R³L: Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification
Pith reviewed 2026-05-25 07:44 UTC · model grok-4.3
The pith
R³L improves LLM reasoning and agentic performance by synthesizing better trajectories through reflect-then-retry, then refining updates with pivotal credit and positive amplification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
R³L synthesizes high-quality trajectories via reflect-then-retry that leverages language feedback to diagnose errors and restart from identified failure points, applies pivotal credit assignment to update only the diverging suffix where contrastive signals exist, and employs positive amplification to upweight successful trajectories, thereby overcoming low success rates, coarse credit assignment, and instability in standard RL for LLMs and producing 5 to 52 percent relative improvements on agentic and reasoning tasks.
What carries the argument
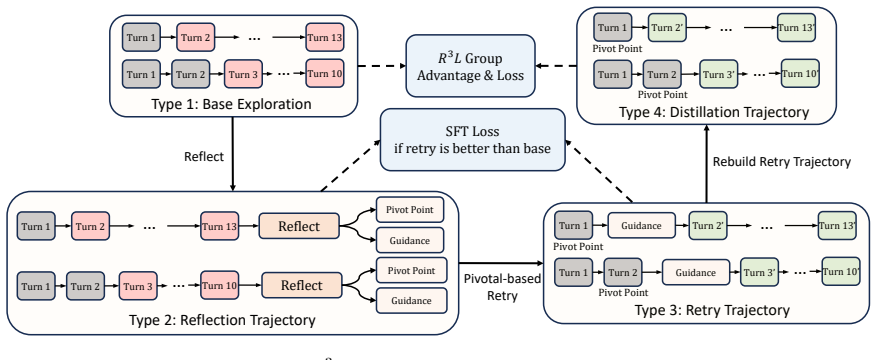
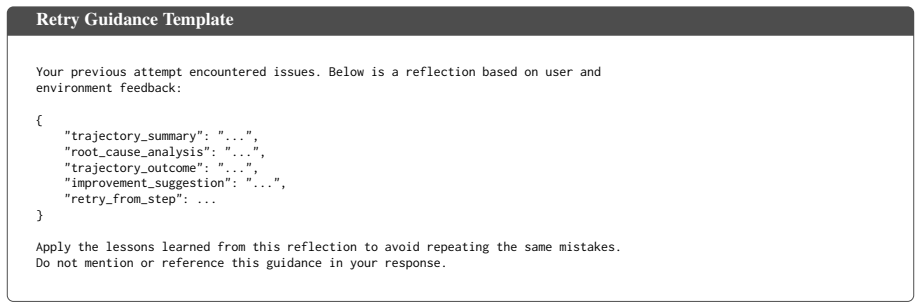
Reflect-then-retry synthesis that uses self-generated language feedback to convert failed trajectories into successful ones by restarting from diagnosed error points, paired with pivotal credit assignment that limits updates to error suffixes and positive amplification that boosts successful examples.
If this is right
- Rollout costs fall because retries begin at localized failure points instead of restarting from scratch each time.
- Credit assignment becomes finer-grained by excluding valid prefixes from gradient updates.
- Training stability holds even though reflect-then-retry generates off-policy data.
- Positive signals dominate optimization on tasks where failures are the majority outcome.
Where Pith is reading between the lines
- The same language-feedback loop could be tested on sequential decision problems outside language models where internal error descriptions are available.
- Relying on the model's own diagnostic language may lower dependence on external reward models or human labels in future RL pipelines.
- The method suggests that restarting at the first divergence point could be combined with other credit-assignment techniques to further reduce variance in long-horizon tasks.
Load-bearing premise
Language feedback generated by the model itself can accurately diagnose its own errors and turn failed trajectories into successful ones without introducing new biases or needing outside supervision.
What would settle it
An experiment in which reflect-then-retry produces no increase in successful trajectories or introduces measurable bias into the training distribution would falsify the central claim.
Figures











read the original abstract
Reinforcement learning drives recent advances in LLM reasoning and agentic capabilities, yet current approaches struggle with both exploration and exploitation. Exploration suffers from low success rates on difficult tasks and high costs of repeated rollouts from scratch. Exploitation suffers from coarse credit assignment and training instability: Trajectory-level rewards penalize valid prefixes for later errors, and failure-dominated groups overwhelm the few positive signals, leaving optimization without constructive direction. To this end, we propose R$^3$L, Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification. To synthesize high-quality trajectories, R$^3$L shifts from stochastic sampling to active synthesis via reflect-then-retry, leveraging language feedback to diagnose errors, transform failed attempts into successful ones, and reduce rollout costs by restarting from identified failure points. With errors diagnosed and localized, Pivotal Credit Assignment updates only the diverging suffix where contrastive signals exist, excluding the shared prefix from gradient update. Since failures dominate on difficult tasks and reflect-then-retry produces off-policy data, risking training instability, Positive Amplification upweights successful trajectories to ensure positive signals guide the optimization process. Experiments on agentic and reasoning tasks demonstrate 5\% to 52\% relative improvements over baselines while maintaining training stability. Our code is released at https://github.com/shiweijiezero/R3L.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes R³L, a reinforcement learning framework for LLM reasoning and agentic tasks. It introduces reflect-then-retry to synthesize trajectories via language-guided error diagnosis and retry from failure points, pivotal credit assignment to update only diverging suffixes, and positive amplification to upweight successful trajectories amid failure-dominated data. The central empirical claim is 5%–52% relative gains over baselines on agentic and reasoning tasks with maintained training stability; code is released.
Significance. If the empirical claims hold under rigorous verification, the method could improve sample efficiency and stability in RL for LLMs by addressing exploration costs and coarse credit assignment. The explicit code release is a strength that enables direct reproducibility checks.
major comments (2)
- [Abstract] Abstract: the reported 5%–52% relative improvements are presented without any description of baselines, number of runs, statistical tests, or ablation results. This absence makes it impossible to determine whether the gains are attributable to the three proposed components or to uncontrolled factors such as prompt engineering or post-hoc trajectory selection.
- [Abstract] Abstract: the reflect-then-retry procedure assumes that the model’s own language feedback can accurately localize errors, propose corrective actions that succeed on retry, and avoid introducing new biases. No analysis, human evaluation, or proxy metric of reflection quality is supplied; if this assumption fails on hard tasks where failures dominate, the synthesized trajectories and subsequent pivotal-credit updates risk amplifying flawed signals rather than providing constructive direction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and the reflect-then-retry mechanism. We address each point below and will make targeted revisions to improve clarity and provide additional supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 5%–52% relative improvements are presented without any description of baselines, number of runs, statistical tests, or ablation results. This absence makes it impossible to determine whether the gains are attributable to the three proposed components or to uncontrolled factors such as prompt engineering or post-hoc trajectory selection.
Authors: The abstract is a concise summary; full details on baselines (standard RL methods for LLMs such as PPO variants), number of runs (multiple random seeds with reported variance), statistical considerations, and component ablations are provided in Sections 4 and 5. Relative gains are computed from these controlled comparisons on identical tasks and prompts. We will revise the abstract to briefly note the evaluation protocol and that ablations isolate the contributions of reflect-then-retry, pivotal credit, and positive amplification. revision: yes
-
Referee: [Abstract] Abstract: the reflect-then-retry procedure assumes that the model’s own language feedback can accurately localize errors, propose corrective actions that succeed on retry, and avoid introducing new biases. No analysis, human evaluation, or proxy metric of reflection quality is supplied; if this assumption fails on hard tasks where failures dominate, the synthesized trajectories and subsequent pivotal-credit updates risk amplifying flawed signals rather than providing constructive direction.
Authors: We agree that direct validation of reflection quality would strengthen the claims. The manuscript shows indirect support via higher overall success rates and stable training when reflect-then-retry is used versus standard sampling. A dedicated analysis (e.g., retry success rates or error-localization proxies) is not currently included. We will add quantitative proxy metrics on reflection effectiveness in the revision to address concerns about potential amplification of flawed signals. revision: yes
Circularity Check
No circularity: algorithmic procedure is self-contained without reductions to fitted inputs or self-citations.
full rationale
The paper presents R³L as a new procedural algorithm consisting of reflect-then-retry synthesis, pivotal credit assignment, and positive amplification. No equations, parameters, or derivations are provided that reduce claimed performance gains to quantities defined by the method's own outputs or fitted values. The description relies on external experimental validation rather than internal self-definition or self-citation chains for its core claims. The method's assumptions about language feedback quality are stated as design choices but do not create a circular derivation where predictions equal inputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
TCOD: Exploring Temporal Curriculum in On-Policy Distillation for Multi-turn Autonomous Agents
TCOD stabilizes on-policy distillation for multi-turn agents via temporal curriculum on trajectory depth, improving performance up to 18 points over vanilla OPD and sometimes surpassing the teacher.
-
STRIDE: Learnable Stepwise Language Feedback for LLM Reasoning
STRIDE co-trains generator and verifier on outcome rewards alone to deliver learnable stepwise language feedback that redirects LLM reasoning trajectories and outperforms scalar-reward baselines.
Reference graph
Works this paper leans on
-
[1]
Group-in-Group Policy Optimization for LLM Agent Training
Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978. Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, and 1 others. 2024. Omni- math: A universal olympiad level mathematic bench- mark for large language models.arXiv preprint arXiv:2410.07985. Daya Guo, D...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Yong Lin, Shange Tang, Bohan Lyu, Ziran Yang, Jui- Hui Chung, Haoyu Zhao, Lai Jiang, Yihan Geng, Jiawei Ge, Jingruo Sun, and 1 others. 2025. Goedel- prover-v2: Scaling formal theorem proving with scaffolded data synthesis and self-correction.arXiv preprint arX...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Training language models with language feed- back.arXiv preprint arXiv:2204.14146. Jérémy Scheurer, Jon Ander Campos, Tomasz Korbak, Jun Shern Chan, Angelica Chen, Kyunghyun Cho, and Ethan Perez. 2023. Training language mod- els with language feedback at scale.arXiv preprint arXiv:2303.16755. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, X...
-
[4]
Math-shepherd: Verify and reinforce llms step- by-step without human annotations. InACL, pages 9426–9439. Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu. 2022. Scienceworld: Is your agent smarter than a 5th grader?arXiv preprint arXiv:2203.07540. Xinyi Wang, Jinyi Han, Zishang Jiang, Tingyun Li, Ji- aqing Liang, Sihang Jiang, Z...
-
[5]
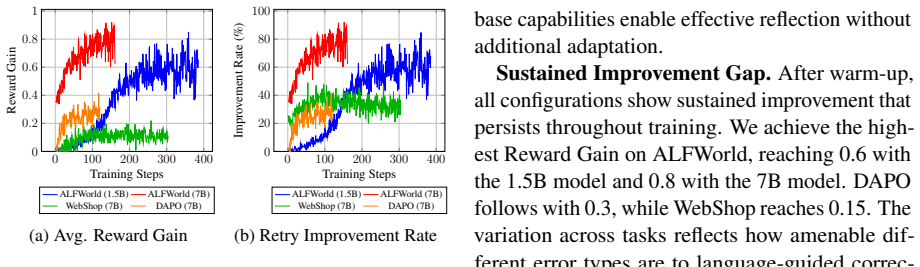
However, it suffers from premature stagna- tion, plateauing at a reward of approximately 0.4 with visible variance. In contrast, R3L undergoes a warm-up phase due to initial adaptation to the reflection mechanism. Following step 120, R 3L demonstrates a rapid phase transition with a signif- icantly steeper learning curve, quickly surpassing the baseline a...
-
[6]
Start/Index page - Initial page with search functionality and task instruction
-
[7]
Search Results page - Lists products returned by search engine with pagination
-
[8]
Item page - Shows product details, options, and purchase button
-
[9]
Item Sub-page - Shows additional product information
-
[10]
Done page - Final confirmation page after purchase ## Available Actions:
-
[11]
search[your_query_here] - To search for products from any page with a search bar
-
[12]
click[exact_button_text_here] - To click on any clickable element ## Task Completion: Goal: Find and purchase an item matching the given instruction within 15 steps Success: Episode ends when you click "Buy Now" with appropriate product and options Figure 10: System prompt used for the WebShop environment. 24 ScienceWorld System Prompt You are an agent, y...
-
[13]
Carefully read and understand the problem
-
[14]
Show your reasoning step by step in the <think> tags
-
[15]
Provide your final answer in the <answer> tags
-
[16]
For numerical answers, provide the exact value
-
[17]
If the problem asks for a specific format, use that format in your answer Figure 12: System prompt used for mathematical reasoning tasks. Unified Reflection Prompt Template You are a Reflector that analyzes trajectory logs based on user and environment feedback. Your goal is to identify what went wrong, trace root causes, and extract reusable principles f...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.