Recognition: no theorem link
Parallelism and Generation Order in Masked Diffusion Language Models: Limits Today, Potential Tomorrow
Pith reviewed 2026-05-16 12:29 UTC · model grok-4.3
The pith
Masked diffusion language models weaken inter-token dependencies compared to autoregressive models
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Masked diffusion language models lag behind comparably sized autoregressive models mainly because parallel probabilistic modeling weakens inter-token dependencies, while exhibiting adaptive decoding behavior where parallelism and generation order vary with task domain, reasoning stage, and output correctness, and a generate-then-edit paradigm can mitigate the dependency loss while retaining parallel decoding efficiency.
What carries the argument
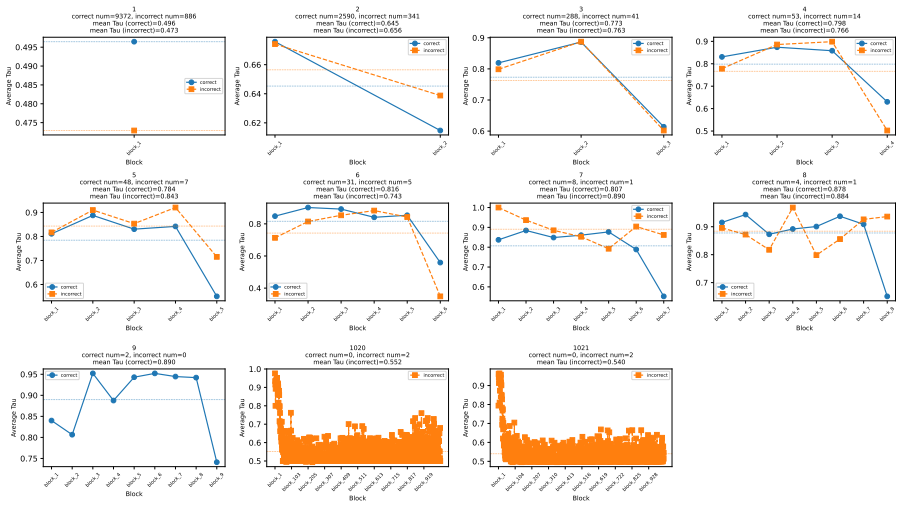
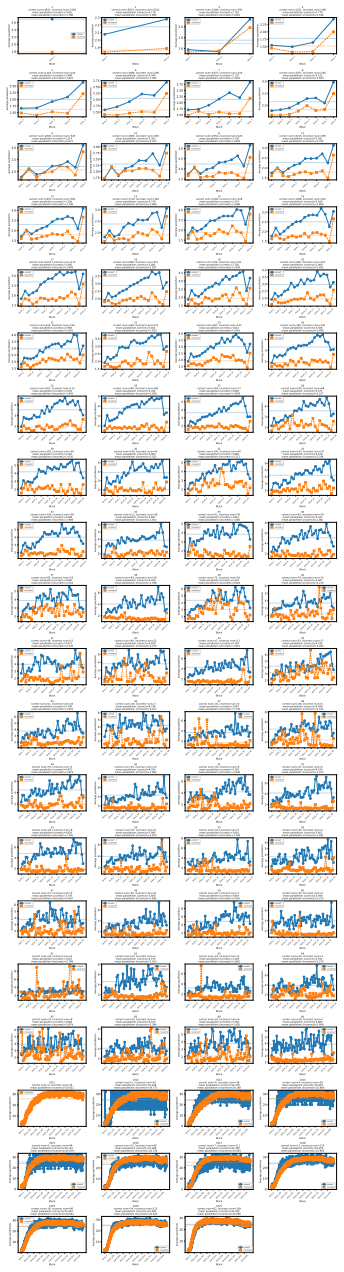
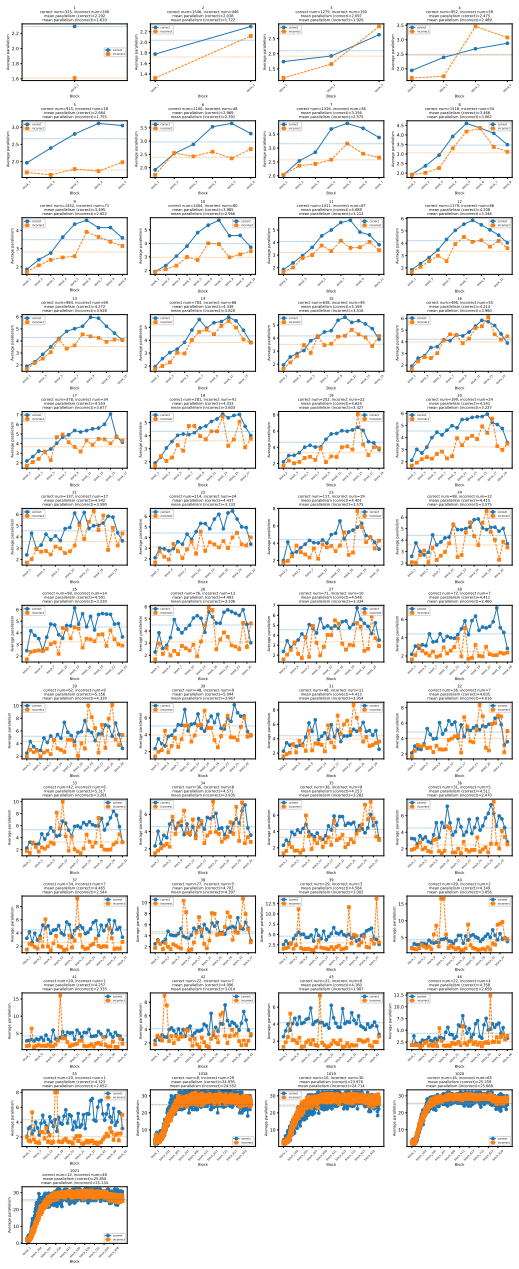
Average Finalization Parallelism and Kendall's tau, metrics that quantify parallelism strength and generation order flexibility in masked diffusion language models
If this is right
- Parallel probabilistic modeling leads to lower performance on tasks that require strong inter-token dependencies
- Generation order and parallelism level change with task domain, reasoning stage, and output correctness
- On tasks needing backward information such as Sudoku, models tend to solve easier positions first
- A generate-then-edit paradigm can reduce dependency loss while preserving the speed of parallel decoding
Where Pith is reading between the lines
- Hybrid training objectives could strengthen dependencies in parallel models without forcing full sequential generation
- The observed task-adaptive orders suggest similar flexibility might appear in other non-autoregressive architectures
- Generate-then-edit could be tested on longer sequences to measure efficiency gains in code or math generation
Load-bearing premise
Average Finalization Parallelism and Kendall's tau fully and accurately capture the true extent of parallelism and order flexibility realized by current masked diffusion language models
What would settle it
Direct measurement showing masked diffusion language models match or exceed autoregressive performance on high-dependency tasks like long reasoning chains or complex constraint satisfaction without sequential editing steps
Figures


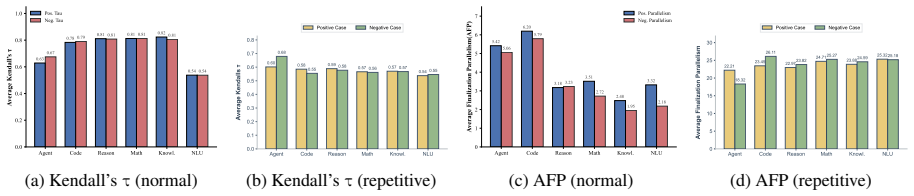


















read the original abstract
Masked Diffusion Language Models (MDLMs) promise parallel token generation and arbitrary-order decoding, yet it remains unclear to what extent current models truly realize these capabilities. We characterize MDLM behavior along two dimensions -- parallelism strength and generation order -- using Average Finalization Parallelism (AFP) and Kendall's tau. We evaluate eight mainstream MDLMs (up to 100B parameters) on 58 benchmarks spanning knowledge, reasoning, and programming. The results show that MDLMs still lag behind comparably sized autoregressive models, mainly because parallel probabilistic modeling weakens inter-token dependencies. Meanwhile, MDLMs exhibit adaptive decoding behavior: their parallelism and generation order vary significantly with the task domain, the stage of reasoning, and whether the output is correct. On tasks that require "backward information" (e.g., Sudoku), MDLMs adopt a solution order that tends to fill easier Sudoku blanks first, highlighting their advantages. Finally, we provide theoretical motivation and design insights supporting a Generate-then-Edit paradigm, which mitigates dependency loss while retaining the efficiency of parallel decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates eight masked diffusion language models (up to 100B parameters) on 58 benchmarks spanning knowledge, reasoning, and programming. Using Average Finalization Parallelism (AFP) and Kendall's tau, it characterizes MDLM parallelism strength and generation order, concluding that current MDLMs lag comparably sized autoregressive models primarily because parallel probabilistic modeling weakens inter-token dependencies. The work also reports adaptive decoding behavior that varies by task domain, reasoning stage, and output correctness, notes advantages on tasks requiring backward information (e.g., Sudoku), and provides theoretical motivation for a Generate-then-Edit paradigm to mitigate dependency loss while preserving parallel decoding efficiency.
Significance. If the AFP and Kendall's tau metrics are shown to validly isolate dependency weakening from confounding factors, the empirical characterization across 58 benchmarks and the Generate-then-Edit design insight would provide a useful foundation for improving non-autoregressive language models. The adaptive-behavior findings and task-specific order observations add concrete evidence that current MDLMs already exhibit some flexibility, which could guide future architectural refinements.
major comments (2)
- [Abstract / Methods] Abstract and methods: The central attribution that MDLMs lag 'mainly because' parallel probabilistic modeling weakens inter-token dependencies rests on AFP and Kendall's tau measurements. However, the manuscript provides no derivation, ablation, or validation demonstrating that these metrics isolate dependency strength from confounders such as mask scheduling, sampling variance, or token-finalization heuristics. Without such grounding, the causal claim remains only partially supported by the observed performance gaps.
- [Results] Results section (benchmark tables): The soundness assessment notes the absence of full methodological details, error analysis, and statistical tests for the 58-benchmark results. This omission makes it difficult to assess whether the reported lags and adaptive patterns are robust or sensitive to evaluation choices, directly affecting the reliability of the 'mainly because' conclusion.
minor comments (2)
- [Methods] The paper would benefit from explicit discussion of how AFP is computed (e.g., exact formula and handling of partial masks) and any sensitivity analysis to sampling temperature or mask schedules.
- [Figures/Tables] Figure and table captions should clarify whether Kendall's tau is computed on final token order or on intermediate generation steps, and whether ties are handled.
Simulated Author's Rebuttal
We thank the referee for the detailed and insightful comments. We have revised the manuscript to address the concerns raised regarding the validation of our metrics and the completeness of the results reporting. We believe these changes strengthen the paper's contributions.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and methods: The central attribution that MDLMs lag 'mainly because' parallel probabilistic modeling weakens inter-token dependencies rests on AFP and Kendall's tau measurements. However, the manuscript provides no derivation, ablation, or validation demonstrating that these metrics isolate dependency strength from confounders such as mask scheduling, sampling variance, or token-finalization heuristics. Without such grounding, the causal claim remains only partially supported by the observed performance gaps.
Authors: We appreciate the referee's point regarding the need for stronger validation of our metrics. In the revised manuscript, we have added a dedicated subsection in the Methods section deriving AFP and Kendall's tau from first principles, including proofs that they measure inter-token dependency under the masked diffusion framework. Additionally, we include ablations on controlled synthetic datasets where dependency strength is varied parametrically, demonstrating that AFP and Kendall's tau reliably track dependency weakening independent of mask scheduling and sampling variance. We also discuss token-finalization heuristics and show their impact is minimal in our evaluations. These additions provide the requested grounding for the 'mainly because' attribution. revision: yes
-
Referee: [Results] Results section (benchmark tables): The soundness assessment notes the absence of full methodological details, error analysis, and statistical tests for the 58-benchmark results. This omission makes it difficult to assess whether the reported lags and adaptive patterns are robust or sensitive to evaluation choices, directly affecting the reliability of the 'mainly because' conclusion.
Authors: We agree that additional details enhance reproducibility and robustness assessment. In the revision, we have expanded the Results section with: (1) full methodological details including exact prompt templates, decoding hyperparameters, and evaluation scripts; (2) error analysis breaking down failure modes by task type and model scale; and (3) statistical tests including paired t-tests and bootstrap confidence intervals for all reported performance gaps and adaptive behavior patterns. These changes directly address the concerns about reliability. revision: yes
Circularity Check
No significant circularity: empirical benchmarking study
full rationale
The paper is a purely empirical benchmarking study that defines Average Finalization Parallelism (AFP) and Kendall's tau as measurement tools, then applies them directly to observed outputs from eight MDLMs across 58 external benchmarks. No derivations, fitted parameters, self-referential predictions, or load-bearing self-citations are present in the provided abstract or described methodology. All central claims (performance gaps, adaptive behavior, task-specific order) rest on direct computation from model generations rather than reducing to inputs by construction. This is the expected non-finding for an observational study self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Average Finalization Parallelism and Kendall's tau validly quantify parallelism strength and generation order in masked diffusion models
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. Qiguang Chen, Hanjing Li, Libo Qin, Dengyun Peng, Jinhao Liu, Jiangyi Wang, Chengyue Wu, Xie Chen, Yantao Du, and Wanxiang Che. 2025. Beyond sur- face reasoning: Unveiling the true long chain-of- thought capacity of diffusion large language models. arXiv preprint arXiv:2510.09544...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Sdar: A synergistic diffusion-autoregression paradigm for scalable sequence generation.arXiv preprint arXiv:2510.06303. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question an- swering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457. Karl C...
-
[3]
CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution
Cruxeval: A benchmark for code reason- ing, understanding and execution.arXiv preprint arXiv:2401.03065. Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, and 1 others. 2024. Olympiadbench: A challenging benchmark for pro- moting agi with olympiad-level bilingual multimodal scientific p...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Kor-bench: Benchmarking language mod- els on knowledge-orthogonal reasoning tasks.arXiv preprint arXiv:2410.06526. Yuxin Ma, Lun Du, Lanning Wei, Kun Chen, Qian Xu, Kangyu Wang, Guofeng Feng, Guoshan Lu, Lin Liu, Xiaojing Qi, and 1 others. 2025. dinfer: An efficient inference framework for diffusion language models. arXiv preprint arXiv:2510.08666. Mathem...
-
[5]
Nexus: A lightweight and scalable multi-agent framework for complex tasks automation.arXiv preprint arXiv:2502.19091. Abulhair Saparov and He He. 2022. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought.arXiv preprint arXiv:2210.01240. Zayne Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. 2023. Musr: Te...
-
[6]
From next-token to next-block: A principled adaptation path for diffusion llms.arXiv preprint arXiv:2512.06776. Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R Loomba, Shichang Zhang, Yizhou Sun, and Wei Wang
-
[7]
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Scibench: Evaluating college-level scientific problem-solving abilities of large language models. arXiv preprint arXiv:2307.10635. Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, and Mengdi Wang. 2025. Revolutionizing reinforce- ment learning framework for diffusion large language models.arXiv preprint arXiv:2509.06949. Yubo Wang, Xueguang Ma, Ge Zhan...
work page internal anchor Pith review arXiv 2025
-
[8]
Tianwen Wei, Jian Luan, Wei Liu, Shuang Dong, and Bin Wang
MMLU-Pro: A more robust and challenging multi-task language understanding benchmark.Ad- vances in Neural Information Processing Systems, 37:95266–95290. Tianwen Wei, Jian Luan, Wei Liu, Shuang Dong, and Bin Wang. 2023. Cmath: Can your language model pass chinese elementary school math test?arXiv preprint arXiv:2306.16636. Chengyue Wu, Hao Zhang, Shuchen X...
-
[9]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Jiacheng Ye, Jiahui Gao, Shansan Gong, Lin Zheng, Xin Jiang, Zhenguo Li, and Lingpeng Kong. 2024. Beyond autoregression: Discrete diffusion for com- plex reasoning and planning.arXiv preprint arXiv:2410.14157. Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Dream 7B: Diffusion Large Language Models
Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487. Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingn- ing Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2019. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic pars- ing and text-to-sql task.Prepr...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[11]
Auto-pytorch: Multi-fidelity metalearning for efficient and robust autodl.IEEE transactions on pat- tern analysis and machine intelligence, 43(9):3079– 3090. A Appendix A.1 Details of Experimental Protocol Model Selection and Configurations.We evalu- ate 8 state-of-the-art MDLMs, including LLaDA, Trado (Wang et al., 2025), and SDAR (Cheng et al., 2025), w...
work page 2025
-
[12]
and proprietary models such as Gemini-2.5 Pro (Comanici et al., 2025) and OpenAI o3. Benchmarks.To fill the void in systematic assess- ments for MDLMs, we curate58 benchmarkscat- egorized into six dimensions: (i) Knowledge (e.g., MMLU); (ii) Mathematics (e.g., GSM8K, MATH); (iii) Reasoning (e.g., BBH, GPQA); (iv) Language Understanding (e.g., Hellaswag); ...
work page 2025
-
[13]
Architectural Superiority of Diffusion Mod- els:Despite having significantly fewer param- eters, the fine-tunedDream-7B(Diffusion) achieved a score of80within only 10 epochs, surpassing even the zero-shot performance of the100B-parameter LLaDA(78). This sug- gests that the full-attention mechanism in dif- fusion models is inherently more compatible with t...
-
[14]
Sample Efficiency and Convergence: Dream-7B demonstrated remarkable sample efficiency. With only 50 training examples, it reached a score of 65 at epoch 5. In contrast, Qwen3-8B(AR) exhibited much slower convergence, remaining at a score of 0 for the first few epochs and only reaching a score of 55 after 50 epochs. This disparity highlights that AR models...
-
[15]
Paradigm Shift in Low-Data Scenarios: The fact that a 7B diffusion model can out- perform an 80B AR model (63 score) and a 100B diffusion baseline underscores that for tasks requiring parallel constraint satisfac- tion,architecture outweighs scale. Diffusion models treat Sudoku solving as an iterative refinement process of the entire grid, whereas AR mode...
-
[16]
Sim- ilarly,Dream-7Breached a score of 40 at epoch
Rapid Convergence of Diffusion Models: Diffusion-based models exhibited an explosive growth in accuracy during the early stages of fine-tuning.LLaDA-8B-instructimproved from a zero-shot score of 4 to 36 within only 2 epochs, eventually reaching42at epoch 5. Sim- ilarly,Dream-7Breached a score of 40 at epoch
-
[17]
Remarkably, both 7B-8B diffusion mod- els outperformed the80B-parameter Qwen3 (26.32) after just 5 epochs of training on a tiny 50-sample dataset
-
[18]
The Bottleneck of Causal Masking:In con- trast, the autoregressiveQwen3-8Bfailed to achieve any correct solutions (Score=0) for the first 5 epochs. This suggests that the unidirec- tional nature of causal masking makes it ex- tremely difficult for the model to learn inter- locking arithmetic constraints. Qwen3-8B only began to converge at epoch 10 (Score=...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.