Recognition: 2 theorem links
· Lean TheoremCORE: Concept-Oriented Reinforcement for Bridging the Definition-Application Gap in Mathematical Reasoning
Pith reviewed 2026-05-16 20:23 UTC · model grok-4.3
The pith
A new reinforcement learning method uses explicit math concepts to train models that apply definitions in problems rather than reusing solution patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
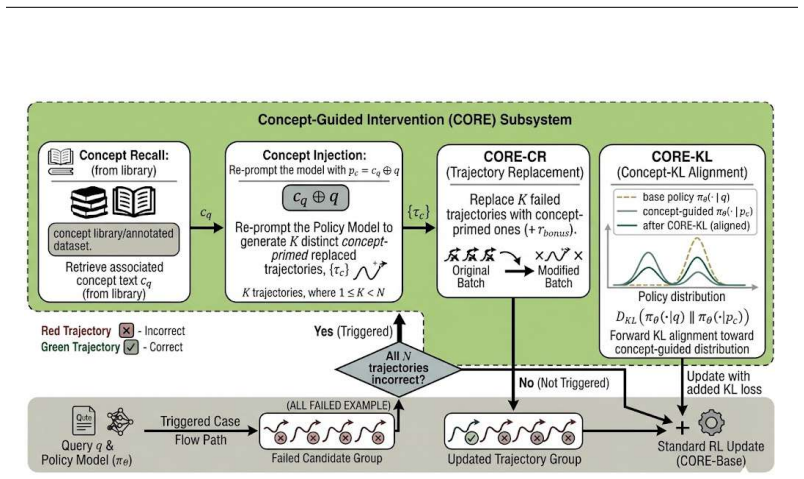
CORE turns explicit concepts into a controllable supervision signal by synthesizing concept-aligned quizzes from a low-contamination textbook, injecting brief concept snippets during rollouts to elicit primed trajectories, and reinforcing conceptual reasoning via trajectory replacement after group failures, a forward-KL constraint aligning unguided with primed policies, or standard GRPO on the quizzes, thereby unifying direct quiz training and concept-injected rollouts under outcome regularization to bridge problem-solving competence and genuine conceptual reasoning.
What carries the argument
Concept-primed trajectory injection paired with trajectory replacement or forward-KL policy alignment, which converts textbook concepts into fine-grained reinforcement signals during training.
If this is right
- Models show consistent gains over vanilla and SFT baselines on in-domain concept-exercise suites.
- Performance improves on diverse out-of-domain math benchmarks across several base models.
- Direct training on concept-aligned quizzes and concept-injected rollouts are unified under outcome regularization.
- The framework remains algorithm- and verifier-agnostic while delivering the reported gains.
Where Pith is reading between the lines
- Similar concept-injection techniques could extend to physics or coding domains where definitions must be applied rather than recalled.
- Automating quiz synthesis from larger unstructured resources might scale the method beyond curated textbooks.
- Removing or weakening the outcome verifier after CORE training could test whether conceptual alignment persists independently.
- Applying the same priming and alignment steps to multi-step or proof-based tasks could reveal limits of concept transfer.
Load-bearing premise
The synthesized concept-aligned quizzes and injected snippets provide a faithful, low-contamination signal of genuine conceptual understanding rather than new surface patterns or biases.
What would settle it
If post-training models continue to fail the same concept-linked quizzes at pre-training rates while still improving final-answer accuracy, the conceptual supervision claim would be falsified.
Figures


read the original abstract
Large language models (LLMs) often solve challenging math exercises yet fail to apply the concept right when the problem requires genuine understanding. Popular Reinforcement Learning with Verifiable Rewards (RLVR) pipelines reinforce final answers but provide little fine-grained conceptual signal, so models improve at pattern reuse rather than conceptual applications. We introduce CORE (Concept-Oriented REinforcement), an RL training framework that turns explicit concepts into a controllable supervision signal. Starting from a high-quality, low-contamination textbook resource that links verifiable exercises to concise concept descriptions, we run a sanity probe showing LLMs can restate definitions but fail concept-linked quizzes, quantifying the conceptual reasoning gap. CORE then (i) synthesizes concept-aligned quizzes, (ii) injects brief concept snippets during rollouts to elicit concept-primed trajectories, and (iii) reinforces conceptual reasoning via trajectory replacement after group failures, a lightweight forward-KL constraint that aligns unguided with concept-primed policies, or standard GRPO directly on concept-aligned quizzes. Across several models, CORE delivers consistent gains over vanilla and SFT baselines on both in-domain concept-exercise suites and diverse out-of-domain math benchmarks. CORE unifies direct training on concept-aligned quizzes and concept-injected rollouts under outcome regularization. It provides fine-grained conceptual supervision that bridges problem-solving competence and genuine conceptual reasoning, while remaining algorithm- and verifier-agnostic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CORE, a reinforcement learning framework for LLMs in mathematical reasoning that extracts concept descriptions from a high-quality textbook resource, synthesizes concept-aligned quizzes, injects brief concept snippets during rollouts to elicit primed trajectories, and reinforces them via trajectory replacement after group failures, a forward-KL alignment constraint, or direct GRPO on quizzes. It claims this bridges the definition-application gap, delivering consistent gains over vanilla RLVR and SFT baselines on in-domain concept-exercise suites and diverse out-of-domain math benchmarks while remaining algorithm- and verifier-agnostic.
Significance. If the gains prove attributable to internalized conceptual application rather than synthesis artifacts, the framework could meaningfully advance RLVR pipelines by supplying controllable, fine-grained conceptual supervision that unifies quiz-based training with concept-injected rollouts under outcome regularization. This would address a recognized limitation in current outcome-only reinforcement for reasoning tasks.
major comments (2)
- [Abstract] Abstract and experimental results description: the central claim of 'consistent gains' across models on in-domain and out-of-domain benchmarks is unsupported by any quantitative numbers, ablation tables, error bars, data-split details, or statistical tests, preventing evaluation of the magnitude, reliability, or robustness of the reported improvements.
- [Method] Method description of quiz synthesis and snippet injection: no ablations isolate the contribution of snippet content versus mere presence of snippets or quiz synthesis artifacts from the same textbook source; this is load-bearing for the claim that the signal is low-contamination and promotes genuine understanding rather than surface patterns, as the sanity probe only shows pre-training failure without addressing post-training exploitation risks.
minor comments (1)
- [Method] The forward-KL alignment and trajectory replacement steps are described at a high level; explicit equations or pseudocode would improve reproducibility and allow readers to verify how they differ from standard GRPO.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and describe the revisions we will implement to improve clarity, support for claims, and experimental rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental results description: the central claim of 'consistent gains' across models on in-domain and out-of-domain benchmarks is unsupported by any quantitative numbers, ablation tables, error bars, data-split details, or statistical tests, preventing evaluation of the magnitude, reliability, or robustness of the reported improvements.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the 'consistent gains' claim. The main experimental sections already contain the requested details: tables reporting average improvements across models, error bars from multiple random seeds, explicit data-split descriptions, and comparisons against baselines. In the revised manuscript we will update the abstract to cite specific numerical gains (e.g., average percentage-point improvements on in-domain concept-exercise suites and out-of-domain benchmarks) while directing readers to the corresponding tables and statistical summaries. This change will make the abstract self-contained without altering the underlying results. revision: yes
-
Referee: [Method] Method description of quiz synthesis and snippet injection: no ablations isolate the contribution of snippet content versus mere presence of snippets or quiz synthesis artifacts from the same textbook source; this is load-bearing for the claim that the signal is low-contamination and promotes genuine understanding rather than surface patterns, as the sanity probe only shows pre-training failure without addressing post-training exploitation risks.
Authors: We acknowledge that the current sanity probe focuses on the pre-training gap and does not fully isolate post-training effects of snippet content versus generic presence or synthesis artifacts. To address this, the revised version will include new ablation experiments that (i) compare concept-specific snippets against length-matched generic or random snippets drawn from the same textbook, (ii) contrast textbook-derived quizzes with unrelated control quizzes, and (iii) analyze trajectory patterns after training to check for surface-pattern exploitation. These ablations will be reported alongside the existing results to demonstrate that performance gains arise from conceptual application rather than low-level artifacts, while preserving the low-contamination property of the source material. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical RL framework extending standard RLVR/GRPO pipelines with synthesized quizzes and snippet injections drawn from an external textbook resource. All claimed gains are reported as experimental outcomes on held-out benchmarks rather than as first-principles derivations or predictions that reduce by construction to the training inputs. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the method description. The sanity probe, synthesis step, and regularization choices are explicitly constructed from the source material and standard algorithms, leaving the central claim independent of any tautological reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reinforcement learning with verifiable rewards can be extended with auxiliary concept signals without destabilizing training.
- ad hoc to paper Concept descriptions extracted from the textbook resource accurately capture the intended mathematical ideas and remain low-contamination.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CORE then (i) synthesizes concept-aligned quizzes, (ii) injects brief concept snippets during rollouts... trajectory replacement after group failures, a lightweight forward-KL constraint...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce CORE... turns explicit concepts into a controllable supervision signal.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
anthropic.com/news/claude-3-7-sonnet
URLhttps://www. anthropic.com/news/claude-3-7-sonnet. Accessed: 2025-09-22. Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Al- bert Q. Jiang, Jia Deng, Stella Biderman, and Sean Welleck. Llemma: An open language model for mathematics,
work page 2025
-
[2]
URLhttps://arxiv.org/abs/2310.10631. Luoxin Chen, Jinming Gu, Liankai Huang, Wenhao Huang, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, Kaijing Ma, Cheng Ren, Jiawei Shen, Wenlei Shi, Tong Sun, He Sun, Jiahui Wang, Siran Wang, Zhihong Wang, Chenrui Wei, Shufa Wei, Yonghui Wu, Yuchen Wu, Yihang Xia, Huajian Xin, Fan Yang, Huaiyuan Ying, ...
-
[3]
Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia
URL https://arxiv.org/abs/2507.23726. Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. TheoremQA: A theorem-driven question answering dataset. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.),Proceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pp. 7889–7901, Singapo...
-
[4]
Training Verifiers to Solve Math Word Problems
Associa- tion for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.489. URLhttps: //aclanthology.org/2023.emnlp-main.489/. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math w...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.emnlp-main.489 2023
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025a. URLhttps://arxiv.org/abs/2501.12948. DeepSeek-AI. Deepseek-v3 technical report, 2025b. URLhttps://arxiv.org/abs/2412. 19437. Yu Feng, Ben Zhou, Weidong Lin, and Dan Roth. Bird: A trustworthy bayesian inference framework for large language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URLhttps://arxiv.org/abs/2404.12494. Team Gemini. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,
-
[7]
URLhttps://arxiv.org/abs/ 2507.06261. 13 Dadi Guo, Jiayu Liu, Zhiyuan Fan, Zhitao He, Haoran Li, Yumeng Wang, and Yi R. Fung. Math- ematical proof as a litmus test: Revealing failure modes of advanced large reasoning models, 2025a. URLhttps://arxiv.org/abs/2506.17114. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Sh...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Measuring Massive Multitask Language Understanding
Association for Computational Linguis- tics. doi: 10.18653/v1/2024.acl-long.211. URLhttps://aclanthology.org/2024. acl-long.211/. Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Ja- cob Steinhardt. Measuring massive multitask language understanding, 2021a. URLhttps: //arxiv.org/abs/2009.03300. Dan Hendrycks, Collin Bur...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.211 2024
-
[9]
URLhttps://openreview.net/forum?id=OZy70UggXr. Yichen Huang and Lin F. Yang. Gemini 2.5 pro capable of winning gold at imo 2025,
work page 2025
-
[10]
Gemini 2.5 pro capable of winning gold at imo 2025.arXiv preprint arXiv:2507.15855, 7, 2025
URL https://arxiv.org/abs/2507.15855. Rik Koncel-Kedziorski, Subhro Roy, Aida Amini, Nate Kushman, and Hannaneh Hajishirzi. MAWPS: A math word problem repository. In Kevin Knight, Ani Nenkova, and Owen Rambow (eds.),Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologie...
-
[11]
Association for Computational Linguistics. doi: 10.18653/v1/N16-1136. URL https://aclanthology.org/N16-1136/. Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ra- masesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning...
-
[12]
Solving Quantitative Reasoning Problems with Language Models
URLhttps://arxiv.org/abs/2206.14858. Yinghui Li, Jiayi Kuang, Haojing Huang, Zhikun Xu, Xinnian Liang, Yi Yu, Wenlian Lu, Yangn- ing Li, Xiaoyu Tan, Chao Qu, Ying Shen, Hai-Tao Zheng, and Philip S. Yu. One exam- ple shown, many concepts known! counterexample-driven conceptual reasoning in mathemat- ical LLMs. InForty-second International Conference on Mac...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct
URL https://arxiv.org/abs/2308.09583. Shen-Yun Miao, Chao-Chun Liang, and Keh-Yih Su. A diverse corpus for evaluating and developing english math word problem solvers,
work page internal anchor Pith review arXiv
-
[14]
arXiv preprint arXiv:2106.15772 , year=
URLhttps://arxiv.org/abs/2106.15772. Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models,
-
[15]
URLhttps://arxiv.org/abs/2410.05229. OpenAI. Openai o1 system card,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URLhttps://arxiv.org/abs/2412.16720. OpenAI. Openai o3 and o4-mini system card. OpenAI,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Are NLP Models really able to Solve Simple Math Word Problems?
URLhttps: //cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/ o3-and-o4-mini-system-card.pdf. Accessed: 2025-09-22. Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve sim- ple math word problems? In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2021.naacl-main.168 2025
-
[18]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
URLhttps://arxiv.org/abs/2505.22756. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms,
-
[19]
Proximal Policy Optimization Algorithms
URLhttps://arxiv.org/abs/1707.06347. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
HybridFlow: A Flexible and Efficient RLHF Framework
URLhttps://arxiv.org/abs/2409.19256. Martin A Simon. Studying mathematics conceptual learning: Student learning through their math- ematical activity.North American Chapter of the International Group for the Psychology of Mathematics Education,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
URLhttps://arxiv.org/abs/2507.10532. 15 An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jin- gren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Da...
-
[23]
URLhttps:// arxiv.org/abs/2506.17211. Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. Agieval: A human-centric benchmark for evaluating foundation models,
-
[24]
Ben Zhou, Sarthak Jain, Yi Zhang, Qiang Ning, Shuai Wang, Yassine Benajiba, and Dan Roth
URLhttps:// arxiv.org/abs/2404.00205. Ben Zhou, Sarthak Jain, Yi Zhang, Qiang Ning, Shuai Wang, Yassine Benajiba, and Dan Roth. Self- supervised analogical learning using language models,
-
[25]
URLhttps://arxiv.org/ abs/2502.00996. A DETAILS FOR TEXTBOOK DATA A.1 DATACURATIONDETAILS Our data curation followed a multi-stage pipeline to ensure high fidelity. We first employed an OCR tool2 to digitize the textbook. The concept and exercise sections then underwent a manual verifi- cation stage, with any recognition errors corrected using GPT-4o. Sub...
-
[26]
Rewards follow a binary scheme (1 for correct, 0 for incorrect)
For each prompt, four responses are generated to conduct GRPO updates. Rewards follow a binary scheme (1 for correct, 0 for incorrect). The maximum prompt length is capped at 1024, while the maximum response length varies across models, being set to 1024 for Qwen2-Math-7B, 2048 for Qwen2.5-Math-1.5B and Llama-3-8B-Instruct, and 6000 for DeepSeek-R1-Distil...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.