Setting the Stage: Text-Driven Scene-Consistent Image Generation
Pith reviewed 2026-05-21 17:33 UTC · model grok-4.3
The pith
A data pipeline from real photos and video models plus a cross-view attention loss lets models add actors to a reference scene per text instructions while keeping the scene identical.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
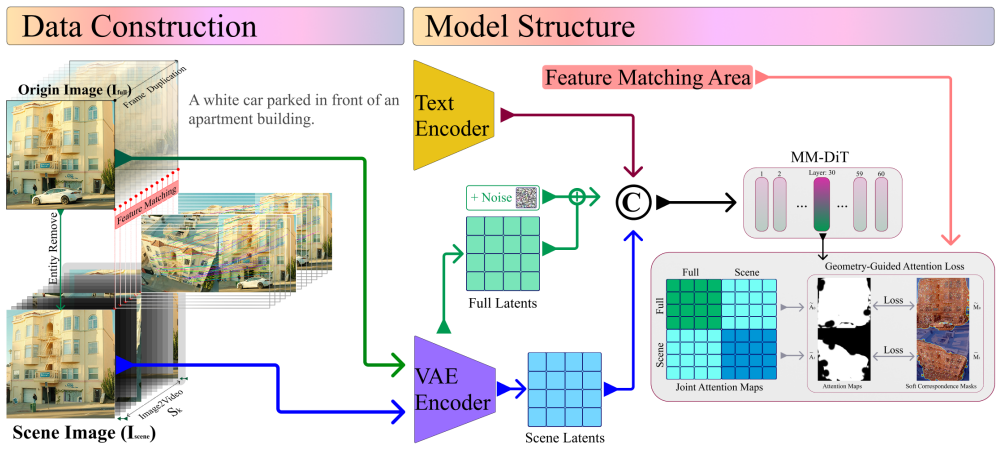
The central claim is that a training set built by entity removal on real photographs followed by image-to-video synthesis, together with a correspondence-guided attention loss that exploits cross-view cues, produces a generator whose outputs preserve reference scene identity, respect the spatial relation stated in text, and outperform prior methods on both automatic alignment metrics and human preference judgments.
What carries the argument
The correspondence-guided attention loss that uses cross-view correspondences from the synthesized pairs to enforce spatial alignment between the generated actor and the reference scene.
If this is right
- The generated images achieve higher scene alignment and text-image alignment than current state-of-the-art baselines.
- Performance gains appear in both automatic metrics and human preference studies.
- Outputs maintain diverse viewpoints and compositions while still obeying the textual spatial instructions.
- Reference scene identity is preserved even when the added actor occupies new positions or scales.
Where Pith is reading between the lines
- The same synthetic-pair construction could supply training data for other consistency-heavy tasks such as object removal or lighting transfer within a fixed scene.
- Cross-view attention losses may generalize to multi-frame video generation where background identity must stay constant across shots.
- Design tools for architecture or film pre-visualization could adopt the pipeline to reduce reliance on large manually annotated scene datasets.
Load-bearing premise
The data pipeline of entity removal plus image-to-video diffusion creates training pairs whose entity-scene relationships are correct and free of artifacts that would bias the model toward generated rather than real distributions.
What would settle it
Train two identical models, one with the authors' synthetic pairs and attention loss and one without, then measure whether the version without them scores lower on scene-identity metrics or loses to the full method in a forced-choice human study on the scene-consistent benchmark.
Figures







read the original abstract
We focus on the foundational task of Scene Staging: given a reference scene image and a text condition specifying an actor category to be generated in the scene and its spatial relation to the scene, the goal is to synthesize an output image that preserves the same scene identity as the reference image while correctly generating the actor according to the spatial relation described in the text. Existing methods struggle with this task, largely due to the scarcity of high-quality paired data and unconstrained generation objectives. To overcome the data bottleneck, we propose a novel data construction pipeline that combines real-world photographs, entity removal, and image-to-video diffusion models to generate training pairs with diverse scenes, viewpoints and correct entity-scene relationships. Furthermore, we introduce a novel correspondence-guided attention loss that leverages cross-view cues to enforce spatial alignment with the reference scene. Experiments on our scene-consistent benchmark show that our approach achieves better scene alignment and text-image alignment than state-of-the-art baselines, according to both automatic metrics and human preference studies. Our method generates images with diverse viewpoints and compositions while faithfully following the textual instructions and preserving the reference scene identity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses the task of Scene Staging: given a reference scene image and text specifying an actor category and its spatial relation to the scene, synthesize an output image that preserves scene identity while correctly placing the actor per the text. To address data scarcity, it introduces a pipeline combining real-world photographs, entity removal, and image-to-video diffusion models to create training pairs with diverse viewpoints and correct entity-scene relationships. It further proposes a correspondence-guided attention loss that uses cross-view cues for spatial alignment. Experiments on the authors' custom scene-consistent benchmark report superior scene alignment and text-image alignment compared to baselines, supported by automatic metrics and human preference studies.
Significance. If the data pipeline produces faithful pairs without systematic artifacts and the internal benchmark is shown to be independent, the approach could meaningfully advance controllable text-to-image generation in complex, multi-entity scenes by providing both a scalable data source and a targeted loss for consistency.
major comments (2)
- [Section 3.2] Section 3.2 (Data Construction Pipeline): The pipeline description does not include quantitative validation of pair fidelity, such as human verification rates for spatial relations or metrics auditing whether image-to-video diffusion introduces hallucinations in viewpoint or entity placement. This is load-bearing for the central claim, as any systematic errors in the generated training pairs could be reinforced by the correspondence-guided attention loss rather than corrected.
- [Section 4.1] Section 4.1 (Scene-Consistent Benchmark): The benchmark is constructed using a similar internal pipeline to the training data, yet no details are provided on distribution shift controls, statistical significance testing of metric gains, or explicit checks for correlated artifacts between train and test sets. Without these, the reported improvements in automatic metrics and human studies cannot be confidently attributed to genuine generalization.
minor comments (2)
- [Abstract] The abstract and Section 4 would benefit from explicit statements of benchmark size, number of scenes, and exact metric formulations to allow readers to assess the scale and rigor of the evaluation.
- [Section 3.3] Notation for the correspondence-guided attention loss (likely in Section 3.3) could be clarified with a diagram or pseudocode showing how cross-view cues are extracted and applied during training.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our work. We provide detailed responses to each major comment below, and we will incorporate revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (Data Construction Pipeline): The pipeline description does not include quantitative validation of pair fidelity, such as human verification rates for spatial relations or metrics auditing whether image-to-video diffusion introduces hallucinations in viewpoint or entity placement. This is load-bearing for the central claim, as any systematic errors in the generated training pairs could be reinforced by the correspondence-guided attention loss rather than corrected.
Authors: We concur that quantitative validation is essential for substantiating the quality of our data construction pipeline. To address this, we will augment Section 3.2 with results from a human study verifying spatial relations in the generated pairs, reporting agreement rates, as well as quantitative metrics to detect potential hallucinations, such as consistency checks using feature matching between views. These additions will provide stronger evidence for the pipeline's fidelity. revision: yes
-
Referee: [Section 4.1] Section 4.1 (Scene-Consistent Benchmark): The benchmark is constructed using a similar internal pipeline to the training data, yet no details are provided on distribution shift controls, statistical significance testing of metric gains, or explicit checks for correlated artifacts between train and test sets. Without these, the reported improvements in automatic metrics and human studies cannot be confidently attributed to genuine generalization.
Authors: We appreciate the referee highlighting the need for rigorous validation of the benchmark. While the benchmark employs a distinct set of reference scenes and varied generation parameters to promote independence, we agree that more explicit documentation is warranted. In the revised manuscript, we will provide additional details on distribution shift controls, such as scene diversity metrics, and include statistical significance testing (e.g., paired t-tests) for the reported metric gains to better support claims of generalization. revision: yes
Circularity Check
Novel data pipeline and loss evaluated on internal benchmark; no definitional or fitted-input circularity
full rationale
The paper's core contributions are a data construction pipeline (real photographs + entity removal + image-to-video diffusion) and a correspondence-guided attention loss. Performance is reported via experiments on an internally constructed scene-consistent benchmark. No quoted step shows a result reducing by construction to its own inputs, a fitted parameter renamed as prediction, or a load-bearing self-citation chain. The evaluation uses new elements rather than tautological reuse of training distributions or prior author theorems, qualifying as self-contained for circularity purposes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Image-to-video diffusion models can generate diverse viewpoints while preserving scene identity from a single reference image.
- domain assumption Cross-view correspondence cues provide reliable spatial alignment signals for attention guidance.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a scene-consistent data construction pipeline that combines real-world photographs, entity removal, and image-to-video diffusion models... geometry-guided attention loss that leverages cross-view correspondence cues
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Geometry-Guided Attention Loss... Lattn = Lattn0 + Lattn1
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Blended latent diffusion.ACM transactions on graphics (TOG), 42 (4):1–11, 2023
Omri Avrahami, Ohad Fried, and Dani Lischinski. Blended latent diffusion.ACM transactions on graphics (TOG), 42 (4):1–11, 2023. 2
work page 2023
-
[2]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18392–18402, 2023. 3
work page 2023
-
[3]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 6, 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dream- sim: Learning new dimensions of human visual similar- ity using synthetic data.arXiv preprint arXiv:2306.09344,
-
[5]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patash- nik, Amit H Bermano, Gal Chechik, and Daniel Cohen- Or. An image is worth one word: Personalizing text-to- image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022. 6, 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Jia Guo, Jiankang Deng, Alexandros Lattas, and Stefanos Zafeiriou. Sample and computation redistribution for effi- cient face detection.arXiv preprint arXiv:2105.04714, 2021. 3
-
[7]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guob- ing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Li- hang Pan, et al. Glm-4.1 v-thinking: Towards versatile multi- modal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Magicfight: Personalized martial arts combat video generation
Jiancheng Huang, Mingfu Yan, Songyan Chen, Yi Huang, and Shifeng Chen. Magicfight: Personalized martial arts combat video generation. InProceedings of the 32nd ACM International Conference on Multimedia, pages 10833– 10842, 2024. 1
work page 2024
-
[10]
Dual-schedule inver- sion: Training-and tuning-free inversion for real image edit- ing
Jiancheng Huang, Yi Huang, Jianzhuang Liu, Donghao Zhou, Yifan Liu, and Shifeng Chen. Dual-schedule inver- sion: Training-and tuning-free inversion for real image edit- ing. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 660–669. IEEE, 2025. 2, 3
work page 2025
-
[11]
M4v: Multi-modal mamba for text-to-video generation.arXiv preprint arXiv:2506.10915, 2025
Jiancheng Huang, Gengwei Zhang, Zequn Jie, Siyu Jiao, Yinlong Qian, Ling Chen, Yunchao Wei, and Lin Ma. M4v: Multi-modal mamba for text-to-video generation.arXiv preprint arXiv:2506.10915, 2025. 1
-
[12]
Gen- erative photography: a systematic, constructive approach
Gottfried J ¨ager, Herbert W Franke, and Jean Stken. Gen- erative photography: a systematic, constructive approach. Leonardo, 19(1):19–25, 1986. 1, 3
work page 1986
-
[13]
Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion
Xuan Ju, Xian Liu, Xintao Wang, Yuxuan Bian, Ying Shan, and Qiang Xu. Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion. InEuropean Conference on Computer Vision, pages 150–168. Springer,
-
[14]
Christoph Klimmt, Christian Roth, Ivar Vermeulen, Peter V orderer, and Franziska Susanne Roth. Forecasting the expe- rience of future entertainment technology: “interactive sto- rytelling” and media enjoyment.Games and Culture, 7(3): 187–208, 2012. 1
work page 2012
-
[15]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Control-nerf: Editable feature volumes for scene rendering and manipulation
Verica Lazova, Vladimir Guzov, Kyle Olszewski, Sergey Tulyakov, and Gerard Pons-Moll. Control-nerf: Editable feature volumes for scene rendering and manipulation. In Proceedings of the IEEE/CVF Winter Conference on Appli- cations of Computer Vision, pages 4340–4350, 2023. 1, 3
work page 2023
-
[18]
Mat: Mask-aware transformer for large hole im- age inpainting
Wenbo Li, Zhe Lin, Kun Zhou, Lu Qi, Yi Wang, and Ji- aya Jia. Mat: Mask-aware transformer for large hole im- age inpainting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10758– 10768, 2022. 1
work page 2022
-
[19]
Storygan: A sequential conditional gan for story vi- sualization
Yitong Li, Zhe Gan, Yelong Shen, Jingjing Liu, Yu Cheng, Yuexin Wu, Lawrence Carin, David Carlson, and Jianfeng Gao. Storygan: A sequential conditional gan for story vi- sualization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6329–6338,
-
[20]
Photomaker: Customizing re- alistic human photos via stacked id embedding
Zhen Li, Mingdeng Cao, Xintao Wang, Zhongang Qi, Ming- Ming Cheng, and Ying Shan. Photomaker: Customizing re- alistic human photos via stacked id embedding. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8640–8650, 2024. 2
work page 2024
-
[21]
Zongjian Li, Zheyuan Liu, Qihui Zhang, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Yang Ye, Wangbo Yu, Yuwei Niu, and Li Yuan. Uniworld-v2: Reinforce image editing with diffusion negative-aware finetuning and mllm implicit feedback.arXiv preprint arXiv:2510.16888, 2025. 2, 3
work page internal anchor Pith review arXiv 2025
-
[22]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024. 2, 8
work page 2024
-
[23]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuro- pean conference on computer vision, pages 38–55. Springer,
-
[24]
Story-adapter: A training-free iterative framework for long story visualization
Jiawei Mao, Xiaoke Huang, Yunfei Xie, Yuanqi Chang, Mude Hui, Bingjie Xu, and Yuyin Zhou. Story-adapter: A training-free iterative framework for long story visualization. arXiv preprint arXiv:2410.06244, 2024. 1
-
[25]
Synthesizing coherent story with auto-regressive la- tent diffusion models
Xichen Pan, Pengda Qin, Yuhong Li, Hui Xue, and Wenhu Chen. Synthesizing coherent story with auto-regressive la- tent diffusion models. InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision, pages 2920–2930, 2024
work page 2024
-
[26]
Make-a-story: Visual memory conditioned consistent story generation
Tanzila Rahman, Hsin-Ying Lee, Jian Ren, Sergey Tulyakov, Shweta Mahajan, and Leonid Sigal. Make-a-story: Visual memory conditioned consistent story generation. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2493–2502, 2023. 1
work page 2023
-
[27]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Minima: Modality invariant im- age matching
Jiangwei Ren, Xingyu Jiang, Zizhuo Li, Dingkang Liang, Xin Zhou, and Xiang Bai. Minima: Modality invariant im- age matching. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23059–23068, 2025. 4, 6
work page 2025
-
[29]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next- generation multimodal image generation.arXiv preprint arXiv:2509.20427, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Quanjian Song, Mingbao Lin, Wengyi Zhan, Shuicheng Yan, Liujuan Cao, and Rongrong Ji. Univst: A unified framework for training-free localized video style transfer.arXiv preprint arXiv:2410.20084, 2024. 1
-
[31]
Quanjian Song, Donghao Zhou, Jingyu Lin, Fei Shen, Jiaze Wang, Xiaowei Hu, Cunjian Chen, and Pheng-Ann Heng. Scenedecorator: Towards scene-oriented story generation with scene planning and scene consistency.arXiv preprint arXiv:2510.22994, 2025. 3, 6, 7, 2, 4
-
[32]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 1, 3, 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Vistadream: Sampling multiview consistent images for single-view scene reconstruction
Haiping Wang, Yuan Liu, Ziwei Liu, Wenping Wang, Zhen Dong, and Bisheng Yang. Vistadream: Sampling multiview consistent images for single-view scene reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 26772–26782, 2025. 3
work page 2025
-
[34]
InstantID: Zero-shot Identity-Preserving Generation in Seconds
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, Anthony Chen, Huaxia Li, Xu Tang, and Yao Hu. Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Styleadapter: A unified stylized image generation model.arXiv preprint arXiv:2309.01770, 2023
Zhouxia Wang, Xintao Wang, Liangbin Xie, Zhongang Qi, Ying Shan, Wenping Wang, and Ping Luo. Styleadapter: A unified stylized image generation model.arXiv preprint arXiv:2309.01770, 2023. 2
-
[36]
Omniedit: Building image edit- ing generalist models through specialist supervision
Cong Wei, Zheyang Xiong, Weiming Ren, Xeron Du, Ge Zhang, and Wenhu Chen. Omniedit: Building image edit- ing generalist models through specialist supervision. InThe Thirteenth International Conference on Learning Represen- tations, 2024. 4, 5
work page 2024
-
[37]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 3, 4, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Bin Xia, Bohao Peng, Yuechen Zhang, Junjia Huang, Jiyang Liu, Jingyao Li, Haoru Tan, Sitong Wu, Chengyao Wang, Yitong Wang, et al. Dreamomni2: Multimodal instruction-based editing and generation.arXiv preprint arXiv:2510.06679, 2025. 2, 3
-
[39]
Guangxuan Xiao, Tianwei Yin, William T Freeman, Fr ´edo Durand, and Song Han. Fastcomposer: Tuning-free multi- subject image generation with localized attention.Interna- tional Journal of Computer Vision, 133(3):1175–1194, 2025. 2
work page 2025
-
[40]
Smartbrush: Text and shape guided object inpainting with diffusion model
Shaoan Xie, Zhifei Zhang, Zhe Lin, Tobias Hinz, and Kun Zhang. Smartbrush: Text and shape guided object inpainting with diffusion model. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22428–22437, 2023. 1
work page 2023
-
[41]
Paint by example: Exemplar-based image editing with diffusion mod- els
Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion mod- els. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 18381–18391,
-
[42]
Seed-story: Multi- modal long story generation with large language model
Shuai Yang, Yuying Ge, Yang Li, Yukang Chen, Yixiao Ge, Ying Shan, and Ying-Cong Chen. Seed-story: Multi- modal long story generation with large language model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1850–1860, 2025. 1
work page 2025
-
[43]
Stydeco: Unsupervised style transfer with distilling priors and semantic decoupling
Yuanlin Yang, Quanjian Song, Zhexian Gao, Ge Wang, Shanshan Li, and Xiaoyan Zhang. Stydeco: Unsupervised style transfer with distilling priors and semantic decoupling. arXiv preprint arXiv:2508.01215, 2025. 2
-
[44]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 2
work page 2023
-
[47]
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition.IEEE Transactions on Pattern Analy- sis and Machine Intelligence, 2017. 5
work page 2017
-
[48]
Donghao Zhou, Jiancheng Huang, Jinbin Bai, Jiaze Wang, Hao Chen, Guangyong Chen, Xiaowei Hu, and Pheng- Ann Heng. Magictailor: Component-controllable person- alization in text-to-image diffusion models.arXiv preprint arXiv:2410.13370, 2024. 2
-
[49]
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, and Qibin Hou. Storydiffusion: Consistent self- attention for long-range image and video generation.Ad- vances in Neural Information Processing Systems, 37: 110315–110340, 2024. 1 Geometry-Aware Scene-Consistent Image Generation Supplementary Material
work page 2024
-
[50]
Evaluation Metric Selection 6.1. Text-Image Alignment Metric Selection For evaluating text–image alignment, we compare two met- rics:CLIP-T[5] andGemini 2.5 Flash Text–Image Alignment (G2.5F-TIA)[3]. CLIP-T is a CLIP-based met- ric that computes global feature similarity between visual and textual inputs. Leveraging large-scale image–text pairs during tra...
work page 1987
-
[51]
Visual Analysis of DL3DV-10K–based Com- posited Images We visualize some examples of the DL3DV-10K–based data construction baseline in Figure 7, where entities (an old man, a horse statue, and a bicycle) are composited into real scenes. Across these cases, the inserted instances are frequently mis-scaled relative to nearby objects: in the first row, the p...
-
[52]
Additional Qualitative Comparison Results We provide additional qualitative comparisons with Qwen- Image-Edit [37], FLUX.1 Kontext Dev [16], and SceneDec- orator [31] in Fig 8. These examples cover diverse text- guided editing scenarios and further highlight the limita- tions of the compared approaches, including unintended background changes, reduced spa...
-
[53]
Details of Quantitative Evaluation This section provides additional details on the automatic metrics and user study protocol used in Section 4.2. We explicitly describe the Gemini 2.5 Flash prompts used for automatic scoring and the annotation interface shown to hu- man raters. 9.1. Details of Automatic Metrics As described in Section 4.2, we utilize Gemi...
-
[54]
Supplementary Videos To further demonstrate the effectiveness of our geometry- aware framework in maintaining scene consistency across diverse viewpoints, and to illustrate its application in syn- thesizing start and end frames for image-to-video genera- tion, we provide two videos in the accompanying supple- mentary folder. These videos were synthesized ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.