Recognition: 2 theorem links
· Lean TheoremFeudalNav: A Simple Framework for Visual Navigation
Pith reviewed 2026-05-16 13:22 UTC · model grok-4.3
The pith
A hierarchical framework uses visual similarity in latent space as a proxy for distance to navigate novel environments without maps or odometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
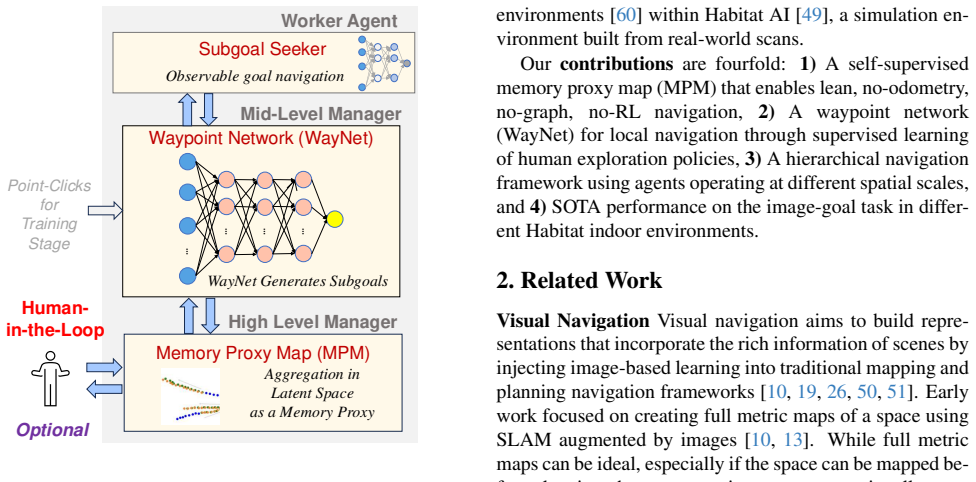
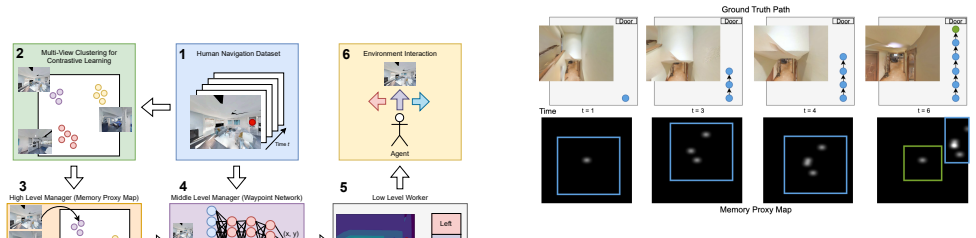
The central claim is that a latent-space memory module organized solely by visual similarity functions as an adequate proxy for distance, allowing a transferable waypoint selection network to decompose navigation into hierarchical decisions that succeed in novel locations without odometry or pre-built maps.
What carries the argument
The latent-space memory module organized by visual similarity, serving as a proxy for distance in place of graph-based topological representations.
If this is right
- The navigator trains and runs without odometry yet matches SOTA performance in Habitat AI environments.
- A simple waypoint network selects subgoals that transfer across different scenes.
- Minimal human directional input during trials raises navigation success rates substantially.
- The framework remains compact and lightweight while supporting interpretability for intervention.
Where Pith is reading between the lines
- The visual-similarity memory could be tested in real-robot settings with camera noise or lighting shifts to check robustness beyond simulation.
- This structure might extend to related tasks such as object search by reusing the same memory organization for different goal types.
- If visual similarity fails in highly symmetric or textureless spaces, adding a lightweight geometric cue could be a minimal fix without reintroducing full maps.
Load-bearing premise
Visual similarity between observations is a sufficient stand-in for actual path distance when choosing navigation subgoals in unseen environments.
What would settle it
A test environment where scenes share high visual similarity yet require long detours or backtracking to reach the goal; if the memory module still guides the agent to success at rates matching or exceeding baselines, the proxy claim holds, otherwise the approach collapses.
Figures



read the original abstract
Visual navigation for robotics is inspired by the human ability to navigate environments using visual cues and memory, eliminating the need for detailed maps. In unseen, unmapped, or GPS-denied settings, traditional metric map-based methods fall short, prompting a shift toward learning-based approaches with minimal exploration. In this work, we develop a hierarchical framework that decomposes the navigation decision-making process into multiple levels. Our method learns to select subgoals through a simple, transferable waypoint selection network. A key component of the approach is a latent-space memory module organized solely by visual similarity, as a proxy for distance. This alternative to graph-based topological representations proves sufficient for navigation tasks, providing a compact, light-weight, simple-to-train navigator that can find its way to the goal in novel locations. We show competitive results with a suite of SOTA methods in Habitat AI environments without using any odometry in training or inference. An additional contribution leverages the interpretablility of the framework for interactive navigation. We consider the question: how much direction intervention/interaction is needed to achieve success in all trials? We demonstrate that even minimal human involvement can significantly enhance overall navigation performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FeudalNav, a hierarchical framework for visual navigation in unseen environments. It decomposes decision-making into levels with a transferable waypoint selection network and a latent-space memory module organized solely by visual similarity as a proxy for distance, avoiding metric maps or odometry. The work claims competitive success rates against SOTA methods in Habitat AI environments and shows that minimal human intervention can further improve performance via the framework's interpretability.
Significance. If the central results hold under rigorous validation, the approach would offer a compact, lightweight, and simple-to-train alternative to graph-based or metric-mapping methods for GPS-denied navigation. The absence of odometry in both training and inference, combined with the interactive navigation component, represents a practical strength for robotics applications. The interpretability for human-in-the-loop use is a clear positive contribution.
major comments (2)
- [Abstract] Abstract: the claim of 'competitive results with a suite of SOTA methods' is presented without any reported baselines, error bars, data splits, or statistical tests, which directly weakens evaluation of the central claim that visual-similarity memory suffices as a distance proxy.
- [Method/Experiments] Method and Experiments sections: the sufficiency of nearest-neighbor lookup in the visual embedding as a distance proxy is load-bearing for the hierarchical policy, yet no ablation isolates performance on high-aliasing versus low-aliasing Habitat scenes (repeated textures, symmetric corridors). This leaves the weakest assumption untested.
minor comments (1)
- [Method] The notation for embedding storage and query in the latent memory module could be made more precise to clarify independence from the navigation objective.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and will revise the manuscript accordingly to strengthen the evaluation and presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'competitive results with a suite of SOTA methods' is presented without any reported baselines, error bars, data splits, or statistical tests, which directly weakens evaluation of the central claim that visual-similarity memory suffices as a distance proxy.
Authors: We appreciate this observation. The Experiments section reports quantitative comparisons against SOTA methods on the Habitat AI benchmark using standard unseen-environment splits, with success rates, error bars from multiple random seeds, and statistical tests. To make the abstract self-contained and directly support the visual-similarity proxy claim, we will revise it to include the key numerical results (e.g., success rate relative to baselines) and a brief reference to the evaluation protocol. This change will improve transparency without altering the core contribution. revision: yes
-
Referee: [Method/Experiments] Method and Experiments sections: the sufficiency of nearest-neighbor lookup in the visual embedding as a distance proxy is load-bearing for the hierarchical policy, yet no ablation isolates performance on high-aliasing versus low-aliasing Habitat scenes (repeated textures, symmetric corridors). This leaves the weakest assumption untested.
Authors: We agree that an explicit ablation on aliasing would strengthen validation of the nearest-neighbor visual-similarity mechanism. While our current Habitat evaluations span diverse scenes that implicitly include both low- and high-aliasing conditions, we did not isolate this variable. In the revised manuscript we will add a targeted ablation that partitions scenes by texture repetition and symmetry metrics, reporting separate success rates for the memory module under high- versus low-aliasing conditions. This will directly test the proxy assumption. revision: yes
Circularity Check
No significant circularity; visual-similarity memory is an explicit architectural choice, not a derived tautology
full rationale
The paper describes a hierarchical policy with a waypoint network and a latent memory module explicitly organized by visual similarity as a proxy for distance. This is presented as a design decision rather than a result derived from equations or fitted parameters that would reduce to the inputs by construction. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided text. The competitive Habitat results are empirical claims, not forced by renaming or ansatz smuggling. A score of 2 accounts for possible minor self-citation that does not carry the central argument.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visual similarity in latent space serves as a sufficient proxy for spatial distance in navigation tasks
Reference graph
Works this paper leans on
-
[1]
Zero experience required: Plug & play modular transfer learning for semantic visual navigation
Ziad Al-Halah, Santhosh Kumar Ramakrishnan, and Kristen Grauman. Zero experience required: Plug & play modular transfer learning for semantic visual navigation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17031–17041, 2022. 2, 4, 5, 6
work page 2022
-
[2]
Navigation world models.arXiv preprint arXiv:2412.03572, 2024
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models.arXiv preprint arXiv:2412.03572, 2024. 2
-
[3]
EgoMap: Projective mapping and structured egocentric memory for Deep RL
Edward Beeching, Jilles Dibangoye, Olivier Simonin, and Christian Wolf. EgoMap: Projective mapping and structured egocentric memory for Deep RL. InJoint European Con- ference on Machine Learning and Knowledge Discovery in Databases, pages 525–540. Springer, 2020. 2
work page 2020
-
[4]
Learning to plan with uncertain topological maps
Edward Beeching, Jilles Dibangoye, Olivier Simonin, and Christian Wolf. Learning to plan with uncertain topological maps. InEuropean Conference on Computer Vision, pages 473–490. Springer, 2020. 8
work page 2020
-
[5]
Guillaume Bono, Leonid Antsfeld, Boris Chidlovskii, Philippe Weinzaepfel, and Christian Wolf. End-to-end (instance)-image goal navigation through correspondence as an emergent phenomenon.arXiv preprint arXiv:2309.16634,
-
[6]
Guillaume Bono, Leonid Antsfeld, Assem Sadek, Gianluca Monaci, and Christian Wolf. Learning with a mole: Trans- ferable latent spatial representations for navigation without reconstruction.arXiv preprint arXiv:2306.03857, 2023. 2
-
[7]
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Pi- otr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments.Ad- vances in neural information processing systems, 33:9912– 9924, 2020. 5, 6
work page 2020
-
[8]
Goal- conditioned reinforcement learning with imagined subgoals
Elliot Chane-Sane, Cordelia Schmid, and Ivan Laptev. Goal- conditioned reinforcement learning with imagined subgoals. InInternational Conference on Machine Learning, pages 1430–1440. PMLR, 2021. 3
work page 2021
-
[9]
Goat: Go to any thing.arXiv preprint arXiv:2311.06430, 2023
Matthew Chang, Theophile Gervet, Mukul Khanna, Sriram Yenamandra, Dhruv Shah, So Yeon Min, Kavit Shah, Chris Paxton, Saurabh Gupta, Dhruv Batra, et al. Goat: Go to any thing.arXiv preprint arXiv:2311.06430, 2023. 2
-
[10]
Learning To Ex- plore Using Active Neural SLAM
Devendra Singh Chaplot, Dhiraj Gandhi, Saurabh Gupta, Abhinav Gupta, and Ruslan Salakhutdinov. Learning To Ex- plore Using Active Neural SLAM. InInternational Confer- ence on Learning Representations, 2019. 1, 2
work page 2019
-
[11]
Learning to ex- plore using active neural slam
Devendra Singh Chaplot, Dhiraj Gandhi, Saurabh Gupta, Abhinav Gupta, and Ruslan Salakhutdinov. Learning to ex- plore using active neural slam. In8th International Confer- ence on Learning Representations, ICLR 2020, 2020. 7, 8
work page 2020
-
[12]
Devendra Singh Chaplot, Dhiraj Prakashchand Gandhi, Ab- hinav Gupta, and Russ R Salakhutdinov. Object goal navi- gation using goal-oriented semantic exploration.Advances in Neural Information Processing Systems, 33:4247–4258,
-
[13]
Neural topological slam for vi- sual navigation
Devendra Singh Chaplot, Ruslan Salakhutdinov, Abhinav Gupta, and Saurabh Gupta. Neural topological slam for vi- sual navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12875– 12884, 2020. 1, 2, 7, 8
work page 2020
-
[14]
A Behavioral Approach to Visual Navigation with Graph Lo- calization Networks
Kevin Chen, Juan Pablo de Vicente, Gabriel Sepulveda, Fei Xia, Alvaro Soto, Marynel Vazquez, and Silvio Savarese. A Behavioral Approach to Visual Navigation with Graph Lo- calization Networks. InProceedings of Robotics: Science and Systems, FreiburgimBreisgau, Germany, 2019. 1
work page 2019
-
[15]
A Behavioral Approach to Visual Navigation with Graph Localization Networks
Kevin Chen, Juan Pablo De Vicente, Gabriel Sepulveda, Fei Xia, Alvaro Soto, Marynel V´azquez, and Silvio Savarese. A behavioral approach to visual navigation with graph local- ization networks.arXiv preprint arXiv:1903.00445, 2019. 2
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[16]
Valerie Chen, Abhinav Gupta, and Kenneth Marino. Ask your humans: Using human instructions to improve gen- eralization in reinforcement learning.arXiv preprint arXiv:2011.00517, 2020. 3
-
[17]
From cognitive maps to cognitive graphs.PloS one, 9(11):e112544, 2014
Elizabeth R Chrastil and William H Warren. From cognitive maps to cognitive graphs.PloS one, 9(11):e112544, 2014. 1
work page 2014
-
[18]
Feudal reinforcement learning.Advances in neural information processing sys- tems, 5, 1992
Peter Dayan and Geoffrey E Hinton. Feudal reinforcement learning.Advances in neural information processing sys- tems, 5, 1992. 1, 2
work page 1992
-
[19]
Alessandro Devo, Giacomo Mezzetti, Gabriele Costante, Mario L Fravolini, and Paolo Valigi. Towards generaliza- tion in target-driven visual navigation by using deep rein- forcement learning.IEEE Transactions on Robotics, 36(5): 1546–1561, 2020. 2
work page 2020
-
[20]
The cognitive map in humans: spatial navi- gation and beyond.Nature neuroscience, 20(11):1504–1513,
Russell A Epstein, Eva Zita Patai, Joshua B Julian, and Hugo J Spiers. The cognitive map in humans: spatial navi- gation and beyond.Nature neuroscience, 20(11):1504–1513,
-
[21]
Ben Eysenbach, Russ R Salakhutdinov, and Sergey Levine. Search on the replay buffer: Bridging planning and rein- forcement learning.Advances in Neural Information Pro- cessing Systems, 32, 2019. 1
work page 2019
-
[22]
Scene memory transformer for embodied agents in long-horizon tasks
Kuan Fang, Alexander Toshev, Li Fei-Fei, and Silvio Savarese. Scene memory transformer for embodied agents in long-horizon tasks. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 538–547, 2019. 2
work page 2019
-
[23]
Scott Fujimoto and Shixiang Shane Gu. A minimalist ap- proach to offline reinforcement learning.Advances in neural information processing systems, 34:20132–20145, 2021. 3
work page 2021
-
[24]
Learning to map for active semantic goal navigation,
Georgios Georgakis, Bernadette Bucher, Karl Schmeck- peper, Siddharth Singh, and Kostas Daniilidis. Learning to map for active semantic goal navigation.arXiv preprint arXiv:2106.15648, 2021. 2
-
[25]
Navigating to objects in the real world.Science Robotics, 8(79), 2023
Theophile Gervet, Soumith Chintala, Dhruv Batra, Jitendra Malik, and Devendra Singh Chaplot. Navigating to objects in the real world.Science Robotics, 8(79), 2023. 1
work page 2023
-
[26]
Cognitive Mapping and Plan- ning for Visual Navigation
Saurabh Gupta, James Davidson, Sergey Levine, Rahul Suk- thankar, and Jitendra Malik. Cognitive Mapping and Plan- ning for Visual Navigation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 1, 2
work page 2017
-
[27]
Meera Hahn, Devendra Singh Chaplot, Shubham Tulsiani, Mustafa Mukadam, James M Rehg, and Abhinav Gupta. No rl, no simulation: Learning to navigate without navigat- ing.Advances in Neural Information Processing Systems, 34:26661–26673, 2021. 1, 2, 4, 5, 6
work page 2021
-
[28]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 4, 5, 6
work page 2016
-
[29]
Momentum contrast for unsupervised visual rep- resentation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual rep- resentation learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9729–9738, 2020. 5, 6
work page 2020
-
[30]
Metric-Free Exploration for Topological Mapping by Task and Motion Imitation in Feature Space
Yuhang He, Irving Fang, Yiming Li, Rushi Bhavesh Shah, and Chen Feng. Metric-Free Exploration for Topological Mapping by Task and Motion Imitation in Feature Space. arXiv preprint arXiv:2303.09192, 2023. 1, 2
-
[31]
Mapnet: An allocen- tric spatial memory for mapping environments
Joao F Henriques and Andrea Vedaldi. Mapnet: An allocen- tric spatial memory for mapping environments. Inproceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8476–8484, 2018. 2
work page 2018
-
[32]
A Landmark-Aware Visual Navigation Dataset.ACM Conference on Human Robot Interaction HRI 2025, 2025
Faith Johnson, Bryan Bo Cao, Kristin Dana, Shubham Jain, and Ashwin Ashok. A Landmark-Aware Visual Navigation Dataset.ACM Conference on Human Robot Interaction HRI 2025, 2025. 2, 3, 4, 5
work page 2025
-
[33]
Topological Semantic Graph Mem- ory for Image-Goal Navigation
Nuri Kim, Obin Kwon, Hwiyeon Yoo, Yunho Choi, Jeongho Park, and Songhwai Oh. Topological Semantic Graph Mem- ory for Image-Goal Navigation. InConference on Robot Learning, pages 393–402. PMLR, 2023. 1, 2, 5
work page 2023
-
[34]
Ashish Kumar, Saurabh Gupta, David Fouhey, Sergey Levine, and Jitendra Malik. Visual memory for robust path following.Advances in neural information processing sys- tems, 31, 2018. 2
work page 2018
-
[35]
Visual graph memory with unsuper- vised representation for visual navigation
Obin Kwon, Nuri Kim, Yunho Choi, Hwiyeon Yoo, Jeongho Park, and Songhwai Oh. Visual graph memory with unsuper- vised representation for visual navigation. InProceedings of the IEEE/CVF international conference on computer vision, pages 15890–15899, 2021. 7, 8
work page 2021
-
[36]
Renderable Neural Radiance Map for Visual Navigation
Obin Kwon, Jeongho Park, and Songhwai Oh. Renderable Neural Radiance Map for Visual Navigation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9099–9108, 2023. 1, 5
work page 2023
-
[37]
Hierarchical imitation and reinforcement learning
Hoang Le, Nan Jiang, Alekh Agarwal, Miroslav Dud ´ık, Yisong Yue, and Hal Daum´e III. Hierarchical imitation and reinforcement learning. InInternational conference on ma- chine learning, pages 2917–2926. PMLR, 2018. 3
work page 2018
-
[38]
Hrl4in: Hierarchical reinforcement learning for interactive navigation with mobile manipulators
Chengshu Li, Fei Xia, Roberto Martin-Martin, and Silvio Savarese. Hrl4in: Hierarchical reinforcement learning for interactive navigation with mobile manipulators. InConfer- ence on Robot Learning, pages 603–616. PMLR, 2020. 3
work page 2020
-
[39]
Memonav: Working memory model for visual navigation
Hongxin Li, Zeyu Wang, Xu Yang, Yuran Yang, Shuqi Mei, and Zhaoxiang Zhang. Memonav: Working memory model for visual navigation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 17913–17922, 2024. 7, 8
work page 2024
-
[40]
Memory-augmented reinforcement learning for image-goal navigation
Lina Mezghan, Sainbayar Sukhbaatar, Thibaut Lavril, Olek- sandr Maksymets, Dhruv Batra, Piotr Bojanowski, and Kar- teek Alahari. Memory-augmented reinforcement learning for image-goal navigation. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3316–3323. IEEE, 2022. 2, 8
work page 2022
-
[41]
Piotr Mirowski, Matt Grimes, Mateusz Malinowski, Karl Moritz Hermann, Keith Anderson, Denis Teplyashin, Karen Simonyan, Andrew Zisserman, Raia Hadsell, et al. Learning to navigate in cities without a map.Advances in neural information processing systems, 31, 2018. 1
work page 2018
-
[42]
One- 4-All: Neural Potential Fields for Embodied Navigation
Sacha Morin, Miguel Saavedra-Ruiz, and Liam Paull. One- 4-All: Neural Potential Fields for Embodied Navigation. arXiv preprint arXiv:2303.04011, 2023. 2
-
[43]
Unsupervised visual representation learning by synchronous momentum grouping
Bo Pang, Yifan Zhang, Yaoyi Li, Jia Cai, and Cewu Lu. Unsupervised visual representation learning by synchronous momentum grouping. InEuropean Conference on Computer Vision, pages 265–282. Springer, 2022. 3, 4, 5, 6
work page 2022
-
[44]
Michael Peer, Iva K Brunec, Nora S Newcombe, and Rus- sell A Epstein. Structuring knowledge with cognitive maps and cognitive graphs.Trends in cognitive sciences, 25(1): 37–54, 2021. 1
work page 2021
-
[45]
Envi- ronment predictive coding for visual navigation.ICLR 2022,
Santhosh Kumar Ramakrishnan and Tushar Nagarajan. Envi- ronment predictive coding for visual navigation.ICLR 2022,
work page 2022
-
[46]
Poni: Potential functions for objectgoal navigation with interaction-free learning
Santhosh Kumar Ramakrishnan, Devendra Singh Chap- lot, Ziad Al-Halah, Jitendra Malik, and Kristen Grauman. Poni: Potential functions for objectgoal navigation with interaction-free learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18890–18900, 2022. 2
work page 2022
-
[47]
Superglue: Learning feature matching with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938–4947, 2020. 3, 4
work page 2020
-
[48]
Semi-parametric Topological Memory for Navigation
Nikolay Savinov, Alexey Dosovitskiy, and Vladlen Koltun. Semi-parametric topological memory for navigation.arXiv preprint arXiv:1803.00653, 2018. 1, 2, 8
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[49]
Habitat: A Platform for Embodied AI Research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A Platform for Embodied AI Research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019. 2, 7
work page 2019
-
[50]
Maast: Map attention with semantic transformers for effi- cient visual navigation
Zachary Seymour, Kowshik Thopalli, Niluthpol Mithun, Han-Pang Chiu, Supun Samarasekera, and Rakesh Kumar. Maast: Map attention with semantic transformers for effi- cient visual navigation. In2021 IEEE International Con- ference on Robotics and Automation (ICRA), pages 13223– 13230. IEEE, 2021. 2
work page 2021
-
[51]
Ving: Learning open- world navigation with visual goals
Dhruv Shah, Benjamin Eysenbach, Gregory Kahn, Nicholas Rhinehart, and Sergey Levine. Ving: Learning open- world navigation with visual goals. In2021 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 13215–13222. IEEE, 2021. 1, 2
work page 2021
-
[52]
Rapid exploration for open-world navigation with latent goal models.arXiv preprint arXiv:2104.05859,
Dhruv Shah, Benjamin Eysenbach, Nicholas Rhinehart, and Sergey Levine. Rapid exploration for open-world navigation with latent goal models.arXiv preprint arXiv:2104.05859,
-
[53]
Offline reinforce- ment learning for visual navigation.arXiv preprint arXiv:2212.08244, 2022
Dhruv Shah, Arjun Bhorkar, Hrish Leen, Ilya Kostrikov, Nick Rhinehart, and Sergey Levine. Offline reinforce- ment learning for visual navigation.arXiv preprint arXiv:2212.08244, 2022. 2
-
[54]
Cognitive maps in rats and men.Psycho- logical review, 55(4):189, 1948
Edward C Tolman. Cognitive maps in rats and men.Psycho- logical review, 55(4):189, 1948. 1
work page 1948
-
[55]
Options as responses: Grounding behavioural hierarchies in multi-agent reinforcement learn- ing
Alexander Vezhnevets, Yuhuai Wu, Maria Eckstein, R ´emi Leblond, and Joel Z Leibo. Options as responses: Grounding behavioural hierarchies in multi-agent reinforcement learn- ing. InInternational Conference on Machine Learning, pages 9733–9742. PMLR, 2020. 3
work page 2020
-
[56]
Feudal networks for hierarchical reinforce- ment learning
Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. Feudal networks for hierarchical reinforce- ment learning. InInternational Conference on Machine Learning, pages 3540–3549. PMLR, 2017. 1, 2, 3
work page 2017
-
[57]
Last-mile embodied visual navigation
Justin Wasserman, Karmesh Yadav, Girish Chowdhary, Ab- hinav Gupta, and Unnat Jain. Last-mile embodied visual navigation. InConference on Robot Learning, pages 666–
-
[58]
Erik Wijmans, Abhishek Kadian, Ari Morcos, Stefan Lee, Irfan Essa, Devi Parikh, Manolis Savva, and Dhruv Batra. Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames.International Conference on Learning Rep- resentations, 2019. 1, 4, 5, 6
work page 2019
-
[59]
Hierarchies of planning and reinforcement learning for robot navigation
Jan W ¨ohlke, Felix Schmitt, and Herke van Hoof. Hierarchies of planning and reinforcement learning for robot navigation. In2021 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 10682–10688. IEEE, 2021. 3
work page 2021
-
[60]
Zamir, Zhi-Yang He, Alexander Sax, Jiten- dra Malik, and Silvio Savarese
Fei Xia, Amir R. Zamir, Zhi-Yang He, Alexander Sax, Jiten- dra Malik, and Silvio Savarese. Gibson env: real-world per- ception for embodied agents. InComputer Vision and Pat- tern Recognition (CVPR), 2018 IEEE Conference on. IEEE,
work page 2018
-
[61]
Chengguang Xu, Christopher Amato, and Lawson LS Wong. Hierarchical robot navigation in novel environments using rough 2-d maps.arXiv preprint arXiv:2106.03665, 2021. 3
-
[62]
Karmesh Yadav, Ram Ramrakhya, Arjun Majumdar, Vincent-Pierre Berges, Sachit Kuhar, Dhruv Batra, Alexei Baevski, and Oleksandr Maksymets. Offline visual repre- sentation learning for embodied navigation.arXiv preprint arXiv:2204.13226, 2022. 4, 5, 6
-
[63]
Habitat Challenge 2023.https: //aihabitat.org/challenge/2023/, 2023
Karmesh Yadav, Jacob Krantz, Ram Ramrakhya, San- thosh Kumar Ramakrishnan, Jimmy Yang, Austin Wang, John Turner, Aaron Gokaslan, Vincent-Pierre Berges, Roozbeh Mootaghi, Oleksandr Maksymets, Angel X Chang, Manolis Savva, Alexander Clegg, Devendra Singh Chap- lot, and Dhruv Batra. Habitat Challenge 2023.https: //aihabitat.org/challenge/2023/, 2023. 1
work page 2023
-
[64]
Target-driven vi- sual navigation in indoor scenes using deep reinforcement learning
Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J Lim, Ab- hinav Gupta, Li Fei-Fei, and Ali Farhadi. Target-driven vi- sual navigation in indoor scenes using deep reinforcement learning. In2017 IEEE international conference on robotics and automation (ICRA), pages 3357–3364. IEEE, 2017. 2
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.