Circuit Mechanisms for Spatial Relation Generation in Diffusion Transformers
Pith reviewed 2026-05-16 15:30 UTC · model grok-4.3
The pith
Diffusion transformers use different internal circuits for spatial relations depending on the text encoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
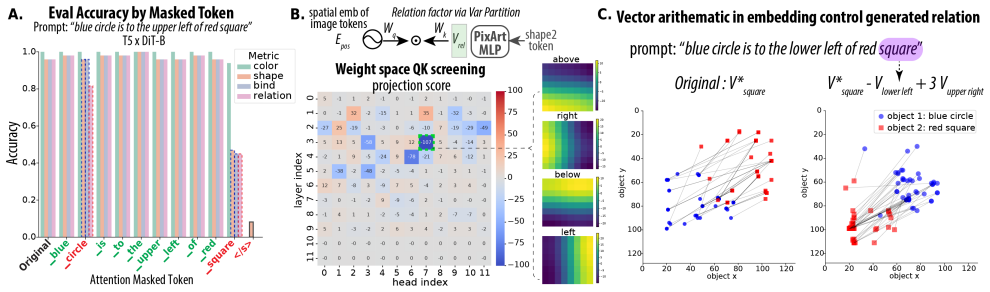
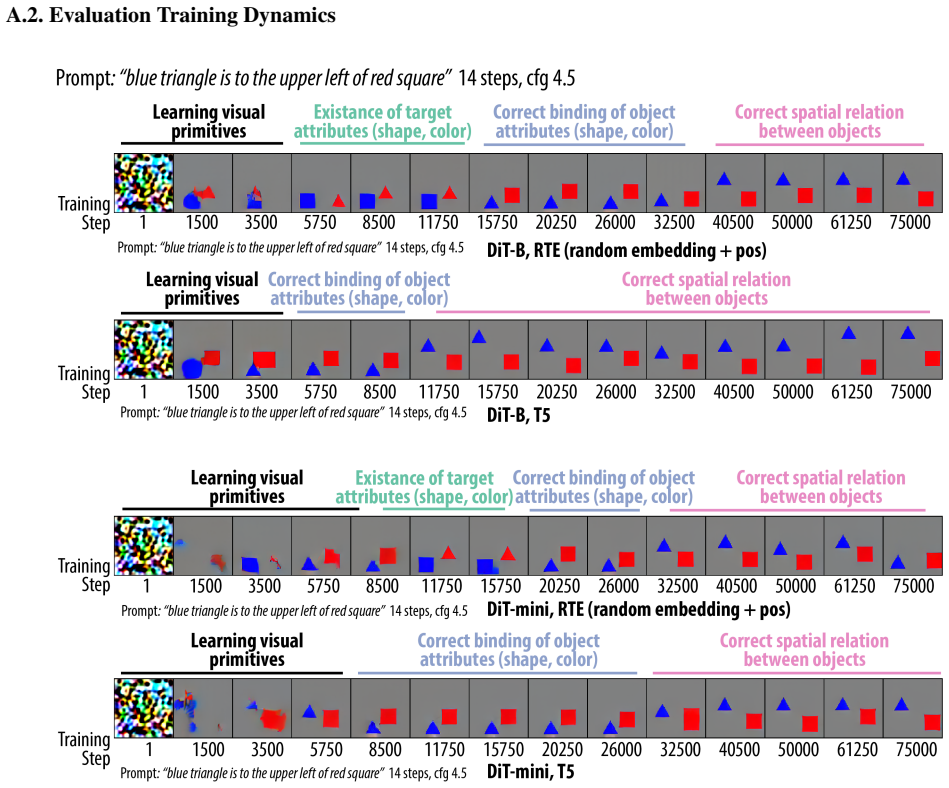
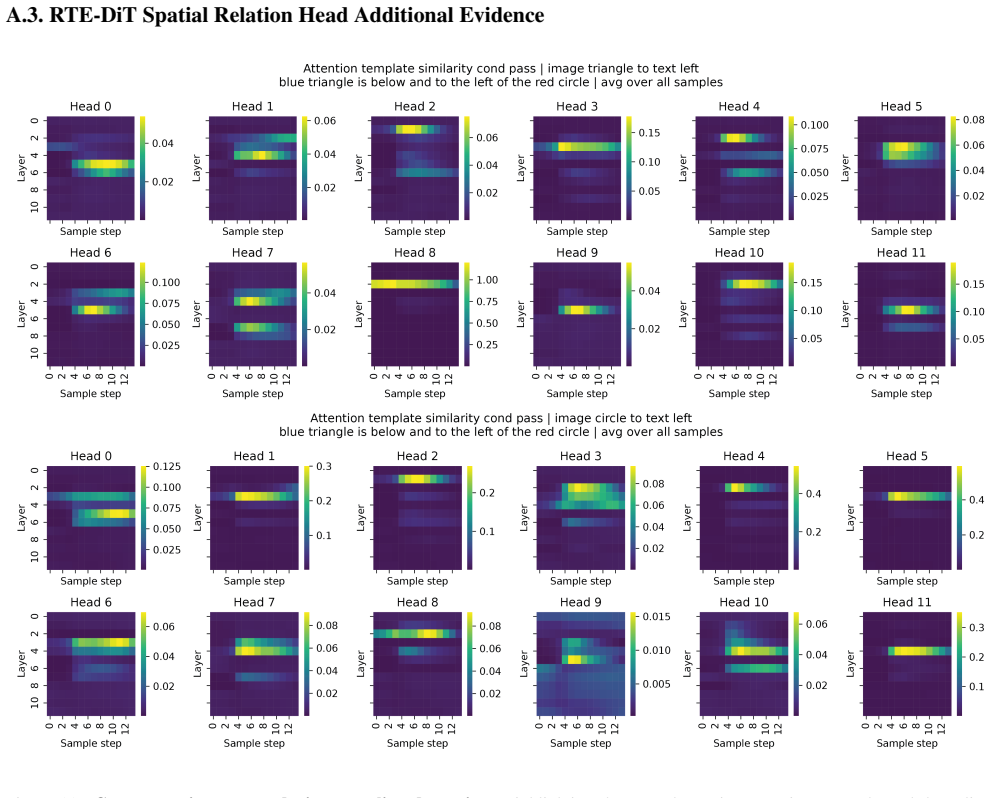
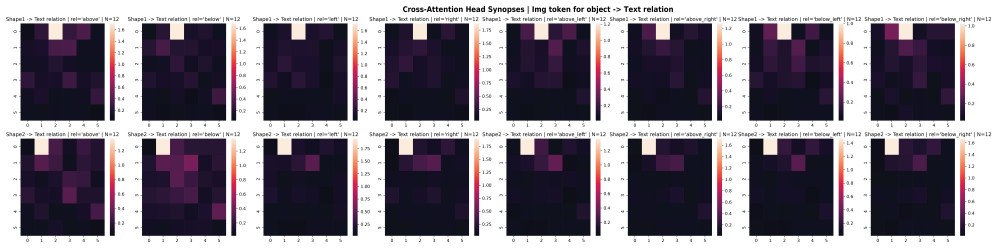
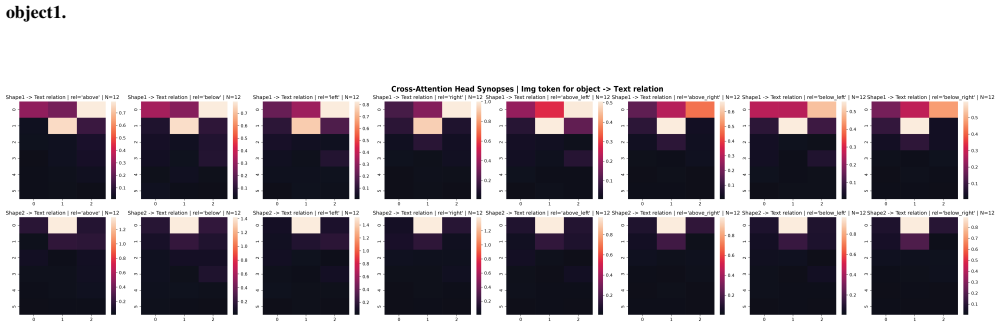
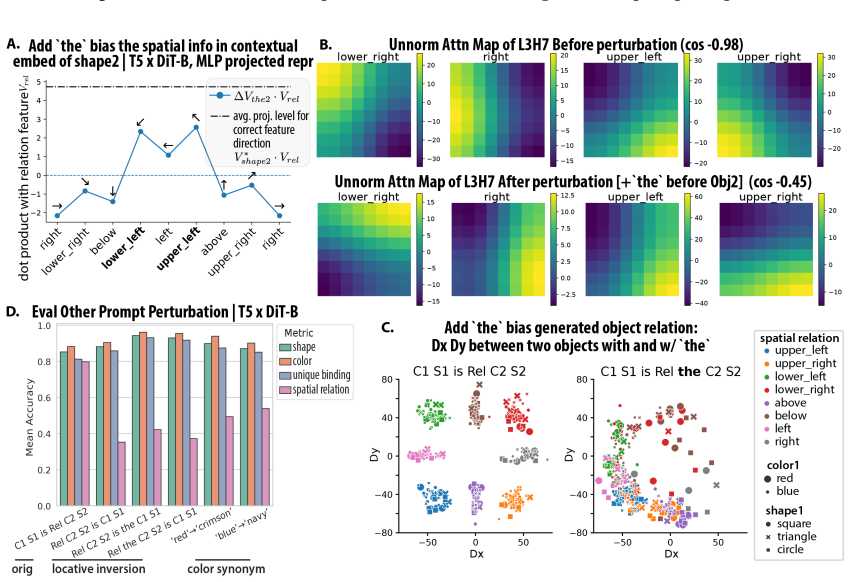
Although all models learn the task to near-perfect accuracy, the underlying mechanisms differ drastically depending on the choice of text encoder. When using random text embeddings, the spatial-relation information is passed to image tokens through a two-stage circuit involving two cross-attention heads that separately read the spatial relation and single-object attributes. When using a pretrained T5 encoder, the DiT uses a different circuit that leverages information fusion in the text tokens, reading spatial-relation and single-object information together from a single text token.
What carries the argument
Two distinct circuits that route spatial-relation information from text tokens to image tokens: a two-stage cross-attention pathway versus fused representation inside a single text token.
Load-bearing premise
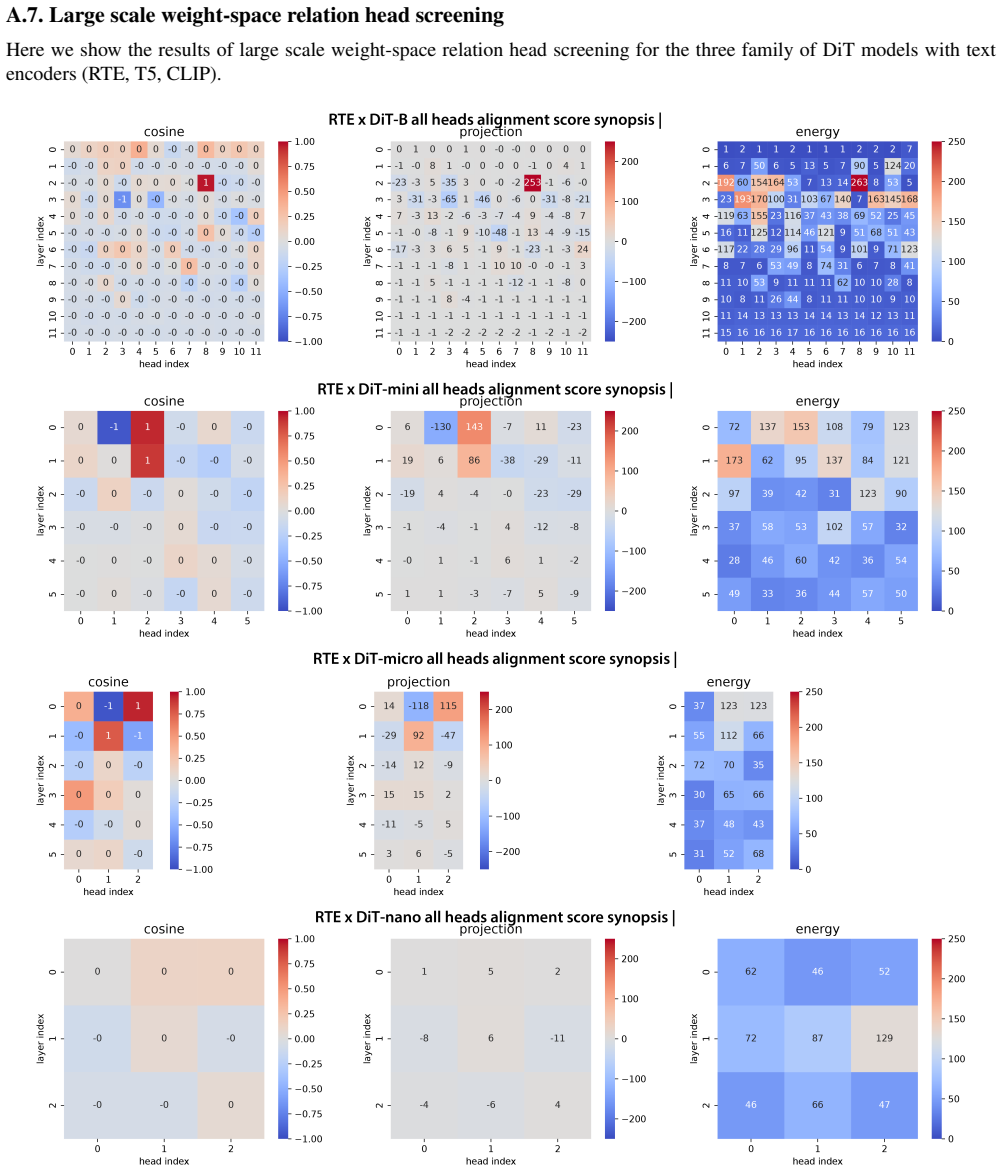
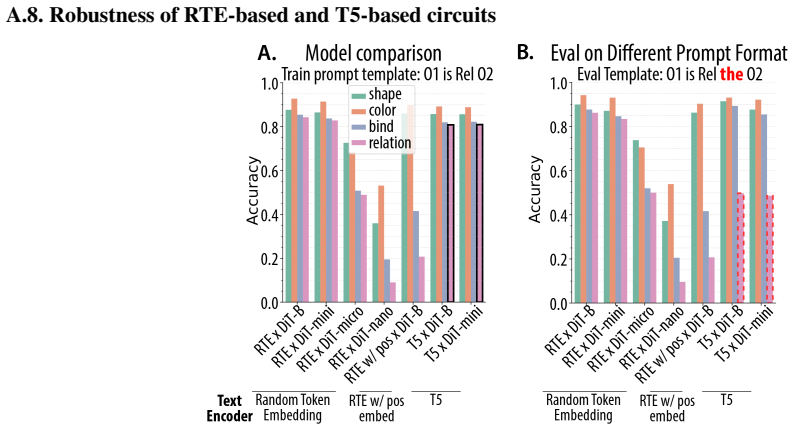
The circuits identified in small models trained from scratch accurately reflect or inform the mechanisms inside large-scale pretrained diffusion transformers used in applications.
What would settle it
Probing a large pretrained DiT on the same two-object spatial task and checking whether the two-stage cross-attention pattern or the single-token fusion pattern appears.
Figures





















read the original abstract
Diffusion Transformers (DiTs) have greatly advanced text-to-image generation, but models still struggle to generate the correct spatial relations between objects as specified in the text prompt. In this study, we adopt a mechanistic interpretability approach to investigate how a DiT can generate correct spatial relations between objects. We train, from scratch, DiTs of different sizes with different text encoders to learn to generate images containing two objects whose attributes and spatial relations are specified in the text prompt. We find that, although all the models can learn this task to near-perfect accuracy, the underlying mechanisms differ drastically depending on the choice of text encoder. When using random text embeddings, we find that the spatial-relation information is passed to image tokens through a two-stage circuit, involving two cross-attention heads that separately read the spatial relation and single-object attributes in the text prompt. When using a pretrained text encoder (T5), we find that the DiT uses a different circuit that leverages information fusion in the text tokens, reading spatial-relation and single-object information together from a single text token. We further show that, although the in-domain performance is similar for the two settings, their robustness to out-of-domain perturbations differs, potentially suggesting the difficulty of generating correct relations in real-world scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper trains small Diffusion Transformers (DiTs) from scratch on a synthetic two-object spatial-relation image generation task using either random text embeddings or a pretrained T5 encoder. It claims that all models reach near-perfect in-domain accuracy, yet the underlying circuits differ sharply: random embeddings induce a two-stage cross-attention pathway in which two heads separately read spatial relations and object attributes, while T5 induces information fusion within text tokens so that a single token supplies both relation and attribute information. The work further reports differing robustness to out-of-domain perturbations and suggests these mechanisms may help explain spatial-relation failures in large pretrained DiTs.
Significance. If the circuit identifications prove reproducible, the controlled comparison supplies concrete mechanistic evidence that text-encoder choice alters how spatial information is routed inside DiTs. This is a useful existence proof that distinct circuits can solve the same task and that out-of-domain robustness can diverge even when in-domain accuracy is matched. The absence of any bridging experiments to large-scale or pretrained models, however, confines the result to the small-scratch regime and weakens its immediate relevance to deployed text-to-image systems.
major comments (3)
- [Methods] Methods section: the manuscript provides no description of the circuit-discovery procedure (activation patching, attention-head ablation, causal interventions, or quantitative metrics) used to identify the two-stage cross-attention pathway or the single-token fusion mechanism. Without these details the central claim that the circuits are distinct cannot be evaluated.
- [Results] Results and §4: no error bars, run-to-run variance, or statistical controls accompany the “near-perfect accuracy” figures or the reported circuit differences. This omission is load-bearing because the paper’s strongest claim is that mechanisms differ despite matched performance.
- [Discussion] Discussion: the suggestion that the observed circuits “may indicate why real-world DiTs struggle with spatial relations” is unsupported; all experiments use small models trained from scratch, and no ablation, head-role comparison, or circuit analysis on any pretrained or large-scale DiT checkpoint is reported.
minor comments (1)
- [Figures] Figure captions and axis labels should explicitly state the number of training runs and random seeds underlying each plotted accuracy or attention value.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below with clarifications and proposed revisions to strengthen the manuscript while remaining within the scope of our controlled small-scale experiments.
read point-by-point responses
-
Referee: [Methods] Methods section: the manuscript provides no description of the circuit-discovery procedure (activation patching, attention-head ablation, causal interventions, or quantitative metrics) used to identify the two-stage cross-attention pathway or the single-token fusion mechanism. Without these details the central claim that the circuits are distinct cannot be evaluated.
Authors: We agree that the Methods section requires a more explicit description of the circuit identification techniques. In the revised manuscript we will add a dedicated subsection detailing the activation patching protocol, attention-head ablation experiments, causal interventions, and quantitative metrics (including logit-difference scores and attention-map consistency measures) used to establish the two-stage cross-attention circuit for random embeddings versus the single-token fusion circuit for T5. This addition will include procedural steps and representative examples to allow full evaluation of the claims. revision: yes
-
Referee: [Results] Results and §4: no error bars, run-to-run variance, or statistical controls accompany the “near-perfect accuracy” figures or the reported circuit differences. This omission is load-bearing because the paper’s strongest claim is that mechanisms differ despite matched performance.
Authors: We accept that variance reporting is necessary to support the claim of matched in-domain performance with distinct mechanisms. The revised Results section and §4 will include error bars (standard deviation across at least three independent training seeds per configuration) for accuracy metrics and circuit-identification outcomes. We will also add a brief statistical summary confirming that circuit differences remain consistent across runs. revision: yes
-
Referee: [Discussion] Discussion: the suggestion that the observed circuits “may indicate why real-world DiTs struggle with spatial relations” is unsupported; all experiments use small models trained from scratch, and no ablation, head-role comparison, or circuit analysis on any pretrained or large-scale DiT checkpoint is reported.
Authors: We recognize that our experiments are limited to small models trained from scratch and that direct evidence on large pretrained DiTs is absent. The original phrasing presented the link as a hypothesis motivated by the observed out-of-domain robustness differences. In revision we will reword the Discussion to frame this explicitly as a speculative direction for future work, add a limitations paragraph stating the small-model scope, and remove any implication of direct applicability to deployed systems. revision: partial
- We cannot perform circuit analysis on large-scale pretrained DiT checkpoints, as this would require access to model weights and computational resources beyond the controlled small-scale setting of the current study.
Circularity Check
No circularity in empirical circuit discovery
full rationale
The paper trains DiTs from scratch on a synthetic two-object spatial-relation task and identifies circuits via direct mechanistic analysis of attention heads and information flow. All claims rest on observed model behavior after training, head ablations, and comparisons between random embeddings versus T5 encoders; no parameters are fitted to the target result, no self-citations justify core premises, and no equations or definitions reduce the findings to their own inputs by construction. The derivation chain is therefore self-contained empirical observation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mechanistic interpretability techniques can accurately identify the functional circuits in the trained DiT models responsible for spatial relations.
Reference graph
Works this paper leans on
-
[1]
Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden- Eijnden. Stochastic Interpolants: A Unifying Framework for Flows and Diffusions, 2023. 1
work page 2023
-
[2]
Gary Bradski. The opencv library.Dr. Dobb’s Journal of Software Tools, 2000. 3
work page 2000
-
[3]
Getting it right: Improving spatial consis- tency in text-to-image models, 2024
Agneet Chatterjee, Gabriela Ben Melech Stan, Estelle Aflalo, Sayak Paul, Dhruba Ghosh, Tejas Gokhale, Ludwig Schmidt, Hannaneh Hajishirzi, Vasudev Lal, Chitta Baral, and Yezhou Yang. Getting it right: Improving spatial consis- tency in text-to-image models, 2024. 1
work page 2024
-
[4]
Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models, 2023
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models, 2023. 1, 2
work page 2023
-
[5]
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. PixArt-$α$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Syn- thesis, 2023. 2, 3, 34
work page 2023
-
[6]
Testing Relational Un- derstanding in Text-Guided Image Generation, 2022
Colin Conwell and Tomer Ullman. Testing Relational Un- derstanding in Text-Guided Image Generation, 2022. 1
work page 2022
-
[7]
Diffusion Models Beat GANs on Image Synthesis
Prafulla Dhariwal and Alex Nichol. Diffu- sion Models Beat GANs on Image Synthesis. https://arxiv.org/abs/2105.05233v4, 2021. 1
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
A mathematical framework for transformer circuits
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova Das- Sarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah....
work page 2021
-
[9]
Into the Rabbit Hull: From Task-Relevant Concepts in DINO to Minkowski Geometry
Thomas Fel, Binxu Wang, Michael A Lepori, Matthew Kowal, Andrew Lee, Randall Balestriero, Sonia Joseph, Ekdeep S Lubana, Talia Konkle, Demba Ba, et al. Into the rabbit hull: From task-relevant concepts in dino to minkowski geometry.arXiv preprint arXiv:2510.08638,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Geneval: An object-focused framework for evaluating text- to-image alignment, 2023
Dhruba Ghosh, Hanna Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text- to-image alignment, 2023. 1
work page 2023
-
[11]
Pro- gressive compositionality in text-to-image generative mod- els
Xu Han, Linghao Jin, Xiaofeng Liu, and Paul Pu Liang. Pro- gressive compositionality in text-to-image generative mod- els. InThe Thirteenth International Conference on Learning Representations, 2025. 1
work page 2025
-
[12]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 3, 35
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020. 1
work page 2020
-
[15]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffu- sion models. InAdvances in Neural Information Processing Systems, pages 8633–8646. Curran Associates, Inc., 2022. 1
work page 2022
-
[16]
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i-compbench: A comprehensive bench- mark for open-world compositional text-to-image genera- tion.Advances in Neural Information Processing Systems, 36:78723–78747, 2023. 1
work page 2023
-
[17]
Kaiyi Huang, Chengqi Duan, Kaiyue Sun, Enze Xie, Zhen- guo Li, and Xihui Liu. T2I-CompBench++: An Enhanced and Comprehensive Benchmark for Compositional Text-to- Image Generation .IEEE Transactions on Pattern Analysis Machine Intelligence, (01):1–17, 2025. 1
work page 2025
-
[18]
Raphi Kang, Yue Song, Georgia Gkioxari, and Pietro Perona. Is clip ideal? no. can we fix it? yes!, 2025. 2
work page 2025
-
[19]
Analyzing and Improving the Training Dynamics of Diffusion Models, 2024
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and Improving the Training Dynamics of Diffusion Models, 2024. 3
work page 2024
-
[20]
Gligen: Open-set grounded text-to-image generation, 2023
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jian- wei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation, 2023. 1
work page 2023
-
[21]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxi- milian Nickel, and Matt Le. Flow Matching for Generative Modeling, 2023. 1
work page 2023
-
[22]
Bingyan Liu, Chengyu Wang, Tingfeng Cao, Kui Jia, and Jun Huang. Towards Understanding Cross and Self-Attention in Stable Diffusion for Text-Guided Image Editing, 2024. arXiv:2403.03431 [cs]. 4
-
[23]
DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongx- uan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models.arXiv preprint arXiv:2211.01095, 2022. 3, 35
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Maya Okawa, Ekdeep Singh Lubana, Robert P. Dick, and Hidenori Tanaka. Compositional Abilities Emerge Multi- plicatively: Exploring Diffusion Models on a Synthetic Task,
-
[25]
Emergence of Hid- den Capabilities: Exploring Learning Dynamics in Concept Space, 2024
Core Francisco Park, Maya Okawa, Andrew Lee, Hidenori Tanaka, and Ekdeep Singh Lubana. Emergence of Hid- den Capabilities: Exploring Learning Dynamics in Concept Space, 2024. 2
work page 2024
-
[26]
Grounded text-to-image synthesis with attention refocusing, 2023
Quynh Phung, Songwei Ge, and Jia-Bin Huang. Grounded text-to-image synthesis with attention refocusing, 2023. 2
work page 2023
-
[27]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, 2023. 3
work page 2023
-
[28]
High-Resolution Image Synthesis with Latent Diffusion Models, 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models, 2022. 2, 3
work page 2022
-
[29]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 1, 34
work page 2022
-
[30]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InProceedings of the 32nd International Conference on Machine Learning, pages 2256–2265, Lille, France, 2015. PMLR. 1
work page 2015
-
[31]
What the DAAM: Interpreting stable diffusion using cross attention
Raphael Tang, Akshat Pandey, Zhiying Jiang, Gefei Yang, Karun Kumar, Jimmy Lin, and Ferhan Ture. What the DAAM: Interpreting stable diffusion using cross attention. arXiv preprint arXiv:2210.04885, 2022. 4
-
[32]
Martin Wattenberg and Fernanda B. Vi´egas. Relational Com- position in Neural Networks: A Survey and Call to Action,
-
[33]
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers, 2024
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, and Song Han. SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers, 2024. 2
work page 2024
-
[34]
blue triangle is to the upper left of red square
Gaoyang Zhang, Bingtao Fu, Qingnan Fan, Qi Zhang, Runx- ing Liu, Hong Gu, Huaqi Zhang, and Xinguo Liu. Compass: Enhancing spatial understanding in text-to-image diffusion models, 2024. 2 A. Extended Results A.1. Evaluation and Benchmark 0.0 0.2 0.4 0.6 0.8 1.0 Mean(single: color, shape, texture) 0.0 0.2 0.4 0.6 0.8 1.0Mean(spatial: 2D, 3D) SD v1-4 SD v2 C...
work page 2024
-
[35]
Shuffle the labels of factorf:˜y (f) i =y (f) π(i)
-
[36]
Reconstruct the permuted designZ (f) π and the full designZ π = [Z (f) π , Z−f]
-
[37]
Form the permuted projectorP all,π and compute SS part f,π = tr A Pall,π −P −f .(19) GivenN perm permutations, we define the permutationp-value as pf = 1 + #{π:SS part f,π ≥SS part f } 1 +N perm .(20) Table 4.Example Variance partitioning results for representational factors of T5 contextual word vector. The model achieves a total explained variance ofR 2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.