Recognition: 2 theorem links
· Lean TheoremBEAR: Towards Beam-Search-Aware Optimization for Recommendation with Large Language Models
Pith reviewed 2026-05-16 09:22 UTC · model grok-4.3
The pith
BEAR adds a regularization term to LLM fine-tuning that keeps every token of a positive item inside the top-B candidates at each decoding step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
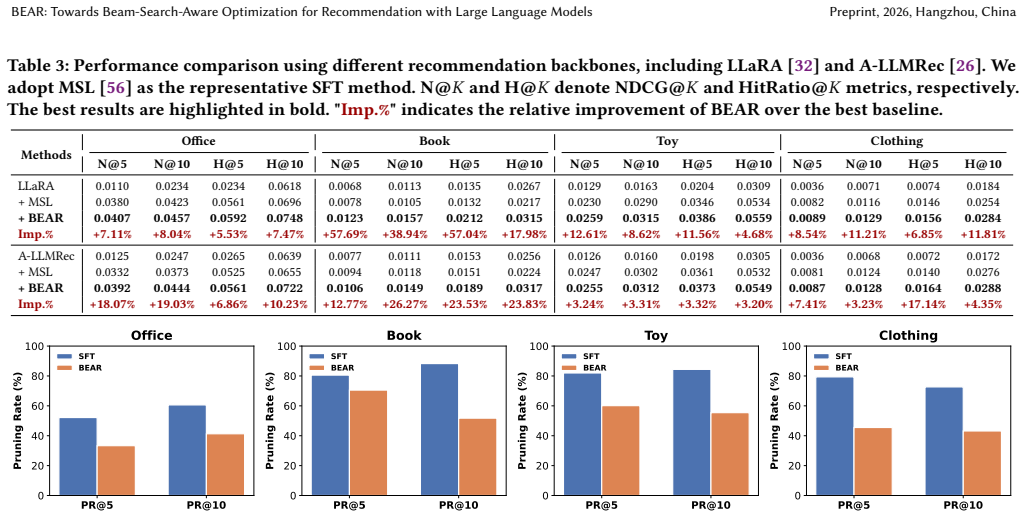
BEAR enforces a relaxed necessary condition: each token in a positive item must rank within the top-B candidate tokens at each decoding step. This objective mitigates the risk of incorrect pruning while adding negligible computational overhead compared with standard supervised fine-tuning.
What carries the argument
A beam-search-aware regularization term added to the supervised fine-tuning loss that penalizes any step where a positive-item token falls outside the top-B candidates.
Load-bearing premise
Keeping positive-item tokens inside the top-B at every training step is sufficient to stop them from being pruned by beam search at inference and does not degrade other ranking metrics.
What would settle it
Run inference beam search on held-out positive items and count how many that satisfied the top-B token condition during BEAR training are still discarded, then compare that count with the same items under plain supervised fine-tuning.
Figures




read the original abstract
Recent years have seen a rapid surge in research leveraging Large Language Models (LLMs) for recommendation. These methods typically employ supervised fine-tuning (SFT) to adapt LLMs to recommendation scenarios, and utilize beam search during inference to efficiently retrieve $B$ top-ranked recommended items. However, we identify a critical training-inference inconsistency: while SFT optimizes the overall probability of positive items, it does not guarantee that such items will be retrieved by beam search even if they possess high overall probabilities. Due to the greedy pruning mechanism, beam search can prematurely discard a positive item once its prefix probability is insufficient. To address this inconsistency, we propose BEAR (Beam-SEarch-Aware Regularization), a novel fine-tuning objective that explicitly accounts for beam search behavior during training. Rather than directly simulating beam search for each instance during training, which is computationally prohibitive, BEAR enforces a relaxed necessary condition: each token in a positive item must rank within the top-$B$ candidate tokens at each decoding step. This objective effectively mitigates the risk of incorrect pruning while incurring negligible computational overhead compared to standard SFT. Extensive experiments across four real-world datasets demonstrate that BEAR significantly outperforms strong baselines. Code is available at https://github.com/Tiny-Snow/BEAR-SIGIR-2026 .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a training-inference mismatch in LLM-based recommendation: standard SFT optimizes the overall probability of positive items but does not prevent their premature pruning during beam search at inference when prefix probabilities fall below competing paths. It introduces BEAR, which augments the fine-tuning loss with a regularization term enforcing that each token of a positive item ranks among the top-B candidates at every decoding step. This is presented as a relaxed necessary condition that mitigates incorrect pruning at negligible extra cost. Experiments across four real-world datasets report that BEAR outperforms strong baselines.
Significance. If the local top-B condition proves sufficient to preserve positive sequences under actual beam search and does not degrade other ranking metrics, BEAR would offer a lightweight, practical alignment between training and inference for generative recommenders. The availability of code and the multi-dataset evaluation are positive factors that would strengthen adoption if the empirical claims are robustly supported.
major comments (2)
- [§3] §3 (Method), the definition of the BEAR objective: the manuscript asserts that enforcing per-token top-B ranking at each step mitigates the risk of incorrect pruning, yet provides no derivation or counter-example analysis demonstrating that this local condition guarantees survival of the full sequence under global beam search (where pruning decisions depend on cumulative log-probabilities across competing beams). The skeptic concern that a sequence can satisfy the per-step condition while still being outranked cumulatively is not addressed.
- [Experiments] Experiments section: results claim significant outperformance, but the reported tables lack full details on exact metric values for all baselines, statistical significance tests (e.g., paired t-tests or Wilcoxon), and ablation isolating BEAR from standard SFT. Without these, the central empirical claim that the relaxed condition improves retrieval quality remains only moderately supported.
minor comments (2)
- [Abstract] Abstract and §1: the phrase 'significantly outperforms' should be accompanied by concrete improvement magnitudes or primary metrics to allow readers to gauge practical impact without reading the full results.
- [§3] Notation in §3: the exact formulation of the regularization term (e.g., how the top-B ranking is turned into a loss) could be clarified with a short pseudocode snippet or explicit equation reference to avoid ambiguity in implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying our approach where appropriate and outlining planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method), the definition of the BEAR objective: the manuscript asserts that enforcing per-token top-B ranking at each step mitigates the risk of incorrect pruning, yet provides no derivation or counter-example analysis demonstrating that this local condition guarantees survival of the full sequence under global beam search (where pruning decisions depend on cumulative log-probabilities across competing beams). The skeptic concern that a sequence can satisfy the per-step condition while still being outranked cumulatively is not addressed.
Authors: We thank the referee for highlighting this distinction. The BEAR objective enforces a relaxed necessary condition: if any token of a positive item falls outside the top-B candidates at its decoding step, the corresponding path is immediately pruned by beam search, independent of later cumulative scores. This directly targets the premature pruning issue identified in the paper. We agree that the condition is not sufficient to guarantee the sequence will survive global beam search, as cumulative log-probabilities across competing beams ultimately determine retention. In the revised manuscript we will expand §3 to explicitly state this limitation, include a brief counter-example showing a case where per-step top-B ranking holds yet the full sequence is outranked cumulatively, and explain why the local condition nonetheless provides practical mitigation at negligible cost. No change to the core objective is required. revision: partial
-
Referee: Experiments section: results claim significant outperformance, but the reported tables lack full details on exact metric values for all baselines, statistical significance tests (e.g., paired t-tests or Wilcoxon), and ablation isolating BEAR from standard SFT. Without these, the central empirical claim that the relaxed condition improves retrieval quality remains only moderately supported.
Authors: We agree that additional experimental details will strengthen the empirical claims. In the revised version we will expand the tables to report exact metric values for every baseline, add statistical significance results using paired t-tests (with p-values) computed over multiple random seeds, and include a dedicated ablation study that isolates the BEAR regularization term from standard SFT. These updates will be placed in the Experiments section and will directly address the concern about moderate support for the central claim. revision: yes
Circularity Check
No circularity: BEAR objective is constructed directly from beam-search mechanics
full rationale
The paper's central derivation introduces BEAR as a regularization term that enforces each positive-item token to lie in the top-B candidates at its decoding step. This condition is defined explicitly from the standard beam-search pruning rule (select B highest cumulative-score paths) and does not reduce to any fitted parameter, self-citation chain, or quantity defined inside the paper itself. The objective is therefore an independent modeling choice rather than a tautological restatement of its inputs. No load-bearing step collapses by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Beam search decoding prunes candidates based on cumulative prefix probability
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BEAR enforces a relaxed necessary condition: each token in a positive item must rank within the top-B candidate tokens at each decoding step
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lreg = sum log sigma(log beta_B^t - log P(y_t | y_<t, x))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Keqin Bao, Jizhi Zhang, Wenjie Wang, Yang Zhang, Zhengyi Yang, Yanchen Luo, Chong Chen, Fuli Feng, and Qi Tian. 2025. A bi-step grounding paradigm for large language models in recommendation systems.ACM Transactions on Recommender Systems3, 4 (2025), 1–27
work page 2025
-
[4]
Keqin Bao, Jizhi Zhang, Yang Zhang, Xinyue Huo, Chong Chen, and Fuli Feng
-
[5]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Decoding matters: Addressing amplification bias and homogeneity issue in recommendations for large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 10540–10552
work page 2024
-
[6]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. InProceedings of the 17th ACM conference on recommender systems. 1007–1014
work page 2023
-
[7]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
work page 2020
-
[8]
Guohao Cai, Jieming Zhu, Quanyu Dai, Zhenhua Dong, Xiuqiang He, Ruiming Tang, and Rui Zhang. 2022. Reloop: A self-correction continual learning loop for recommender systems. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2692–2697
work page 2022
-
[9]
Jianxin Chang, Chen Gao, Yu Zheng, Yiqun Hui, Yanan Niu, Yang Song, Depeng Jin, and Yong Li. 2021. Sequential recommendation with graph neural networks. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 378–387
work page 2021
-
[10]
Xu Chen, Hongteng Xu, Yongfeng Zhang, Jiaxi Tang, Yixin Cao, Zheng Qin, and Hongyuan Zha. 2018. Sequential recommendation with user memory networks. InProceedings of the eleventh ACM international conference on web search and data mining. 108–116
work page 2018
-
[11]
Yuxin Chen, Junfei Tan, An Zhang, Zhengyi Yang, Leheng Sheng, Enzhi Zhang, Xiang Wang, and Tat-Seng Chua. 2024. On softmax direct preference optimization for recommendation.Advances in Neural Information Processing Systems37 (2024), 27463–27489
work page 2024
-
[12]
Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, and Jiawei Chen. 2024. Distillation matters: empowering sequential recommenders to match the performance of large language models. InProceedings of the 18th ACM Conference on Recommender Systems. 507–517
work page 2024
- [13]
-
[14]
Sunhao Dai, Ninglu Shao, Haiyuan Zhao, Weijie Yu, Zihua Si, Chen Xu, Zhongx- iang Sun, Xiao Zhang, and Jun Xu. 2023. Uncovering chatgpt’s capabilities in recommender systems. InProceedings of the 17th ACM Conference on Recom- mender Systems. 1126–1132
work page 2023
-
[15]
Markus Freitag and Yaser Al-Onaizan. 2017. Beam Search Strategies for Neural Machine Translation. InProceedings of the First Workshop on Neural Machine Translation. 56–60
work page 2017
-
[16]
Chongming Gao, Ruijun Chen, Shuai Yuan, Kexin Huang, Yuanqing Yu, and Xiangnan He. 2025. Sprec: Self-play to debias llm-based recommendation. In Proceedings of the ACM on Web Conference 2025. 5075–5084
work page 2025
- [17]
-
[18]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM conference on recommender systems. 299–315
work page 2022
-
[19]
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, and Gabriel Synnaeve. 2024. Better & faster large language models via multi-token prediction.arXiv preprint arXiv:2404.19737(2024)
work page internal anchor Pith review arXiv 2024
-
[20]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Ruining He and Julian McAuley. 2016. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. Inproceedings of the 25th international conference on world wide web. 507–517
work page 2016
-
[22]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[23]
Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory.Neural computation9, 8 (1997), 1735–1780
work page 1997
-
[25]
Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian McAuley, and Wayne Xin Zhao. 2024. Large language models are zero-shot rankers for recommender systems. InEuropean Conference on Information Retrieval. Springer, 364–381
work page 2024
-
[26]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3. BEAR: Towards Beam-Search-Aware Optimization for Recommendation with Large Language Models Preprint, 2026, Hangzhou, China
work page 2022
-
[27]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
work page 2018
-
[28]
Sein Kim, Hongseok Kang, Seungyoon Choi, Donghyun Kim, Minchul Yang, and Chanyoung Park. 2024. Large language models meet collaborative filtering: An efficient all-round llm-based recommender system. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1395–1406
work page 2024
-
[29]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. 2012. Imagenet classifi- cation with deep convolutional neural networks.Advances in neural information processing systems25 (2012)
work page 2012
-
[30]
Jiacheng Li, Yujie Wang, and Julian McAuley. 2020. Time interval aware self- attention for sequential recommendation. InProceedings of the 13th international conference on web search and data mining. 322–330
work page 2020
-
[31]
Xiaoxi Li, Jiajie Jin, Yujia Zhou, Yuyao Zhang, Peitian Zhang, Yutao Zhu, and Zhicheng Dou. 2025. From matching to generation: A survey on generative information retrieval.ACM Transactions on Information Systems43, 3 (2025), 1–62
work page 2025
- [32]
- [33]
-
[34]
Jiayi Liao, Sihang Li, Zhengyi Yang, Jiancan Wu, Yancheng Yuan, Xiang Wang, and Xiangnan He. 2024. Llara: Large language-recommendation assistant. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1785–1795
work page 2024
- [35]
- [36]
-
[37]
Junling Liu, Chao Liu, Peilin Zhou, Renjie Lv, Kang Zhou, and Yan Zhang
- [38]
-
[39]
Qijiong Liu, Nuo Chen, Tetsuya Sakai, and Xiao-Ming Wu. 2024. Once: Boosting content-based recommendation with both open-and closed-source large language models. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 452–461
work page 2024
- [40]
-
[41]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Sijin Lu, Zhibo Man, Fangyuan Luo, and Jun Wu. 2025. Dual Debiasing in LLM-based Recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2685–2689
work page 2025
-
[43]
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel
-
[44]
Image-based recommendations on styles and substitutes. InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52
-
[45]
Fei Mi, Xiaoyu Lin, and Boi Faltings. 2020. Ader: Adaptively distilled exem- plar replay towards continual learning for session-based recommendation. In Proceedings of the 14th ACM Conference on Recommender Systems. 408–413
work page 2020
-
[46]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
work page 2022
-
[47]
Weizhen Qi, Yeyun Gong, Yu Yan, Jian Jiao, Bo Shao, Ruofei Zhang, Houqiang Li, Nan Duan, and Ming Zhou. 2020. Prophetnet-ads: A looking ahead strategy for generative retrieval models in sponsored search engine. InCCF International Conference on Natural Language Processing and Chinese Computing. Springer, 305–317
work page 2020
-
[48]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners.OpenAI blog 1, 8 (2019), 9
work page 2019
-
[49]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
work page 2023
-
[50]
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ Questions for Machine Comprehension of Text. InProceed- ings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2383–2392
work page 2016
-
[51]
Wentao Shi, Xiangnan He, Yang Zhang, Chongming Gao, Xinyue Li, Jizhi Zhang, Qifan Wang, and Fuli Feng. 2024. Large language models are learnable planners for long-term recommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1893–1903
work page 2024
-
[52]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[53]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[54]
Zhongxiang Sun, Zihua Si, Xiaoxue Zang, Kai Zheng, Yang Song, Xiao Zhang, and Jun Xu. 2024. Large language models enhanced collaborative filtering. InPro- ceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2178–2188
work page 2024
- [55]
-
[56]
Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommenda- tion via convolutional sequence embedding. InProceedings of the eleventh ACM international conference on web search and data mining. 565–573
work page 2018
-
[57]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
2013.The nature of statistical learning theory
Vladimir Vapnik. 2013.The nature of statistical learning theory. Springer science & business media
work page 2013
-
[59]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
work page 2017
-
[60]
Ashwin Vijayakumar, Michael Cogswell, Ramprasaath Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. 2018. Diverse beam search for improved description of complex scenes. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 32
work page 2018
-
[61]
Bohao Wang, Feng Liu, Jiawei Chen, Xingyu Lou, Changwang Zhang, Jun Wang, Yuegang Sun, Yan Feng, Chun Chen, and Can Wang. 2025. Msl: Not all tokens are what you need for tuning llm as a recommender. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1912–1922
work page 2025
-
[62]
Bohao Wang, Feng Liu, Changwang Zhang, Jiawei Chen, Yudi Wu, Sheng Zhou, Xingyu Lou, Jun Wang, Yan Feng, Chun Chen, and Can Wang. 2025. LLM4DSR: Leveraging Large Language Model for Denoising Sequential Recommendation. ACM Transactions on Information Systems(Aug. 2025). Just Accepted
work page 2025
- [63]
-
[64]
Zhefan Wang, Weizhi Ma, and Min Zhang. 2024. To recommend or not: Recom- mendability identification in conversations with pre-trained language models. In International Conference on Database Systems for Advanced Applications. Springer, 19–35
work page 2024
-
[65]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
work page 2022
-
[66]
Wei Wei, Chao Huang, Lianghao Xia, and Chuxu Zhang. 2023. Multi-modal self-supervised learning for recommendation. InProceedings of the ACM web conference 2023. 790–800
work page 2023
-
[67]
Jiancan Wu, Xiang Wang, Xingyu Gao, Jiawei Chen, Hongcheng Fu, and Tianyu Qiu. 2024. On the effectiveness of sampled softmax loss for item recommendation. ACM Transactions on Information Systems42, 4 (2024), 1–26
work page 2024
-
[68]
Shiguang Wu, Zhaochun Ren, Xin Xin, Jiyuan Yang, Mengqi Zhang, Zhumin Chen, Maarten de Rijke, and Pengjie Ren. 2025. Constrained Auto-Regressive Decoding Constrains Generative Retrieval. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2429–2440
work page 2025
-
[69]
Xue Xia, Pong Eksombatchai, Nikil Pancha, Dhruvil Deven Badani, Po-Wei Wang, Neng Gu, Saurabh Vishwas Joshi, Nazanin Farahpour, Zhiyuan Zhang, and An- drew Zhai. 2023. Transact: Transformer-based realtime user action model for recommendation at pinterest. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5249–5259
work page 2023
-
[70]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. 2024. Qwen2. 5- math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Weiqin Yang, Jiawei Chen, Xin Xin, Sheng Zhou, Binbin Hu, Yan Feng, Chun Chen, and Can Wang. 2024. PSL: Rethinking and Improving Softmax Loss from Pairwise Perspective for Recommendation.Advances in Neural Information Processing Systems37 (2024), 120974–121006
work page 2024
-
[72]
Weiqin Yang, Jiawei Chen, Shengjia Zhang, Peng Wu, Yuegang Sun, Yan Feng, Chun Chen, and Can Wang. 2025. Breaking the Top-K Barrier: Advancing Top-K Ranking Metrics Optimization in Recommender Systems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 3542–3552
work page 2025
-
[73]
Zhengyi Yang, Xiangnan He, Jizhi Zhang, Jiancan Wu, Xin Xin, Jiawei Chen, and Xiang Wang. 2023. A generic learning framework for sequential recommenda- tion with distribution shifts. InProceedings of the 46th International ACM SIGIR Preprint, 2026, Hangzhou, China Weiqin Yang et al. Conference on Research and Development in Information Retrieval. 331–340
work page 2023
-
[74]
Hansi Zeng, Chen Luo, Bowen Jin, Sheikh Muhammad Sarwar, Tianxin Wei, and Hamed Zamani. 2024. Scalable and effective generative information retrieval. In Proceedings of the ACM Web Conference 2024. 1441–1452
work page 2024
-
[75]
Hansi Zeng, Chen Luo, and Hamed Zamani. 2024. Planning ahead in generative retrieval: Guiding autoregressive generation through simultaneous decoding. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 469–480
work page 2024
-
[76]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. 2024. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
Junjie Zhang, Ruobing Xie, Yupeng Hou, Xin Zhao, Leyu Lin, and Ji-Rong Wen
-
[78]
Recommendation as instruction following: A large language model em- powered recommendation approach.ACM Transactions on Information Systems 43, 5 (2025), 1–37
work page 2025
- [79]
-
[80]
Xin Zhou, Hongyu Zhou, Yong Liu, Zhiwei Zeng, Chunyan Miao, Pengwei Wang, Yuan You, and Feijun Jiang. 2023. Bootstrap latent representations for multi- modal recommendation. InProceedings of the ACM web conference 2023. 845–854
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.