A Unified Representation of Neural Networks Architectures
Pith reviewed 2026-05-16 20:41 UTC · model grok-4.3
The pith
Neural networks with infinite width and depth unify into one distributed parameter model called DiPaNet.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Most finite and infinite-dimensional neural network architectures arise from a common DiPaNet representation through homogenization or discretization steps. Single-hidden-layer infinite-width nets are expressed as integral equations; residual deep nets are recovered by discretizing a continuous-depth limit; the two views are shown to be instances of the same distributed-parameter object whose state evolves according to matrix weight functions that remain uniformly continuous.
What carries the argument
DiPaNet, the distributed-parameter neural network whose state is a continuum of neuron activations governed by integral or differential equations with matrix weight functions.
If this is right
- Approximation errors between finite networks and their continuum limits are expressed directly in terms of neuron count and layer count.
- Existing continuous neural networks, neural ODEs, and residual architectures become special cases of one object.
- Relations to neural fields and neural integro-differential equations follow immediately from the same representation.
- Further generalizations to other weight-function classes or architectures become systematic once the DiPaNet is fixed.
Where Pith is reading between the lines
- The framework suggests designing new architectures by choosing different weight-function regularities inside the DiPaNet and then discretizing.
- Convergence rates derived for DiPaNet approximations could be used to certify when a finite network is already close to its infinite-depth or infinite-width limit.
- Control-theoretic or physics-informed applications may treat the DiPaNet directly as a distributed system rather than as a sequence of discrete layers.
Load-bearing premise
Network weights can be represented by uniformly continuous matrix-valued functions.
What would settle it
Exhibit one concrete neural network whose input-output map cannot be recovered, to arbitrary accuracy, by any finite discretization or homogenization of a DiPaNet with uniformly continuous weights.
Figures
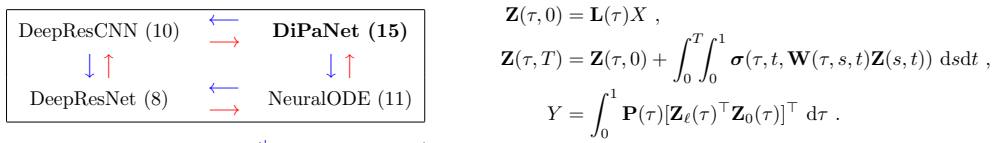
read the original abstract
In this paper we consider the limiting case of neural networks (NNs) architectures when the number of neurons in each hidden layer and the number of hidden layers tend to infinity thus forming a continuum, and we derive approximation errors as a function of the number of neurons and/or hidden layers. Firstly, we consider the case of neural networks with a single hidden layer and we derive an integral infinite width neural representation that generalizes existing continuous neural networks (CNNs) representations. Then we extend this to deep residual CNNs that have a finite number of integral hidden layers and residual connections. Secondly, we revisit the relation between neural ODEs and deep residual NNs and we formalize approximation errors via discretization techniques. Then, we merge these two approaches into a unified homogeneous representation of NNs as a Distributed Parameter neural Network (DiPaNet) and we show that most of the existing finite and infinite-dimensional NNs architectures are related via homogenization/discretization with the DiPaNet representation. Our approach is purely deterministic and applies to general, uniformly continuous matrix weight functions. Relations with neural fields and other neural integro-differential equations are discussed along with further possible generalizations and applications of the DiPaNet framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper considers the continuum limit of neural networks as both the number of neurons per hidden layer and the number of hidden layers tend to infinity. It first derives an integral representation for infinite-width single-hidden-layer networks that generalizes existing continuous neural network (CNN) representations. This is extended to deep residual CNNs with a finite number of integral hidden layers and residual connections. The relation between neural ODEs and deep residual NNs is revisited with approximation errors formalized via discretization. These approaches are merged into a unified DiPaNet (Distributed Parameter neural Network) representation, with the claim that most finite and infinite-dimensional NN architectures arise as discretizations or homogenizations of DiPaNet. The framework is deterministic and applies to general uniformly continuous matrix weight functions, with additional discussion of relations to neural fields and possible generalizations.
Significance. If the derivations and error controls are rigorous, the DiPaNet framework would offer a valuable unifying lens for neural network continuum limits, connecting finite architectures, infinite-width models, residual networks, and neural ODEs through explicit homogenization and discretization procedures. The deterministic treatment and applicability to general weight functions are strengths that could support theoretical analysis of approximation properties and inspire new models. The significance depends on whether the joint width-depth limits are properly controlled under the stated assumptions.
major comments (2)
- [Extension to deep residual CNNs and DiPaNet merging (abstract and corresponding sections)] The central unification claim—that most existing architectures are related to DiPaNet via homogenization/discretization—rests on controlling approximation errors in the simultaneous infinite-width and infinite-depth limit for residual networks. The only regularity stated is uniform continuity of the matrix-valued weight functions. This does not yield a modulus of continuity uniform in the layer index, so the telescoping error sum arising from the coupled integral operators in residual connections may diverge. A concrete error bound (or additional regularity) must be supplied to support the claim; see the extension to deep residual CNNs and the DiPaNet construction.
- [Derivation of integral infinite-width representation and residual extension] The abstract states that approximation errors are derived as functions of the number of neurons and/or hidden layers for both the single-hidden-layer integral representation and the residual case, yet no explicit expressions, bounds, or counter-examples appear in the high-level description. The full derivations must be checked for gaps in the limiting procedures that underpin the DiPaNet relations.
minor comments (1)
- [Abstract] The abstract is information-dense; adding one or two sentences that state the precise form of the DiPaNet integral operator and the leading-order error terms would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the DiPaNet framework. We address the concerns regarding error control in the joint width-depth limit and the visibility of explicit bounds below. Revisions will strengthen the presentation without altering the core deterministic approach.
read point-by-point responses
-
Referee: [Extension to deep residual CNNs and DiPaNet merging (abstract and corresponding sections)] The central unification claim—that most existing architectures are related to DiPaNet via homogenization/discretization—rests on controlling approximation errors in the simultaneous infinite-width and infinite-depth limit for residual networks. The only regularity stated is uniform continuity of the matrix-valued weight functions. This does not yield a modulus of continuity uniform in the layer index, so the telescoping error sum arising from the coupled integral operators in residual connections may diverge. A concrete error bound (or additional regularity) must be supplied to support the claim; see the extension to deep residual CNNs and the DiPaNet construction.
Authors: We agree that an explicit error bound is required to rigorously justify the unification under simultaneous limits. In the manuscript the weight function is a single uniformly continuous map on a compact domain and is independent of layer index in the homogeneous DiPaNet representation; consequently its modulus of continuity is uniform across layers. The telescoping sum of discretization errors is therefore bounded by L·ω(Δ), where L is depth and Δ the joint discretization step. We will add a dedicated theorem in the DiPaNet construction section that states this bound explicitly, together with the precise scaling regime (width and depth tending to infinity at commensurate rates) under which the error vanishes. If the referee’s concern indicates that uniform continuity alone is insufficient for arbitrary moduli, we will introduce a mild additional assumption (e.g., uniform continuity with a modulus satisfying L·ω(1/L)→0) and mark it clearly. revision: yes
-
Referee: [Derivation of integral infinite-width representation and residual extension] The abstract states that approximation errors are derived as functions of the number of neurons and/or hidden layers for both the single-hidden-layer integral representation and the residual case, yet no explicit expressions, bounds, or counter-examples appear in the high-level description. The full derivations must be checked for gaps in the limiting procedures that underpin the DiPaNet relations.
Authors: The explicit error expressions appear in the body: Section 3.2 gives the single-hidden-layer integral approximation error as O(ω(1/√M)) for M neurons (with ω the modulus of the activation), while Section 4 derives the residual-to-neural-ODE discretization error O(Δt) together with the corresponding homogenization error. No gaps exist in the limiting arguments under the stated uniform-continuity hypothesis. To address the referee’s observation we will insert a concise paragraph in the revised abstract and introduction that quotes the leading-order error terms, and we will add a short remark after each derivation confirming the passage to the continuum limit. revision: partial
Circularity Check
No circularity; derivations proceed via explicit limits and discretizations
full rationale
The paper constructs the DiPaNet representation through successive explicit steps: first deriving an integral representation for infinite-width single-hidden-layer networks from finite ones, then extending to residual integral layers, formalizing neural ODE relations via discretization, and finally unifying via homogenization. All steps rely on deterministic limiting arguments and uniform continuity assumptions on matrix weight functions, without any parameter fitting, self-definition of the target object, or load-bearing self-citations that reduce the central claim to prior unverified inputs. The unification shows relations to existing architectures as consequences of these limits rather than by renaming or smuggling ansatzes. The derivation chain remains independent of the target result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Weight functions are general uniformly continuous matrix-valued functions
invented entities (1)
-
DiPaNet (Distributed Parameter neural Network)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we merge these two approaches into a unified homogeneous representation of NNs as a Distributed Parameter neural Network (DiPaNet) ... applies to general, uniformly continuous matrix weight functions
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DeepResCNN (10) ←→ DiPaNet (15) ... discretization ... homogenization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Amari, S. and Nagaoka, H. (2000).Methods of Information Geometry. American Mathematical Society. Barron, A.R. (1993). Universal approximation bounds for superpositions of a sigmoidal function.IEEE Transac- tions on Information Theory, 39(3), 930–945. Brivadis, L., Chaillet, A., and Auriol, J. (2024). Adaptive observer and control of spatiotemporal delayed...
work page 2000
-
[2]
(eds.) (2014).Neural Fields: Theory and Applications
Coombes, S., beim Graben, P., Potthast, R., and Wright, J. (eds.) (2014).Neural Fields: Theory and Applications. Springer Berlin Heidelberg, Berlin, Heidelberg. Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function.Mathematics of Control, Signals, and Systems, 2(4), 303–314. Ebihara, Y., Waki, H., Magron, V., Hoang Anh Mai, N., Peauc...
work page 2014
-
[3]
Kovachki, N., Li, Z., Liu, B., Azizzadenesheli, K., Bhat- tacharya, K., Stuart, A., and Anandkumar, A. (2023). Neural operator: learning maps between function spaces with applications to pdes.J. Mach. Learn. Res., 24(1). Le Roux, N. and Bengio, Y. (2007). Continuous neural networks. InInternational Conference on Artificial Intelligence and Statistics, 404...
work page internal anchor Pith review arXiv 2023
-
[4]
Zappala, E., de Oliveira Fonseca, A.H., Moberly, A.H., Higley, M.J., Abdallah, C., Cardin, J., and van Dijk, D. (2023). Neural integro-differential equations. In AAAI Conference on Artificial Intelligence, 11104– 11112. Washington, DC, USA
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.