Recognition: 2 theorem links
· Lean TheoremPANC: Prior-Aware Normalized Cut via Anchor-Augmented Token Graphs
Pith reviewed 2026-05-16 06:38 UTC · model grok-4.3
The pith
Connecting labeled prior tokens to foreground and background anchors steers normalized cut partitions toward target classes in token graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
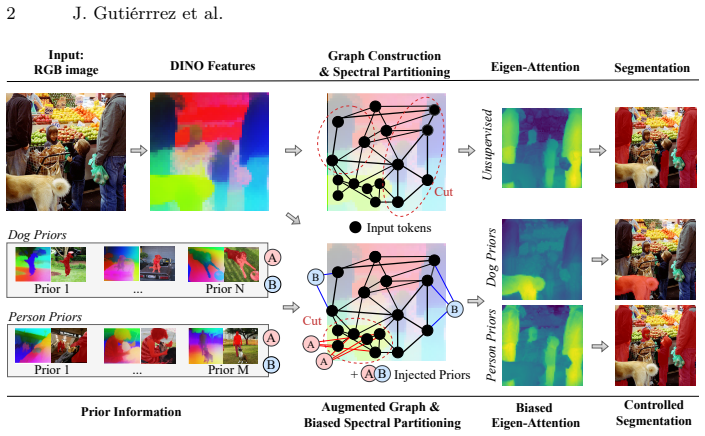
PANC extends the Normalized Cut algorithm by connecting labeled prior tokens to foreground/background anchors, forming an anchor-augmented generalized eigenproblem that steers low-frequency partitions toward the target class while preserving global spectral structure. With prior-aware eigenvector orientation and thresholding, the approach yields stable masks. Spectral diagnostics confirm that injected priors widen eigengaps and stabilize partitions, consistent with the analytical hypotheses. The method reports mIoU gains of +2.3 percent on DUTS-TE, +2.8 percent on DUT-OMRON, and +8.7 percent on CrackForest over strong unsupervised and weakly supervised baselines.
What carries the argument
The anchor-augmented generalized eigenproblem formed by linking labeled prior tokens to foreground and background anchors inside the token graph.
If this is right
- Stable masks emerge in multi-object and low-semantic scenes where standard normalized cut fails.
- User labels directly influence the low-frequency eigenvectors without retraining the underlying vision transformer.
- Eigengap widening occurs consistently enough to improve thresholding reliability.
- Reported mIoU lifts of roughly 2 to 9 percent hold across DUTS-TE, DUT-OMRON, and CrackForest datasets.
- The same anchor construction preserves the global spectral properties of the original graph.
Where Pith is reading between the lines
- The same anchor mechanism could be inserted into other spectral methods that rely on low-frequency eigenvectors, such as graph-based clustering beyond images.
- User steerability might reduce the amount of post-processing needed after vision transformer feature extraction.
- If priors can be generated automatically from simple heuristics, the approach could move closer to fully unsupervised operation while retaining its robustness gains.
- The widening of eigengaps suggests a general way to inject weak supervision into any graph Laplacian eigenproblem.
Load-bearing premise
The injected prior tokens will reliably widen eigengaps and stabilize partitions toward the target class across varied scenes without introducing new artifacts or requiring scene-specific tuning.
What would settle it
A collection of test images in which adding the prior anchors produces narrower eigengaps or masks with higher error than the unaugmented normalized cut baseline.
Figures














read the original abstract
Unsupervised segmentation from self-supervised ViT patches holds promise but lacks robustness: multi-object scenes confound saliency cues, and low-semantic images weaken patch relevance, both leading to erratic masks. To address this, we present Prior-Aware Normalized Cut (PANC), a training-free method that data-efficiently produces consistent, user-steerable segmentations. PANC extends the Normalized Cut algorithm by connecting labeled prior tokens to foreground/background anchors, forming an anchor-augmented generalized eigenproblem that steers low-frequency partitions toward the target class while preserving global spectral structure. With prior-aware eigenvector orientation and thresholding, our approach yields stable masks. Spectral diagnostics confirm that injected priors widen eigengaps and stabilize partitions, consistent with our analytical hypotheses. PANC outperforms strong unsupervised and weakly supervised baselines, achieving mIoU improvements of +2.3% on DUTS-TE, +2.8% on DUT-OMRON, and +8.7% on low-semantic CrackForest datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Prior-Aware Normalized Cut (PANC), a training-free extension of the Normalized Cut algorithm for unsupervised segmentation of self-supervised ViT patches. It augments the token affinity graph by connecting labeled prior tokens to explicit foreground/background anchors, yielding an anchor-augmented generalized eigenproblem whose low-frequency eigenvectors are steered toward the target class while preserving global spectral structure. Prior-aware eigenvector orientation and thresholding then produce the final masks. Spectral diagnostics are reported to confirm eigengap widening, and the method is shown to outperform unsupervised and weakly-supervised baselines with mIoU gains of +2.3% on DUTS-TE, +2.8% on DUT-OMRON, and +8.7% on CrackForest.
Significance. If the reported gains and spectral diagnostics hold under controlled evaluation, PANC would supply a simple, parameter-light mechanism for injecting user-specified priors into spectral segmentation without retraining. The anchor-augmented construction and explicit eigengap analysis constitute a concrete, falsifiable contribution to training-free segmentation methods.
major comments (2)
- [Spectral diagnostics and derivation of the generalized eigenproblem] The central claim that the anchor augmentation widens the relevant eigengap while leaving low-frequency eigenvectors otherwise close to the unaugmented case lacks a perturbation analysis or closed-form bound on the change to the Rayleigh quotient. The abstract and spectral-diagnostics section report increased gaps on test sets, but without this analysis it remains unclear whether the improvement is guaranteed or scene-dependent.
- [Experiments and results tables] The experimental results report mIoU improvements but supply neither error bars across multiple runs nor ablations on the choice and labeling of prior tokens. Without these controls, the headline gains cannot be distinguished from post-hoc selection effects, undermining the claim of robustness across multi-object and low-semantic scenes.
minor comments (2)
- [Method] The exact construction of the augmented affinity matrix (added rows/columns and their weights) should be stated explicitly with equation numbers for reproducibility.
- [Figures] Figure captions for spectral diagnostics should include the unaugmented Normalized Cut baseline for direct visual comparison of eigengap changes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: The central claim that the anchor augmentation widens the relevant eigengap while leaving low-frequency eigenvectors otherwise close to the unaugmented case lacks a perturbation analysis or closed-form bound on the change to the Rayleigh quotient. The abstract and spectral-diagnostics section report increased gaps on test sets, but without this analysis it remains unclear whether the improvement is guaranteed or scene-dependent.
Authors: We agree that a formal perturbation analysis or closed-form bound would strengthen the theoretical grounding. The manuscript presents the anchor-augmented generalized eigenproblem as a direct extension of the standard Normalized Cut formulation, where the added connections to foreground/background anchors modify the affinity matrix to bias the low-frequency eigenvectors. Our spectral diagnostics section empirically shows consistent eigengap widening across the evaluated datasets. In the revision we will add a concise discussion of the expected first-order effects on the Rayleigh quotient induced by the anchor terms, supported by the observed diagnostics, while explicitly noting that the widening is empirically robust rather than provably guaranteed for arbitrary scenes. A full closed-form bound is beyond the current scope and is identified as future work. revision: partial
-
Referee: The experimental results report mIoU improvements but supply neither error bars across multiple runs nor ablations on the choice and labeling of prior tokens. Without these controls, the headline gains cannot be distinguished from post-hoc selection effects, undermining the claim of robustness across multi-object and low-semantic scenes.
Authors: We accept this criticism and will strengthen the experimental validation. The revised manuscript will report mean mIoU together with standard deviations computed over five independent runs that vary the random selection and labeling of prior tokens. We will also insert a dedicated ablation subsection that systematically varies the number of prior tokens (from 1 to 10) and their labeling strategy, reporting the resulting mIoU on all three datasets. These additions will demonstrate that the reported gains remain stable and are not artifacts of post-hoc selection. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper extends the standard Normalized Cut formulation by augmenting the token affinity matrix with explicit connections from labeled prior tokens to foreground/background anchors, then solves the resulting generalized eigenproblem for low-frequency partitions. This construction is presented as a direct algorithmic modification whose effect on eigengaps is verified empirically via spectral diagnostics on held-out test sets (DUTS-TE, DUT-OMRON, CrackForest). No step reduces the claimed steering of partitions or mIoU gains to a quantity defined by the priors themselves, no parameters are fitted and then relabeled as predictions, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The method is training-free with the only free choices being the selection and labeling of prior tokens; the reported improvements therefore rest on external empirical evidence rather than internal redefinition.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PANC extends the Normalized Cut algorithm by connecting labeled prior tokens to foreground/background anchors, forming an anchor-augmented generalized eigenproblem... Spectral diagnostics confirm that injected priors widen eigengaps
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the NCut relaxation solves (D−W)y=λDy... augmented graph ˜G with block affinity ˜W
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Ahn, J., Kwak, S.: Learning pixel-level semantic affinity with image-level super- vision for weakly supervised semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4981–4990 (2018)
work page 2018
- [2]
-
[3]
In: European conference on computer vision
Bearman, A., Russakovsky, O., Ferrari, V., Fei-Fei, L.: What’s the point: Semantic segmentation with point supervision. In: European conference on computer vision. pp. 549–565. Springer (2016)
work page 2016
- [4]
-
[5]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, X., Cai, D.: Large scale spectral clustering with landmark-based represen- tation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 25, pp. 313–318 (2011)
work page 2011
-
[6]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Cho, M., Kwak, S., Schmid, C., Ponce, J.: Unsupervised object discovery and localization in the wild: Part-based matching with bottom-up region proposals. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1201–1210 (2015)
work page 2015
-
[7]
In: Proceedings of the IEEE interna- tional conference on computer vision
Dai, J., He, K., Sun, J.: Boxsup: Exploiting bounding boxes to supervise convolu- tional networks for semantic segmentation. In: Proceedings of the IEEE interna- tional conference on computer vision. pp. 1635–1643 (2015)
work page 2015
- [8]
-
[9]
Everingham,M.,VanGool,L.,Williams,C.K.,Winn,J.,Zisserman,A.:Thepascal visualobjectclasses(voc)challenge.Internationaljournalofcomputervision88(2), 303–338 (2010)
work page 2010
-
[10]
Fu, S., Hamilton, M., Brandt, L., Feldman, A., Zhang, Z., Freeman, W.T.: Featup: A model-agnostic framework for features at any resolution (2024),https://arxiv. org/abs/2403.10516
-
[11]
In: Proceedings of the IEEE/CVF international conference on computer vision
Gao, W., Wan, F., Pan, X., Peng, Z., Tian, Q., Han, Z., Zhou, B., Ye, Q.: Ts-cam: Token semantic coupled attention map for weakly supervised object localization. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2886–2895 (2021)
work page 2021
-
[12]
IEEE transactions on pattern analysis and machine intelligence28(11), 1768–1783 (2006)
Grady, L.: Random walks for image segmentation. IEEE transactions on pattern analysis and machine intelligence28(11), 1768–1783 (2006)
work page 2006
-
[13]
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners (2021),https://arxiv.org/abs/2111.06377
work page internal anchor Pith review arXiv 2021
-
[14]
In: 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition
Joulin, A., Bach, F., Ponce, J.: Discriminative clustering for image co- segmentation. In: 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. pp. 1943–1950. IEEE (2010)
work page 2010
-
[15]
In: 2012 IEEE confer- ence on computer vision and pattern recognition
Joulin, A., Bach, F., Ponce, J.: Multi-class cosegmentation. In: 2012 IEEE confer- ence on computer vision and pattern recognition. pp. 542–549. IEEE (2012)
work page 2012
-
[16]
In: European conference on computer vi- sion
Kolesnikov, A., Lampert, C.H.: Seed, expand and constrain: Three principles for weakly-supervised image segmentation. In: European conference on computer vi- sion. pp. 695–711. Springer (2016) 16 J. Gutiérrrez et al
work page 2016
-
[17]
Computers in Biology and Medicine170, 107988 (2024)
Li, Z., Zhang, N., Gong, H., Qiu, R., Zhang, W.: Sg-mian: Self-guided multiple information aggregation network for image-level weakly supervised skin lesion seg- mentation. Computers in Biology and Medicine170, 107988 (2024)
work page 2024
-
[18]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Lin, D., Dai, J., Jia, J., He, K., Sun, J.: Scribblesup: Scribble-supervised convolu- tional networks for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3159–3167 (2016)
work page 2016
-
[19]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
work page 2014
-
[20]
IEEE Transactions on Image Processing33, 2689– 2702 (2024)
Lv, Y., Zhang, J., Barnes, N., Dai, Y.: Weakly-supervised contrastive learning for unsupervised object discovery. IEEE Transactions on Image Processing33, 2689– 2702 (2024)
work page 2024
-
[21]
IEEE Transactions on Intelligent Transportation Systems25(10), 13926–13936 (2024)
Ma, N., Fan, R., Xie, L.: Up-cracknet: Unsupervised pixel-wise road crack detection via adversarial image restoration. IEEE Transactions on Intelligent Transportation Systems25(10), 13926–13936 (2024)
work page 2024
-
[22]
arXiv preprint arXiv:2105.08127 (2021)
Melas-Kyriazi, L., Rupprecht, C., Laina, I., Vedaldi, A.: Finding an unsuper- vised image segmenter in each of your deep generative models. arXiv preprint arXiv:2105.08127 (2021)
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Melas-Kyriazi, L., Rupprecht, C., Laina, I., Vedaldi, A.: Deep spectral methods: A surprisingly strong baseline for unsupervised semantic segmentation and localiza- tion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8364–8375 (2022)
work page 2022
-
[24]
Advances in neural information processing systems14(2001)
Ng, A., Jordan, M., Weiss, Y.: On spectral clustering: Analysis and an algorithm. Advances in neural information processing systems14(2001)
work page 2001
-
[25]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W.,Howes,R.,Huang,P.Y.,Li,S.W.,Misra,I.,Rabbat,M.,Sharma,V.,Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual features without su...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
In: Proceedings of the IEEE international conference on computer vision
Papandreou, G., Chen, L.C., Murphy, K.P., Yuille, A.L.: Weakly-and semi- supervised learning of a deep convolutional network for semantic image segmenta- tion. In: Proceedings of the IEEE international conference on computer vision. pp. 1742–1750 (2015)
work page 2015
-
[27]
IEEE Open Journal of Signal Processing1, 242– 256 (2020)
Pourkamali-Anaraki, F.: Scalable spectral clustering with nyström approximation: Practical and theoretical aspects. IEEE Open Journal of Signal Processing1, 242– 256 (2020)
work page 2020
-
[28]
ACM transactions on graphics (TOG)23(3), 309–314 (2004)
Rother,C.,Kolmogorov,V.,Blake,A.:"grabcut"interactiveforegroundextraction using iterated graph cuts. ACM transactions on graphics (TOG)23(3), 309–314 (2004)
work page 2004
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shen, X., Efros, A.A., Joulin, A., Aubry, M.: Learning co-segmentation by segment swapping for retrieval and discovery. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5082–5092 (2022)
work page 2022
-
[30]
IEEE Transactions on pattern analysis and machine intelligence22(8), 888–905 (2000)
Shi, J., Malik, J.: Normalized cuts and image segmentation. IEEE Transactions on pattern analysis and machine intelligence22(8), 888–905 (2000)
work page 2000
-
[31]
IEEE transactions on pattern analysis and machine intelligence38(4), 717– 729 (2015)
Shi, J., Yan, Q., Xu, L., Jia, J.: Hierarchical image saliency detection on extended cssd. IEEE transactions on pattern analysis and machine intelligence38(4), 717– 729 (2015)
work page 2015
-
[32]
Shi, Y., Cui, L., Qi, Z., Meng, F., Chen, Z.: Automatic road crack detection us- ing random structured forests. IEEE Transactions on Intelligent Transportation Systems17(12), 3434–3445 (2016) PANC: Prior-Aware Normalized Cut via Anchor-Augmented Token Graphs 17
work page 2016
- [33]
-
[34]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: Dinov3 (2025),https://ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Tang, M., Djelouah, A., Perazzi, F., Boykov, Y., Schroers, C.: Normalized cut loss for weakly-supervised cnn segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1818–1827 (2018)
work page 2018
-
[36]
IEEE transactions on pattern analysis and machine intelligence44(2), 1050–1065 (2020)
Tian, Z., Zhao, H., Shu, M., Yang, Z., Li, R., Jia, J.: Prior guided feature enrich- ment network for few-shot segmentation. IEEE transactions on pattern analysis and machine intelligence44(2), 1050–1065 (2020)
work page 2020
-
[37]
Scientific data5(1), 1–9 (2018)
Tschandl, P., Rosendahl, C., Kittler, H.: The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Scientific data5(1), 1–9 (2018)
work page 2018
-
[38]
Vicente, S., Rother, C., Kolmogorov, V.: Object cosegmentation. In: CVPR 2011. pp. 2217–2224. IEEE (2011)
work page 2011
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Vo, H.V., Bach, F., Cho, M., Han, K., LeCun, Y., Pérez, P., Ponce, J.: Unsu- pervised image matching and object discovery as optimization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8287–8296 (2019)
work page 2019
-
[40]
In: European Conference on Computer Vision
Vo, H.V., Pérez, P., Ponce, J.: Toward unsupervised, multi-object discovery in large-scale image collections. In: European Conference on Computer Vision. pp. 779–795. Springer (2020)
work page 2020
-
[41]
Statistics and computing17(4), 395–416 (2007)
Von Luxburg, U.: A tutorial on spectral clustering. Statistics and computing17(4), 395–416 (2007)
work page 2007
-
[42]
In: International Conference on Machine Learning
Voynov, A., Morozov, S., Babenko, A.: Object segmentation without labels with large-scale generative models. In: International Conference on Machine Learning. pp. 10596–10606. PMLR (2021)
work page 2021
-
[43]
Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: Caltech-ucsd birds- 200-2011. Tech. Rep. CNS-TR-2011-001, California Institute of Technology (2011)
work page 2011
-
[44]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Wang, L., Lu, H., Wang, Y., Feng, M., Wang, D., Yin, B., Ruan, X.: Learning to detect salient objects with image-level supervision. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 136–145 (2017)
work page 2017
-
[45]
Data Mining and Knowledge Discovery28(1), 1–30 (2014)
Wang, X., Qian, B., Davidson, I.: On constrained spectral clustering and its appli- cations. Data Mining and Knowledge Discovery28(1), 1–30 (2014)
work page 2014
- [46]
-
[47]
Engineering Applica- tions of Artificial Intelligence133, 108497 (2024)
Xiang, C., Gan, V.J., Deng, L., Guo, J., Xu, S.: Unified weakly and semi-supervised crack segmentation framework using limited coarse labels. Engineering Applica- tions of Artificial Intelligence133, 108497 (2024)
work page 2024
-
[48]
In: 2009 IEEE Conference on Computer Vision and Pattern Recognition
Xu, L., Li, W., Schuurmans, D.: Fast normalized cut with linear constraints. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition. pp. 2866–
work page 2009
-
[49]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Yang, C., Zhang, L., Lu, H., Ruan, X., Yang, M.H.: Saliency detection via graph- based manifold ranking. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3166–3173 (2013) 18 J. Gutiérrrez et al
work page 2013
-
[50]
Zhou, J., Wei, C., Wang, H., Shen, W., Xie, C., Yuille, A., Kong, T.: ibot: Image bert pre-training with online tokenizer (2022),https://arxiv.org/abs/2111. 07832
work page 2022
-
[51]
In: Proceedings of the 20th International conference on Machine learning (ICML-03)
Zhu, X., Ghahramani, Z., Lafferty, J.D.: Semi-supervised learning using gaussian fields and harmonic functions. In: Proceedings of the 20th International conference on Machine learning (ICML-03). pp. 912–919 (2003) PANC: Prior-Aware Normalized Cut via Anchor-Augmented Token Graphs 19 Supplementary Material A GPU-Accelerated Spectral Partitioning This sect...
work page 2003
-
[52]
For typical usage (e.g.,m≤ 1,500), the overhead is well-managed
Number of Injected Priors (m): We evaluate the impact of augmenting the graph with an increasing number of annotated vertices, scaling fromm= 0 (unsupervised baseline ) up tom= 5,000. For typical usage (e.g.,m≤ 1,500), the overhead is well-managed. However, injecting a massive number of priors (M= 5,000) drastically expands the graph connectivity, resulti...
-
[53]
Resolution Scaling: We evaluate input resolutions scaling from224×224up to1344×1344
-
[54]
Backbone Efficiency: We also benchmark the DINOv3 family against the DINOv2-L standard. Our results indicate that DINOv3-L matches the com- putational footprint of legacy DINOv2-L (306 GFLOPs) while offering im- provements in cross-resolution stability and geometric consistency. Table3:Extendedevaluationofcomputationalresources(GFLOPs)andpeakmemory (MB) u...
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.