Recognition: 2 theorem links
· Lean TheoremSparse Reward Subsystem in Large Language Models
Pith reviewed 2026-05-16 09:18 UTC · model grok-4.3
The pith
Reward-related information in large language models concentrates in a sparse subset of neurons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reward-related information is concentrated in a sparse subset of neurons within LLM hidden states. Using simple probing, we identify value neurons whose activations predict state value and dopamine neurons whose activations encode step-level temporal difference errors. Together these neurons form a sparse reward subsystem. Value neurons are robust and transferable across diverse datasets and models, and we provide causal evidence that they encode reward-related information. The subsystem enables applications such as using value neurons to predict model confidence and dopamine neurons as a process reward model to guide inference-time search.
What carries the argument
Value neurons and dopamine neurons identified via linear probing of hidden states, together forming the sparse reward subsystem that encodes state values and temporal-difference errors.
If this is right
- Value neurons serve as effective predictors of model confidence.
- Dopamine neurons can function as a process reward model to guide inference-time search.
- Value neurons remain effective across diverse datasets and models.
- Causal interventions on the identified neurons alter the encoding of reward-related information.
Where Pith is reading between the lines
- Targeting these neurons individually could allow more precise editing of an LLM's reward-sensitive behavior without retraining the full model.
- The same probing method might locate analogous sparse subsystems for other internal signals such as uncertainty or planning.
- If the subsystem is modular, future training runs could regularize or amplify it separately to improve alignment or exploration.
Load-bearing premise
Linear probes on hidden states isolate neurons whose activations causally encode reward signals rather than merely correlating with them.
What would settle it
An intervention that selectively ablates or perturbs the identified value and dopamine neurons and finds no measurable change in the model's reward predictions or search performance.
Figures








read the original abstract
Recent studies show that LLM hidden states encode reward-related information, such as answer correctness and model confidence. However, existing approaches typically fit black-box probes on the full hidden states, offering little insight into how this information is structured across neurons. In this paper, we show that reward-related information is concentrated in a sparse subset of neurons. Using simple probing, we identify two types of neurons: value neurons, whose activations predict state value, and dopamine neurons, whose activations encode step-level temporal difference (TD) errors. Together, these neurons form a sparse reward subsystem within LLM hidden states. These names are drawn by analogy with neuroscience, where value neurons and dopamine neurons in the biological reward subsystem also encode value and reward prediction errors, respectively. We demonstrate that value neurons are robust and transferable across diverse datasets and models, and provide causal evidence that they encode reward-related information. Finally, we show applications of the reward subsystem: value neurons serve as effective predictors of model confidence, and dopamine neurons can function as a process reward model (PRM) to guide inference-time search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that reward-related information in LLM hidden states is concentrated in a sparse subset of neurons. Using linear probes, it identifies value neurons whose activations predict state value and dopamine neurons whose activations encode step-level temporal difference (TD) errors. These form a sparse reward subsystem by analogy to neuroscience. The paper reports that value neurons are robust and transferable across datasets and models, supplies causal evidence via interventions, and demonstrates applications including confidence prediction and use of dopamine neurons as a process reward model (PRM) to guide inference-time search.
Significance. If the central claims hold, the work contributes to mechanistic interpretability by isolating a sparse internal structure for reward processing in LLMs. The empirical identification of transferable value neurons and the proposed applications to confidence calibration and PRM-guided search could inform alignment and inference techniques. The absence of parameter-free derivations or machine-checked proofs limits the strength of the contribution relative to purely theoretical work, but reproducible probing and intervention protocols would be a positive if fully documented.
major comments (2)
- [Causal evidence / interventions] Causal evidence section: the assertion that interventions on the identified neurons supply causal evidence for encoding reward-related information is load-bearing for the central claim, yet the description supplies no quantitative comparison showing that ablating the selected neurons produces a larger drop in reward metrics (e.g., calibration error or PRM-guided search success) than ablating an equal number of randomly chosen neurons matched for activation magnitude. Without this differential control, the neurons may simply be high-variance features rather than a dedicated subsystem.
- [Probing methods and results] Probing and results sections: the abstract states that value neurons are robust and transferable but provides no reported probe accuracies, effect sizes, or sparsity statistics (e.g., fraction of neurons selected, cross-validation R²). These metrics are required to substantiate the sparsity claim and to allow verification that the probes isolate reward-specific signals rather than generic variance.
minor comments (1)
- [Abstract] Abstract: the neuroscience analogy for labeling value and dopamine neurons is presented without explicit caveats; a brief clarification that the labels are functional analogies rather than claims of biological equivalence would reduce risk of misreading.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and describe the planned revisions.
read point-by-point responses
-
Referee: Causal evidence section: the assertion that interventions on the identified neurons supply causal evidence for encoding reward-related information is load-bearing for the central claim, yet the description supplies no quantitative comparison showing that ablating the selected neurons produces a larger drop in reward metrics (e.g., calibration error or PRM-guided search success) than ablating an equal number of randomly chosen neurons matched for activation magnitude. Without this differential control, the neurons may simply be high-variance features rather than a dedicated subsystem.
Authors: We agree that a matched random ablation control is necessary to strengthen the causal claim. In the revision we will add quantitative comparisons of reward metric degradation (calibration error and search success) between targeted ablations and random controls of equal size and activation magnitude, including statistical significance tests. revision: yes
-
Referee: Probing and results sections: the abstract states that value neurons are robust and transferable but provides no reported probe accuracies, effect sizes, or sparsity statistics (e.g., fraction of neurons selected, cross-validation R²). These metrics are required to substantiate the sparsity claim and to allow verification that the probes isolate reward-specific signals rather than generic variance.
Authors: The full manuscript already reports probe accuracies, R² values, and sparsity fractions in the probing and results sections. We will revise the abstract to include the key numerical statistics (average probe accuracy, fraction of neurons selected, and cross-validation R²) so that the sparsity and robustness claims are quantified at the abstract level. revision: partial
Circularity Check
No significant circularity; empirical identification and intervention remain independent
full rationale
The paper identifies value neurons and dopamine neurons by fitting linear probes to predict state value and TD errors from hidden-state activations, then reports causal effects via separate ablation and scaling interventions. No derivation, equation, or self-citation reduces the reported causal subsystem or its performance metrics to the probe-fit parameters by construction. The central claims rest on differential intervention outcomes rather than renaming or re-using the probe outputs themselves. This is standard empirical probing plus control comparison and scores as self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
value neurons, whose activations predict state value, and dopamine neurons, whose activations encode step-level temporal difference (TD) errors... intervention experiments... zeroing out the hidden states of even a small fraction of value neurons results in substantial performance degradation
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
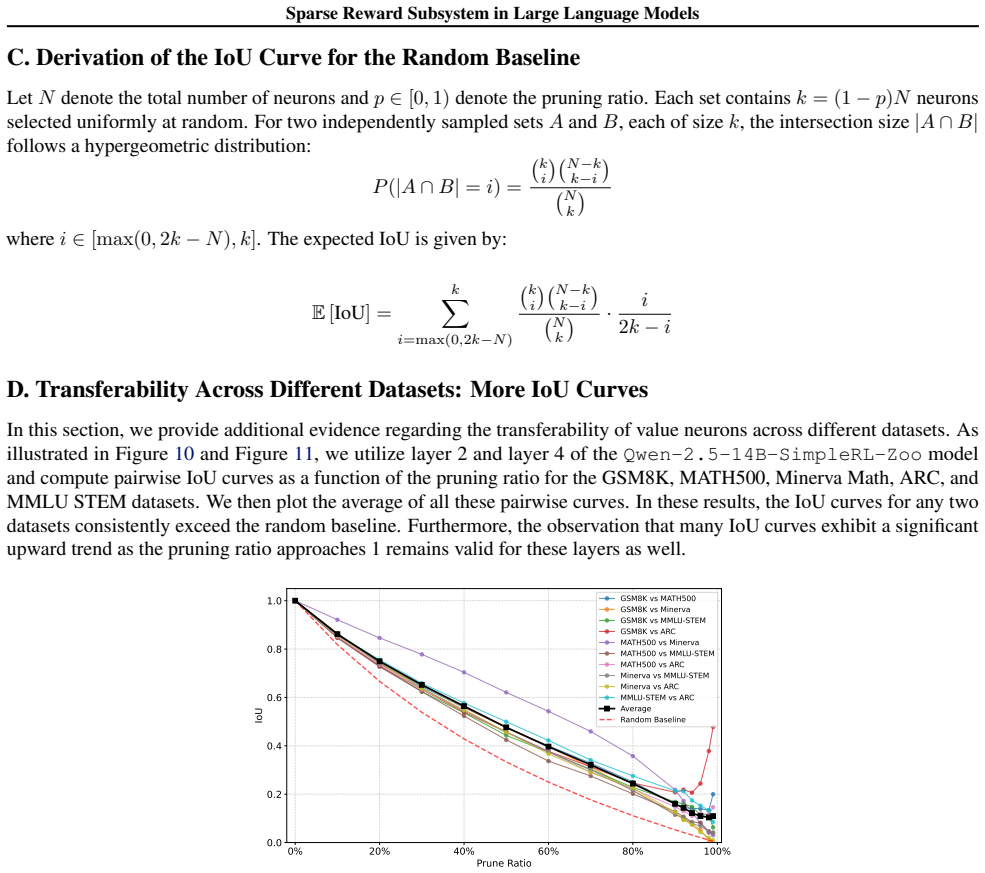
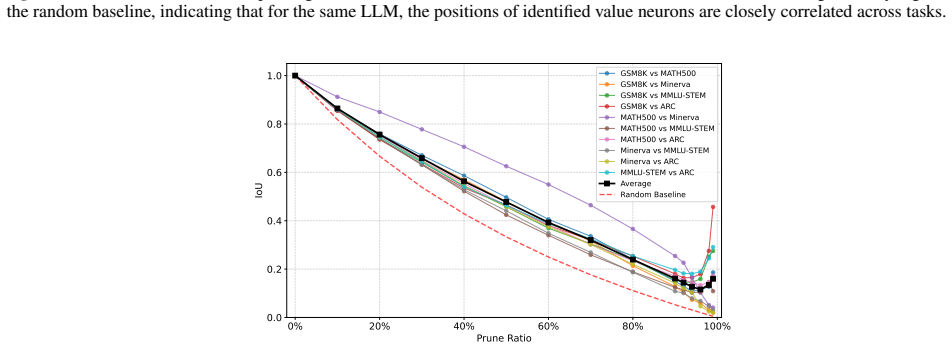
AUC curves do not exhibit a significant decline as pruning proceeds; even a slight initial increase... value neurons... robust and transferable across diverse datasets and models
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2404.14219. Bai, J., Bai, S., Chu, Y ., Cui, Z., Dang, K., Deng, X., Fan, Y ., Ge, W., Han, Y ., Huang, F., Hui, B., Ji, L., Li, M., Lin, J., Lin, R., Liu, D., Liu, G., Lu, C., Lu, K., Ma, J., Men, R., Ren, X., Ren, X., Tan, C., Tan, S., Tu, J., Wang, P., Wang, S., Wang, W., Wu, S., Xu, B., Xu, J., Yang, A., Yang, H., Yang, J., Ya...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URL https://arxiv.org/ abs/2309.16609. Burns, C., Ye, H., Klein, D., and Steinhardt, J. Discovering latent knowledge in language models without supervision. InThe Eleventh International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Chen, J., Hu, S., Liu, Z., and Sun, M
URL https://arxiv.org/abs/ 2509.10625. Chen, J., Hu, S., Liu, Z., and Sun, M. States hidden in hidden states: Llms emerge discrete state representations implicitly,
-
[4]
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O
URL https://arxiv.org/abs/ 2407.11421. Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge,
-
[5]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
URL https://arxiv.org/abs/ 1803.05457. Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Training Verifiers to Solve Math Word Problems
URL https://arxiv. org/abs/2110.14168. Diego-Sim´on, P., D’Ascoli, S., Chemla, E., Lakretz, Y ., and King, J.-R. A polar coordinate system represents syntax in large language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Du, H., Dong, Y ., and Ning, X
URL https: //arxiv.org/abs/2412.05571. Du, H., Dong, Y ., and Ning, X. Latent thinking optimization: Your latent reasoning language model secretly encodes reward signals in its latent thoughts,
-
[8]
Gao, C., Chen, H., Xiao, C., Chen, Z., Liu, Z., and Sun, M
URL https: //arxiv.org/abs/2509.26314. Gao, C., Chen, H., Xiao, C., Chen, Z., Liu, Z., and Sun, M. H-neurons: On the existence, impact, and origin of hallucination-associated neurons in llms,
-
[9]
URL https://arxiv.org/abs/2512.01797. Gekhman, Z., Ben-David, E., Orgad, H., Ofek, E., Belinkov, Y ., Szpektor, I., Herzig, J., and Reichart, R. Inside-out: Hidden factual knowledge in LLMs. InSecond Con- ference on Language Modeling,
-
[10]
URL https://arxiv.org/abs/2407.21783. Gunasekar, S., Zhang, Y ., Aneja, J., Mendes, C. C. T., 10 Sparse Reward Subsystem in Large Language Models Giorno, A. D., Gopi, S., Javaheripi, M., Kauffmann, P., de Rosa, G., Saarikivi, O., Salim, A., Shah, S., Behl, H. S., Wang, X., Bubeck, S., Eldan, R., Kalai, A. T., Lee, Y . T., and Li, Y . Textbooks are all you need,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
URL https://arxiv.org/abs/2306.11644. Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., Zhang, X., Yu, X., Wu, Y ., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., Liu, A., Xue, B., Wang, B., Wu, B., Feng, B., Lu, C., Zhao, C., Deng, C., Ruan, C., Dai, D., Chen, D., Ji, D., Li, E., Lin, F., Dai, F., Luo, F., Hao,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09422-z
-
[12]
URL https: //assets-8291.accso.de/downloads/ Masterarbeit_Ilir_Hajrullahu_2025.pdf. Supervised by Dr. Yunpu Ma. Han, J., Band, N., Razzak, M., Kossen, J., Rudner, T. G. J., and Gal, Y . Simple factuality probes de- tect hallucinations in long-form natural language gen- eration. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Fin...
work page 2025
-
[13]
As- sociation for Computational Linguistics. ISBN 979-8- 89176-335-7. doi: 10.18653/v1/2025.findings-emnlp
-
[14]
URL https://aclanthology.org/2025. findings-emnlp.880/. Heindrich, L., Torr, P., Barez, F., and Thost, V . Do sparse autoencoders generalize? a case study of an- swerability. InICML 2025 Workshop on Reliable and Responsible Foundation Models,
work page 2025
-
[15]
Language Models (Mostly) Know What They Know
URLhttps://arxiv.org/abs/2207.05221. Lewkowycz, A., Andreassen, A. J., Dohan, D., Dyer, E., Michalewski, H., Ramasesh, V . V ., Slone, A., Anil, C., Schlag, I., Gutman-Solo, T., Wu, Y ., Neyshabur, B., Gur- Ari, G., and Misra, V . Solving quantitative reasoning problems with language models. In Oh, A. H., Agarwal, A., Belgrave, D., and Cho, K. (eds.),Adva...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URL https: //arxiv.org/abs/2512.20949. Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step,
-
[17]
URL https: //arxiv.org/abs/2305.20050. Liu, X., Liang, T., He, Z., Xu, J., Wang, W., He, P., Tu, Z., Mi, H., and Yu, D. Trust, but verify: A self-verification approach to reinforcement learning with verifiable re- wards. InThe Thirty-ninth Annual Conference on Neural 11 Sparse Reward Subsystem in Large Language Models Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
URL https://arxiv.org/ abs/2410.01866. Padoa-Schioppa, C. and Assad, J. A. Neurons in the or- bitofrontal cortex encode economic value.Nature, 441 (7090):223–226,
-
[19]
URL https://arxiv.org/abs/2601.03267. Team, G., Mesnard, T., Hardin, C., Dadashi, R., Bhupatiraju, S., Pathak, S., Sifre, L., Rivi`ere, M., Kale, M. S., Love, J., Tafti, P., Hussenot, L., Sessa, P. G., Chowdhery, A., Roberts, A., Barua, A., Botev, A., Castro-Ros, A., Slone, A., H´eliou, A., Tacchetti, A., Bulanova, A., Paterson, A., Tsai, B., Shahriari, B...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
URLhttps://arxiv.org/abs/2403.08295. Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ram ´e, A., Rivi`ere, M., Rouillard, L., Mesnard, T., Cideron, G., bastien Grill, J., Ramos, S., Yvinec, E., Casbon, M., Pot, E., Penchev, I., Liu, G., Visin, F., Kenealy, K., Beyer, L., Zhai, X., Tsitsulin, A., Busa-...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
URLhttps://arxiv.org/abs/2503.19786. Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi `ere, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lample, G. Llama: Open and efficient foundation lan- guage models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
LLaMA: Open and Efficient Foundation Language Models
URL https://arxiv.org/ abs/2302.13971. Tremblay, L. and Schultz, W. Relative reward preference in primate orbitofrontal cortex.Nature, 398(6729):704–708,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Zeng, W., Huang, Y ., Liu, Q., Liu, W., He, K., Ma, Z., and He, J
URL https://arxiv.org/ abs/2510.14943. Zeng, W., Huang, Y ., Liu, Q., Liu, W., He, K., Ma, Z., and He, J. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild,
-
[24]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
URL https://arxiv.org/abs/ 2503.18892. 13 Sparse Reward Subsystem in Large Language Models Zhang, L., Song, D., Wu, Z., Tian, Y ., Zhou, C., Xu, J., Yang, Z., and Zhang, S. Detecting hallucination in large language models through deep internal represen- tation analysis. InProceedings of the Thirty-Fourth In- ternational Joint Conference on Artificial Inte...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.24963/ijcai.2025/929 2025
-
[25]
Learning to Reason without External Rewards
URL https://arxiv.org/abs/2505.19590. Zhu, Y ., Liu, D., Lin, Z., Tong, W., Zhong, S., and Shao, J. The llm already knows: Estimating llm-perceived question difficulty via hidden representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
14 Sparse Reward Subsystem in Large Language Models A
URL https://arxiv.org/abs/2509.12886. 14 Sparse Reward Subsystem in Large Language Models A. The Benefit of Using the TD Error Training Objective One might naturally question the specific benefits of utilizing a Temporal Difference (TD) error training objective as opposed to simply predicting the final reward. To investigate this, we conducted an ablation...
-
[27]
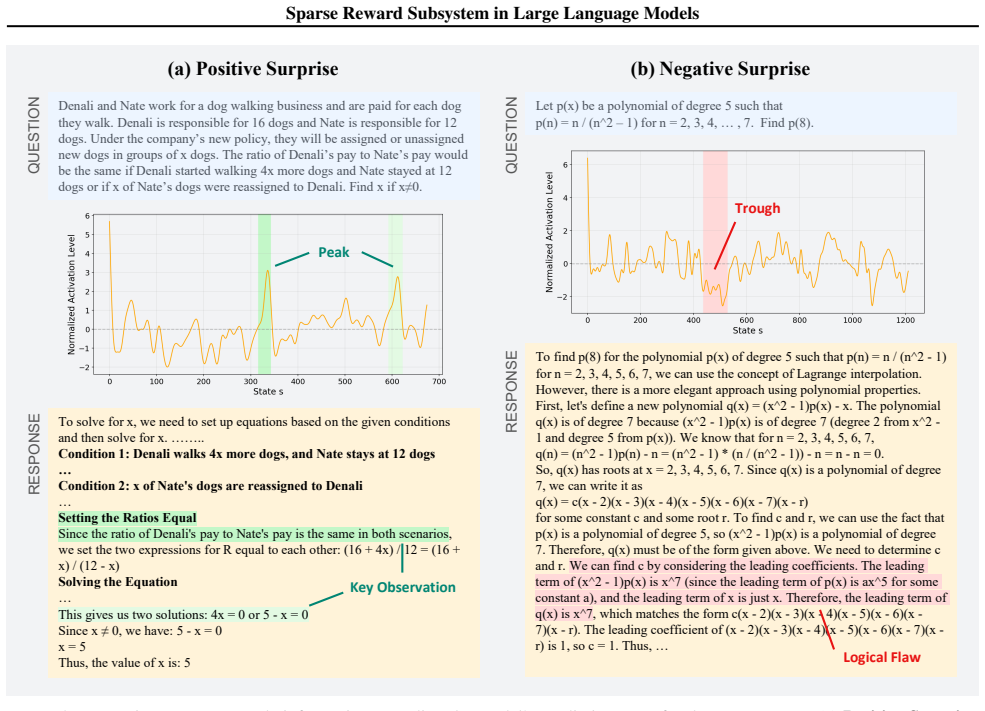
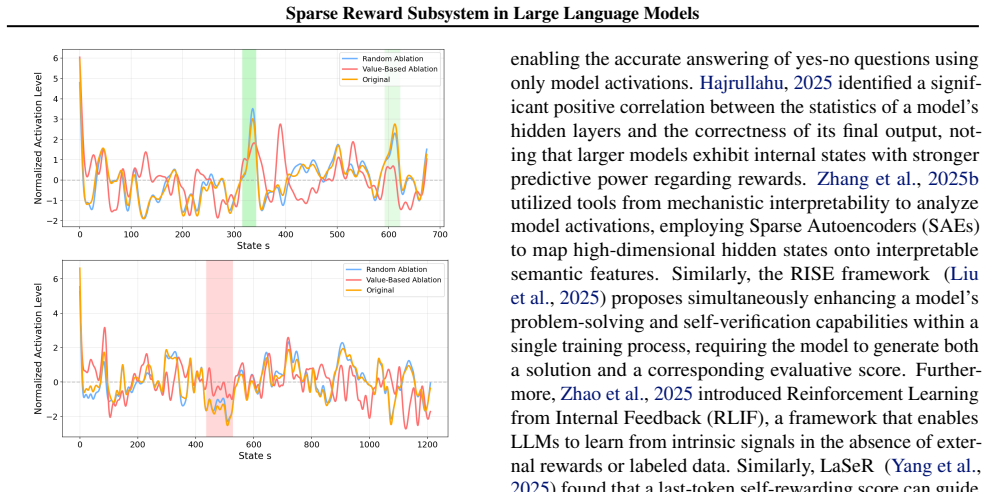
+ C e^(-2t) y = 1/2 t - 1/4 + C e^(-2t) Therefore, the general solution to the differential equation y' = x - 2y is: y = 1/2 t - 1/4 + C e^(-2t) (a) Positive Surprise (b) Negative SurpriseQUESTION RESPONSEKey ObservationWrong Step More datasets PeakTrough Figure 12.Dopamine neurons encode information regarding the model’s prediction error for the current ...
work page 2025
-
[28]
Do not try to solve the question. ’to elicit a confidence score. If the model fails to produce a valid numerical output, we resample until a score is obtained. The Spearman correlation coefficient for this method is only 0.08. 19 Sparse Reward Subsystem in Large Language Models Next-token Confidence.In this baseline, we utilize the log probability ( logp ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.