On the Provable Suboptimality of Momentum SGD in Nonstationary Stochastic Optimization
Pith reviewed 2026-05-21 15:29 UTC · model grok-4.3
The pith
Momentum SGD incurs a drift-amplification penalty under distribution shift that grows as the momentum parameter approaches 1, producing systematic tracking lag that vanilla SGD avoids.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
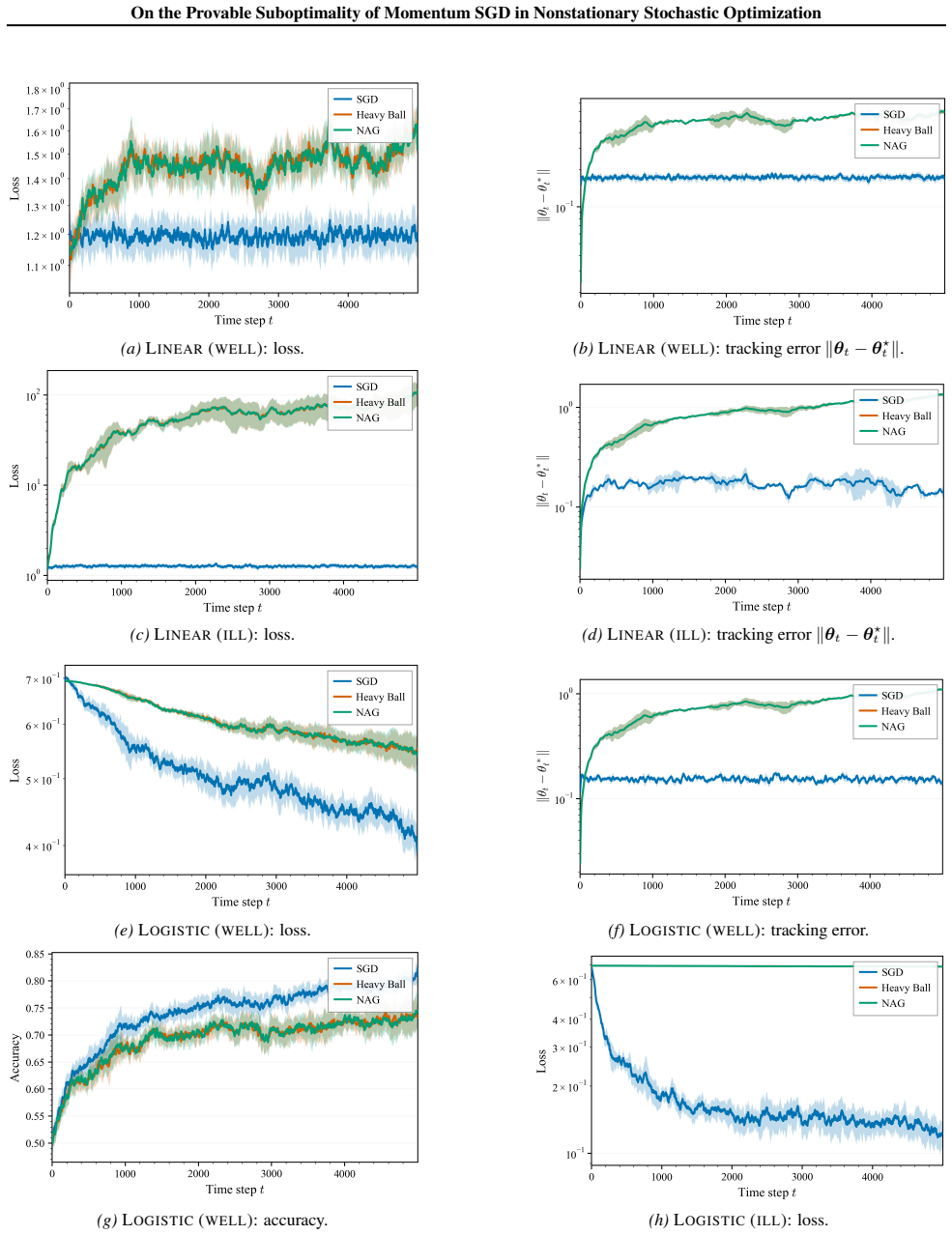
Under the stated strong-convexity and smoothness assumptions, momentum methods introduce an explicit drift-amplification term in the tracking error that diverges with the momentum parameter β approaching 1. This produces systematic lag behind the moving optimum. The upper bounds are paired with minimax lower bounds over gradient-variation classes, establishing that stale-gradient averaging forces an information-theoretic barrier: in drift-dominated regimes momentum is provably inferior to plain SGD.
What carries the argument
The tracking-error decomposition that isolates a drift-induced component whose size grows with the momentum parameter β.
If this is right
- In drift-dominated regimes vanilla SGD provably tracks the moving optimum more accurately than momentum variants.
- The information-theoretic lower bounds delimit the regime boundaries where momentum becomes harmful.
- The explicit penalty explains observed instability of momentum in dynamic environments.
- Practitioners can use the decomposition to decide when to disable momentum.
Where Pith is reading between the lines
- Similar lag penalties may appear in other accelerated first-order methods under nonstationarity.
- The result suggests testing momentum decay schedules that keep β well below 1 during periods of high drift.
- Extensions could relax strong convexity to see whether the barrier persists in convex or nonconvex drifting settings.
Load-bearing premise
The time-varying objectives remain strongly convex and smooth throughout the analysis.
What would settle it
In a controlled strongly convex and smooth nonstationary problem with measurable gradient variations, run momentum SGD at several β values approaching 1 and record whether the observed tracking error increases with β; if the error stays flat or decreases, the claimed penalty does not hold.
Figures




read the original abstract
In this paper, we provide a comprehensive theoretical analysis of Stochastic Gradient Descent (SGD) and its momentum variants (Polyak Heavy-Ball and Nesterov) for tracking time-varying optima under strong convexity and smoothness. Our finite-time bounds reveal a sharp decomposition of tracking error into transient, noise-induced, and drift-induced components. This decomposition exposes a fundamental trade-off: while momentum is often used as a gradient-smoothing heuristic, under distribution shift it incurs an explicit drift-amplification penalty that diverges as the momentum parameter $\beta$ approaches 1, yielding systematic tracking lag. We complement these upper bounds with minimax lower bounds under gradient-variation constraints, proving this momentum-induced tracking penalty is not an analytical artifact but an information-theoretic barrier: in drift-dominated regimes, momentum is unavoidably worse because stale-gradient averaging forces systematic lag. Our results provide theoretical grounding for the empirical instability of momentum in dynamic settings and precisely delineate regime boundaries where vanilla SGD provably outperforms its accelerated counterparts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes SGD and momentum variants (Polyak Heavy-Ball and Nesterov) for tracking time-varying optima under strong convexity and smoothness. Finite-time upper bounds decompose tracking error into transient, noise-induced, and drift-induced terms, exposing a drift-amplification penalty for momentum that diverges as β approaches 1. These upper bounds are paired with minimax lower bounds under gradient-variation constraints, establishing the penalty as an information-theoretic barrier in drift-dominated regimes where momentum is provably worse than vanilla SGD.
Significance. If the bounds are correct, the work supplies a precise theoretical account of why momentum can exhibit instability under distribution shift, while identifying explicit regime boundaries where SGD outperforms its accelerated counterparts. The upper/lower bound pairing is a strength, as it converts an empirical observation into a falsifiable, information-theoretic statement rather than an artifact of analysis technique.
major comments (1)
- [lower-bound section (minimax result)] The central claim that the drift penalty is information-theoretic rests on the gradient-variation constraint in the lower-bound construction. Please confirm in the proof of the minimax lower bound that the variation measure is defined identically to the one appearing in the upper-bound drift term; any mismatch would weaken the matching claim.
minor comments (2)
- The abstract states that both Polyak and Nesterov momentum incur the same drift penalty; the main text should explicitly note whether the constants differ between the two variants or whether the analysis treats them uniformly.
- [finite-time bounds] All finite-time bounds should list the explicit dependence of the drift term on β and on the gradient-variation measure so that readers can directly recover the regime boundaries without re-deriving the expressions.
Simulated Author's Rebuttal
We thank the referee for their thorough review and insightful comment on the minimax lower bound. We are pleased that the significance of the work is recognized. Below we provide a point-by-point response to the major comment.
read point-by-point responses
-
Referee: [lower-bound section (minimax result)] The central claim that the drift penalty is information-theoretic rests on the gradient-variation constraint in the lower-bound construction. Please confirm in the proof of the minimax lower bound that the variation measure is defined identically to the one appearing in the upper-bound drift term; any mismatch would weaken the matching claim.
Authors: We confirm that the variation measure is defined identically in both the upper and lower bounds. In the upper-bound analysis (Theorem 3), the drift-induced error term is bounded in terms of the total gradient variation V_G = sum_{t=1}^T ||nabla f_t(x_t^*) - nabla f_{t-1}(x_{t-1}^*)||, where x_t^* denotes the time-varying optimum. The minimax lower bound construction in Section 4 employs precisely the same constraint: the adversary is restricted to sequences where the cumulative gradient variation is at most V_G. This identical definition ensures that the lower bound applies directly to the regimes analyzed in the upper bounds, establishing that the drift-amplification penalty for momentum is indeed an information-theoretic barrier rather than an artifact of the analysis. To make this equivalence more explicit, we will include a clarifying remark in the revised manuscript. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper derives finite-time upper bounds decomposing tracking error into transient, noise-induced, and drift-induced terms for SGD and momentum methods under strong convexity and smoothness, explicitly expressing the drift-amplification penalty in terms of the momentum parameter β and gradient variation. These are paired with independent minimax lower bounds under gradient-variation constraints. No step reduces by construction to a fitted parameter, self-definition, or load-bearing self-citation chain; the bounds are self-contained mathematical derivations within the stated assumptions and do not rely on renaming or smuggling ansatzes from prior self-work. This matches the default expectation of no significant circularity (score 0-2) for papers with explicit, falsifiable bound derivations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The time-varying objective functions are strongly convex and smooth.
- domain assumption Gradient variation is bounded in the minimax lower-bound construction.
Forward citations
Cited by 1 Pith paper
-
Adapt or Forget: Provable Tradeoffs Between Adam and SGD in Nonstationary Optimization
Adam's adaptive preconditioning and first-moment averaging improve high-probability tracking error in noise-dominated nonstationary regimes but can increase it under strong drift, where SGD achieves a smaller floor, w...
Reference graph
Works this paper leans on
-
[1]
Cevher, V ., Becker, S., and Schmidt, M
doi: 10.23919/ACC.2019.8814889. Cevher, V ., Becker, S., and Schmidt, M. Convex optimiza- tion for big data: Scalable, randomized, and parallel al- gorithms for big data analytics.IEEE Signal Processing Magazine, 31(5):32–43, 2014. doi: 10.1109/MSP.2014. 2329397. Chen*, J., Pan*, X., Monga, R., Bengio, S., and Joze- fowicz, R. Revisiting distributed synch...
-
[2]
URL https://openreview.net/forum? id=HyAddcLge. Chen, J., Wolfe, C., Li, Z., and Kyrillidis, A. Demon: Improved neural network training with momentum decay. InICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3958–3962, 2022. doi: 10.1109/ICASSP43922.2022. 9746839. Chen, X., Wang, Y ., and Wang, Y .-...
-
[3]
cc/paper_files/paper/2021/file/ 62e7f2e090fe150ef8deb4466fdc81b3-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ 62e7f2e090fe150ef8deb4466fdc81b3-Paper. pdf. Cutler, J., Drusvyatskiy, D., and Harchaoui, Z. Stochas- tic optimization under distributional drift.Jour- nal of Machine Learning Research, 24(147):1–56,
work page 2021
-
[4]
Davtyan, A., Sameni, S., Cerkezi, L., Meishvili, G., Bielski, A., and Favaro, P
URL http://jmlr.org/papers/v24/ 21-1410.html. Davtyan, A., Sameni, S., Cerkezi, L., Meishvili, G., Bielski, A., and Favaro, P. Koala: A Kalman opti- mization algorithm with loss adaptivity.Proceedings of the AAAI Conference on Artificial Intelligence, 36 (6):6471–6479, Jun. 2022. doi: 10.1609/aaai.v36i6. 20599. URL https://ojs.aaai.org/index. php/AAAI/art...
-
[5]
URL https://proceedings.mlr.press/ v97/ghorbani19b.html. Gitman, I., Lang, H., Zhang, P., and Xiao, L.Understanding the role of momentum in stochastic gradient methods. Curran Associates Inc., Red Hook, NY , USA, 2019. Godichon-Baggioni, A., Lu, W., and Portier, B. Online estimation of the inverse of the hessian for stochastic op- timization with applicat...
-
[6]
ISSN 2167-3888. doi: 10.1561/2400000013. URL https://doi.org/10.1561/2400000013. Huang, T., Zhu, Z., Jin, G., Liu, L., Wang, Z., and Liu, S. SPAM: Spike-aware Adam with momentum reset for sta- ble LLM training. InThe Thirteenth International Confer- ence on Learning Representations, 2025. URL https: //openreview.net/forum?id=L9eBxTCpQG. Ilboudo, W. E. L.,...
-
[7]
Jagannath, A., Jones-McCormick, T., and Sarangian, V
doi: 10.1109/TNNLS.2020.3041755. Jagannath, A., Jones-McCormick, T., and Sarangian, V . High-dimensional limit theorems for SGD: Momentum and adaptive step-sizes, 2025. URL https://arxiv. org/abs/2511.03952. arXiv:2511.03952. Jastrz˛ ebski, S., Kenton, Z., Ballas, N., Fischer, A., Bengio, Y ., and Storkey, A. On the relation between the sharpest direction...
-
[8]
URL https://openreview.net/forum? id=SkgEaj05t7. Jelassi, S. and Li, Y . Towards understanding how momentum improves generalization in deep learning,
-
[9]
Jentzen, A., Kranz, J., and Riekert, A
URL https://openreview.net/forum? id=lf0W6tcWmh-. Jentzen, A., Kranz, J., and Riekert, A. PADAM: Parallel av- eraged Adam reduces the error for stochastic optimization in scientific machine learning, 2025. URL https:// arxiv.org/abs/2505.22085. arXiv:2505.22085. Kingma, D. P. and Ba, J. Adam: A method for stochas- tic optimization. In Bengio, Y . and LeCu...
-
[10]
URL https://api.semanticscholar. org/CorpusID:15039054. 10 On the Provable Suboptimality of Momentum SGD in Nonstationary Stochastic Optimization Li, X., Luo, J., Zheng, Z., Wang, H., Luo, L., Wen, L., Wu, L., and Xu, S. On the performance analysis of momentum method: A frequency domain perspective. InThe Thirteenth International Conference on Learning Re...
work page 2025
-
[11]
URL https://proceedings.mlr.press/ v237/liao24a.html. Liu, J., Su, J., Yao, X., Jiang, Z., Lai, G., Du, Y ., Qin, Y ., Xu, W., Lu, E., Yan, J., Chen, Y ., Zheng, H., Liu, Y ., Liu, S., Yin, B., He, W., Zhu, H., Wang, Y ., Wang, J., Dong, M., Zhang, Z., Kang, Y ., Zhang, H., Xu, X., Zhang, Y ., Wu, Y ., Zhou, X., and Yang, Z. Muon is scalable for llm train...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Luo, L., Xiong, Y ., and Liu, Y
URL https://openreview.net/forum? id=Syxt5oC5YQ. Luo, L., Xiong, Y ., and Liu, Y . Adaptive gradient methods with dynamic bound of learning rate. InIn- ternational Conference on Learning Representations,
-
[13]
URL https://openreview.net/forum? id=Bkg3g2R9FX. Nesterov, Y . A method for solving the convex programming problem with convergence rateo(1/k2).Dokl Akad Nauk SSSR, 269:543, 1983. URL https://cir.nii.ac. jp/crid/1370862715914709505. Nesterov, Y . Introductory lectures on convex opti- mization - a basic course. InApplied Optimization,
-
[14]
The Extended Kalman Filter is a Natural Gradient Descent in Trajectory Space
URL https://api.semanticscholar. org/CorpusID:62288331. Ollivier, Y . The extended Kalman filter is a natural gradi- ent descent in trajectory space, 2019. URL https:// arxiv.org/abs/1901.00696. arXiv:1901.00696. Papyan, V . Traces of class/cross-class structure pervade deep learning spectra.Journal of Machine Learning Research, 21(252):1–64, 2020. URL ht...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/0041-5553(63)90382-3 2019
- [15]
-
[16]
URL https://arxiv.org/abs/1810. 12273. arXiv:1810.12273. Vyas, N., Morwani, D., Zhao, R., Shapira, I., Brandfon- brener, D., Janson, L., and Kakade, S. M. SOAP: Im- proving and stabilizing shampoo using Adam for lan- guage modeling. InThe Thirteenth International Confer- ence on Learning Representations, 2025. URL https: //openreview.net/forum?id=IDxZhXrp...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
URL https: //doi.org/10.1155/2017/9478952
doi: 10.1155/2017/9478952. URL https: //doi.org/10.1155/2017/9478952. Article ID 9478952, 9 pages. Yang, X. Towards stochastic gradient variance reduction by solving a filtering problem, 2023. URL https:// openreview.net/forum?id=0sxmoci9Ma. Yao, Z., Gholami, A., Shen, S., Mustafa, M., Keutzer, K., and Mahoney, M. ADAHESSIAN: An adaptive second order opti...
-
[18]
ADADELTA: An Adaptive Learning Rate Method
URL https://proceedings.neurips. cc/paper_files/paper/2018/file/ 90365351ccc7437a1309dc64e4db32a3-Paper. pdf. Zeiler, M. D. Adadelta: An adaptive learning rate method, 2012. URL https://arxiv.org/abs/ 1212.5701. arXiv:1212.5701. Zhang, J. and Mitliagkas, I. Yellowfin and the art of momentum tuning. In Talwalkar, A., Smith, V ., and Zaharia, M. (eds.),Proc...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
org/paper_files/paper/2019/file/ b205b525b7ce002baae53228bab6d26b-Paper
URL https://proceedings.mlsys. org/paper_files/paper/2019/file/ b205b525b7ce002baae53228bab6d26b-Paper. pdf. Zhang, T. Solving large scale linear prediction prob- lems using stochastic gradient descent algorithms. In 12 On the Provable Suboptimality of Momentum SGD in Nonstationary Stochastic Optimization Proceedings of the Twenty-First International Con-...
-
[20]
Zhao, P., Zhang, Y .-J., Zhang, L., and Zhou, Z.-H
URL https://www.sciencedirect.com/ science/article/pii/S0167739X18332540. Zhao, P., Zhang, Y .-J., Zhang, L., and Zhou, Z.-H. Adaptiv- ity and non-stationarity: Problem-dependent dynamic re- gret for online convex optimization.Journal of Machine Learning Research, 25(98):1–52, 2024. URL http: //jmlr.org/papers/v25/21-0748.html. Zhou, K., Jin, Y ., Ding, Q...
work page 2024
-
[21]
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ eddea82ad2755b24c4e168c5fc2ebd40-Paper. pdf. Ziyin, L., Wang, Z. T., and Ueda, M. Laprop: Separating mo- mentum and adaptivity in Adam, 2021. URL https:// arxiv.org/abs/2002.04839. arXiv:2002.04839. 13 On the Provable Suboptimality of Momentum SGD in Nonstationary Stochastic Optimization App...
-
[22]
Then ξt+1(θ) is Ft+1–measurable and satisfies E[ξt+1(θ)| Ft] =0a.s
(Martingale difference noise)Define the conditional mean gradient mt+1(θ) =E ∇θg(θ, Xt+1)| F t , and the gradient noise ξt+1(θ) =∇ θg(θ, Xt+1)−m t+1(θ). Then ξt+1(θ) is Ft+1–measurable and satisfies E[ξt+1(θ)| Ft] =0a.s. for allθ∈R d. Under this framework, SGD admits the decomposition θt+1 =θ t −γ tmt+1(θt)−γ tξt+1(θt).(SGD) For momentum, we use a two-par...
-
[23]
(Gradient noise along iterates)The gradient noise ξt+1 satisfies E ∥ξt+1(θt)∥2 ≤σ 2 and E ∥ξt+1(ψt)∥2 ≤ 18 On the Provable Suboptimality of Momentum SGD in Nonstationary Stochastic Optimization σ2 a.s. C.1. Proof for SGD tracking error bound First we will prove a recursive relation for the tracking error that we will subsequently use for our expectation a...
work page 2021
-
[24]
(Step-decay schedule in the low drift-to-noise regime).Suppose γ⋆ <1/2L (equivalently, the minimizer of E(γ) is not at the smoothness cap), so that γ⋆ = 8∆2 µσ2 1/3 ,E= 3 ∆σ2 µ2 2/3 . Define epochsk= 0,1, . . . , K−1with γ0 := 1 2L , γ k := γk−1 +γ ⋆ 2 (k≥1), K:= 1 + l log2 γ0 γ⋆ m , and epoch lengths T0 := l 2 µγ0 log 2∥θ0 −θ ⋆ 0∥2 E(γ0) m , T k := l2 lo...
work page 2016
-
[25]
(Step-decay schedule with momentum restart).Suppose γ⋆ β < µ(1−β) 2/(4L2) (i.e., the minimizer of Eβ(γ) is not at the stability cap). Define the epoch stepsizes γ0 := µ(1−β) 2 4L2 , γ k := γk−1 +γ ⋆ β 2 (k≥1), K:= 1 + l log2 γ0 γ⋆ β m . 31 On the Provable Suboptimality of Momentum SGD in Nonstationary Stochastic Optimization Define epoch lengths T0 := l1−...
work page 2012
-
[26]
(Minimizers.) Eachg u admits a unique minimizerθ ⋆ u, andθ ⋆ u =uae 1
-
[27]
(Discrepancy.) The two-point discrepancy satisfiesχ(g +, g−)≥µa 2/8. Proof of Lemma E.4. On the Euclidean ball {θ:∥θ∥ 2 ≤r/2} , we have ψr(θ) = 1 and ∇ψr(θ) = 0 by construction of the bump. Therefore, for all ∥θ∥2 ≤r/2 , ∇gu(θ) =µθ−uµae 1. Setting ∇gu(θ) = 0 yields θ=uae 1, and this point indeed lies in the region where the above simplification holds sinc...
-
[28]
The Markov chain (St)t≥0 admits a unique stationary distribution π∞, which is a centered Gaussian N(0,Σ ∞) on R2
-
[29]
The stationary covarianceΣ ∞ is the unique positive semidefinite solution of the discrete-time Lyapunov equation Σ =AΣA ⊤ +σ 2BB ⊤.(172)
-
[30]
WritingΣ ∞ = ( v c c v )withv= Var π∞(xt)andc= Cov π∞(xt, xt−1), we have the exact closed form v= (1 +β)γ 2σ2 (1−β) (1 +β) 2 −(1 +β−γµ) 2 = (1 +β)γσ 2 (1−β)µ 2(1 +β)−γµ .(173)
-
[31]
In the stable regime one necessarily has γµ <2(1 +β) , so the denominator in (173) is positive. Moreover, if additionallyγµ≤1 +β(a common small-step regime), then v≥ γσ2 4µ(1−β) .(174) Proof of Lemma E.7. We proceed in four steps: (1) existence/uniqueness of a stationary law, (2) characterization via a Lyapunov equation, (3) explicit solution of the(1,1)e...
work page 2019
-
[32]
Gaussian-gradient KL bound:from Lemma E.12, we have supu,v∈U DKL(P π u ∥P π v )≤Cµ 2a2T /(σ2/(1−β)),∀π
-
[33]
LetV T >0be the variation budget
Packing size lower bound:from Lemma E.9, we have the packing size lower bound log|U | ≥c J for a universal constantc >0(e.g., from Varshamov–Gilbert or constant-weight codes). LetV T >0be the variation budget. Choose a:= VT C µ J1/q 1/α .(209) ThenGVar p,q(Gu 1:T )≤V T for allu∈ U. Moreover, ifJadditionally satisfies C µ2a2 σ2/(1−β) T≤ c 2 J,(210) then Fa...
-
[34]
sub-Gaussian × sub-Gaussian ⇒ sub-exponential
Subsequently invoking Lemma E.1, we conclude that there does not exist an admissible policy π∈Π β such that supg∈Gp,q(VT ) Rπ,ϕG T (g)≤ 1 9 inf g,˜g∈Θ PT t=1 χ(gt,˜gt). This gives us a lower bound for the minimax regret. Now we must just enforce the gradient variational budget and the information constraint. To enforce the gradient variational budget, we ...
-
[35]
for a constantK, then∥X| G 1∥Ψ2 ≤Ka.s
IfG 1 ⊆ G2 and∥X| G 2∥Ψ2 ≤Ka.s. for a constantK, then∥X| G 1∥Ψ2 ≤Ka.s
-
[36]
for a constantK, then∥XY| G∥ Ψα ≤K∥X| G∥ Ψα a.s
If|Y| ≤Ka.s. for a constantK, then∥XY| G∥ Ψα ≤K∥X| G∥ Ψα a.s
-
[37]
IfXis independent ofG, then∥X| G∥ Ψα =∥X∥ Ψα a.s
-
[38]
IfX⊥Y| G, thenE[XY| G] =E[X| G]E[Y| G]a.s., andE[X|Y,G] =E[X| G]a.s. Proof. (i) By assumption, E[exp(|X/K|2)| G 2]≤2 a.s.; taking G1-conditional expectations and using the tower property yields E[exp(|X/K|2)| G 1]≤2 a.s., hence ∥X| G 1∥Ψ2 ≤K . (ii) If ϕ is admissible for X given G, then Kϕ is admissible for XY given G since |XY|/(Kϕ)≤ |X|/ϕ . Taking essen...
-
[39]
(Vector).Let X∈R d. If supu∈Sd−1,u∈F E exp |u⊤X|2/K2 F | F ≤2a.s , then E[XX⊤ | F]⪯K 2 F Id a.s and henceE[∥X∥ 2 2 | F]≤dK 2 F a.s Proof.We first prove the scalar case. Bye y ≥1 +yfory≥0, 2≥E 1 + |X|2 K2 F F = 1 + 1 K2 F E[|X|2 | F]a.s., soE[|X| 2 | F]≤K 2 F. The vector case follows very similarly. Fix any F-measurable u∈S d−1 and apply the scalar part to...
-
[40]
(Unbounded stopping time via truncation).Assume E[|Mτ∧n |]<∞ for all n and that {Mτ∧n }n≥1 is uniformly integrable. Then E[Mτ] =E[M 0]. More generally, if(Mt) is an integrable supermartingale (resp. submartingale), then ineither(i) or (ii) we have E[Mτ]≤ E[M0](resp.E[M τ]≥E[M 0]). Proof.We first show that the stopped process is a martingale: Step 1: Show ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.