M³KG-RAG: Multi-hop Multimodal Knowledge Graph-enhanced Retrieval-Augmented Generation
Pith reviewed 2026-05-16 20:22 UTC · model grok-4.3
The pith
M³KG-RAG builds multi-hop multimodal knowledge graphs and prunes them with GRASP to deliver more accurate audio-visual retrieval for MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
M³KG-RAG retrieves query-aligned audio-visual knowledge from MMKGs by first building multi-hop context-enriched triplets via a lightweight multi-agent pipeline and then applying GRASP to ground entities, evaluate relevance, and prune redundant context, resulting in enhanced multimodal reasoning and answer faithfulness in MLLMs.
What carries the argument
M³KG, the multi-hop multimodal knowledge graph of context-enriched triplets, together with the GRASP module that performs grounded entity matching, relevance scoring, and selective pruning.
If this is right
- MLLMs gain improved depth in multi-hop reasoning across audio and visual modalities.
- Retrieval becomes more precise by filtering off-topic and redundant knowledge.
- Answer faithfulness increases as only essential supporting knowledge is retained for generation.
- Existing MMKGs with limited coverage can be extended through the multi-agent construction method.
Where Pith is reading between the lines
- The same construction-plus-pruning pattern could apply to text-only or video-centric tasks where long reasoning chains matter.
- The approach suggests modality-specific retrieval paths can outperform a single shared embedding space on queries that cross modalities.
- Real-time adaptation might be tested by updating only affected subgraphs instead of rebuilding the full MMKG.
Load-bearing premise
The multi-agent pipeline produces a sufficiently connected and modality-covered MMKG and GRASP correctly identifies and keeps only answer-supporting knowledge without adding errors.
What would settle it
If the constructed MMKG shows low multi-hop connectivity or if GRASP pruning retains off-topic facts, performance on the same benchmarks would show no gain or a drop versus standard similarity-based RAG baselines.
Figures






read the original abstract
Retrieval-Augmented Generation (RAG) has recently been extended to multimodal settings, connecting multimodal large language models (MLLMs) with vast corpora of external knowledge such as multimodal knowledge graphs (MMKGs). Despite their recent success, multimodal RAG in the audio-visual domain remains challenging due to 1) limited modality coverage and multi-hop connectivity of existing MMKGs, and 2) retrieval based solely on similarity in a shared multimodal embedding space, which fails to filter out off-topic or redundant knowledge. To address these limitations, we propose M$^3$KG-RAG, a Multi-hop Multimodal Knowledge Graph-enhanced RAG that retrieves query-aligned audio-visual knowledge from MMKGs, improving reasoning depth and answer faithfulness in MLLMs. Specifically, we devise a lightweight multi-agent pipeline to construct multi-hop MMKG (M$^3$KG), which contains context-enriched triplets of multimodal entities, enabling modality-wise retrieval based on input queries. Furthermore, we introduce GRASP (Grounded Retrieval And Selective Pruning), which ensures precise entity grounding to the query, evaluates answer-supporting relevance, and prunes redundant context to retain only knowledge essential for response generation. Extensive experiments across diverse multimodal benchmarks demonstrate that M$^3$KG-RAG significantly enhances MLLMs' multimodal reasoning and grounding over existing approaches. Project website: https://kuai-lab.github.io/cvpr2026m3kgrag/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce M³KG-RAG, a multimodal RAG framework that constructs a multi-hop multimodal knowledge graph (M³KG) via a lightweight multi-agent pipeline and applies GRASP (Grounded Retrieval And Selective Pruning) for query-aligned entity grounding and relevance-based pruning of redundant knowledge, thereby improving MLLMs' audio-visual reasoning depth and answer faithfulness over standard similarity-based retrieval from existing MMKGs. Extensive experiments on diverse multimodal benchmarks are said to demonstrate significant gains.
Significance. If the core pipeline and pruning mechanism are shown to deliver the claimed coverage and precision, the work would address two persistent bottlenecks in multimodal RAG—limited MMKG connectivity and noisy retrieval—potentially enabling more reliable multi-hop reasoning in MLLMs. The engineering focus on a practical, modality-aware construction and pruning pipeline is a concrete contribution that could be adopted or extended by the community.
major comments (3)
- [Abstract / §3] Abstract and §3 (MMKG construction): The central claim requires that the multi-agent pipeline produces an M³KG with sufficient modality coverage and multi-hop connectivity for the target queries, yet no quantitative metrics (triplet counts per modality, average path length, connectivity statistics, or coverage against gold knowledge) are reported to validate this assumption.
- [Abstract / §4] Abstract and §4 (GRASP): GRASP is presented as performing precise entity grounding and answer-supporting relevance evaluation while pruning redundant context without introducing errors, but the manuscript provides no ablation on the relevance threshold, no precision/recall against human judgments, and no error-injection study to confirm that pruning improves rather than degrades downstream performance.
- [Experiments] Experiments section: The assertion of 'significant gains' over existing approaches is unsupported by reported baseline details, error bars, statistical significance tests, or component ablations (e.g., M³KG vs. GRASP vs. full pipeline), making it impossible to attribute observed improvements to the proposed mechanisms rather than dataset artifacts or base MLLM capabilities.
minor comments (2)
- [Abstract] Notation: The acronym M³KG is used before its expansion is fully clarified in the abstract; a parenthetical definition on first use would improve readability.
- [Abstract] The project website is referenced but no link to released code, constructed graphs, or evaluation scripts is provided in the manuscript, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The points raised highlight important areas for strengthening the validation of M³KG construction, GRASP, and experimental rigor. We will incorporate all suggested additions and clarifications in the revised manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (MMKG construction): The central claim requires that the multi-agent pipeline produces an M³KG with sufficient modality coverage and multi-hop connectivity for the target queries, yet no quantitative metrics (triplet counts per modality, average path length, connectivity statistics, or coverage against gold knowledge) are reported to validate this assumption.
Authors: We agree that quantitative metrics are needed to substantiate the claims about M³KG coverage and connectivity. The original manuscript focused on the pipeline description without reporting these statistics. In the revised version, we will add a dedicated subsection in §3 with triplet counts per modality, average path lengths, connectivity statistics (e.g., average degree and component sizes), and coverage metrics against available gold knowledge sources, including direct comparisons to existing MMKGs. revision: yes
-
Referee: [Abstract / §4] Abstract and §4 (GRASP): GRASP is presented as performing precise entity grounding and answer-supporting relevance evaluation while pruning redundant context without introducing errors, but the manuscript provides no ablation on the relevance threshold, no precision/recall against human judgments, and no error-injection study to confirm that pruning improves rather than degrades downstream performance.
Authors: We acknowledge the value of these additional validations for GRASP. The current manuscript describes the mechanism but lacks the requested ablations and studies. In the revision, we will add to §4 and the experiments: an ablation varying the relevance threshold, precision/recall results against human annotations on sampled queries, and an error-injection analysis showing that selective pruning improves downstream accuracy without introducing new errors. revision: yes
-
Referee: [Experiments] Experiments section: The assertion of 'significant gains' over existing approaches is unsupported by reported baseline details, error bars, statistical significance tests, or component ablations (e.g., M³KG vs. GRASP vs. full pipeline), making it impossible to attribute observed improvements to the proposed mechanisms rather than dataset artifacts or base MLLM capabilities.
Authors: We agree that the experimental reporting requires expansion for proper attribution. The original experiments section presented overall results without the requested details. In the revised manuscript, we will expand the Experiments section to include complete baseline specifications, error bars from multiple runs, statistical significance tests (e.g., paired t-tests with p-values), and component ablations isolating M³KG construction, GRASP, and the full pipeline. revision: yes
Circularity Check
No circularity: independent engineering pipeline with external benchmark validation
full rationale
The paper presents M³KG-RAG as a descriptive pipeline (lightweight multi-agent MMKG construction plus GRASP pruning) without equations, derivations, fitted parameters, or uniqueness theorems. No step reduces by construction to its own inputs, self-citations, or renamed empirical patterns. Central claims rest on reported benchmark gains, which are external to the method definition itself. This matches the default expectation of a non-circular engineering contribution.
Axiom & Free-Parameter Ledger
free parameters (1)
- relevance threshold in GRASP
axioms (1)
- domain assumption Existing multimodal knowledge graphs have limited modality coverage and insufficient multi-hop connectivity.
invented entities (2)
-
M³KG
no independent evidence
-
GRASP
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. InAdvances in Neural Information Processing Systems, 2022. 2
work page 2022
-
[3]
Rohan Anil, Andrew M Dai, Orhan Firat, Melvin John- son, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report.arXiv preprint arXiv:2305.10403, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Xiaohe Bo, Zeyu Zhang, Quanyu Dai, Xueyang Feng, Lei Wang, Rui Li, Xu Chen, and Ji-Rong Wen. Reflective multi- agent collaboration based on large language models.Ad- vances in Neural Information Processing Systems, 37:138595– 138631, 2024. 3
work page 2024
-
[5]
Improving language models by retriev- ing from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retriev- ing from trillions of tokens. InInternational Conference on Machine Learning, pages 2206–2240. PMLR, 2022. 2
work page 2022
-
[6]
Activitynet: A large-scale video bench- mark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video bench- mark for human activity understanding. InProceedings of the ieee conference on computer vision and pattern recognition, pages 961–970, 2015. 5, 2
work page 2015
-
[7]
Vggsound: A large-scale audio-visual dataset
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zis- serman. Vggsound: A large-scale audio-visual dataset. In ICASSP 2020-2020 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), pages 721–725. IEEE, 2020. 3
work page 2020
-
[8]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476, 2024. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, et al. Kimi-audio technical report.arXiv preprint arXiv:2504.18425, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407,
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407,
-
[11]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropoli- tansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused sum- marization.arXiv preprint arXiv:2404.16130, 2024. 1, 2, 6, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
A sur- vey on rag meeting llms: Towards retrieval-augmented large language models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. A sur- vey on rag meeting llms: Towards retrieval-augmented large language models. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, pages 6491–6501, 2024. 2
work page 2024
-
[13]
Precise zero-shot dense retrieval without relevance labels
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. Precise zero-shot dense retrieval without relevance labels. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1762–1777, 2023. 2
work page 2023
-
[14]
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human-labeled dataset for audio events. In2017 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 776–780, 2017. 2
work page 2017
-
[15]
Recap: Retrieval- augmented audio captioning
Sreyan Ghosh, Sonal Kumar, Chandra Kiran Reddy Evuru, Ramani Duraiswami, and Dinesh Manocha. Recap: Retrieval- augmented audio captioning. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1161–1165. IEEE, 2024. 2
work page 2024
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Ab- hinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
LightRAG: Simple and fast retrieval-augmented gen- eration
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. LightRAG: Simple and fast retrieval-augmented gen- eration. InFindings of the Association for Computational Lin- guistics: EMNLP 2025, pages 10746–10761, Suzhou, China,
work page 2025
- [19]
-
[20]
From RAG to memory: Non-parametric continual learning for large language models
Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. From RAG to memory: Non-parametric continual learning for large language models. InForty-second International Conference on Machine Learning, 2025. 2
work page 2025
-
[21]
Realm: retrieval-augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. Realm: retrieval-augmented language model pre-training. InProceedings of the 37th International Conference on Machine Learning, pages 3929–3938, 2020. 2
work page 2020
-
[22]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering.arXiv preprint arXiv:2007.01282, 2020. 2
work page internal anchor Pith review arXiv 2007
-
[24]
VideoRAG: Retrieval-augmented generation over video corpus
Soyeong Jeong, Kangsan Kim, Jinheon Baek, and Sung Ju Hwang. VideoRAG: Retrieval-augmented generation over video corpus. InFindings of the Association for Computa- tional Linguistics: ACL 2025, pages 21278–21298, Vienna, Austria, 2025. Association for Computational Linguistics. 2
work page 2025
-
[25]
Billion-scale similarity search with gpus.IEEE Transactions on Big Data, 7(3):535–547, 2019
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with gpus.IEEE Transactions on Big Data, 7(3):535–547, 2019. 4 9
work page 2019
-
[26]
Audiocaps: Generating captions for audios in the wild
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generating captions for audios in the wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 119–132, 2019. 3, 5, 2
work page 2019
-
[27]
Vista: Visual-textual knowledge graph representation learning
Jaejun Lee, Chanyoung Chung, Hochang Lee, Sungho Jo, and Joyce Whang. Vista: Visual-textual knowledge graph representation learning. InFindings of the association for computational linguistics: EMNLP 2023, pages 7314–7328,
work page 2023
-
[28]
Multi- modal reasoning with multimodal knowledge graph.arXiv preprint arXiv:2406.02030, 2024
Junlin Lee, Yequan Wang, Jing Li, and Min Zhang. Multi- modal reasoning with multimodal knowledge graph.arXiv preprint arXiv:2406.02030, 2024. 1, 3
-
[29]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval- augmented generation for knowledge-intensive nlp tasks.Ad- vances in Neural Information Processing Systems, 33:9459– 9474, 2020. 1, 2
work page 2020
-
[30]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
LLaV A-neXT- interleave: Tackling multi-image, video, and 3d in large mul- timodal models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun MA, and Chunyuan Li. LLaV A-neXT- interleave: Tackling multi-image, video, and 3d in large mul- timodal models. InThe Thirteenth International Conference on Learning Representations, 2025. 2
work page 2025
-
[32]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip- 2: bootstrapping language-image pre-training with frozen image encoders and large language models. InProceedings of the 40th International Conference on Machine Learning, pages 19730–19742, 2023. 2
work page 2023
-
[33]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InProceedings of the 37th International Conference on Neural Information Processing Systems, pages 34892–34916, 2023. 2
work page 2023
-
[34]
Valor: Vision-audio- language omni-perception pretraining model and dataset
Jing Liu, Sihan Chen, Xingjian He, Longteng Guo, Xinxin Zhu, Weining Wang, and Jinhui Tang. Valor: Vision-audio- language omni-perception pretraining model and dataset. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2024. 5, 2, 6
work page 2024
-
[35]
Junming Liu, Siyuan Meng, Yanting Gao, Song Mao, Pinlong Cai, Guohang Yan, Yirong Chen, Zilin Bian, Ding Wang, and Botian Shi. Aligning vision to language: Annotation-free multimodal knowledge graph construction for enhanced llms reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 981–992, 2025. 1
work page 2025
-
[36]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean con- ference on computer vision, pages 38–55. Springer, 2024. 2, 4, 3, 5
work page 2024
-
[37]
Video-chatgpt: Towards detailed video un- derstanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video un- derstanding via large vision and language models. InPro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12585–12602, 2024. 5, 6
work page 2024
-
[38]
Hyeongcheol Park, Jiyoung Seo, MinHyuk Jang, Hogun Park, Ha Dam Baek, Gyusam Chang, Hyeonsoo Im, and Sang- pil Kim. Vat-kg: Knowledge-intensive multimodal knowl- edge graph dataset for retrieval-augmented generation.arXiv preprint arXiv:2506.21556, 2025. 1, 2, 3, 6, 4
-
[39]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 6
work page 2021
-
[40]
Accept the modality gap: An exploration in the hyperbolic space
Sameera Ramasinghe, Violetta Shevchenko, Gil Avraham, and Ajanthan Thalaiyasingam. Accept the modality gap: An exploration in the hyperbolic space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27263–27272, 2024. 1
work page 2024
-
[41]
Xubin Ren, Lingrui Xu, Long Xia, Shuaiqiang Wang, Dawei Yin, and Chao Huang. Videorag: Retrieval-augmented gen- eration with extreme long-context videos.arXiv preprint arXiv:2502.01549, 2025. 1, 6, 4
-
[42]
Chaitanya Sharma. Retrieval-augmented generation: A com- prehensive survey of architectures, enhancements, and ro- bustness frontiers.arXiv preprint arXiv:2506.00054, 2025. 1
-
[43]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. Salmonn: Towards generic hearing abilities for large language models. arXiv preprint arXiv:2310.13289, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[44]
Qwen Team et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2(3), 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc- Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. Multi- agent collaboration mechanisms: A survey of llms.arXiv preprint arXiv:2501.06322, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Audiobench: A universal benchmark for audio large language models
Bin Wang, Xunlong Zou, Geyu Lin, Shuo Sun, Zhuohan Liu, Wenyu Zhang, Zhengyuan Liu, AiTi Aw, and Nancy Chen. Audiobench: A universal benchmark for audio large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pa...
work page 2025
-
[47]
Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu, Zhengyan Zhang, Zhiyuan Liu, Juanzi Li, and Jian Tang. Kepler: A unified model for knowledge embedding and pre-trained lan- guage representation.Transactions of the Association for Computational Linguistics, 9:176–194, 2021. 6, 3
work page 2021
-
[48]
Internvideo2: Scaling foundation models for mul- timodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. Internvideo2: Scaling foundation models for mul- timodal video understanding. InEuropean Conference on Computer Vision, pages 396–416. Springer, 2024. 4, 6, 7
work page 2024
-
[49]
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale con- 10 trastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023. 4, 6, 7
work page 2023
-
[50]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, et al. Qwen2. 5-omni technical report.arXiv preprint arXiv:2503.20215, 2025. 2, 5, 7, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025. 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Towards weakly supervised text-to-audio grounding.IEEE Transac- tions on Multimedia, 2024
Xuenan Xu, Ziyang Ma, Mengyue Wu, and Kai Yu. Towards weakly supervised text-to-audio grounding.IEEE Transac- tions on Multimedia, 2024. 2, 5, 3
work page 2024
-
[53]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 2, 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Woongyeong Yeo, Kangsan Kim, Soyeong Jeong, Jin- heon Baek, and Sung Ju Hwang. Universalrag: Retrieval- augmented generation over corpora of diverse modalities and granularities.arXiv preprint arXiv:2504.20734, 2025. 1, 2, 4
-
[56]
M2conceptbase: A fine-grained aligned concept-centric multimodal knowledge base
Zhiwei Zha, Jiaan Wang, Zhixu Li, Xiangru Zhu, Wei Song, and Yanghua Xiao. M2conceptbase: A fine-grained aligned concept-centric multimodal knowledge base. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 3113–3123, 2024. 1, 2, 3, 6, 4
work page 2024
-
[57]
Extract, define, canonicalize: An llm-based framework for knowledge graph construction
Bowen Zhang and Harold Soh. Extract, define, canonicalize: An llm-based framework for knowledge graph construction. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9820–9836, 2024. 3
work page 2024
-
[58]
A survey of graph retrieval- augmented generation for customized large language models
Qinggang Zhang, Shengyuan Chen, Yuanchen Bei, Zheng Yuan, Huachi Zhou, Zijin Hong, Hao Chen, Yilin Xiao, Chuang Zhou, Junnan Dong, et al. A survey of graph retrieval- augmented generation for customized large language models. arXiv preprint arXiv:2501.13958, 2025. 1
-
[59]
Zikang Zhang, Wangjie You, Tianci Wu, Xinrui Wang, Juntao Li, and Min Zhang. A survey of generative information ex- traction. InProceedings of the 31st International Conference on Computational Linguistics, pages 4840–4870, 2025. 3 11 M3KG-RAG: Multi-hop Multimodal Knowledge Graph-enhanced Retrieval-Augmented Generation Supplementary Material Overview Thi...
work page 2025
-
[60]
Detect whether any triple’s context appears in the input (enti- ties, attributes, actions, time/place cues)
-
[61]
– Do NOT contradict the primary evidence; if conflict exists, ignore the triple
If matched, integrate the FULL triple (head, relation, tail) into the answer, and enrich with head_desc/tail_desc. – Do NOT contradict the primary evidence; if conflict exists, ignore the triple
-
[62]
If no triple is confidently matched, answer from the primary evidence only. Query : {QUERY} Retrieved Triples : {TRIPLES_BLOCK} Triple Format : [i] head={h} | relation={r} | tail={t} || head_description={hd} | tail_description={td} Answer : Table 13. Graph-augmented generation template used to instantiate Eq. (6) in our multimodal RAG framework. over M3KG...
- [63]
-
[64]
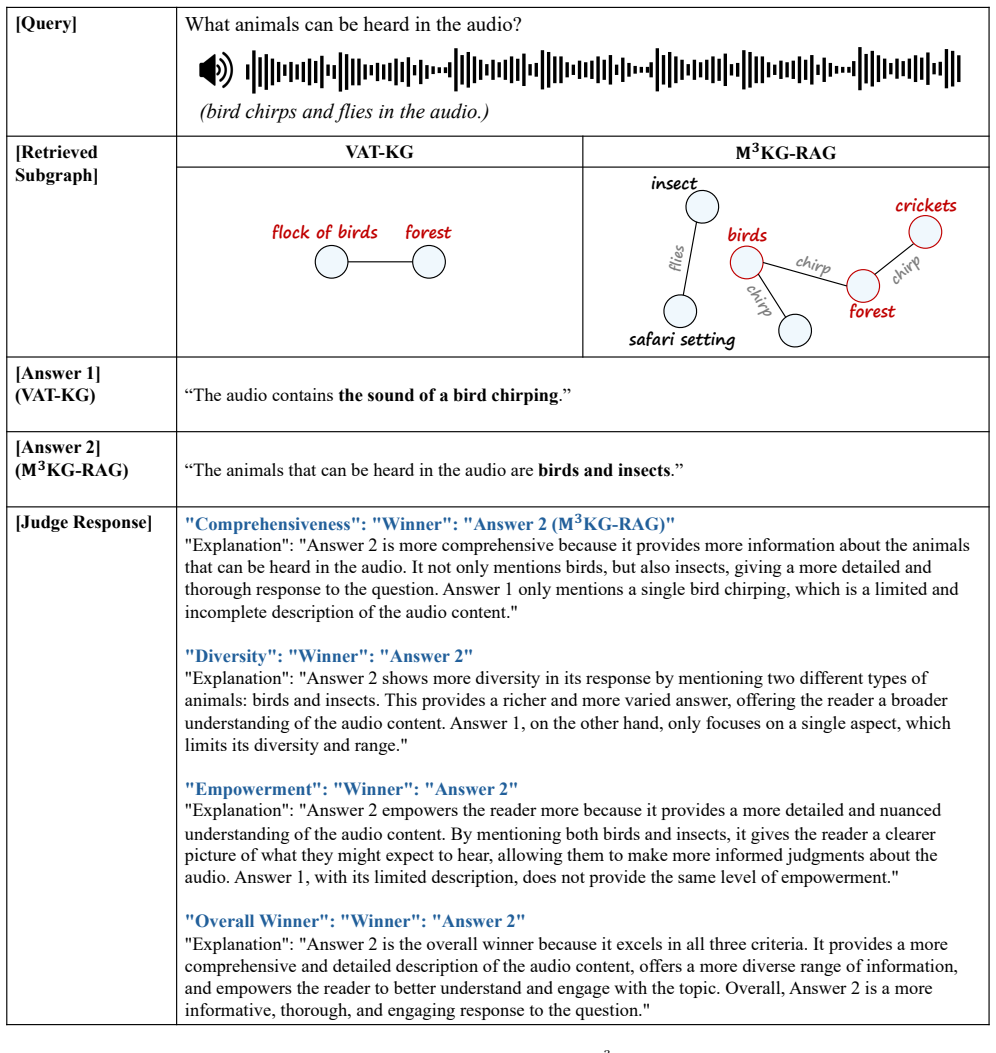
The audio contains the sound of a bird chirping
70. 91. 21. 51. 8Presence Score Threshold 𝜼𝒂𝒗 𝝉=𝟒.𝟓 Model-As-JudgeScoreModel-As-JudgeScore Figure 5.Sensitivity analysis.M.J. score on V ALOR versus modality-wise distance threshold τ (top) and GRASP presence thresholdη av (bottom). d(qm, xm)≤τ . The remaining retrieved items are lifted into the graph via Eq. (3) in the main paper. To understand how the c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.