Recognition: 1 theorem link
· Lean TheoremGenerating Literature-Driven Scientific Theories at Scale
Pith reviewed 2026-05-16 11:35 UTC · model grok-4.3
The pith
Literature-grounded generation produces scientific theories that better match past evidence and predict future experimental results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
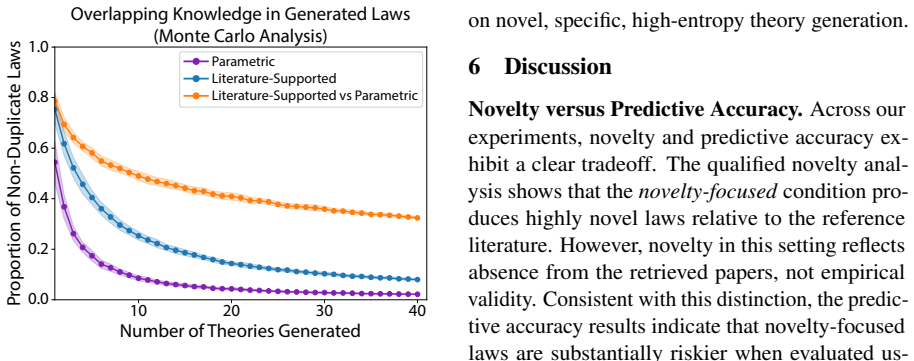
The central claim is that generating theories by grounding large language models in a corpus of 13.7k scientific papers yields 2.9k theories that significantly outperform parametrically generated ones in matching existing evidence and predicting results from 4.6k future papers. The study also varies generation objectives between accuracy focus and novelty focus to measure effects on theory properties.
What carries the argument
Literature-grounded theory synthesis, where models generate qualitative and quantitative laws by referencing specific source papers rather than relying solely on pre-trained parameters.
If this is right
- Literature-supported theories match existing evidence more closely than those from parametric knowledge.
- Such theories show stronger predictive power for results in subsequently published papers.
- Accuracy-focused generation objectives produce theories with greater evidential alignment.
- Novelty-focused objectives yield theories that explore less conventional connections.
- The method scales to synthesize thousands of theories from large literature corpora.
Where Pith is reading between the lines
- The approach could accelerate hypothesis formation in data-rich fields by surfacing candidate unifying laws from existing publications.
- If extended with simulation outputs or experimental metadata, the generated theories might directly inform new experiment design.
- Comparing generated theories against actual later publications could help flag under-explored areas in the scientific record.
- The framework raises the possibility of tracking how scientific consensus emerges across successive waves of papers.
Load-bearing premise
That the LLM-generated theories capture genuine scientific mechanisms rather than surface-level recombinations, and that the evaluation on future papers fairly measures predictive power without leakage or metric overfitting.
What would settle it
A direct test showing that literature-grounded theories perform no better than parametric ones when evaluated on a fresh set of future papers, or when domain experts rate the generated theories as no more predictive than plausible recombinations of known facts.
Figures


read the original abstract
Contemporary automated scientific discovery has focused on agents for generating scientific experiments, while systems that perform higher-level scientific activities such as theory building remain underexplored. In this work, we formulate the problem of synthesizing theories consisting of qualitative and quantitative laws from large corpora of scientific literature. We study theory generation at scale, using 13.7k source papers to synthesize 2.9k theories, examining how generation using literature-grounding versus parametric knowledge, and accuracy-focused versus novelty-focused generation objectives change theory properties. Our experiments show that, compared to using parametric LLM memory for generation, our literature-supported method creates theories that are significantly better at both matching existing evidence and at predicting future results from 4.6k subsequently-written papers
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates the problem of synthesizing qualitative and quantitative scientific theories from large literature corpora using LLMs. From 13.7k source papers it generates 2.9k theories, comparing literature-grounded generation against parametric-knowledge baselines and accuracy-focused versus novelty-focused objectives. The central empirical claim is that literature-supported theories are significantly better at matching existing evidence and at predicting results reported in 4.6k subsequently published papers.
Significance. If the predictive gains are shown to arise from the synthesized theories rather than model memorization, the work would constitute a concrete step toward scalable, literature-grounded theory generation—an area that remains underexplored relative to experiment-generation agents. The temporal split and scale of the corpus are positive features; however, the significance is currently limited by the absence of controls that isolate the contribution of the generated theory from the LLM’s pretraining exposure to the test papers.
major comments (2)
- [Evaluation on future papers (abstract and §4)] Evaluation on future papers (abstract and §4): the claim that literature-supported theories predict results in the 4.6k held-out papers better than parametric baselines is load-bearing for the central contribution, yet the manuscript provides no ablation that rules out contamination from the LLM’s pretraining corpus. Because the same underlying model is used for both generation and evaluation, superior scores on entailment, numerical agreement, or textual similarity could reflect retrieval of memorized content rather than independent logical content of the theory. A control that masks or removes the target papers from the model’s context (or uses a model known not to have seen them) is required.
- [Theory quality measurement (§3 and §4)] Theory quality measurement (§3 and §4): the abstract states directional improvements but supplies no concrete metrics, statistical tests, inter-annotator agreement figures, or rubric for “matching existing evidence.” Without these details it is impossible to determine whether the reported gains exceed what would be expected from surface-level recombination or from the model’s parametric knowledge alone.
minor comments (2)
- [Methods] Clarify the exact prompting templates and any post-processing steps used to extract qualitative versus quantitative laws; these details are necessary for reproducibility.
- [Terminology] Ensure consistent terminology between “literature-supported,” “literature-grounded,” and “literature-driven” throughout the text and figures.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects for improving the rigor of our evaluation. We agree that additional controls and clarifications will strengthen the manuscript and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Evaluation on future papers (abstract and §4)] Evaluation on future papers (abstract and §4): the claim that literature-supported theories predict results in the 4.6k held-out papers better than parametric baselines is load-bearing for the central contribution, yet the manuscript provides no ablation that rules out contamination from the LLM’s pretraining corpus. Because the same underlying model is used for both generation and evaluation, superior scores on entailment, numerical agreement, or textual similarity could reflect retrieval of memorized content rather than independent logical content of the theory. A control that masks or removes the target papers from the model’s context (or uses a model known not to have seen them) is required.
Authors: We acknowledge this concern regarding potential pretraining contamination. In the revised manuscript, we will add an ablation using an LLM with a training cutoff prior to the publication dates of the 4.6k held-out papers. This will isolate whether predictive gains derive from the synthesized theories or from memorized content, and we will report the results with discussion in an updated §4. revision: yes
-
Referee: [Theory quality measurement (§3 and §4)] Theory quality measurement (§3 and §4): the abstract states directional improvements but supplies no concrete metrics, statistical tests, inter-annotator agreement figures, or rubric for “matching existing evidence.” Without these details it is impossible to determine whether the reported gains exceed what would be expected from surface-level recombination or from the model’s parametric knowledge alone.
Authors: We will expand §3 and §4 (and update the abstract) to explicitly detail the metrics for matching existing evidence (entailment, numerical agreement, textual similarity), include statistical tests with p-values, report inter-annotator agreement where human evaluation was performed, and provide the full rubric used. These additions will clarify the evaluation procedure and support that gains exceed surface-level or parametric effects. revision: yes
Circularity Check
No significant circularity in claimed derivation or evaluation chain
full rationale
The paper's method generates theories from a fixed corpus of 13.7k source papers and evaluates them empirically on matching evidence plus prediction of results in a temporally later set of 4.6k papers. This temporal split supplies an external benchmark rather than deriving predictions from fitted parameters or self-referential definitions. No equations, ansatzes, or uniqueness theorems are invoked that reduce the central performance claim to the generation inputs by construction. Self-citations, if present, are not load-bearing for the reported superiority. The evaluation therefore remains self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can synthesize coherent qualitative and quantitative theories from scientific literature
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate the problem of synthesizing theories consisting of qualitative and quantitative laws from large corpora of scientific literature... using 13.7k source papers to synthesize 2.9k theories
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
COMET: Commonsense transformers for auto- matic knowledge graph construction. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4762–4779, Flo- rence, Italy. Association for Computational Linguis- tics. Zied Bouraoui, José Camacho-Collados, and S. Schock- aert. 2019. Inducing relational knowledge from bert. I...
work page 2019
-
[2]
Interpretable Machine Learning for Science with PySR and SymbolicRegression.jl
Combining data and theory for derivable sci- entific discovery with ai-descartes.Nature Commu- nications, 14. Miles Cranmer. 2023. Interpretable machine learn- ing for science with pysr and symbolicregression.jl. ArXiv, abs/2305.01582. John Dagdelen, Alex Dunn, Sanghoon Lee, Nicholas Walker, Andrew S. Rosen, G. Ceder, Kristin A. Pers- son, and Anubhav Jai...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Computational discovery of scientific knowl- edge. InComputational Discovery of Scientific Knowledge: Introduction, Techniques, and Appli- cations in Environmental and Life Sciences, pages 1–14. Kenneth D. Forbus. 1984. Qualitative process theory. Artif. Intell., 24:85–168. Kenneth D. Forbus. 2019.Qualitative Representations: How People Reason and Learn a...
-
[4]
A systematic review on literature-based dis- covery workflow.PeerJ Computer Science, 5. Alexander V . Tobias and Adam Wahab. 2025. Au- tonomous ‘self-driving’ laboratories: a review of technology and policy implications.Royal Society Open Science, 12. Rosni Vasu, Chandrayee Basu, Bhavana Dalvi Mishra, Cristina Sarasua, Peter Clark, and Abraham Bern- stein...
-
[5]
InAnnual Meeting of the Associa- tion for Computational Linguistics
Scimon: Scientific inspiration machines opti- mized for novelty. InAnnual Meeting of the Associa- tion for Computational Linguistics. Zonglin Yang, Li Dong, Xinya Du, Hao Cheng, Erik Cambria, Xiaodong Liu, Jianfeng Gao, and Furu Wei
-
[6]
Language models as inductive reasoners. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 209–225, St. Julian’s, Malta. Association for Computational Linguistics. 11 Meliha Yetisgen-Yildiz and Wanda Pratt. 2009. A new evaluation methodology for literature-based d...
work page 2009
-
[7]
Generated Theory: Table 5
-
[8]
Predictive Accuracy Evaluation: Table 6
-
[9]
Qualified Novelty Evaluation: Tables 7 and 8
-
[10]
Extraction Schema: Table 9
-
[11]
Models:The generation models are user-selectable in the THEORIZERuser interface and API
Extraction from Paper: Table 10 C Theory Generation Hyperparameters The theory generation procedure is described in Section 4, with full details including promtps in the code release. Models:The generation models are user-selectable in the THEORIZERuser interface and API. In the experiments reported here, the generation model was GPT-4.1, which is used fo...
work page 2024
-
[12]
For learners with social anxiety, increased agent interaction may not increase motivation. Supporting Evidence 1. SimClass multi-agent classroom ablation showed that removing classmate agents reduced user speech length by 26.5% (TAGI) and 45.2% (HSU), and reduced Community of Inquiry (CoI) social and cognitive presence scores; full multi-agent systems had...
-
[13]
SimClass FIAS coding showed high Student Initiation Ratios (SIR 0.9), indicating active participation in multi-agent settings. (UUIDs: e2892.0)
-
[14]
SRLAgent’s gamified, multi-agent orchestration (Planning Agent, SubTask Tutor, Reflection Agent) increased engagement and SRL skills compared to baseline multimedia learning. (UUIDs: e2717.0)
-
[15]
EnglishBot’s open conversational practice (simulated dialogue) led to greater engagement and learning gains than a listen-and- repeat interface. (UUIDs: e2760.3)
-
[16]
DBTS (Discussion-Based Teaching Systems) report 72% increase in engagement and 74% improvement in learning outcomes, attributed to dialogic, multi-agent interaction. (UUIDs: e2771.2) Self-Assessed Law Novelty(produced as part of theory generation; independent of later novelty evaluation) What Already Exists Social presence and collaborative learning are e...
work page 2000
-
[17]
Dillenbourg (1999) Collaborative learning: Cognitive and computational approaches [collaborative learning, not LLM multi-agent orchestration] Table 5:An example theory generated in this work, including the theory name, description, a single law, and a self-assessment of novelty made from the generation model. An example predictive accuracy evaluation for ...
work page 1999
-
[18]
Engagement or social presence metrics across different role configurations
-
[20]
Learning outcome measures (test scores, knowledge gains) in assessment contexts
-
[21]
Explicit categorization of tasks as individual/assessment vs collaborative Strong Test Require- ment A paper must compare multi-agent vs single-agent LLM-ITS effects on cognitive outcomes in an explicitly assessment-driven or individual task context, with clear outcome measures. What Does Support Look Like Multi-agent presence shows minimal or no signific...
-
[22]
Learning efficiency metrics: time to mastery, learning gains per minute, task completion rates
-
[23]
User confusion, cognitive load, or negative feedback related to agent interaction complexity Strong Test Require- ment A paper must compare different levels of agent complexity or orchestration quality in multi-agent LLM-ITS, measuring learning efficiency or related outcomes. What Does Support Look Like Overly complex or poorly orchestrated multi-agent sy...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.