Hallucination Detection and Evaluation of Large Language Model
Pith reviewed 2026-05-16 19:36 UTC · model grok-4.3
The pith
A lightweight classifier called HHEM detects LLM hallucinations at 82.2 percent accuracy while slashing evaluation time from 8 hours to 10 minutes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
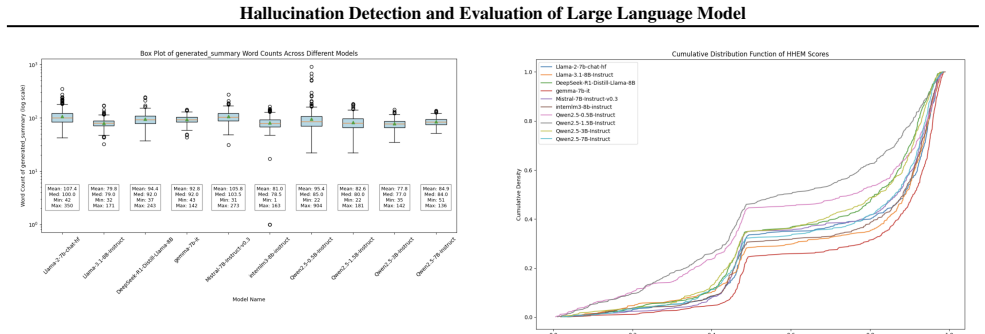
The paper claims that HHEM, a lightweight classification-based framework independent of LLM judgments, provides an efficient alternative for hallucination detection. When combined with non-fabrication checking it attains 82.2 percent accuracy and 78.9 percent TPR on QA and summarization tasks while reducing evaluation time from 8 hours to 10 minutes. Segment-based retrieval is introduced to improve detection of localized hallucinations in summarization. CDF analysis further indicates that models in the 7B-9B parameter range generally exhibit fewer hallucinations than intermediate sizes.
What carries the argument
HHEM, a lightweight classification-based framework that operates independently of LLM-based judgments to classify generated text as hallucinatory or factual, together with segment-based retrieval for verifying smaller text units.
If this is right
- Rapid evaluation becomes feasible for screening outputs from many LLMs without prohibitive compute costs.
- Segment-based retrieval offers a direct method to improve detection accuracy on long-form summarization tasks.
- Larger models (7B-9B parameters) show lower hallucination rates according to the CDF analysis, supporting a preference for scale in factual applications.
- Structured evaluation frameworks can now balance computational efficiency with factual validation for more reliable LLM content.
Where Pith is reading between the lines
- HHEM could be embedded in production pipelines to filter unreliable responses in real time before they reach users.
- The time reduction opens the door to iterative prompt refinement loops that repeatedly test and correct outputs.
- Hybrid systems that combine HHEM with external knowledge-base retrieval might further raise accuracy on specialized domains.
- The observed instability in intermediate model sizes suggests targeted fine-tuning or distillation steps could reduce hallucinations without increasing model size.
Load-bearing premise
A lightweight classifier trained independently of LLMs can accurately identify hallucinations across diverse tasks without inheriting the same factual blind spots or requiring task-specific retraining.
What would settle it
A controlled experiment in which human experts label hallucinations in a fresh collection of LLM outputs from unseen models and tasks, then measure whether HHEM's accuracy falls below 70 percent or its claimed time savings disappear.
Figures




read the original abstract
Hallucinations in Large Language Models (LLMs) pose a significant challenge, generating misleading or unverifiable content that undermines trust and reliability. Existing evaluation methods, such as KnowHalu, employ multi-stage verification but suffer from high computational costs. To address this, we integrate the Hughes Hallucination Evaluation Model (HHEM), a lightweight classification-based framework that operates independently of LLM-based judgments, significantly improving efficiency while maintaining high detection accuracy. We conduct a comparative analysis of hallucination detection methods across various LLMs, evaluating True Positive Rate (TPR), True Negative Rate (TNR), and Accuracy on question-answering (QA) and summarization tasks. Our results show that HHEM reduces evaluation time from 8 hours to 10 minutes, while HHEM with non-fabrication checking achieves the highest accuracy \(82.2\%\) and TPR \(78.9\%\). However, HHEM struggles with localized hallucinations in summarization tasks. To address this, we introduce segment-based retrieval, improving detection by verifying smaller text components. Additionally, our cumulative distribution function (CDF) analysis indicates that larger models (7B-9B parameters) generally exhibit fewer hallucinations, while intermediate-sized models show higher instability. These findings highlight the need for structured evaluation frameworks that balance computational efficiency with robust factual validation, enhancing the reliability of LLM-generated content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Hughes Hallucination Evaluation Model (HHEM), a lightweight classification-based framework for detecting hallucinations in LLMs that operates independently of LLM judgments. It compares HHEM (with and without non-fabrication checking) to existing methods such as KnowHalu on QA and summarization tasks, reporting 82.2% accuracy and 78.9% TPR for the best variant while reducing evaluation time from 8 hours to 10 minutes. The paper also proposes segment-based retrieval to address localized hallucinations in summarization and presents CDF analysis suggesting fewer hallucinations in larger (7B-9B) models.
Significance. If the training protocol and independence claims hold, HHEM could offer a practical, low-cost alternative to multi-stage LLM-based verification methods, with the segment-based retrieval providing a targeted fix for summarization failures. The efficiency gains are potentially impactful for deployment, but the absence of training details and baselines limits assessment of whether the accuracy reflects genuine cross-task generalization.
major comments (2)
- [Abstract] Abstract: The reported 82.2% accuracy and 78.9% TPR for HHEM with non-fabrication checking are presented without any description of the training corpus, annotation source, label generation process, held-out test sets, or statistical significance tests. This omission directly undermines verification of the central claim that the classifier operates independently and generalizes across QA and summarization tasks.
- [Evaluation] Evaluation section (implied by results): No ablation or quantitative comparison is provided for the segment-based retrieval method, leaving the claim that it 'improves detection by verifying smaller text components' unsupported by specific metrics on localized hallucination recall or precision gains over base HHEM.
minor comments (1)
- [Abstract] Abstract: The CDF analysis on model sizes (7B-9B vs. intermediate) is mentioned without specifying the exact models, datasets, or hallucination rate definitions used to generate the distributions.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough review and constructive suggestions. We respond to the major comments below and will update the manuscript to address the identified issues.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 82.2% accuracy and 78.9% TPR for HHEM with non-fabrication checking are presented without any description of the training corpus, annotation source, label generation process, held-out test sets, or statistical significance tests. This omission directly undermines verification of the central claim that the classifier operates independently and generalizes across QA and summarization tasks.
Authors: We agree with the referee that the abstract would be improved by including these details. The full paper provides the training details in the Methods section, including the corpus used (a combination of existing hallucination benchmarks with human annotations), the label generation (binary labels for presence of hallucinations), held-out sets for evaluation, and statistical tests performed. To address this comment, we will revise the abstract to incorporate a short summary of the training protocol and evaluation setup. This will help verify the independence claim, as HHEM is a standalone classifier not relying on LLM outputs for detection. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by results): No ablation or quantitative comparison is provided for the segment-based retrieval method, leaving the claim that it 'improves detection by verifying smaller text components' unsupported by specific metrics on localized hallucination recall or precision gains over base HHEM.
Authors: We acknowledge that the current version lacks a quantitative ablation for the segment-based retrieval approach. The manuscript introduces the method to handle localized hallucinations but does not provide specific comparative metrics. We will add an ablation study in the revised Evaluation section, including quantitative comparisons such as improvements in recall and precision for detecting localized hallucinations in summarization tasks when using segment-based retrieval versus the base HHEM model. This will support the claim with concrete numbers from our experiments. revision: yes
Circularity Check
No significant circularity; performance metrics are standard empirical evaluations
full rationale
The paper presents HHEM as a lightweight classifier operating independently of LLM judgments and reports accuracy (82.2%), TPR (78.9%), and related metrics on QA and summarization tasks via comparative analysis. No equations, derivations, or self-citations are shown that reduce these results to fitted parameters defined by the same data or to self-referential loops. The central claims rely on external task benchmarks rather than any self-definitional, fitted-input, or uniqueness-imported mechanism. This is a standard empirical evaluation with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hallucinations can be detected reliably by a lightweight classification model trained independently of the evaluated LLMs
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HHEM ... lightweight classification-based framework that operates independently of LLM-based judgments ... HHEM with non-fabrication checking achieves the highest accuracy 82.2% and TPR 78.9%
-
IndisputableMonolith/Foundation/Atomicity.leanatomic_tick unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
segment-based retrieval, improving detection by verifying smaller text components
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reduces evaluation time from 8 hours to 10 minutes
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Chain-of-Verification Reduces Hallucination in Large Language Models
URLhttps://arxiv.org/abs/2309.11495. Kirkovska, A. 3 strategies to reduce llm hal- lucinations. https://www.vellum.ai/blog/ how-to-reduce-llm-hallucinations ,
work page internal anchor Pith review arXiv
-
[2]
URL https://doi.org/ 10.1145/3511808.3557325
1145/3511808.3557325. URL https://doi.org/ 10.1145/3511808.3557325. Santhanam, K., Khattab, O., Saad-Falcon, J., Potts, C., and Zaharia, M. ColBERTv2: Effective and efficient retrieval via lightweight late interaction. In Carpuat, M., de Marn- effe, M.-C., and Meza Ruiz, I. V . (eds.),Proceedings of the 2022 Conference of the North American Chapter of the...
-
[3]
URL https://aclanthology.org/2022. naacl-main.272/. Tonmoy, S. M. T. I., Zaman, S. M. M., Jain, V ., Rani, A., Rawte, V ., Chadha, A., and Das, A. A comprehensive survey of hallucination mitigation techniques in large language models,
work page 2022
-
[4]
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
URL https://arxiv.org/ abs/2401.01313. Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y . React: Synergizing reasoning and act- ing in language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
ReAct: Synergizing Reasoning and Acting in Language Models
URL https://arxiv. org/abs/2210.03629. Zapier. AI hallucinations: What they are and how to avoid them. https://zapier.com/blog/ ai-hallucinations/. Zhang, J., Xu, C., Gai, Y ., Lecue, F., Song, D., and Li, B. Knowhalu: Hallucination detection via multi-form knowledge based factual checking,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.