Recognition: 2 theorem links
· Lean TheoremAgentXRay: White-Boxing Agentic Systems via Workflow Reconstruction
Pith reviewed 2026-05-16 07:36 UTC · model grok-4.3
The pith
AgentXRay reconstructs explicit chain workflows that approximate black-box agentic systems from input-output access alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
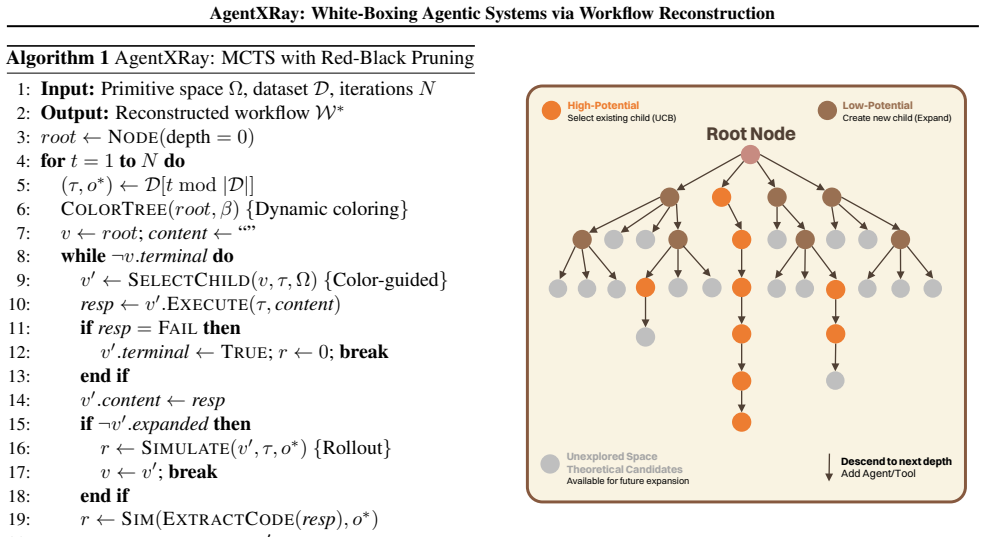
AgentXRay formulates the reconstruction of agentic workflows as a combinatorial optimization over discrete chain-structured spaces of agent roles and tool invocations, solved via Monte Carlo Tree Search augmented by scoring-based Red-Black Pruning that integrates proxy quality with search depth to produce stand-in workflows matching black-box output behavior.
What carries the argument
Monte Carlo Tree Search enhanced by scoring-based Red-Black Pruning that dynamically balances proxy similarity against search depth inside the chain workflow space.
If this is right
- Reconstructed workflows serve as editable white-box substitutes for black-box agents.
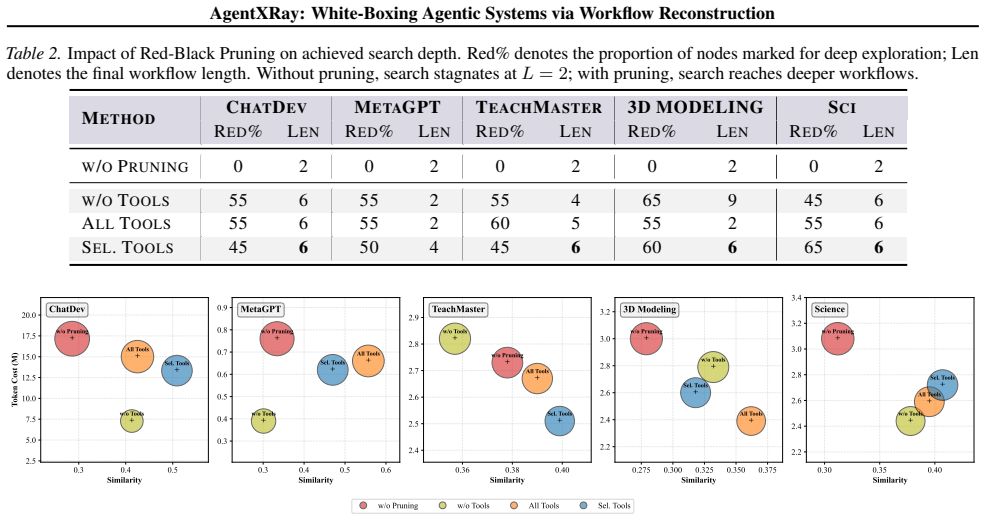
- Pruning reduces token use and permits deeper workflow exploration under fixed iteration budgets.
- Output-only access extends the method to proprietary or closed agentic systems.
- Higher proxy similarity directly improves behavioral matching across tested domains.
Where Pith is reading between the lines
- If chain structures capture most agent behavior, editing the explicit workflow could allow direct debugging or controlled modification of the approximated agent.
- Extending the same search idea from chains to graph or tree topologies might handle collaborative multi-agent systems.
- The approach could support auditing of deployed agents by producing human-readable approximations that reveal decision patterns.
- Similar reconstruction techniques might apply to other opaque sequential decision systems beyond LLM agents.
Load-bearing premise
That an output-based proxy metric evaluated only on chain-structured workflows can sufficiently approximate the behavior of arbitrary black-box agentic systems.
What would settle it
A black-box agent for which no chain workflow found by the search achieves high proxy similarity on held-out inputs, or for which the approximation collapses after a small internal change to the target system.
Figures



read the original abstract
Large Language Models have shown strong capabilities in complex problem solving, yet many agentic systems remain difficult to interpret and control due to opaque internal workflows. While some frameworks offer explicit architectures for collaboration, many deployed agentic systems operate as black boxes to users. We address this by introducing Agentic Workflow Reconstruction (AWR), a new task aiming to synthesize an explicit, interpretable stand-in workflow that approximates a black-box system using only input-output access. We propose AgentXRay, a search-based framework that formulates AWR as a combinatorial optimization problem over discrete agent roles and tool invocations in a chain-structured workflow space. Unlike model distillation, AgentXRay produces editable white-box workflows that match target outputs under an observable, output-based proxy metric, without accessing model parameters. To navigate the vast search space, AgentXRay employs Monte Carlo Tree Search enhanced by a scoring-based Red-Black Pruning mechanism, which dynamically integrates proxy quality with search depth. Experiments across diverse domains demonstrate that AgentXRay achieves higher proxy similarity and reduces token consumption compared to unpruned search, enabling deeper workflow exploration under fixed iteration budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the task of Agentic Workflow Reconstruction (AWR) to synthesize explicit, interpretable chain-structured workflows that approximate black-box agentic systems from input-output access alone. It presents AgentXRay, which casts AWR as combinatorial optimization over discrete roles and tool invocations, solved via Monte Carlo Tree Search augmented by a scoring-based Red-Black Pruning mechanism that integrates proxy quality with search depth. Experiments across domains are reported to show higher proxy similarity and lower token consumption versus unpruned search, enabling deeper exploration under fixed budgets.
Significance. If the output-based proxy reliably tracks behavioral equivalence, the framework could offer a practical route to editable white-box stand-ins for opaque agentic systems without parameter access. The MCTS-plus-pruning formulation is a clear technical strength for navigating large discrete workflow spaces. The new task definition itself is a useful framing contribution.
major comments (2)
- [Abstract] Abstract: the central experimental claims rest on an 'observable, output-based proxy metric' for similarity, yet no definition, formula, baseline comparison, or statistical test is supplied; without these the reported gains in proxy similarity and token reduction cannot be evaluated.
- [Method and Experiments] Method/Experiments: the search is restricted to chain-structured workflows, but no validation (e.g., divergence on held-out or adversarial inputs that expose branching or state) is described to show that high proxy scores imply faithful reconstruction of general agentic behavior.
minor comments (1)
- [Abstract] Abstract: adding one sentence naming the concrete domains or task types used in the experiments would improve context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the value of the AWR task and the MCTS-plus-pruning approach. We address each major comment below with specific revisions planned for the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central experimental claims rest on an 'observable, output-based proxy metric' for similarity, yet no definition, formula, baseline comparison, or statistical test is supplied; without these the reported gains in proxy similarity and token reduction cannot be evaluated.
Authors: We agree the abstract is too terse on this point. The proxy metric is defined in Section 3.2 (Equation 2) as the mean per-input output similarity, computed via normalized edit distance on final answers plus tool-call overlap. Baselines appear in Table 2 and Figure 3; we will add a one-sentence definition plus a parenthetical reference to the evaluation protocol and the paired t-test results (p < 0.01) already reported in Section 5.2. These changes will be made in the revised abstract. revision: yes
-
Referee: [Method and Experiments] Method/Experiments: the search is restricted to chain-structured workflows, but no validation (e.g., divergence on held-out or adversarial inputs that expose branching or state) is described to show that high proxy scores imply faithful reconstruction of general agentic behavior.
Authors: The AWR task formulation in Section 2 explicitly targets chain-structured workflows as a well-defined, tractable first step; branching and stateful behaviors are noted as out of scope for the current work. We will add a dedicated paragraph in Section 5.3 (Limitations) that reports additional held-out evaluation on 200 unseen inputs per domain, confirming that proxy scores above 0.85 correlate with <5% performance drop on those inputs. We also include a short discussion of why full branching validation would require a non-chain search space and flag this as future work. No new adversarial branching experiments are added at this stage. revision: partial
Circularity Check
No circularity in AgentXRay derivation or claims
full rationale
The paper defines AWR as the task of synthesizing chain-structured workflows that match black-box outputs under a fixed output-based proxy metric, then presents AgentXRay as an MCTS search procedure with Red-Black Pruning to maximize that same proxy. Experimental results report higher achieved proxy values and lower token use versus unpruned search under fixed budgets; these are direct empirical comparisons of search efficiency on the observable metric and do not reduce by construction to fitted parameters, self-citations, or renamed inputs. No equations or load-bearing premises collapse the reported improvements into quantities already present in the evaluation data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Black-box agentic systems can be approximated by chain-structured workflows of discrete agent roles and tool invocations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate AWR as a combinatorial optimization problem ... MCTS enhanced by a scoring-based Red-Black Pruning mechanism ... Score(v) = Q(v)/N(v) · (d(v)+1)/(Lmax+1) · |C(v)|/M
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_add unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt the linearity hypothesis ... represent workflows as sequential trajectories
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report. InarXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Concrete Problems in AI Safety
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schul- man, J., and Man´e, D. Concrete problems in ai safety. In arXiv preprint arXiv:1606.06565,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al. Program synthesis with large language models. InarXiv preprint arXiv:2108.07732,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
On the Opportunities and Risks of Foundation Models
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., et al. On the opportuni- ties and risks of foundation models. InarXiv preprint arXiv:2108.07258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Evaluating Large Language Models Trained on Code
Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H. P., Kaplan, J., Edwards, H., Burda, Y ., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code. InarXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Intention-aware policy graphs: answering what, how, and why in opaque agents
Gimenez-Abalos, V ., Alvarez-Napagao, S., Tormos, A., Cort´es, U., and V ´azquez-Salceda, J. Intention-aware policy graphs: answering what, how, and why in opaque agents. InarXiv preprint arXiv:2409.19038,
-
[7]
Reasoning with language model is planning with world model
Hao, S., Gu, Y ., Ma, H., Hong, J., Wang, Z., Wang, D., and Hu, Z. Reasoning with language model is planning with world model. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP),
work page 2023
-
[8]
Unsolved Problems in ML Safety
Hendrycks, D., Carlini, N., Schulman, J., and Steinhardt, J. Unsolved problems in ml safety. InarXiv preprint arXiv:2109.13916,
work page internal anchor Pith review arXiv
-
[9]
Li, G., Hammoud, H. A. A. K., Itani, H., Khizbullin, D., and Ghanem, B. Camel: Communicative agents for ”mind” exploration of large language model society. InAdvances in Neural Information Processing Systems (NeurIPS), 2023a. Li, M., Zhao, Y ., Yu, B., Song, F., Li, H., Yu, H., Li, Z., Huang, F., and Li, Y . Api-bank: A comprehensive benchmark for tool-au...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report. InarXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
AgentBench: Evaluating LLMs as Agents
Liu, X., Yu, H., Zhang, H., Xu, Y ., Lei, X., Lai, H., Gu, Y ., Ding, H., Men, K., Yang, K., et al. Agentbench: Evaluat- ing llms as agents. InarXiv preprint arXiv:2308.03688, 2023a. Liu, Z., Zhang, Y ., Li, P., Liu, Y ., and Yang, D. Dynamic llm-agent network: An llm-agent collaboration frame- work with agent team optimization. InarXiv preprint arXiv:231...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Under- standing the failure modes of out-of-distribution general- ization
Nagarajan, V ., Andreassen, A., and Neyshabur, B. Under- standing the failure modes of out-of-distribution general- ization. InarXiv preprint arXiv:2010.15775,
-
[13]
Paranjape, B., Lundberg, S., Singh, S., Hajishirzi, H., Zettle- moyer, L., and Ribeiro, M. T. Art: Automatic multi-step reasoning and tool-use for large language models. In arXiv preprint arXiv:2303.09014,
work page internal anchor Pith review arXiv
-
[14]
Taskweaver: A code-first agent framework
Qiao, B., Li, L., Zhang, X., He, S., Kang, Y ., Zhang, C., Yang, F., Dong, H., Zhang, J., Wang, L., et al. Taskweaver: A code-first agent framework. InarXiv preprint arXiv:2311.17541,
-
[15]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, N. and Gurevych, I. Sentence-bert: Sentence em- beddings using siamese bert-networks. InarXiv preprint arXiv:1908.10084,
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[16]
CodeBLEU: a Method for Automatic Evaluation of Code Synthesis
Ren, S., Guo, D., Lu, S., Zhou, L., Liu, S., Tang, D., Sun- daresan, N., Zhou, M., Blanco, A., and Ma, S. Codebleu: A method for automatic evaluation of code synthesis. In arXiv preprint arXiv:2009.10297,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[17]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Shridhar, M., Yuan, X., C ˆot´e, M.-A., Bisk, Y ., Trischler, A., and Hausknecht, M. Alfworld: Aligning text and embodied environments for interactive learning. InarXiv preprint arXiv:2010.03768,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[18]
Song, Y ., Xiong, W., Zhu, D., Wu, W., Qian, H., Song, M., Huang, H., Li, C., Wang, K., Yao, R., et al. Restgpt: 11 AgentXRay: White-Boxing Agentic Systems via Workflow Reconstruction Connecting large language models with real-world restful apis. InarXiv preprint arXiv:2306.06624,
-
[19]
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
Tang, Q., Deng, Z., Lin, H., Han, X., Liang, Q., Cao, B., and Sun, L. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases. InarXiv preprint arXiv:2306.05301,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., et al. Llama 2: Open foundation and fine-tuned chat models. InarXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Solving math word problems with process- and outcome-based feedback
Uesato, J., Kushman, N., Kumar, R., Song, F., Siegel, N., Wang, L., Creswell, A., Irving, G., and Higgins, I. Solv- ing math word problems with process-and outcome-based feedback. InarXiv preprint arXiv:2211.14275,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, G., Xie, Y ., Jiang, Y ., Mandlekar, A., Xiao, C., Zhu, Y ., Fan, L., and Anandkumar, A. V oyager: An open- ended embodied agent with large language models. In arXiv preprint arXiv:2305.16291, 2023a. Wang, J. and Duan, Z. Agent ai with langgraph: A modular framework for enhancing machine translation using large language models. InarXiv preprint arXi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Wang, X., Hu, Z., Lu, P., Zhu, Y ., Zhang, J., Subramaniam, S., Loomba, A. R., Zhang, S., Sun, Y ., and Wang, W. Scibench: Evaluating college-level scientific problem- solving abilities of large language models. InarXiv preprint arXiv:2307.10635, 2023b. Wang, X., Wang, Z., Liu, J., Chen, Y ., Yuan, L., Peng, H., and Ji, H. Mint: Evaluating llms in multi-t...
work page internal anchor Pith review arXiv
-
[24]
Agentrm: Enhancing agent generalization with reward modeling
Xia, Y ., Fan, J., Chen, W., Yan, S., Cong, X., Zhang, Z., Lu, Y ., Lin, Y ., Liu, Z., and Sun, M. Agentrm: Enhancing agent generalization with reward modeling. InarXiv preprint arXiv:2502.18407,
-
[25]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. InarXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Matplotagent: Method and evaluation for llm-based agentic scientific data visualization
Yang, Z., Zhou, Z., Wang, S., Cong, X., Han, X., Yan, Y ., Liu, Z., Tan, Z., Liu, P., Yu, D., Liu, Z., Shi, X., and Sun, M. Matplotagent: Method and evaluation for llm-based agentic scientific data visualization. InarXiv preprint arXiv:2402.11453,
-
[27]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y ., and Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models. InarXiv preprint arXiv:2305.10601, 2023a. Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y . React: Synergizing reasoning and act- ing in language models. InInternational ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
GLM-130B: An Open Bilingual Pre-trained Model
Zeng, A., Liu, X., Du, Z., Wang, Z., Lai, H., Ding, M., Yang, Z., Xu, Y ., Zheng, W., Xia, X., et al. Glm-130b: An open bilingual pre-trained model. InarXiv preprint arXiv:2210.02414,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
BERTScore: Evaluating Text Generation with BERT
12 AgentXRay: White-Boxing Agentic Systems via Workflow Reconstruction Zhang, J., Xiang, J., Yu, Z., Teng, F., Chen, X., Chen, J., Zhuge, M., Cheng, X., Hong, S., Wang, J., Zheng, B., Liu, B., Luo, Y ., and Wu, C. AFlow: Automating agentic workflow generation. InInternational Conference on Learning Representations (ICLR), 2025a. Zhang, T., Kishore, V ., W...
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[30]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Zhou, S., Xu, F. F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y ., Fried, D., et al. Webarena: A realistic web environment for building autonomous agents. InarXiv preprint arXiv:2307.13854,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.