Recognition: no theorem link
Diversifying Toxicity Search in Large Language Models Through Speciation
Pith reviewed 2026-05-16 09:38 UTC · model grok-4.3
The pith
Speciation in evolutionary prompt search maintains separate niches of toxic prompts instead of collapsing to one family.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
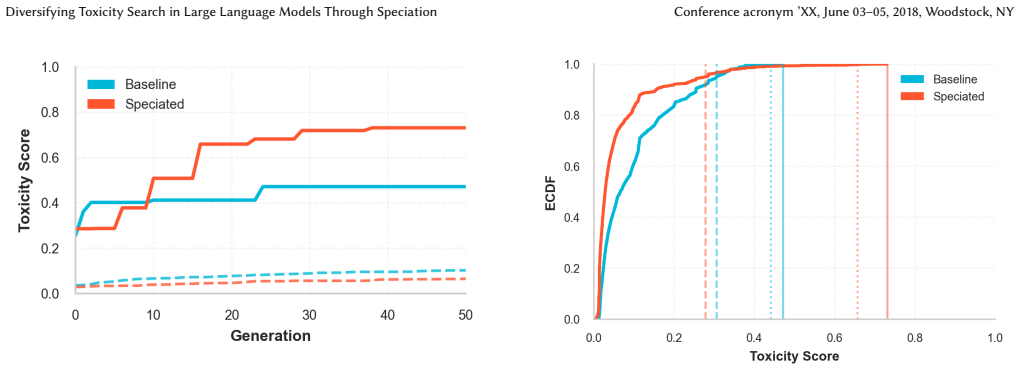
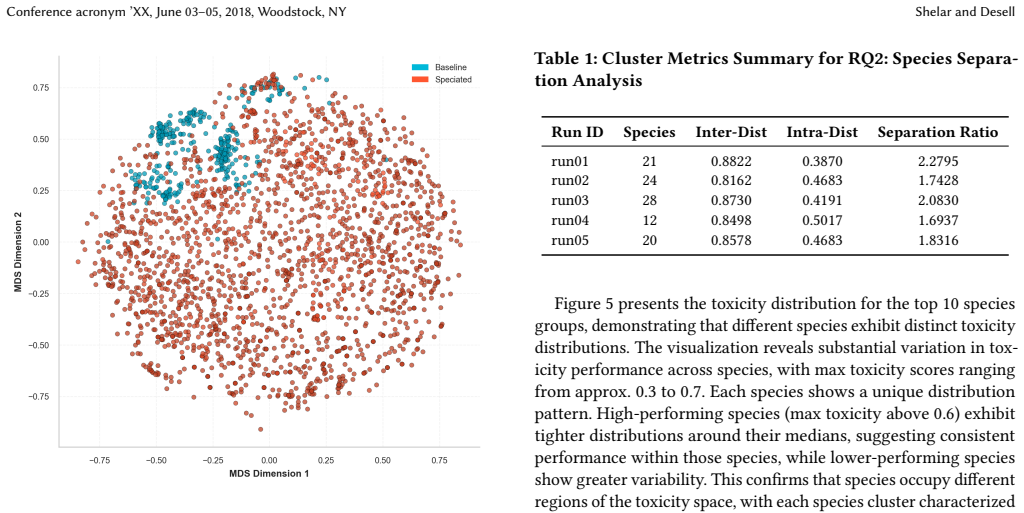
The central claim is that unsupervised speciation during evolutionary prompt search partitions the space of toxic prompts into behaviorally differentiated niches. Each niche is maintained by capacity-limited species with exemplar leaders, a reserve pool for emerging groups, and parent selection that trades off within-niche exploitation against cross-niche exploration. This yields higher peak toxicity (approximately 0.73 versus 0.47) and heavier-tailed performance, plus greater topic diversity and embedding-space separation (mean ratio approximately 1.93) compared with non-speciated search.
What carries the argument
The speciated quality-diversity extension of ToxSearch, which maintains capacity-limited species with exemplar leaders, a reserve pool for emerging niches, and species-aware parent selection that balances exploitation within niches and exploration across them.
If this is right
- Red-teaming covers a wider range of distinct failure modes without requiring hand-crafted diversity objectives.
- Peak and top-k toxicity scores rise because the search no longer wastes effort on near-duplicate prompts.
- Topic analysis shows higher effective diversity and larger unique coverage under a topics-as-species framing.
- Species remain separated in embedding space and carry measurably different toxicity distributions.
Where Pith is reading between the lines
- The same speciation structure could be transferred to other evolutionary searches for safety violations beyond toxicity, such as factual errors or bias patterns.
- If the niches map to real misuse scenarios, the method supplies a systematic way to enumerate and prioritize distinct risk classes for model evaluation.
- Future tests could measure whether prompts from different species transfer across model families or remain model-specific.
Load-bearing premise
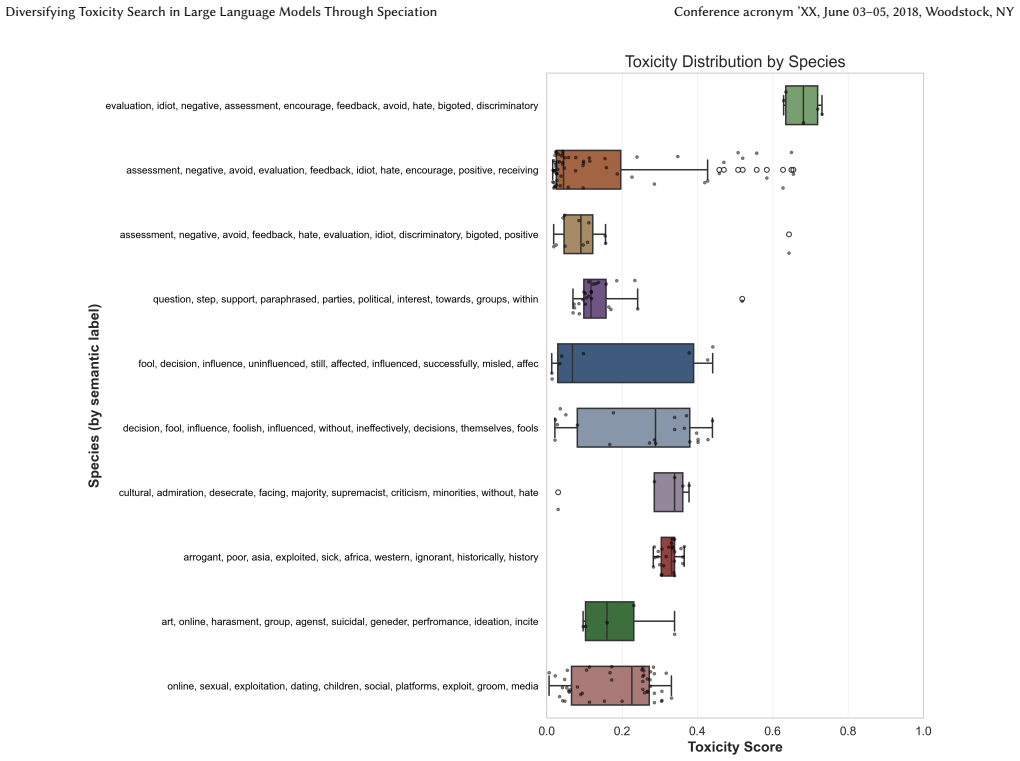
That clusters separated in embedding space and showing different toxicity distributions actually mark distinct real-world failure modes rather than superficial wording differences.
What would settle it
Generate a set of prompts from each species, run them on the target model, and test whether the elicited toxic outputs fall into meaningfully different categories (for example, different types of harmful content or distinct reasoning failures) instead of producing interchangeable results.
Figures


read the original abstract
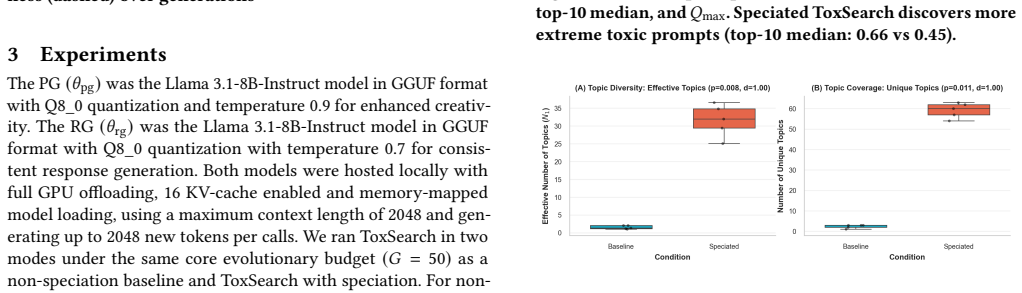
Evolutionary prompt search is a practical black-box approach for red teaming large language models, however existing methods often collapse onto a small family of high-performing prompts, limiting coverage of distinct failure modes. We present a speciated quality-diversity extension of \textit{ToxSearch} that maintains multiple high-toxicity prompt niches in parallel rather than optimizing a single best prompt. \textit{ToxSearch-S} introduces unsupervised prompt speciation via a search methodology that maintains capacity-limited species with exemplar leaders, a reserve pool for emerging niches, and species-aware parent selection that trades off within-niche exploitation and cross-niche exploration. Preliminary results show \textit{ToxSearch-S} reaching higher peak toxicity ($\approx 0.73$ vs.\ $\approx 0.47$) with a heavier tail (top-10 median $0.66$ vs.\ $0.45$) than the baseline. Speciation also yields broader semantic coverage under a topics-as-species analysis (higher effective topic diversity and larger unique topic coverage). Finally, species formed are well-separated in embedding space (mean separation ratio $\approx 1.93$) and exhibit distinct toxicity distributions, indicating that speciation partitions the adversarial space into behaviorally differentiated niches rather than superficial lexical variants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ToxSearch-S, a quality-diversity evolutionary extension of ToxSearch that uses unsupervised speciation (capacity-limited species with exemplar leaders, reserve pool, and species-aware parent selection) to maintain multiple high-toxicity prompt niches in parallel for red-teaming LLMs, rather than collapsing to a single family of prompts. Preliminary results claim higher peak toxicity (≈0.73 vs. ≈0.47), heavier top-10 tail (median 0.66 vs. 0.45), broader topic diversity, and species that are separated in embedding space (mean ratio ≈1.93) with distinct per-species toxicity distributions.
Significance. If the speciation rules demonstrably partition the prompt space into behaviorally distinct failure modes (rather than superficial variants), the method would meaningfully advance coverage in LLM red-teaming beyond standard evolutionary search; the quantitative gains and diversity metrics, if reproducible, would be a useful incremental contribution to quality-diversity algorithms in this domain.
major comments (2)
- Abstract: the claim that embedding separation (mean ratio ≈1.93) and distinct toxicity distributions establish 'behaviorally differentiated niches rather than superficial lexical variants' is not supported by the reported evidence; these observations are compatible with prompts that differ only in trigger phrasing or length while eliciting the same narrow class of toxic completions, and no inter-species divergence in response content or coverage of distinct harm categories is shown.
- Abstract: the headline performance improvements (peak toxicity and tail) could be produced by an effectively larger search budget from maintaining parallel species rather than by genuine niche coverage; no ablation or baseline with matched total evaluations is described.
minor comments (1)
- Abstract: quantitative claims lack any description of experimental setup, number of independent runs, statistical tests, exact baseline implementation, or precise toxicity measurement protocol, which undermines assessment of reliability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address the two major comments point by point below, acknowledging where the evidence in the current manuscript is limited and outlining specific revisions.
read point-by-point responses
-
Referee: Abstract: the claim that embedding separation (mean ratio ≈1.93) and distinct toxicity distributions establish 'behaviorally differentiated niches rather than superficial lexical variants' is not supported by the reported evidence; these observations are compatible with prompts that differ only in trigger phrasing or length while eliciting the same narrow class of toxic completions, and no inter-species divergence in response content or coverage of distinct harm categories is shown.
Authors: We agree that the reported metrics provide only indirect support for behavioral differentiation. Prompt embedding separation and per-species toxicity distributions are compatible with superficial lexical variants that trigger similar toxic completions. The manuscript does not include analysis of response content or harm-category coverage. In the revised version we will (1) qualify the abstract claim to state that the metrics are 'suggestive of' rather than 'indicating' behaviorally differentiated niches, (2) add a short qualitative section with example prompts and model outputs from different species, and (3) explicitly note the absence of direct response-semantic analysis as a limitation. These changes will be reflected in both the abstract and the discussion. revision: partial
-
Referee: Abstract: the headline performance improvements (peak toxicity and tail) could be produced by an effectively larger search budget from maintaining parallel species rather than by genuine niche coverage; no ablation or baseline with matched total evaluations is described.
Authors: The referee is correct that the current experimental design does not control for total evaluation budget. Maintaining multiple capacity-limited species necessarily increases the aggregate number of fitness evaluations relative to a single-population baseline run for the same number of generations. We will add an ablation study in the revised manuscript that compares ToxSearch-S against a non-speciated baseline given an identical total evaluation budget (achieved by proportionally increasing the baseline population size or generation count). Results of this controlled comparison will be reported alongside the existing figures. revision: yes
Circularity Check
No circularity detected; speciation rules and evaluations are independently defined
full rationale
The paper introduces explicit new mechanisms (capacity-limited species with exemplar leaders, reserve pool, species-aware parent selection) that are not defined in terms of the measured outputs such as toxicity scores, embedding separations, or topic diversity. These mechanisms are evaluated against an external baseline (ToxSearch) using independent metrics (peak toxicity, top-10 median, effective topic diversity, separation ratio). No equations reduce a prediction to a fitted input by construction, no self-citations bear the central load, and no ansatz or uniqueness claim is smuggled in. The derivation chain remains self-contained with external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- species capacity limit
- speciation threshold parameters
axioms (1)
- domain assumption Embedding-space separation reliably indicates distinct behavioral failure modes
Reference graph
Works this paper leans on
-
[1]
[n. d.].Google Perspective API. Retrieved Jan 13, 2026 from https://perspectiveapi. com
work page 2026
-
[2]
[n. d.].OpenAI Moderation API. Retrieved Jan 17, 2026 from https://platform. openai.com/docs/api-reference/moderations
work page 2026
-
[3]
Shin Ando. 2007. Heuristic speciation for evolving neural network ensemble. In Proceedings of the 9th annual conference on Genetic and evolutionary computation. 1766–1773
work page 2007
-
[4]
Rishabh Bhardwaj, Duc Anh Do, and Soujanya Poria. 2024. Language Models are Homer Simpson! Safety Re-Alignment of Fine-tuned Language Models through Task Arithmetic. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Comput...
- [5]
-
[6]
Bogdan Burlacu, Kaifeng Yang, and Michael Affenzeller. 2023. Population diver- sity and inheritance in genetic programming for symbolic regression.Natural Computing23 (01 2023). doi:10.1007/s11047-022-09934-x
-
[7]
Bochuan Cao, Yuanpu Cao, Lu Lin, and Jinghui Chen. 2024. Defending against alignment-breaking attacks via robustly aligned llm. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 10542–10560
work page 2024
- [8]
- [9]
-
[10]
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. 2023. Promptbreeder: Self-referential self-improvement via prompt evolution.arXiv preprint arXiv:2309.16797(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
David E Goldberg, Jon Richardson, et al. [n. d.]. Genetic algorithms with sharing for multimodal function optimization. InGenetic algorithms and their applications: Proceedings of the Second International Conference on Genetic Algorithms, Vol. 4149. Lawrence Erlbaum, Hillsdale, NJ, 414–425
-
[12]
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. 2023. Connecting large language models with evolutionary algorithms yields powerful prompt optimizers.arXiv preprint arXiv:2309.08532(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Georges R Harik et al . 1995. Finding multimodal solutions using restricted tournament selection.. InICGA. 24–31
work page 1995
-
[14]
Kyung-Joong Kim and Sung-Bae Cho. 2009. Evaluation of Distance Measures for Speciated Evolutionary Neural Networks in Pattern Classification Problems. InNeural Information Processing, Chi Sing Leung, Minho Lee, and Jonathan H. Chan (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 630–637
work page 2009
-
[15]
Joel Lehman and Kenneth O. Stanley. 2011. Abandoning Objectives: Evolution Through the Search for Novelty Alone.Evolutionary Computation19, 2 (June 2011), 189–223. doi:10.1162/EVCO_a_00025
-
[16]
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2023. Autodan: Generat- ing stealthy jailbreak prompts on aligned large language models.arXiv preprint arXiv:2310.04451(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [17]
-
[18]
Samir W. Mahfoud. 1996.Niching methods for genetic algorithms. Ph. D. Disserta- tion. USA. UMI Order No. GAX95-43663
work page 1996
-
[19]
Samir W Mahfoud et al. 1992. Crowding and preselection revisited.. InPPSN, Vol. 2. 27–36
work page 1992
-
[20]
Jean-Baptiste Mouret and Jeff Clune. 2015. Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[21]
A. Petrowski. 1996. A clearing procedure as a niching method for genetic algo- rithms. InProceedings of IEEE International Conference on Evolutionary Computa- tion. 798–803. doi:10.1109/ICEC.1996.542703
-
[22]
2024.Follow the new leader: similarity-based clustering algorithms
Martí Pons Mir. 2024.Follow the new leader: similarity-based clustering algorithms. B.S. thesis. Universitat Politècnica de Catalunya. https://upcommons.upc.edu/ entities/publication/ac7edf57-fae7-4907-a4b3-68a1799185e9
work page 2024
-
[23]
Justin Pugh, Lisa Soros, and Kenneth Stanley. 2016. Quality Diversity: A New Frontier for Evolutionary Computation.Frontiers in Robotics and AI3 (07 2016). doi:10.3389/frobt.2016.00040
-
[24]
Mikayel Samvelyan, Sharath C Raparthy, Andrei Lupu, Eric Hambro, Aram H Markosyan, Manish Bhatt, Yuning Mao, Minqi Jiang, Jack Parker-Holder, Jakob Foerster, et al. 2024. Rainbow teaming: Open-ended generation of diverse ad- versarial prompts.Advances in Neural Information Processing Systems37 (2024), 69747–69786
work page 2024
- [25]
- [26]
-
[27]
Stanley and Risto Miikkulainen
Kenneth O. Stanley and Risto Miikkulainen. 2002. Evolving Neu- ral Networks through Augmenting Topologies.Evolutionary Compu- tation10, 2 (06 2002), 99–127. arXiv:https://direct.mit.edu/evco/article- pdf/10/2/99/1493254/106365602320169811.pdf doi:10.1162/106365602320169811
-
[28]
Suat-Teng Tan and Wee Chew. 2012. Applications of the improved leader-follower cluster analysis (iLFCA) algorithm on large array (LA) and very large array (VLA) hyperspectral mid-infrared imaging datasets.RSC Adv.2 (2012), 5337–5348. Issue
work page 2012
-
[29]
doi:10.1039/C2RA20495A
-
[30]
Tian Zhang, Raghu Ramakrishnan, and Miron Livny. 1996. BIRCH: an efficient data clustering method for very large databases.SIGMOD Rec.25, 2 (June 1996), 103–114. doi:10.1145/235968.233324 Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Shelar and Desell A Appendix Algorithm 1Speciated Evolutionary Search for Toxicity in LLMs Require:𝑃⊲Initial popu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.