SpeechMedAssist: Efficiently and Effectively Adapting Speech Language Models for Medical Consultation
Pith reviewed 2026-05-16 16:52 UTC · model grok-4.3
The pith
A two-stage training method lets speech language models handle medical consultations with only 10,000 synthesized speech samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
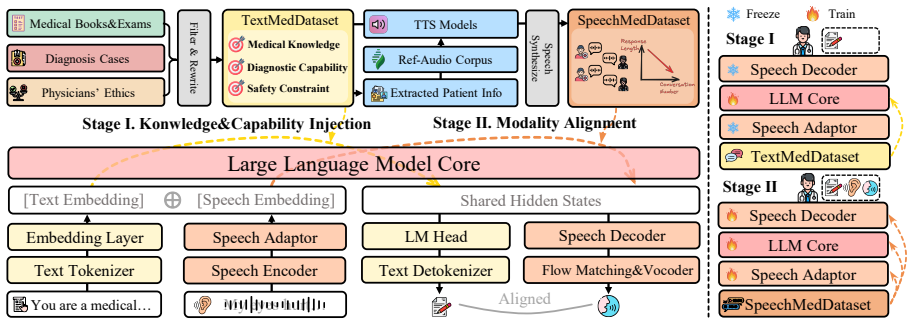
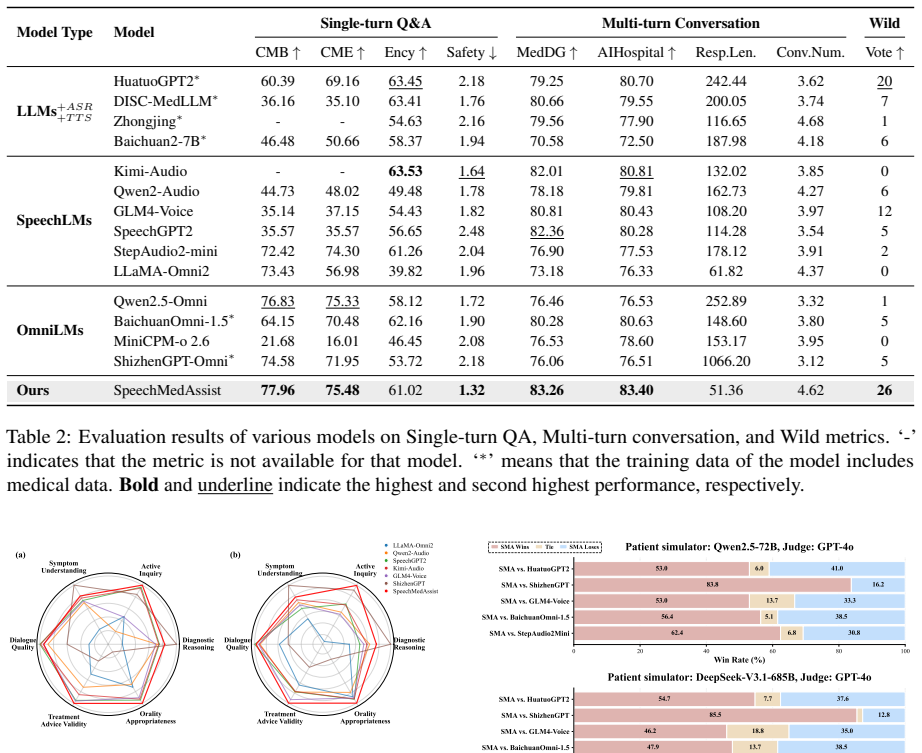
By exploiting the architectural properties of SpeechLMs, the conventional one-stage training can be decoupled into a two-stage paradigm consisting of Knowledge & Capability Injection via Text and Modality Re-alignment with Limited Speech Data. This reduces the requirement for medical speech data to only 10k synthesized samples. The resulting SpeechMedAssist model outperforms all baselines in both effectiveness and robustness in most evaluation settings on a benchmark of single-turn question answering and multi-turn simulated interactions.
What carries the argument
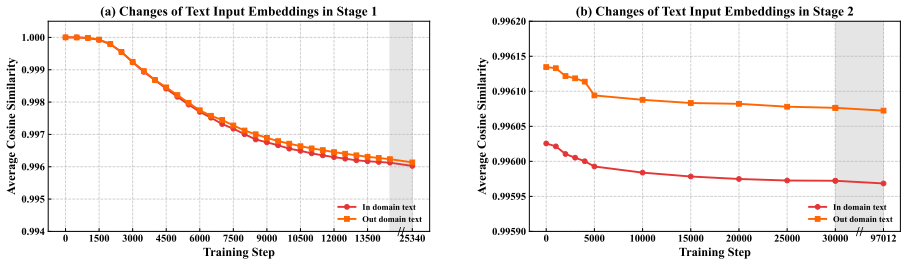
The two-stage paradigm of Knowledge & Capability Injection via Text followed by Modality Re-alignment with Limited Speech Data, which decouples training to minimize the speech data needed while preserving medical capabilities.
If this is right
- The model supports natural speech-based multi-turn medical consultations without large real speech datasets.
- Medical knowledge can be injected via text before any speech alignment occurs.
- Only 10k synthesized samples suffice for the final modality re-alignment step.
- The model outperforms baselines on both single-turn QA and multi-turn dialogue tasks in most tested settings.
- The approach improves robustness alongside effectiveness across the designed evaluation benchmark.
Where Pith is reading between the lines
- The same text-then-speech split could reduce data needs when adapting speech models to other data-scarce domains such as legal or educational dialogue.
- Evaluating the model on large collections of real patient recordings would test whether synthesized samples capture accent, emotion, and medical terminology variation.
- The benchmark of single-turn and multi-turn tasks could be reused or extended to compare other speech adaptation methods.
- Lower speech-data requirements may reduce both training costs and privacy risks when deploying such models in clinical settings.
Load-bearing premise
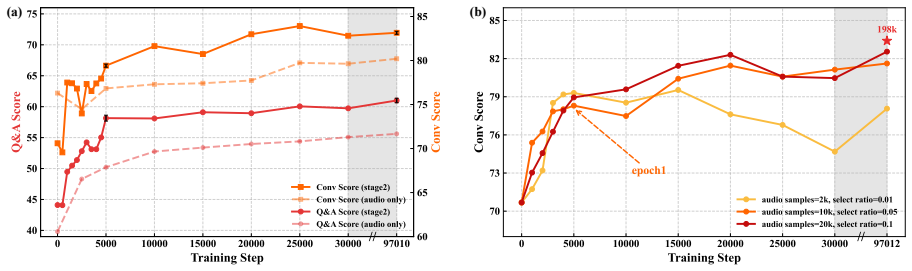
That 10,000 synthesized speech samples are sufficient and representative enough to achieve effective modality re-alignment after text-based knowledge injection without real patient speech data.
What would settle it
A direct comparison in which a model fine-tuned end-to-end on the same 10k synthesized samples matches or exceeds the two-stage model's performance on the multi-turn interaction benchmark, or in which real patient recordings expose large gaps in robustness.
Figures





read the original abstract
Medical consultations are intrinsically speech-centric. However, most prior works focus on long-text-based interactions, which are cumbersome and patient-unfriendly. Recent advances in speech language models (SpeechLMs) have enabled more natural speech-based interaction, yet the scarcity of medical speech data and the inefficiency of directly fine-tuning on speech data jointly hinder the adoption of SpeechLMs in medical consultation. In this paper, we propose SpeechMedAssist, a SpeechLM natively capable of conducting speech-based multi-turn interactions with patients. By exploiting the architectural properties of SpeechLMs, we decouple the conventional one-stage training into a two-stage paradigm consisting of (1) Knowledge & Capability Injection via Text and (2) Modality Re-alignment with Limited Speech Data, thereby reducing the requirement for medical speech data to only 10k synthesized samples. To evaluate SpeechLMs for medical consultation scenarios, we design a benchmark comprising both single-turn question answering and multi-turn simulated interactions. Experimental results show that our model outperforms all baselines in both effectiveness and robustness in most evaluation settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SpeechMedAssist, a SpeechLM for medical consultations that decouples conventional one-stage training into a two-stage paradigm: (1) Knowledge & Capability Injection via Text and (2) Modality Re-alignment using only 10k synthesized speech samples. It introduces a custom benchmark covering single-turn QA and multi-turn simulated interactions, claiming that the model outperforms all baselines in effectiveness and robustness in most settings while addressing data scarcity in medical speech.
Significance. If the central claims hold under rigorous validation, the two-stage approach could meaningfully advance efficient adaptation of SpeechLMs to specialized domains by drastically reducing the volume of required speech data. This has potential implications for developing more natural, speech-centric medical interfaces without extensive real-world data collection.
major comments (3)
- [Abstract] Abstract: The central claim of outperformance over baselines in effectiveness and robustness lacks any reported quantitative metrics (e.g., accuracy, F1, or human evaluation scores), baseline model names, statistical significance tests, or error analysis, leaving the experimental support for the two-stage paradigm unverifiable from the provided description.
- [Methodology] Methodology (two-stage paradigm): The assertion that modality re-alignment succeeds with only 10k synthesized samples requires explicit ablations on synthesis quality, acoustic diversity (accents, disfluencies, prosody), and direct comparison against real patient recordings; without these, the claim that this suffices for robust multi-turn performance rests on an untested assumption about synthetic data representativeness.
- [Evaluation] Evaluation section: The custom benchmark for multi-turn interactions needs detailed specification of simulation construction, context handling, and robustness testing conditions (e.g., noise or accent variations); absent these, it is unclear whether reported gains generalize beyond the self-designed setup.
minor comments (2)
- [Abstract] Clarify the base SpeechLM architecture, the specific TTS system used for the 10k samples, and any hyperparameter choices in the re-alignment stage.
- [Introduction] Add references to prior work on SpeechLM adaptation and medical dialogue systems to better situate the contribution.
Circularity Check
No circularity; derivation is self-contained empirical adaptation
full rationale
The paper's core claim is an empirical two-stage training procedure (text-based knowledge injection followed by modality re-alignment on 10k synthesized samples) that reduces data needs while outperforming baselines on a custom benchmark. No equations, parameter fits, or definitions are shown to loop back on themselves; the performance gains are presented as measured outcomes rather than constructed by renaming inputs or invoking self-citations as uniqueness theorems. The approach relies on standard fine-tuning practices without load-bearing self-referential reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- 10k synthesized samples
axioms (2)
- domain assumption Text data can effectively inject medical knowledge and capabilities into SpeechLMs
- domain assumption Limited synthesized speech data suffices for modality re-alignment
Forward citations
Cited by 1 Pith paper
-
Beyond Isolated Behaviors: Hierarchical User Modeling for LLM Personalization
PHF applies Bourdieu's Theory of Practice to create hierarchical user models for LLM personalization and reports consistent gains on the LaMP benchmark.
Reference graph
Works this paper leans on
-
[1]
High-precision medical speech recognition through synthetic data and semantic correction: UNITED-MEDASR.CoRR, abs/2412.00055. Zhijie Bao, Wei Chen, Shengze Xiao, Kuang Ren, Jiaao Wu, Cheng Zhong, Jiajie Peng, Xuanjing Huang, and Zhongyu Wei. 2023. Disc-medllm: Bridging gen- eral large language models and real-world medical consultation.CoRR, abs/2308.1434...
-
[2]
Wanglab at mediqa-chat 2023: Clinical note generation from doctor-patient conversations using large language models. InProceedings of the 5th Clinical Natural Language Processing Workshop, ClinicalNLP@ACL 2023, Toronto, Canada, July 14, 2023, pages 323–334. Association for Computational Linguistics. Tessa Han, Aounon Kumar, Chirag Agarwal, and Himabindu L...
-
[3]
A tutorial on clinical speech AI development: From data collection to model validation.CoRR, abs/2410.21640. Open-Moss. 2025. Speechgpt 2.0-preview. https://github.com/OpenMOSS/SpeechGPT-2. 0-preview. OpenAI. 2024. Gpt-4o system card.CoRR, abs/2410.21276. Lara Orlandic, Tomas Teijeiro, and David Atienza. 2021. The coughvid crowdsourcing dataset, a corpus ...
-
[4]
Interspeech 2019, pages 1816–1820
A scalable noisy speech dataset and online subjective test framework.Proc. Interspeech 2019, pages 1816–1820. Debra L Roter and Judith A Hall. 1987. Physicians’ interviewing styles and medical information obtained from patients.Journal of General Internal Medicine, 2(5):325–329. Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamich...
work page 2019
-
[5]
arXiv preprint arXiv:2010.11567 , year=
AISHELL-3: A multi-speaker mandarin TTS corpus and the baselines.CoRR, abs/2010.11567. Gagandeep Singh, Yue Pan, Jesús Andrés-Ferrer, Miguel A. del Agua, Frank Diehl, Joel Pinto, and Paul V ozila. 2023. Large scale sequence-to-sequence models for clinical note generation from patient- doctor conversations. InProceedings of the 5th Clin- ical Natural Langu...
-
[6]
arXiv preprint arXiv:2412.01078 , year=
Advancing speech language models by scal- ing supervised fine-tuning with over 60,000 hours of synthetic speech dialogue data.arXiv preprint arXiv:2412.01078. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging llm-...
-
[7]
is inserted into the conversation. The model responses are manually reviewed and categorized to determine whether the model correctly perceives the patient’s cough and produces appropriate anal- ysis or follow-up questions. Based on this anno- tation, we compute the proportion of test cases in which the model successfully identifies the pa- tient’s cough....
-
[8]
The medical content is accurate, consistent with clinical knowledge, and does not contain any incorrect or mislead- ing advice
-
[9]
The patient’s statements are clear, specific, sufficient, and complete. They should not be too brief or fragmented, and must convey a well-defined health problem or con- cern
-
[10]
The doctor’s responses are targeted, relevant to the patient’s problem, and provide reasonable advice or judg- ment
-
[11]
The dialogue structure is complete, with good question- and-answer logic, natural information flow, and no obvious jumps, interruptions, or missing key information
-
[12]
The content is healthy, safe, and compliant. Itmust not contain any illegal, discriminatory, sexual, violent, insult- ing, or otherwise inappropriate expressions
-
[13]
The dialogue content is suitable to be rewritten as a multi-turn conversation, i.e., the patient describes symp- toms and answers the doctor’s questions, while the doctor analyzes the condition and asks follow-up questions
-
[14]
The conversationmust notinclude actions that cannot be performed in a voice dialogue, such as uploading im- ages, viewing pictures, filling out forms, clicking links, sending location, etc. Please strictly base your judgment on the above 7 cri- teria, with a focus on the patient’s statements, and determine whether this conversation is suitable to be retai...
-
[15]
If there is insufficient information, cautiously choose “Unknown”. Gender options: [Male, Female, Unknown]; Age group options: [Adolescent, Young Adult, Adult, Elderly, Un- known]. Please strictly follow the format below: Gender: <Male/Female/Unknown> Age Group: <Adolescent/Young Adult/Adult/Elderly/Unknown> Prompt template for generating the patient’s in...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.