Recognition: 3 theorem links
· Lean TheoremHigh-Rate Quantized Matrix Multiplication I
Pith reviewed 2026-05-16 11:16 UTC · model grok-4.3
The pith
High-rate quantization theory supplies the exact rate-distortion tradeoff for generic matrix multiplication without calibration data
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the generic MatMul setting without a priori statistical information about the factors, high-rate quantization theory gives the fundamental tradeoff between quantization rate and distortion; absmax INT and FP schemes achieve distortions strictly above this curve, with accurate heuristic approximations supplied for their performance.
What carries the argument
High-rate quantization theory, which asymptotically relates quantization rate to mean-squared distortion for high rates in the absence of side information.
If this is right
- Quantization performance in the generic weight-plus-activation case can be evaluated directly against the high-rate information-theoretic bound.
- Absmax INT and FP schemes leave a measurable gap to the theoretical optimum that cannot be closed without additional side information.
- Heuristic approximations for practical schemes enable quick prediction of distortion without full simulation.
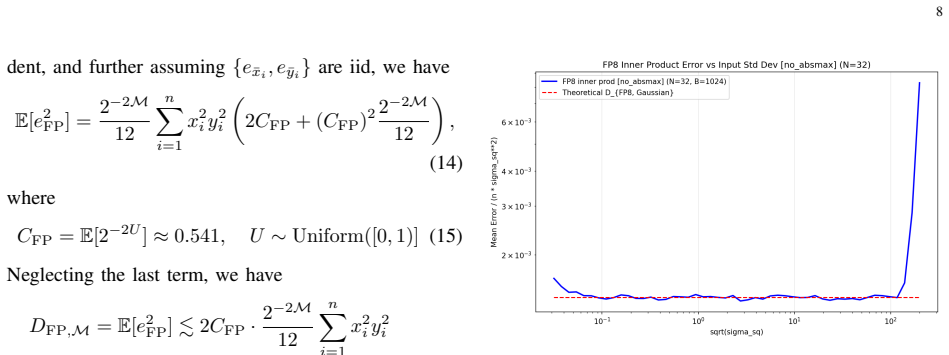
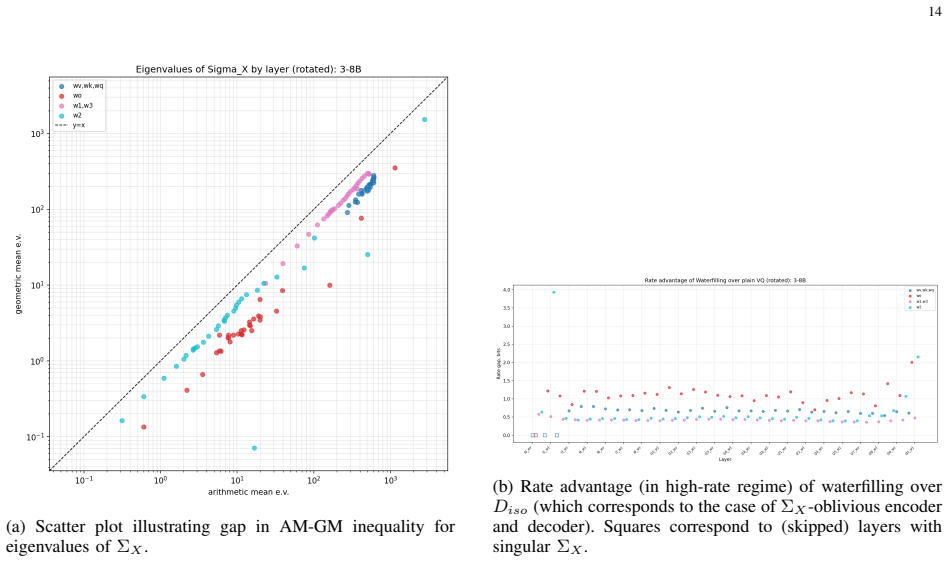
Where Pith is reading between the lines
- Closing the observed gap would require either increasing the bit rate or moving to the weight-only setting with second-order statistics as studied in part II.
- The heuristic formulas suggest floating-point formats may retain an advantage over integer schemes at intermediate rates even without calibration.
Load-bearing premise
The matrix factors behave in a manner that permits the high-rate asymptotic formulas to apply without requiring exact statistical distributions or calibration data.
What would settle it
Measure the empirical mean-squared error for random matrices quantized at rates of 4 to 8 bits per entry using absmax INT, then compare the observed distortion values to the high-rate theoretical bound.
Figures







read the original abstract
This paper investigates the problem of quantized matrix multiplication (MatMul), which has become crucial for the efficient deployment of large language models (LLMs). We consider a Generic MatMul setting, where both matrices must be quantized (weight+activation quantization) without specific apriori (calibration) statistical information about the factors. We review the fundamental information-theoretic tradeoff between quantization rate and distortion (high-rate theory), and contrast those with the performance of popular quantization schemes (absmax INT and floating-point (FP)), for which we also derive accurate heuristic approximations. Part II of this paper studies the weight-only quantization setup where second-order statistics of the activation matrices are available at the encoder.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reviews the information-theoretic high-rate rate-distortion tradeoff for quantized matrix multiplication in a generic setting without prior statistical information on the factors. It contrasts this theoretical limit with the performance of absmax INT and floating-point quantization schemes, for which heuristic approximations are derived.
Significance. If the heuristic approximations are rigorously justified and accurate, the work provides useful benchmarks for understanding quantization limits in LLMs under weight+activation quantization without calibration data, extending standard high-rate theory to a practical generic MatMul setting.
major comments (2)
- [§2] §2 (high-rate theory review): The application of standard high-rate approximations (Bennett integral or 6 dB/bit rule) requires a known source pdf satisfying regularity conditions, yet the generic MatMul setting explicitly disclaims any a priori statistics; the paper must specify the implicit distribution used for the theoretical tradeoff and the INT/FP contrasts.
- [§4] §4 (heuristic approximations): The abstract claims 'accurate heuristic approximations' for absmax INT and FP but provides no error bounds, validation against the assumed distribution, or derivation details; this is load-bearing for the central contrast with information-theoretic limits.
minor comments (2)
- [Introduction] Introduction: Clarify the distinction between the generic MatMul (no calibration) and the weight-only case deferred to Part II with explicit section references.
- [Notation] Notation: Define quantization rate R and mean-squared distortion D with explicit formulas before the high-rate review to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, clarifying the assumptions in our generic setting and committing to revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [§2] §2 (high-rate theory review): The application of standard high-rate approximations (Bennett integral or 6 dB/bit rule) requires a known source pdf satisfying regularity conditions, yet the generic MatMul setting explicitly disclaims any a priori statistics; the paper must specify the implicit distribution used for the theoretical tradeoff and the INT/FP contrasts.
Authors: We agree that standard high-rate approximations such as the Bennett integral presuppose a source pdf meeting regularity conditions (e.g., finite moments and smoothness). In the generic MatMul setting we deliberately avoid assuming a specific calibrated distribution to model the no-calibration scenario. The implicit assumption underlying the reviewed theoretical tradeoff is therefore any pdf satisfying those regularity conditions, with the rate-distortion expressions stated in integral form that can be instantiated for particular pdfs when needed. The INT and FP heuristic contrasts are derived from the absmax normalization, which depends only on the realized dynamic range rather than the pdf shape. We will revise §2 to state these conditions explicitly and note that the generic setting uses the general high-rate form without committing to one particular pdf. revision: yes
-
Referee: [§4] §4 (heuristic approximations): The abstract claims 'accurate heuristic approximations' for absmax INT and FP but provides no error bounds, validation against the assumed distribution, or derivation details; this is load-bearing for the central contrast with information-theoretic limits.
Authors: We acknowledge that the current manuscript presents the heuristic approximations in §4 without full derivation steps or explicit validation. The approximations follow from modeling the quantization error as additive noise whose variance scales with the squared absmax factor; the resulting closed-form distortion expressions are obtained by direct moment calculations under the normalization. We will add a detailed derivation appendix and include Monte-Carlo validation plots comparing the heuristics to exact distortion for representative entry distributions. Analytical error bounds that remain valid for arbitrary distributions are difficult to obtain without further assumptions, so we will instead strengthen the empirical evidence for accuracy in the revised version. revision: partial
Circularity Check
No significant circularity: derivation draws from standard high-rate information theory
full rationale
The paper reviews the established information-theoretic high-rate quantization tradeoff (standard Bennett integral and 6 dB/bit scaling) and contrasts it with absmax INT and FP schemes by deriving heuristic approximations. These steps rely on classical rate-distortion results external to the present work rather than any self-definition, fitted-parameter renaming, or load-bearing self-citation chain. The generic MatMul setting is analyzed under the high-rate regime without introducing equations that reduce to the paper's own inputs by construction. No quoted derivation step equates a claimed prediction to a fitted quantity or imports uniqueness solely from the authors' prior unverified results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-rate quantization theory governs the rate-distortion behavior of matrix multiplication under generic (no calibration) conditions
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We review the fundamental information-theoretic tradeoff between quantization rate and distortion (high-rate theory), and contrast those with the performance of popular quantization schemes (absmax INT and floating-point (FP)), for which we also derive accurate heuristic approximations.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
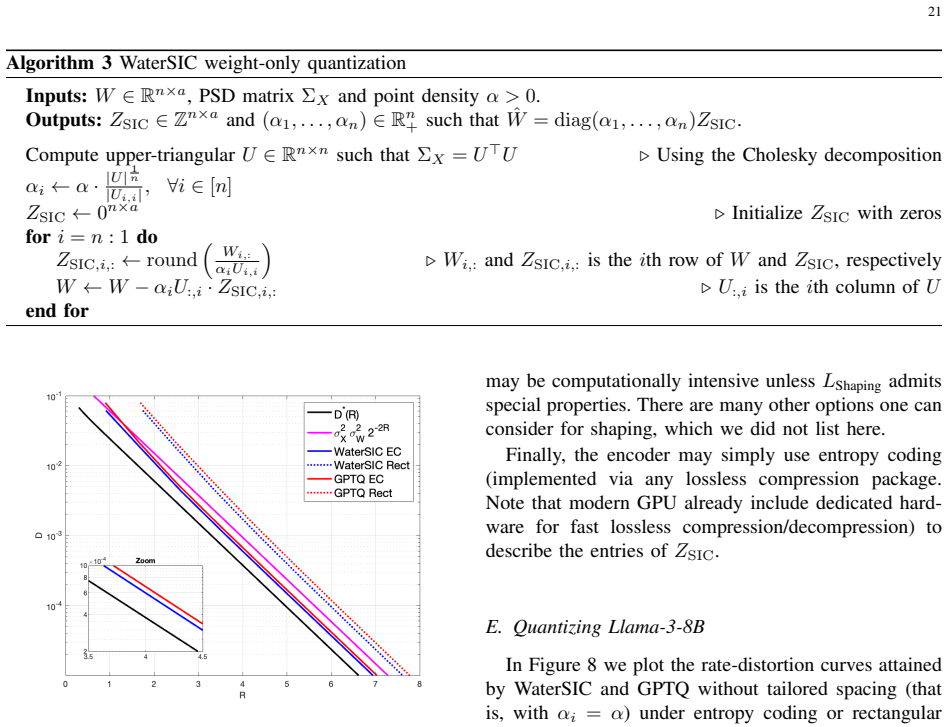
DWaterSIC(R)≈ 2πe/12 σ²_W (∏ U_{i,i}²)^{1/n} 2^{-2R}
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
high-rate assumption allows us to model quantization error as stochastic, independent uniform and additive
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Optimal quantization for matrix multiplication,
O. Ordentlich and Y . Polyanskiy, “Optimal quantization for matrix multiplication,”arXiv preprint arXiv:2410.13780, 2024. 24
-
[2]
OPTQ: Accurate quantization for generative pre-trained transformers,
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “OPTQ: Accurate quantization for generative pre-trained transformers,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https: //openreview.net/forum?id=tcbBPnfwxS
work page 2023
-
[3]
Quip: 2- bit quantization of large language models with guarantees,
J. Chee, Y . Cai, V . Kuleshov, and C. M. De Sa, “Quip: 2- bit quantization of large language models with guarantees,” Advances in Neural Information Processing Systems, vol. 36, pp. 4396–4429, 2023
work page 2023
-
[4]
NestQuant: Nested lattice quantization for matrix products and LLMs,
S. Savkin, E. Porat, O. Ordentlich, and Y . Polyanskiy, “NestQuant: Nested lattice quantization for matrix products and LLMs,”arXiv preprint arXiv:2502.09720, 2025
-
[5]
Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale,
T. Dettmers, M. Lewis, Y . Belkada, and L. Zettlemoyer, “Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale,” Advances in Neural Information Processing Systems, vol. 35, pp. 30 318–30 332, 2022
work page 2022
-
[6]
Optimal brain surgeon and general network pruning,
B. Hassibi, D. G. Stork, and G. J. Wolff, “Optimal brain surgeon and general network pruning,” inIEEE international conference on neural networks. IEEE, 1993, pp. 293–299
work page 1993
-
[7]
W. R. Bennett, “Spectra of quantized signals,”The Bell System Technical Journal, vol. 27, no. 3, pp. 446–472, 1948
work page 1948
-
[8]
R. M. Gray, “Quantization noise spectra,”IEEE Transactions on information theory, vol. 36, no. 6, pp. 1220–1244, 2002
work page 2002
-
[9]
R. Zamir,Lattice Coding for Signals and Networks: A Structured Coding Approach to Quantization, Modulation, and Multiuser Information Theory. Cambridge University Press, 2014
work page 2014
-
[10]
The space complexity of approximating the frequency moments,
N. Alon, Y . Matias, and M. Szegedy, “The space complexity of approximating the frequency moments,” inProceedings of the twenty-eighth annual ACM symposium on Theory of computing, 1996, pp. 20–29
work page 1996
-
[11]
Qjl: 1-bit quantized jl transform for kv cache quantization with zero overhead,
A. Zandieh, M. Daliri, and I. Han, “Qjl: 1-bit quantized jl transform for kv cache quantization with zero overhead,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 24, 2025, pp. 25 805–25 813
work page 2025
-
[12]
Turboquant: Online vector quantization with near-optimal distortion rate,
A. Zandieh, M. Daliri, M. Hadian, and V . Mirrokni, “Turboquant: Online vector quantization with near-optimal distortion rate,” arXiv preprint arXiv:2504.19874, 2025
-
[13]
Smoothquant: Accurate and efficient post-training quantization for large language models,
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “Smoothquant: Accurate and efficient post-training quantization for large language models,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 38 087–38 099
work page 2023
-
[14]
GPTQ: Code for accurate post-training quantization of generative pretrained transformers,
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Code for accurate post-training quantization of generative pretrained transformers,” https://github.com/IST-DASLab/gptq, 2022
work page 2022
-
[15]
Method, device and system of reduced peak-to-average-ratio communication,
M. Feder and A. Ingber, “Method, device and system of reduced peak-to-average-ratio communication,” Feb. 14 2012, uS Patent 8,116,695
work page 2012
-
[16]
Eden: Communication-efficient and robust distributed mean estimation for federated learning,
S. Vargaftik, R. B. Basat, A. Portnoy, G. Mendelson, Y . B. Itzhak, and M. Mitzenmacher, “Eden: Communication-efficient and robust distributed mean estimation for federated learning,” in International Conference on Machine Learning. PMLR, 2022, pp. 21 984–22 014
work page 2022
-
[17]
S. Ashkboos, A. Mohtashami, M. L. Croci, B. Li, M. Jaggi, D. Alistarh, T. Hoefler, and J. Hensman, “Quarot: Outlier-free 4- bit inference in rotated llms,”arXiv preprint arXiv:2404.00456, 2024
-
[18]
SpinQuant: LLM quantization with learned rotations
Z. Liu, C. Zhao, I. Fedorov, B. Soran, D. Choudhary, R. Kr- ishnamoorthi, V . Chandra, Y . Tian, and T. Blankevoort, “Spin- quant: Llm quantization with learned rotations,”arXiv preprint arXiv:2405.16406, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Fp4 all the way: Fully quantized training of llms,
B. Chmiel, M. Fishman, R. Banner, and D. Soudry, “Fp4 all the way: Fully quantized training of llms,”arXiv preprint arXiv:2505.19115, 2025
-
[20]
O. Regev and N. Stephens-Davidowitz, “A reverse minkowski theorem,”Annals of Mathematics, vol. 199, no. 1, 2024
work page 2024
-
[21]
Affirmative resolution of bourgain’s slicing problem using guan’s bound,
B. Klartag and J. Lehec, “Affirmative resolution of bourgain’s slicing problem using guan’s bound,”Geometric and Functional Analysis, pp. 1–22, 2025
work page 2025
-
[22]
Nestquant: Nested lattice quantization for matrix products and llms,
S. Savkin, E. Porat, O. Ordentlich, and Y . Polyanskiy, “Nestquant: Nested lattice quantization for matrix products and llms,”Proc. International Conference on Machine Learning (ICML), 2025
work page 2025
-
[23]
Fast quantizing and decoding and algorithms for lattice quantizers and codes,
J. Conway and N. Sloane, “Fast quantizing and decoding and algorithms for lattice quantizers and codes,”IEEE Transactions on Information Theory, vol. 28, no. 2, pp. 227–232, 1982
work page 1982
-
[24]
High-rate nested-lattice quantized matrix multiplication with small lookup tables,
I. Kaplan and O. Ordentlich, “High-rate nested-lattice quantized matrix multiplication with small lookup tables,” inProc. ISIT 2025, Ann Arbor, Michigan, June 2025
work page 2025
-
[25]
Wush: Near- optimal adaptive transforms for llm quantization,
J. Chen, V . Egiazarian, T. Hoefler, and D. Alistarh, “Wush: Near- optimal adaptive transforms for llm quantization,”arXiv preprint arXiv:2512.00956, 2025
-
[26]
Block rotation is all you need for mxfp4 quantization,
Y . Shao, P. Wang, Y . Chen, C. Xu, Z. Wei, and J. Cheng, “Block rotation is all you need for mxfp4 quantization,”arXiv preprint arXiv:2511.04214, 2025
-
[27]
Model-preserving adaptive rounding,
A. Tseng, Z. Sun, and C. De Sa, “Model-preserving adaptive rounding,”arXiv preprint arXiv:2505.22988, 2025
-
[28]
Half-quadratic quantization of large machine learning models,
H. Badri and A. Shaji, “Half-quadratic quantization of large machine learning models,” November 2023. [Online]. Available: https://mobiusml.github.io/hqq_blog/
work page 2023
-
[29]
Qronos: Correcting the past by shaping the future... in post-training quantization,
S. Zhang, H. Zhang, I. Colbert, and R. Saab, “Qronos: Correcting the past by shaping the future... in post-training quantization,” arXiv preprint arXiv:2505.11695, 2025
-
[30]
Provable Post-Training Quantization: Theoretical Analysis of OPTQ and Qronos
H. Zhang, S. Zhang, I. Colbert, and R. Saab, “Provable post- training quantization: Theoretical analysis of optq and qronos,” arXiv preprint arXiv:2508.04853, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Y . Polyanskiy and Y . Wu,Information theory: From coding to learning. Cambridge university press, 2024
work page 2024
-
[32]
A. Harbuzova, O. Ordentlich, and Y . Polyanskiy, “(work in progress),”arXiv, 2026
work page 2026
-
[33]
The Geometry of LLM Quantization: GPTQ as Babai's Nearest Plane Algorithm
J. Chen, Y . Shabanzadeh, E. Crnˇcevi´c, T. Hoefler, and D. Alistarh, “The geometry of llm quantization: Gptq as babai’s nearest plane algorithm,”arXiv preprint arXiv:2507.18553, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
J. Birnick, “The lattice geometry of neural network quantization– a short equivalence proof of gptq and babai’s algorithm,”arXiv preprint arXiv:2508.01077, 2025
-
[35]
Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks,
A. Tseng, J. Chee, Q. Sun, V . Kuleshov, and C. De Sa, “Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks,”arXiv preprint arXiv:2402.04396, 2024
-
[36]
Bounds on the density of smooth lattice coverings,
O. Ordentlich, O. Regev, and B. Weiss, “Bounds on the density of smooth lattice coverings,”arXiv preprint arXiv:2311.04644, 2023
-
[37]
Quantization distortion in pulse-count modulation with nonuniform spacing of levels,
P. Panter and W. Dite, “Quantization distortion in pulse-count modulation with nonuniform spacing of levels,”Proceedings of the IRE, vol. 39, no. 1, pp. 44–48, 1951
work page 1951
-
[38]
Asymptotic quantization error of continuous signals and the quantization dimension,
P. Zador, “Asymptotic quantization error of continuous signals and the quantization dimension,”IEEE Transactions on Informa- tion Theory, vol. 28, no. 2, pp. 139–149, 1982
work page 1982
-
[39]
Asymptotically optimal block quantization,
A. Gersho, “Asymptotically optimal block quantization,”IEEE Transactions on information theory, vol. 25, no. 4, pp. 373–380, 1979
work page 1979
-
[40]
M. V . Eyuboglu and G. D. Forney, “Lattice and trellis quantiza- tion with lattice-and trellis-bounded codebooks-high-rate theory for memoryless sources,”IEEE Transactions on Information theory, vol. 39, no. 1, pp. 46–59, 1993
work page 1993
-
[41]
On lattice quantization noise,
R. Zamir and M. Feder, “On lattice quantization noise,”IEEE Transactions on Information Theory, vol. 42, no. 4, pp. 1152– 1159, 1996
work page 1996
-
[42]
J. H. Conway and N. J. A. Sloane,Sphere Packings, Lattices and Groups, 3rd ed., ser. Grundlehren der mathematischen Wis- senschaften. New York: Springer-Verlag, 1999, vol. 290
work page 1999
-
[43]
The Voronoi spherical cdf for lattices and linear codes: New bounds for quantization and coding,
O. Ordentlich, “The Voronoi spherical cdf for lattices and linear codes: New bounds for quantization and coding,”arXiv preprint arXiv:2506.19791, 2025
-
[44]
P. W. Wolniansky, G. J. Foschini, G. D. Golden, and R. A. Valenzuela, “V-blast: An architecture for realizing very high data rates over the rich-scattering wireless channel,” in1998 URSI international symposium on signals, systems, and electronics. Conference proceedings (Cat. No. 98EX167). IEEE, 1998, pp. 295–300
work page 1998
-
[45]
On lovász’lattice reduction and the nearest lattice point problem,
L. Babai, “On lovász’lattice reduction and the nearest lattice point problem,”Combinatorica, vol. 6, no. 1, pp. 1–13, 1986. 25
work page 1986
-
[46]
U. Fincke and M. Pohst, “Improved methods for calculating vectors of short length in a lattice, including a complexity analysis,”Mathematics of computation, vol. 44, no. 170, pp. 463– 471, 1985
work page 1985
-
[47]
Closest point search in lattices,
E. Agrell, T. Eriksson, A. Vardy, and K. Zeger, “Closest point search in lattices,”IEEE transactions on information theory, vol. 48, no. 8, pp. 2201–2214, 2002
work page 2002
-
[48]
G. D. Forney, “Trellis shaping,”IEEE Transactions on Informa- tion Theory, vol. 38, no. 2, pp. 281–300, 1992
work page 1992
-
[49]
Privileged bases in the transformer residual stream,
N. Elhage, R. Lasenby, and C. Olah, “Privileged bases in the transformer residual stream,”Transformer Circuits Thread,
-
[50]
Available: https://transformer-circuits.pub/2023/ privileged-basis/index.html
[Online]. Available: https://transformer-circuits.pub/2023/ privileged-basis/index.html
work page 2023
-
[51]
On the best lattice quantizers,
E. Agrell and B. Allen, “On the best lattice quantizers,”IEEE Transactions on Information Theory, vol. 69, no. 12, pp. 7650– 7658, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.