PROGRESSLM: Towards Progress Reasoning in Vision-Language Models
Pith reviewed 2026-05-25 06:48 UTC · model grok-4.3
The pith
A small vision-language model trained on progress reasoning data improves at estimating task progress on entirely new tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
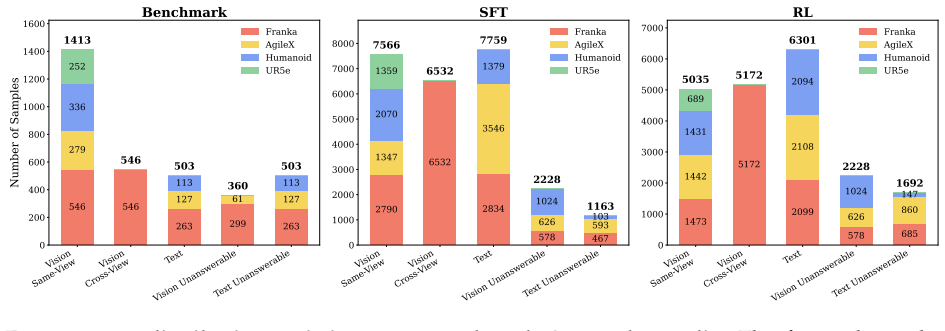
Progress reasoning requires inferring long-horizon dynamics from partial views. Most of the 14 tested VLMs perform poorly on Progress-Bench, showing sensitivity to modality and viewpoint plus weak handling of unanswerable cases. A human-inspired two-stage paradigm yields only modest prompting gains, yet the same paradigm applied through supervised training on ProgressLM-45K produces ProgressLM-3B, which delivers consistent accuracy lifts on the benchmark despite complete task disjointness between training and evaluation sets.
What carries the argument
Two-stage progress reasoning paradigm (state description followed by progress estimation), instantiated via training on the ProgressLM-45K dataset to produce ProgressLM-3B.
If this is right
- Explicit training on progress signals can instill temporal reasoning that prompting alone does not reliably produce.
- Small-scale models can acquire this capability when given suitable data.
- Progress estimation generalizes across task domains when the training set targets the underlying reasoning structure.
- Benchmark results expose specific weaknesses such as viewpoint sensitivity that future models must address.
Where Pith is reading between the lines
- The same two-stage approach could be applied to embodied agents that must monitor their own ongoing actions.
- Progress reasoning may serve as a building block for longer-horizon planning and goal monitoring in autonomous systems.
- The observed transfer from disjoint tasks suggests the model learns abstract progress concepts rather than surface task patterns.
Load-bearing premise
The signals captured in the ProgressLM-45K dataset reflect generalizable progress estimation that transfers to the activities in Progress-Bench.
What would settle it
If ProgressLM-3B shows no accuracy gain or degrades relative to its base model when evaluated on Progress-Bench, the transfer claim would be falsified.
Figures



















read the original abstract
Estimating task progress requires reasoning over long-horizon dynamics rather than recognizing static visual content. While modern Vision-Language Models (VLMs) excel at describing what is visible, it remains unclear whether they can infer how far a task has progressed from partial observations. To this end, we introduce Progress-Bench, a benchmark for systematically evaluating progress reasoning in VLMs. Beyond benchmarking, we further explore a human-inspired two-stage progress reasoning paradigm through both training-free prompting and training-based approach based on curated dataset ProgressLM-45K. Experiments on 14 VLMs show that most models are not yet ready for task progress estimation, exhibiting sensitivity to demonstration modality and viewpoint changes, as well as poor handling of unanswerable cases. While training-free prompting that enforces structured progress reasoning yields limited and model-dependent gains, the training-based ProgressLM-3B achieves consistent improvements even at a small model scale, despite being trained on a task set fully disjoint from the evaluation tasks. Further analyses reveal characteristic error patterns and clarify when and why progress reasoning succeeds or fails. Website: https://progresslm.github.io/ProgressLM/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Progress-Bench, a benchmark for evaluating task progress reasoning in VLMs from partial observations, along with ProgressLM-45K, a curated dataset supporting a two-stage human-inspired reasoning paradigm. It evaluates 14 VLMs, finding most struggle with modality/viewpoint sensitivity and unanswerable cases; training-free prompting yields limited gains, while a trained ProgressLM-3B model reports consistent improvements on the benchmark despite training on a fully disjoint task set from the evaluation tasks. Further analyses examine error patterns.
Significance. If the generalization result holds, the work addresses a clear gap in VLM capabilities for long-horizon dynamics beyond static recognition, with potential impact on robotics and agentic systems. Strengths include the new benchmark, the explicit training on a disjoint task set (if verified), and the empirical demonstration that small-scale training can yield gains where prompting does not. The dataset and benchmark are concrete contributions that could enable follow-on work.
major comments (2)
- [Abstract, §3] Abstract and §3 (dataset/task description): The headline claim that ProgressLM-3B 'achieves consistent improvements even at a small model scale, despite being trained on a task set fully disjoint from the evaluation tasks' is load-bearing for the argument that the model acquires abstract progress reasoning rather than exploiting shared task dynamics. The manuscript asserts full disjointness but provides no enumerated breakdown of training vs. evaluation task categories, object classes, action sequences, or environments (normally expected in §3.2 or Table 1), leaving open the possibility that both sets contain overlapping long-horizon manipulation or navigation primitives.
- [§4] §4 (experiments) and associated tables/figures: The soundness assessment is limited by the absence of reported metrics such as error bars, ablation studies on the two-stage paradigm components, or dataset statistics (e.g., task distribution, sequence lengths) that would allow verification of whether the reported gains are robust or sensitive to post-hoc choices in data curation or evaluation.
minor comments (2)
- [Abstract] The abstract references 'Further analyses reveal characteristic error patterns' without indicating the specific section or figure where these are presented, which would improve readability.
- Website link is provided but no mention of whether code, model weights, or the full ProgressLM-45K dataset splits are released to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight areas where additional details can strengthen the presentation of our claims regarding task disjointness and experimental robustness. We address each point below and commit to revisions that clarify these aspects without altering the core findings.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (dataset/task description): The headline claim that ProgressLM-3B 'achieves consistent improvements even at a small model scale, despite being trained on a task set fully disjoint from the evaluation tasks' is load-bearing for the argument that the model acquires abstract progress reasoning rather than exploiting shared task dynamics. The manuscript asserts full disjointness but provides no enumerated breakdown of training vs. evaluation task categories, object classes, action sequences, or environments (normally expected in §3.2 or Table 1), leaving open the possibility that both sets contain overlapping long-horizon manipulation or navigation primitives.
Authors: We agree that an explicit breakdown would make the disjointness claim more verifiable and directly address potential concerns about shared primitives. The training tasks in ProgressLM-45K were sourced from distinct video collections and task definitions separate from the Progress-Bench evaluation set to avoid overlap in specific sequences and environments. In the revised manuscript, we will expand §3.2 with a new table enumerating training vs. evaluation task categories, object classes, action sequences, and environments, along with a brief justification of the curation process to confirm full disjointness. revision: yes
-
Referee: [§4] §4 (experiments) and associated tables/figures: The soundness assessment is limited by the absence of reported metrics such as error bars, ablation studies on the two-stage paradigm components, or dataset statistics (e.g., task distribution, sequence lengths) that would allow verification of whether the reported gains are robust or sensitive to post-hoc choices in data curation or evaluation.
Authors: We concur that these elements would enhance the assessment of robustness. The current results reflect single-run evaluations on the benchmark, but we have access to the underlying data for multiple seeds. In the revision, we will add error bars computed over 3 runs to the main tables in §4, include a dedicated ablation subsection on the two-stage paradigm components (e.g., removing the first or second stage), and report dataset statistics such as task distribution and average sequence lengths in §3 or the appendix. revision: yes
Circularity Check
No circularity: empirical training and evaluation on explicitly disjoint task sets
full rationale
The paper introduces Progress-Bench and trains ProgressLM-3B on ProgressLM-45K, asserting the task sets are fully disjoint, then reports empirical gains. No equations, fitted parameters, or self-citations are used to derive the central claim; results rest on experimental measurement rather than any reduction of outputs to inputs by construction. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ProgressLM-45K dataset supplies transferable signals for progress reasoning across disjoint task sets
Forward citations
Cited by 2 Pith papers
-
Robometer: Scaling General-Purpose Robotic Reward Models via Trajectory Comparisons
Robometer combines intra-trajectory progress supervision with inter-trajectory preference supervision on a 1M-trajectory dataset to learn more generalizable robotic reward functions than prior methods.
-
IndusAgent: Reinforcing Open-Vocabulary Industrial Anomaly Detection with Agentic Tools
IndusAgent achieves state-of-the-art zero-shot performance on industrial anomaly benchmarks by using a custom Indus-CoT dataset, dynamic tool orchestration, and gated RL to optimize anomaly classification, localizatio...
Reference graph
Works this paper leans on
-
[1]
Analyze the input state-to-estimate image and identify objects that could serve as plausible replacements
-
[2]
Replace the target object in both the task goal and all step-by-step instructions
-
[3]
Preserve the original sentence structure, action verbs, and spatial markers (e.g., [left], [right],[towards]) The model outputs the modified task goal and instructions in a structured XML format, as shown in Table 9. This approach ensures that the edited instructions remain grammatically coherent 18 Vision Same-View Vision Cross-View Text Vision Unanswera...
work page 2000
-
[4]
Object Replacement: Replacing the target object with a semantically different object (e.g., replacing an egg with an orange) 3.Occlusion/Removal: Hiding or removing key objects from the scene The model first reasons about which strategy would most effectively violate the instruction while maintaining visual realism, then outputs a concise editing prompt (...
-
[5]
<image> 0% <image> 25% <image> 50% <image> 75% <image> 100%
insert the battery...”), the model receives the current state image along with the ground-truth reference step (which text step most closely matches the current state) and progress score. The model generates reasoning in two phases: <ref_think> explains why the given reference step is most relevant to the current image, and <score_think> justifies how com...
work page 2025
-
[6]
serving as the generation engine with60%GPU memory utilization. 24 0% 14% 29% 43% 57% 71% 86% 100% State to Estimate <ref_think>The current state image shows a stack of plates being placed on the table, which is similar to the statein the No. 7 demo image where the plates are also being stacked. The robot arm is still in the process of placingthe plates, ...
-
[7]
move towards the plate
-
[8]
move the plate to the plate rack
-
[9]
position the plate vertically in the rack
-
[10]
release the plate Task Goal: placing a plate in a plate rack <ref_think> The current state image shows a plate being held above aplate rack, which aligns with the action described in Step 3 of thedemonstration: "lift the plate." The plate is not yet in the rack,indicating that the action of lifting is in progress or just completed. This step is the most r...
-
[11]
[right]pick up the bowl on the far right
-
[12]
[right]place the rightmost bowl on the table
-
[14]
[left]place the leftmost bowl on the first bowl
-
[15]
[left]pick up the bowl on the far left
-
[16]
[left]place the leftmost bowl on the second bowl Task Goal: place the bowls on the bowl holder onto the table, and stacked together <ref_think> The current image shows a stack ofcups on the floor, which is entirely different fromthe task goal of stacking plates on a plate holder.The objects in the image (cups) do not align with the objects mentioned in th...
-
[17]
Check the current state image carefully
-
[18]
Analyze the overall task goal and visual demonstration to understand how the task progresses from start to completion
-
[19]
Identify the reference states from the visual demonstration that are most related to the current state image
-
[20]
Compare the current state image with the chosen reference state, determining whether the image is behind or after the reference state
-
[21]
Estimate the progress numerically as a floating-point value between 0% and 100%
-
[22]
n/a"</ref> <score_think> Reason for comparing the current state image with the reference state or
If you really cannot match the current state image to any of the states from demon- stration, you need to explain the reason within ‘<ref_think></ref_think>‘ and output "n/a" within ‘<ref></ref>‘, ‘<score_think></score_think>‘, and ‘<score></score>‘. Your response must strictly follow this format: <ref_think> Reason for choosing the most related state fro...
-
[23]
Read the task goal to understand the task objective and the entity being operated on
-
[24]
Analyze the textual demonstration to understand how the task progresses from start to completion
-
[25]
Examine the current state image carefully. If the target is incorrect (different from the object metioned in task goal) or you really cannot match the current image to any step in the demonstration, you must explain the reason within<ref_think></ref_think> and output “n/a” within <ref></ref>, <score_think></score_think>, and <score></score>
-
[26]
If a match is possible, examine all steps in the textual demonstration, where each step represents an independent action. Identify the single step whose action is most closely related to the current state image. Then compare the current image with that reference step to determine whether it corresponds to an earlier or later stage, and finally estimate th...
-
[27]
Analyze the demonstration images to understand how the task visually progresses from start to completion
-
[28]
Identify the frame (or frames) from the demonstration that are visually most similar to the current state image
-
[29]
Compare the current state to that reference frame and determine whether it shows more or less progress
-
[30]
Finally, provide a numeric progress estimation between 0% and 100%, or both <ref> and <score>be “n/a” while encountering abnormal situation. Your response must strictly follow this format: <ref_think> Your reasoning for choosing the closest demonstration frame as the reference, OR explanation of why the situation is abnormal and no reference can be identi...
-
[31]
Analyze the text_demo to understand how the task visually and conceptually progresses from start to completion
-
[32]
Identify the step from the text_demo that are most visually and semantically similar to the current state image
-
[33]
Compare the current state image with the chosen reference step to determine whether it represents an earlier or later stage
-
[34]
Estimate the progress numerically as a floating-point value between 0% and 100%, or both <ref>and<score>be “n/a” while encontering abnormal situation. Your response must strictly follow this format: <ref_think> Your reasoning for choosing the most similar text_demo step as the reference, OR explanation of why the situation is abnormal and no reference can...
-
[35]
Color Change: Alter the color of critical objects (e.g., change a red apple to green)
-
[36]
Object Replacement: Replace the target object with a different object (e.g., replace an egg with an orange)
-
[37]
Occlusion/Removal: Hide or remove key objects from the scene Requirements:
-
[38]
The edited image should clearly violate the corresponding instruction
-
[39]
Maintain visual realism and coherence—the edited image must look natural and believable
-
[40]
Ensure the edit would cause the overall task goal to fail
-
[41]
The modification should be semantically meaningful (not just noise or blur). Output Format: <strategy_think> Analyze the current instruction and image content. Think step by step about which editing strategy would most effectively violate this instruction while maintaining realism. Consider the key objects involved and how modifying them would break the i...
-
[42]
Keep the original sentence format and structure - ONLY replace the object name
-
[43]
put your edited task goal here
For each step in Step-by-step Instructions, preserve ALL markers like [right], [left], [towards], etc. in their EXACT original positions. Output Format: <edited_goal>"put your edited task goal here"</edited_goal> <edited_demo> "text_demo": ["your edited step 1", "your edited step 2", "your edited step 3", ..., "your edited step n"] </edited_demo> Table 9:...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.