Recognition: 2 theorem links
· Lean TheoremMicroBi-ConvLSTM: An Ultra-Lightweight Efficient Model for Human Activity Recognition on Resource Constrained Devices
Pith reviewed 2026-05-16 07:14 UTC · model grok-4.3
The pith
MicroBi-ConvLSTM deploys successfully on all eight HAR benchmarks across both Pico 2 and ESP32 microcontrollers with an average of 11.4K parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
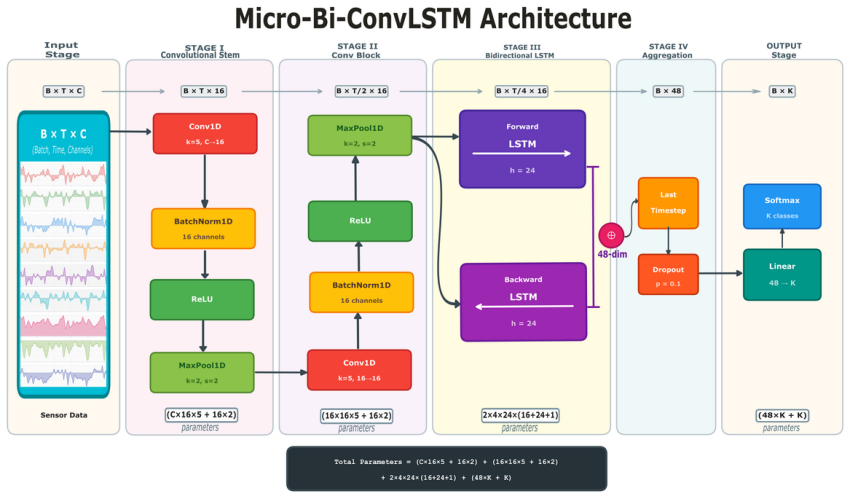
MicroBi-ConvLSTM achieves full 8/8 dataset coverage on Raspberry Pi Pico 2 and ESP32 by reducing to 11.4K parameters on average through two-stage convolutional feature extraction with 4x temporal pooling and a single bidirectional LSTM layer, while preserving linear O(N) complexity and delivering 93.41 percent macro F1 on UCI-HAR, 94.46 percent on SKODA, and 88.98 percent on Daphnet together with 72.8 ms average latency on Pico 2 and 97.9 percent PyTorch parity on ESP32.
What carries the argument
two-stage convolutional feature extraction with 4x temporal pooling followed by a single bidirectional LSTM layer
If this is right
- The architecture fits inside the SRAM budgets of common microcontrollers where TinierHAR and TinyHAR exceed limits after OS overhead.
- Bidirectionality improves detection of episodic events such as gait freeze while adding little value on steady locomotion tasks.
- Linear time complexity is retained while cutting parameters by roughly 2.9 times compared with TinierHAR.
- The model provides the first architecture shown to reach complete coverage across the full set of eight benchmarks on both tested platforms.
Where Pith is reading between the lines
- The same lightweight structure could support always-on activity tracking in low-cost wearables that never connect to the cloud.
- If the eight benchmarks capture the main real-world patterns, the approach may transfer to other sensor streams such as environmental monitoring with only minor retraining.
- Further tests on additional microcontroller variants would clarify whether the reported latency and parity numbers generalize beyond the two platforms examined.
Load-bearing premise
The reported parameter counts and accuracy figures continue to hold once operating-system overhead is added on the target microcontrollers and the eight chosen benchmarks are representative of real-world use without further tuning.
What would settle it
Running the model on the Raspberry Pi Pico 2 or ESP32 and finding either fewer than eight fully working datasets or average latency above the stated 72.8 ms on Pico 2 would disprove the full-deployment claim.
Figures





read the original abstract
Human Activity Recognition (HAR) on resource constrained wearables requires models that balance accuracy against strict memory and computational budgets. State of the art lightweight architectures such as TinierHAR (34K parameters), and TinyHAR (55K parameters) achieve strong accuracy, but exceed memory budgets of microcontrollers with limited SRAM once operating system overhead is considered. We present MicroBi-ConvLSTM, an ultra-lightweight convolutional recurrent architecture achieving 11.4K parameters on average through two stage convolutional feature extraction with 4x temporal pooling, and a single bidirectional LSTM layer. This represents 2.9x parameter reduction versus TinierHAR, and 11.9x versus DeepConvLSTM while preserving linear O(N) complexity. Evaluation across eight diverse HAR benchmarks shows that MicroBi-ConvLSTM maintains competitive performance within the ultra-lightweight regime: 93.41% macro F1 on UCI-HAR, 94.46% on SKODA assembly gestures, and 88.98% on Daphnet gait freeze detection. Systematic ablation reveals task dependent component contributions where bidirectionality benefits episodic event detection, but provides marginal gains on periodic locomotion. On-device deployment on the Raspberry Pi Pico 2 and ESP32 validates hardware viability: MicroBi-ConvLSTM is the only architecture achieving full 8/8 dataset coverage on both platforms, with 72.8 ms average latency on Pico 2 and 97.9% PyTorch parity on ESP32, while all three baselines show partial or complete deployment failure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MicroBi-ConvLSTM, an ultra-lightweight convolutional recurrent architecture with an average of 11.4K parameters that uses two-stage convolutional feature extraction with 4x temporal pooling and a single bidirectional LSTM layer. It claims competitive accuracy on eight HAR benchmarks (e.g., 93.41% macro F1 on UCI-HAR, 94.46% on SKODA, 88.98% on Daphnet) while achieving linear O(N) complexity, a 2.9x parameter reduction versus TinierHAR, and unique full 8/8 deployment success on both Raspberry Pi Pico 2 (72.8 ms average latency) and ESP32 (97.9% PyTorch parity), where the three baselines exhibit partial or complete failure.
Significance. If the deployment viability claims hold after accounting for system overhead, the work would be significant for enabling accurate HAR on severely memory-constrained microcontrollers. The extensive evaluation across eight diverse benchmarks, systematic ablations on bidirectionality, and direct hardware deployment measurements provide a strong empirical foundation that strengthens the case for ultra-lightweight models in real-world wearable applications.
major comments (1)
- [Hardware deployment evaluation] Hardware deployment evaluation: The headline claim that MicroBi-ConvLSTM is the only architecture achieving full 8/8 dataset coverage on both Pico 2 and ESP32 is load-bearing for the superiority argument. However, the manuscript reports no peak SRAM figures that include operating-system overhead (stack, heap, DMA buffers, or runtime allocations) for any model. Without these measurements it remains unclear whether the 2.9x parameter reduction actually enables deployability or whether overhead is comparable across models.
minor comments (2)
- [Abstract] Abstract: Limited detail is provided on the training procedure, exact hyperparameter search, and whether reported accuracy differences are statistically significant.
- [Results tables] Results tables: Consider reporting standard deviations or confidence intervals alongside the macro F1 scores to allow readers to assess the reliability of the cross-model comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the major comment below and will revise the manuscript to incorporate the requested measurements.
read point-by-point responses
-
Referee: Hardware deployment evaluation: The headline claim that MicroBi-ConvLSTM is the only architecture achieving full 8/8 dataset coverage on both Pico 2 and ESP32 is load-bearing for the superiority argument. However, the manuscript reports no peak SRAM figures that include operating-system overhead (stack, heap, DMA buffers, or runtime allocations) for any model. Without these measurements it remains unclear whether the 2.9x parameter reduction actually enables deployability or whether overhead is comparable across models.
Authors: We agree that reporting peak SRAM usage including OS overhead would provide stronger evidence for the deployability claims. The manuscript currently emphasizes successful full deployment outcomes and latency but omits these detailed breakdowns. In the revised manuscript we will add peak memory measurements (including stack, heap, DMA buffers, and runtime allocations) for all models on both platforms, obtained via platform-specific profilers such as Pico SDK memory statistics and ESP-IDF heap tracing. These additions will clarify the role of the 2.9x parameter reduction in enabling full deployment. revision: yes
Circularity Check
No circularity: architecture and results are self-contained empirical claims
full rationale
The paper defines MicroBi-ConvLSTM explicitly via two-stage conv feature extraction, 4x temporal pooling, and one bidirectional LSTM layer, then directly counts parameters as 11.4K from that definition. Accuracies, F1 scores, latency, and 8/8 deployment coverage are reported as measured outcomes on eight benchmarks and two MCUs, with no fitted parameters renamed as predictions, no self-citation chains justifying uniqueness theorems, and no ansatz smuggled in. The derivation chain consists of architectural choices followed by independent empirical validation; baseline failures are presented as comparative measurements rather than self-referential reductions. No step reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- convolutional filter counts and kernel sizes
- LSTM hidden dimension
axioms (1)
- domain assumption Sensor time-series from the eight benchmarks are representative of real-world HAR tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage convolutional feature extraction with 4× temporal pooling and a single bidirectional LSTM layer... 11.4K parameters... O(N) complexity
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MicroBi-ConvLSTM is the only architecture achieving full 8/8 dataset coverage... 72.8 ms average latency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition,
F. J. Ord ´o˜nez and D. Roggen, “Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition,”Sensors, vol. 16, no. 1, p. 115, 2016
work page 2016
-
[2]
TinyHAR: A lightweight deep learning model designed for human activity recognition,
Y . Zhou, H. Zhao, Y . Huang, T. Radu, M. Constantinides, and S. Mehro- tra, “TinyHAR: A lightweight deep learning model designed for human activity recognition,” inProc. ACM Int. Symp. Wearable Comput., 2022, pp. 89–93
work page 2022
-
[3]
S. Bian, M. Liu, V . F. Rey, D. Geissler, and P. Lukowicz, “TinierHAR: Towards ultra-lightweight deep learning models for efficient human activity recognition on edge devices,” inProc. ACM Int. Joint Conf. Pervasive Ubiquitous Comput., 2025
work page 2025
-
[4]
Ensembles of deep LSTM learners for activity recognition using wearables,
Y . Guan and T. Pl ¨otz, “Ensembles of deep LSTM learners for activity recognition using wearables,”Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., vol. 1, no. 2, pp. 1–28, 2017
work page 2017
-
[5]
Deep, convolutional, and recurrent models for human activity recognition using wearables,
N. Y . Hammerla, S. Halloran, and T. Pl ¨otz, “Deep, convolutional, and recurrent models for human activity recognition using wearables,” in Proc. Int. Joint Conf. Artif. Intell., 2016, pp. 1533–1540
work page 2016
-
[6]
Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities,
K. Chen, D. Zhang, L. Yao, B. Guo, Z. Yu, and Y . Liu, “Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities,”ACM Comput. Surv., vol. 54, no. 4, pp. 1–40, 2021
work page 2021
-
[7]
Deep learning for health informatics,
D. Ravi, C. Wong, B. Lo, and G.-Z. Yang, “Deep learning for health informatics,”IEEE J. Biomed. Health Inform., vol. 21, no. 1, pp. 4–21, 2017
work page 2017
-
[8]
Real-time human activity recognition from accelerometer data using convolutional neural networks,
A. Ignatov, “Real-time human activity recognition from accelerometer data using convolutional neural networks,”Appl. Soft Comput., vol. 62, pp. 915–922, 2018
work page 2018
-
[9]
A tutorial on human activity recognition using body-worn inertial sensors,
A. Bulling, U. Blanke, and B. Schiele, “A tutorial on human activity recognition using body-worn inertial sensors,”ACM Comput. Surv., vol. 46, no. 3, pp. 1–33, 2014
work page 2014
-
[10]
Activity recognition using cell phone accelerometers,
J. R. Kwapisz, G. M. Weiss, and S. A. Moore, “Activity recognition using cell phone accelerometers,”ACM SIGKDD Explor. Newsl., vol. 12, no. 2, pp. 74–82, 2011
work page 2011
-
[11]
A public domain dataset for human activity recognition using smartphones,
D. Anguita, A. Ghio, L. Oneto, X. Parra, and J. L. Reyes-Ortiz, “A public domain dataset for human activity recognition using smartphones,” in Proc. Eur. Symp. Artif. Neural Netw., 2013, pp. 437–442
work page 2013
-
[12]
Mobile sensor data anonymization,
M. Malekzadeh, R. G. Clegg, A. Cavallaro, and H. Haddadi, “Mobile sensor data anonymization,” inProc. ACM/IEEE Int. Conf. Internet Things Design Implement., 2019, pp. 49–58
work page 2019
-
[13]
The Opportunity challenge: A bench- mark database for on-body sensor-based activity recognition,
R. Chavarriaga, H. Sagha, A. Calatroni, S. T. Digumarti, G. Tr ¨oster, J. d. R. Mill ´an, and D. Roggen, “The Opportunity challenge: A bench- mark database for on-body sensor-based activity recognition,”Pattern Recognit. Lett., vol. 34, no. 15, pp. 2033–2042, 2013
work page 2033
-
[14]
Wearable activity tracking in car manufacturing,
T. Stiefmeier, D. Roggen, G. Ogris, P. Lukowicz, and G. Tr ¨oster, “Wearable activity tracking in car manufacturing,”IEEE Pervasive Comput., vol. 7, no. 2, pp. 42–50, 2008
work page 2008
-
[15]
Wearable assistant for Parkinson’s disease patients with the freezing of gait symptom,
M. B ¨achlin, M. Plotnik, D. Roggen, I. Maidan, J. M. Hausdorff, N. Giladi, and G. Tr ¨oster, “Wearable assistant for Parkinson’s disease patients with the freezing of gait symptom,”IEEE Trans. Inf. Technol. Biomed., vol. 14, no. 2, pp. 436–446, 2010
work page 2010
-
[16]
Introducing a new benchmarked dataset for activity monitoring,
A. Reiss and D. Stricker, “Introducing a new benchmarked dataset for activity monitoring,” inProc. Int. Symp. Wearable Comput., 2012, pp. 108–109
work page 2012
-
[17]
UniMiB SHAR: A dataset for human activity recognition using acceleration data from smartphones,
D. Micucci, M. Mobilio, and P. Napoletano, “UniMiB SHAR: A dataset for human activity recognition using acceleration data from smartphones,”Appl. Sci., vol. 7, no. 10, p. 1101, 2017
work page 2017
-
[18]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. Int. Conf. Learn. Represent., 2019
work page 2019
-
[19]
Optuna: A next-generation hyperparameter optimization framework,
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A next-generation hyperparameter optimization framework,” inProc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Mining, 2019, pp. 2623–2631
work page 2019
-
[20]
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Comput., vol. 9, no. 8, pp. 1735–1780, 1997
work page 1997
-
[21]
Speech recognition with deep recurrent neural networks,
A. Graves, A.-r. Mohamed, and G. Hinton, “Speech recognition with deep recurrent neural networks,” inProc. IEEE Int. Conf. Acoust. Speech Signal Process., 2013, pp. 6645–6649
work page 2013
-
[22]
Bidirectional recurrent neural net- works,
M. Schuster and K. K. Paliwal, “Bidirectional recurrent neural net- works,”IEEE Trans. Signal Process., vol. 45, no. 11, pp. 2673–2681, 1997
work page 1997
-
[23]
Batch normalization: Accelerating deep network training by reducing internal covariate shift,
S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” inProc. Int. Conf. Mach. Learn., 2015, pp. 448–456
work page 2015
-
[24]
Dropout: A simple way to prevent neural networks from over- fitting,
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhut- dinov, “Dropout: A simple way to prevent neural networks from over- fitting,”J. Mach. Learn. Res., vol. 15, no. 1, pp. 1929–1958, 2014
work page 1929
-
[25]
Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification,
K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification,” in Proc. IEEE Int. Conf. Comput. Vis., 2015, pp. 1026–1034
work page 2015
-
[26]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inProc. Int. Conf. Learn. Represent., 2015
work page 2015
-
[27]
Quantization and training of neural networks for efficient integer-arithmetic-only inference,
B. Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard, H. Adam, and D. Kalenichenko, “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 2704–2713
work page 2018
-
[28]
Quantizing deep convolutional networks for efficient inference: A whitepaper
R. Krishnamoorthi, “Quantizing deep convolutional networks for effi- cient inference,”arXiv preprint arXiv:1806.08342, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
C. R. Banbury, V . J. Reddi, M. Lam, W. Fu, A. Faber, M. Mattina, P. Whatmough, L. Lee, H. Tiber, D. Wijayasinghe,et al., “MLPerf Tiny benchmark,” inProc. NeurIPS Datasets Benchmarks Track, 2021
work page 2021
-
[30]
P. Warden and D. Situnayake,TinyML: Machine Learning with Tensor- Flow Lite on Arduino and Ultra-Low-Power Microcontrollers. O’Reilly Media, 2019
work page 2019
-
[31]
MCUNet: Tiny deep learning on IoT devices,
J. Lin, W.-M. Chen, Y . Lin, J. Cohn, C. Gan, and S. Han, “MCUNet: Tiny deep learning on IoT devices,” inProc. Adv. Neural Inf. Process. Syst., 2020, pp. 11711–11722
work page 2020
-
[32]
CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs
L. Lai, N. Suda, and V . Chandra, “CMSIS-NN: Efficient neural networks on ARM Cortex-M CPUs,”arXiv preprint arXiv:1801.06601, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
A. Abedin, M. Ehsanpour, Q. Shi, H. Rezatofighi, and D. C. Ranasinghe, “Attend and discriminate: Beyond the state-of-the-art for human activity recognition using wearable sensors,”Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., vol. 5, no. 1, pp. 1–22, 2021
work page 2021
-
[34]
GlobalFusion: A global attentional deep learning framework for multisensor information fusion,
S. Liu, S. Yao, J. Li, D. Liu, T. Wang, H. Shao, and T. Abdelza- her, “GlobalFusion: A global attentional deep learning framework for multisensor information fusion,”Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., vol. 4, no. 1, pp. 1–27, 2020
work page 2020
-
[35]
AttnSense: Multi-level attention mechanism for multimodal human activity recognition,
H. Ma, W. Li, X. Zhang, S. Gao, and S. Lu, “AttnSense: Multi-level attention mechanism for multimodal human activity recognition,” in Proc. Int. Joint Conf. Artif. Intell., 2019, pp. 3109–3115
work page 2019
-
[36]
On attention models for human activ- ity recognition,
V . S. Murahari and T. Pl ¨otz, “On attention models for human activ- ity recognition,” inProc. ACM Int. Symp. Wearable Comput., 2018, pp. 100–103
work page 2018
-
[37]
Y . Zhou, T. King, H. Zhao, Y . Huang, T. Riedel, and M. Beigl, “MLP- HAR: Boosting performance and efficiency of HAR models on edge devices with purely fully connected layers,” inProc. ACM Int. Symp. Wearable Comput., 2024, pp. 133–139
work page 2024
-
[38]
LHAR: Lightweight human activity recognition on knowledge distilla- tion,
S. Deng, J. Chen, D. Teng, C. Yang, D. Chen, T. Jia, and H. Wang, “LHAR: Lightweight human activity recognition on knowledge distilla- tion,”IEEE J. Biomed. Health Inform., 2023
work page 2023
-
[39]
M.-K. Yi, W.-K. Lee, and S. O. Hwang, “A human activity recognition method based on lightweight feature extraction combined with pruned and quantized CNN for wearable device,”IEEE Trans. Consum. Elec- tron., vol. 69, no. 3, pp. 657–670, 2023
work page 2023
-
[40]
W.-S. Lim, W. Seo, D.-W. Kim, and J. Lee, “Efficient human activity recognition using lookup table-based neural architecture search for mobile devices,”IEEE Access, vol. 11, pp. 71727–71738, 2023
work page 2023
-
[41]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inProc. Adv. Neural Inf. Process. Syst., 2017, pp. 5998–6008
work page 2017
-
[42]
Are Transformers a useful tool for tiny devices in human activity recognition?,
E. Lattanzi, L. Calisti, and C. Contoli, “Are Transformers a useful tool for tiny devices in human activity recognition?,” inProc. 8th Int. Conf. Advances Artif. Intell., 2024, pp. 339–344
work page 2024
-
[43]
Improv- ing deep learning for HAR with shallow LSTMs,
M. Bock, A. H ¨olzemann, M. Moeller, and K. Van Laerhoven, “Improv- ing deep learning for HAR with shallow LSTMs,” inProc. Int. Symp. Wearable Comput., 2021, pp. 7–12
work page 2021
-
[44]
A lightweight framework for human activity recognition on wearable devices,
Y . L. Coelho, F. de Assis Souza dos Santos, A. Frizera-Neto, and T. Freire Bastos-Filho, “A lightweight framework for human activity recognition on wearable devices,”IEEE Sensors J., vol. 21, no. 21, pp. 24471–24481, 2021
work page 2021
-
[45]
Human activity recognition with smart- phone sensors using deep learning neural networks,
C. A. Ronao and S.-B. Cho, “Human activity recognition with smart- phone sensors using deep learning neural networks,”Expert Syst. Appl., vol. 59, pp. 235–244, 2016
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.