Recognition: 2 theorem links
· Lean TheoremEnd-to-end PDDL Planning with Hardcoded and Dynamic Agents
Pith reviewed 2026-05-16 23:31 UTC · model grok-4.3
The pith
An LLM orchestrator converts natural language specs into verified PDDL plans using hardcoded and dynamic agents with no human input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an LLM-powered orchestrator combined with two categories of agents can produce a complete, validated PDDL model from an ambiguous natural language input: hardcoded agents apply predefined fixes for syntax, time constraints and similar issues, while dynamic agents revise the latent planning abstraction to fit the specific domain, after which any external PDDL engine computes a plan and the system translates it back to natural language while preserving correctness.
What carries the argument
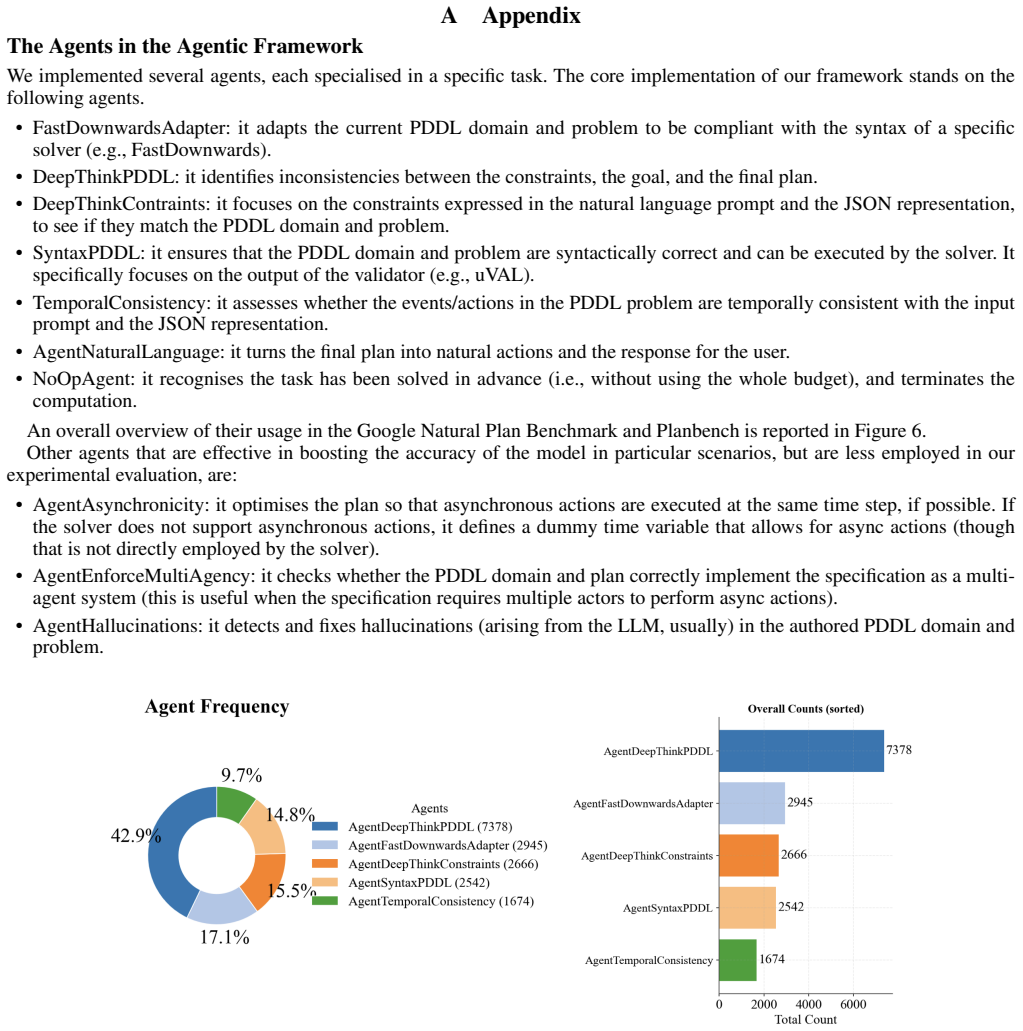
The orchestrator together with its hardcoded agents (pre-defined goals informed by logs and traces) and dynamic agents (no fixed goal, domain-adaptive revision of planning abstraction), all implemented via LLMs, that iteratively refine the PDDL model before external plan generation.
If this is right
- The framework works with any PDDL planning engine and validator, including Fast Downward, LPG, POPF, VAL and uVAL.
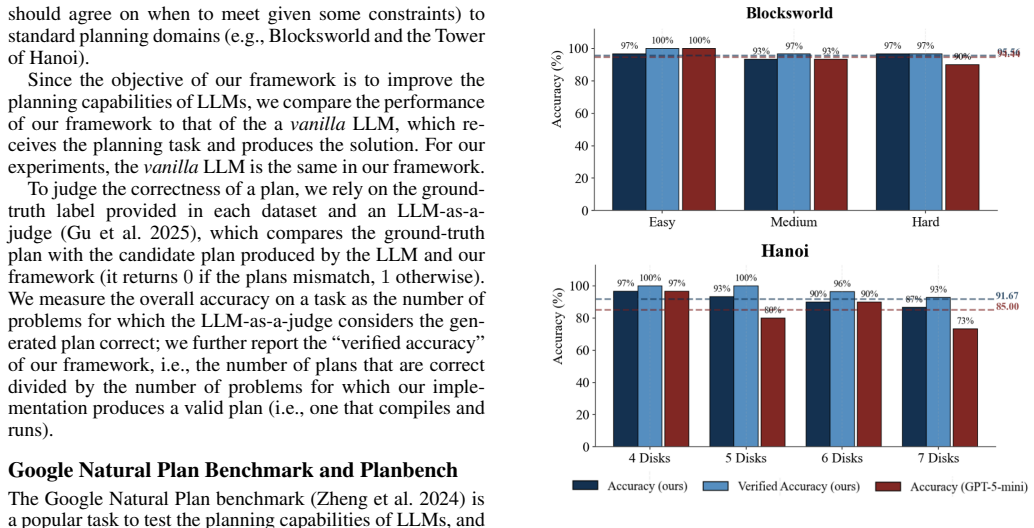
- It produces usable plans on domains such as Sokoban, Blocksworld and Tower of Hanoi where standalone LLMs fail even on small instances.
- The final plan is rendered back into natural language while each step remains correct.
- Performance holds across GPT-4o, GPT-5-mini, GPT-5.4, Gemini-2.5-flash and Gemini-3-flash on the Google NaturalPlan benchmark and Planbench.
- The system requires zero human intervention from specification receipt through plan output.
Where Pith is reading between the lines
- The hybrid hardcoded-plus-dynamic design may transfer to other tasks that convert informal requirements into formal specifications.
- Dynamic agents could allow the system to handle entirely new domains without additional hardcoded rules.
- Success still depends on the coverage of the chosen external validators; gaps in validator expressiveness would limit reliability.
- Further gains are likely if stronger LLMs reduce the number of refinement cycles needed.
Load-bearing premise
LLM agents can detect and repair every ambiguity, contradiction, syntax problem and constraint violation in the original specification without missing errors or creating new ones that external validators fail to catch.
What would settle it
A trial input containing a clear contradiction or unstated constraint where the generated PDDL passes all validators yet the external planner returns a plan that violates the original natural language requirement.
Figures






read the original abstract
We present an end-to-end framework for planning supported by verifiers. An orchestrator receives a human specification written in natural language and converts it into a PDDL (Planning Domain Definition Language) model, where the domain and problem are iteratively refined by sub-modules (agents) to address common planning requirements, such as time constraints and optimality, as well as ambiguities and contradictions that may exist in the human specification. We support two categories of agents: hardcoded, which are informed by logs and error traces and have a pre-defined goal (e.g., fix issues with PDDL syntax, check temporal constraints), and dynamic, which have no predefined goal but adapt to the specific domain and revise the latent planning abstraction. The validated domain and problem are then passed to an external planning engine to generate a plan. The orchestrator and agents are powered by Large Language Models (LLMs) and require no human intervention at any stage of the process. Finally, a module translates the final plan back into natural language to improve human readability while maintaining the correctness of each step. We demonstrate the flexibility and effectiveness of our framework on GPT-\{4o, 5-mini, 5.4\}, and Gemini-\{2.5, 3\}-flash across more than ten domains and tasks, including the Google NaturalPlan benchmark, Planbench, and classic planning problems like Sokoban, Blocksworld and the Tower of Hanoi, where LLMs are known to struggle even with small instances. Our framework can be integrated with any PDDL planning engine and validator (we successfully tested Fast Downward, LPG, POPF, VAL, and uVAL) and represents a significant step toward end-to-end planning aided by LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an end-to-end LLM-orchestrated framework for PDDL planning: an orchestrator converts natural-language specifications into domain and problem files, which are iteratively refined by hardcoded agents (pre-defined goals for syntax, temporal, and log-based fixes) and dynamic agents (goal-free adaptation of latent abstractions), validated via external tools (VAL, uVAL), solved by standard planners (Fast Downward, LPG, POPF), and finally translated back to readable natural language. The system requires no human intervention and is evaluated on GPT-4o/5-mini/5.4 and Gemini-2.5/3-flash across >10 domains including NaturalPlan, PlanBench, Sokoban, Blocksworld, and Tower of Hanoi.
Significance. If the reliability claims hold, the architecture offers a concrete, modular way to handle specification ambiguities and common PDDL pitfalls with LLMs while preserving compatibility with existing validators and solvers; the separation of hardcoded and dynamic agents is a useful design distinction. However, the absence of quantitative success rates, failure-mode analysis, or baseline comparisons in the reported evaluation weakens the ability to assess whether the framework actually delivers reliable end-to-end correctness.
major comments (2)
- [Abstract] Abstract: the central claim that the framework demonstrates 'flexibility and effectiveness' on benchmarks and classic problems where LLMs struggle is unsupported by any quantitative success rates, failure modes, or comparisons to baselines; this data is load-bearing for the assertion of reliable end-to-end operation without human intervention.
- [Framework description] Framework description (orchestrator and dynamic-agent sections): dynamic agents operate on error traces without a fixed goal and can therefore converge to a PDDL model whose semantics differ from the original human specification (e.g., altered predicate meanings or unstated constraints) while still passing VAL/uVAL and producing a valid plan; no concrete safeguards, semantic-equivalence checks, or ablation experiments are described to bound this risk.
minor comments (2)
- [Abstract] Abstract: the model list 'GPT-{4o, 5-mini, 5.4}' and 'Gemini-{2.5, 3}-flash' should use precise version strings (e.g., gpt-4o-2024-08-06) for reproducibility.
- [Evaluation] Evaluation section: integration claims with Fast Downward, LPG, POPF, VAL, and uVAL would benefit from a brief table listing which validator/planner combination was used per domain.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for quantitative support and safeguards against semantic drift. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the framework demonstrates 'flexibility and effectiveness' on benchmarks and classic problems where LLMs struggle is unsupported by any quantitative success rates, failure modes, or comparisons to baselines; this data is load-bearing for the assertion of reliable end-to-end operation without human intervention.
Authors: We agree that the abstract's claims require quantitative backing. The full manuscript reports results across the listed domains and planners, but explicit aggregate success rates, per-domain breakdowns, failure-mode categorization, and baseline comparisons (e.g., direct LLM prompting) are not presented in sufficient detail. We will add a dedicated evaluation subsection with these metrics and comparisons in the revised version. revision: yes
-
Referee: [Framework description] Framework description (orchestrator and dynamic-agent sections): dynamic agents operate on error traces without a fixed goal and can therefore converge to a PDDL model whose semantics differ from the original human specification (e.g., altered predicate meanings or unstated constraints) while still passing VAL/uVAL and producing a valid plan; no concrete safeguards, semantic-equivalence checks, or ablation experiments are described to bound this risk.
Authors: We acknowledge the risk of semantic drift when dynamic agents lack a fixed goal. The current design uses VAL/uVAL for syntactic and plan-validity checks and pairs dynamic agents with hardcoded agents that enforce temporal and log-based constraints, but no explicit semantic-equivalence verification to the original natural-language specification or ablation studies isolating the dynamic component are described. In revision we will add a limitations paragraph discussing this risk, outline any implicit safeguards, and include ablation results comparing configurations with and without dynamic agents. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper describes an LLM-orchestrated framework for converting natural-language specifications into validated PDDL models using hardcoded and dynamic agents, followed by external planning and plan translation. No equations, derivations, fitted parameters, or self-referential logic appear in the architecture or evaluation. The central claims rest on system design choices and empirical results across benchmarks rather than any reduction of outputs to inputs by construction. Self-citations, if present, are not load-bearing for any uniqueness theorem or ansatz. The contribution is therefore self-contained as an engineering description with no circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
orchestrator ... dynamically creates multi-agent workflows ... hardcoded ... dynamic ... refine ... PDDL domain and problem ... validated ... external planning engine
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
iteratively refined by sub-modules (agents) ... FastDownwardsAdapter, SyntaxPDDL, TemporalConsistency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Ahn, M.; Brohan, A.; Brown, N.; Chebotar, Y.; Cortes, O.; David, B.; Finn, C.; Fu, C.; Gopalakrishnan, K.; Hausman, K.; et al. 2022. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Blum, A. L.; and Furst, M. L. 1997. Fast planning through planning graph analysis. Artificial intelligence, 90(1-2): 281--300
work page 1997
-
[5]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Chan, J. S.; Chowdhury, N.; Jaffe, O.; Aung, J.; Sherburn, D.; Mays, E.; Starace, G.; Liu, K.; Maksin, L.; Patwardhan, T.; et al. 2024. Mle-bench: Evaluating machine learning agents on machine learning engineering. arXiv preprint arXiv:2410.07095
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Chase, H. 2022. LangChain
work page 2022
-
[7]
Chevalier-Boisvert, M.; Bahdanau, D.; Lahlou, S.; Willems, L.; Saharia, C.; Nguyen, T. H.; and Bengio, Y. 2019. Baby AI : First Steps Towards Grounded Language Learning With a Human In the Loop. In International Conference on Learning Representations
work page 2019
-
[8]
E.; Lee, N.; Kim, S.; Moon, S.; Furuta, H.; Anumanchipalli, G.; Keutzer, K.; and Gholami, A
Erdogan, L. E.; Lee, N.; Kim, S.; Moon, S.; Furuta, H.; Anumanchipalli, G.; Keutzer, K.; and Gholami, A. 2025. Plan-and-act: Improving planning of agents for long-horizon tasks. arXiv preprint arXiv:2503.09572
-
[9]
Farquhar, S.; Kossen, J.; Kuhn, L.; and Gal, Y. 2024. Detecting hallucinations in large language models using semantic entropy. Nature, 630(8017): 625--630
work page 2024
-
[10]
Fikes, R. E.; and Nilsson, N. J. 1971. STRIPS: A new approach to the application of theorem proving to problem solving. Artificial intelligence, 2(3-4): 189--208
work page 1971
-
[11]
A.; De Freitas, N.; and Whiteson, S
Foerster, J.; Assael, I. A.; De Freitas, N.; and Whiteson, S. 2016. Learning to communicate with deep multi-agent reinforcement learning. Advances in neural information processing systems, 29
work page 2016
-
[12]
Ghallab, M.; Howe, A.; Knoblock, C.; McDermott, D.; Ram, A.; Veloso, M.; Weld, D.; and Wilkins. 1998. Pddl—the planning domain definition language. Technical Report, Tech. Rep
work page 1998
-
[13]
Grosz, B. J. 1996. Collaborative systems (AAAI-94 presidential address). AI magazine, 17(2): 67--67
work page 1996
-
[14]
Gu, J.; Jiang, X.; Shi, Z.; Tan, H.; Zhai, X.; Xu, C.; Li, W.; Shen, Y.; Ma, S.; Liu, H.; Wang, S.; Zhang, K.; Wang, Y.; Gao, W.; Ni, L.; and Guo, J. 2025. A Survey on LLM-as-a-Judge. arXiv:2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [15]
-
[16]
Hazra, R.; Dos Martires, P. Z.; and De Raedt, L. 2024. Saycanpay: Heuristic planning with large language models using learnable domain knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, 20123--20133
work page 2024
-
[17]
Helmert, M. 2006. The fast downward planning system. Journal of Artificial Intelligence Research, 26: 191--246
work page 2006
-
[18]
Hoffmann, J. 2001. FF: The fast-forward planning system. AI magazine, 22(3): 57--57
work page 2001
- [19]
-
[20]
Leibo, J. Z.; Due \ n ez-Guzman, E. A.; Vezhnevets, A.; Agapiou, J. P.; Sunehag, P.; Koster, R.; Matyas, J.; Beattie, C.; Mordatch, I.; and Graepel, T. 2021. Scalable evaluation of multi-agent reinforcement learning with melting pot. In International conference on machine learning, 6187--6199. PMLR
work page 2021
-
[21]
Liu, B.; Jiang, Y.; Zhang, X.; Liu, Q.; Zhang, S.; Biswas, J.; and Stone, P. 2023. Llm+ p: Empowering large language models with optimal planning proficiency. arXiv preprint arXiv:2304.11477
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; and Mordatch, I
Lowe, R.; Wu, Y. I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; and Mordatch, I. 2017. Multi-agent actor-critic for mixed cooperative-competitive environments. Advances in neural information processing systems, 30
work page 2017
- [23]
-
[24]
L.; Petrov, A.; Frieder, S.; Weinhuber, C.; Burnell, R.; Nazar, R.; Cohn, A
Malfa, E. L.; Petrov, A.; Frieder, S.; Weinhuber, C.; Burnell, R.; Nazar, R.; Cohn, A. G.; Shadbolt, N.; and Wooldridge, M. 2023. Language Models as a Service: Overview of a New Paradigm and its Challenges. arXiv:2309.16573
-
[25]
McDermott, D.; Ghallab, M.; Howe, A.; Knoblock, C.; Ram, A.; Veloso, M.; Weld, D.; and Wilkins, D. 1998. PDDL --- T he Planning Domain Definition Language. Technical Report CVC TR-98-003 / DCS TR-1165, Yale Center for Computational Vision and Control, New Haven, CT. Technical report
work page 1998
-
[26]
Oliehoek, F. A.; Amato, C.; et al. 2016. A concise introduction to decentralized POMDPs, volume 1. Springer
work page 2016
-
[27]
Oswald, J.; Srinivas, K.; Kokel, H.; Lee, J.; Katz, M.; and Sohrabi, S. 2024. Large language models as planning domain generators. In Proceedings of the International Conference on Automated Planning and Scheduling, volume 34, 423--431
work page 2024
-
[28]
Shojaee, P.; Mirzadeh, I.; Alizadeh, K.; Horton, M.; Bengio, S.; and Farajtabar, M. 2025. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity. arXiv preprint arXiv:2506.06941
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
B.; Cardenas, E.; Sharma, A.; Trengrove, J.; and van Luijt, B
Shorten, C.; Pierse, C.; Smith, T. B.; Cardenas, E.; Sharma, A.; Trengrove, J.; and van Luijt, B. 2024. Structuredrag: Json response formatting with large language models. arXiv preprint arXiv:2408.11061
-
[30]
Shridhar, M.; Thomason, J.; Gordon, D.; Bisk, Y.; Han, W.; Mottaghi, R.; Zettlemoyer, L.; and Fox, D. 2020 a . Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10740--10749
work page 2020
-
[31]
Shridhar, M.; Yuan, X.; C \^o t \'e , M.-A.; Bisk, Y.; Trischler, A.; and Hausknecht, M. 2020 b . Alfworld: Aligning text and embodied environments for interactive learning. arXiv preprint arXiv:2010.03768
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[32]
B.; Kaelbling, L.; and Katz, M
Silver, T.; Dan, S.; Srinivas, K.; Tenenbaum, J. B.; Kaelbling, L.; and Katz, M. 2024. Generalized planning in pddl domains with pretrained large language models. In Proceedings of the AAAI conference on artificial intelligence, volume 38, 20256--20264
work page 2024
-
[33]
Sukhbaatar, S.; Fergus, R.; et al. 2016. Learning multiagent communication with backpropagation. Advances in neural information processing systems, 29
work page 2016
-
[34]
Tambe, M. 1997. Towards flexible teamwork. Journal of artificial intelligence research, 7: 83--124
work page 1997
-
[35]
Toledo, E.; Hambardzumyan, K.; Josifoski, M.; Hazra, R.; Baldwin, N.; Audran-Reiss, A.; Kuchnik, M.; Magka, D.; Jiang, M.; Lupidi, A. M.; et al. 2025. AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench. arXiv preprint arXiv:2507.02554
- [36]
-
[37]
Valmeekam, K.; Marquez, M.; Olmo, A.; Sreedharan, S.; and Kambhampati, S. 2023. Planbench: An extensible benchmark for evaluating large language models on planning and reasoning about change. Advances in Neural Information Processing Systems, 36: 38975--38987
work page 2023
-
[38]
Valmeekam, K.; Olmo, A.; Sreedharan, S.; and Kambhampati, S. 2022. Large Language Models Still Can't Plan (A Benchmark for LLM s on Planning and Reasoning about Change). In NeurIPS 2022 Foundation Models for Decision Making Workshop
work page 2022
- [39]
-
[40]
Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K. R.; and Cao, Y. 2022. React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representations
work page 2022
-
[41]
S.; Mishra, S.; Zhang, H.; Chen, X.; Chen, M.; Nova, A.; Hou, L.; Cheng, H.-T.; Le, Q
Zheng, H. S.; Mishra, S.; Zhang, H.; Chen, X.; Chen, M.; Nova, A.; Hou, L.; Cheng, H.-T.; Le, Q. V.; Chi, E. H.; et al. 2024. Natural plan: Benchmarking llms on natural language planning. arXiv preprint arXiv:2406.04520
-
[42]
Zuo, M.; Velez, F. P.; Li, X.; Littman, M. L.; and Bach, S. H. 2024. Planetarium: A rigorous benchmark for translating text to structured planning languages. arXiv preprint arXiv:2407.03321
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.