37, no. 7, pp. 1099–1117, 1989
work page 1989
-
[28]
Relaxed look-ahead pipelined LMS adaptive filters and their application to ADPCM coder,
N. R. Shanbhag and K. K. Parhi, “Relaxed look-ahead pipelined LMS adaptive filters and their application to ADPCM coder,” IEEE Transac- tions on Circuits and Systems II: Analog and Digital Signal Processing , vol. 40, no. 12, pp. 753–766, 1993
work page 1993
-
[29]
S. Sanjeet, B. D. Sahoo, and K. K. Parhi, “SpikePipe: Accelerated training of spiking neural networks via inter-layer pipelining and multi- processor scheduling,” IEEE Transactions on Circuits and Systems for Artificial Intelligence, vol. 1, no. 2, pp. 149–163, 2024
work page 2024
-
[30]
Exponential Moving Average of Weights in Deep Learning: Dynamics and Benefits
D. Morales-Brotons, T. V ogels, and H. Hendrikx, “Exponential moving average of weights in deep learning: Dynamics and benefits,” arXiv preprint arXiv:2411.18704, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.