Recognition: 2 theorem links
· Lean TheoremCyclic Adaptive Private Synthesis for Sharing Real-World Data in Education
Pith reviewed 2026-05-16 06:10 UTC · model grok-4.3
The pith
Cyclic Adaptive Private Synthesis enables repeated private sharing of high-dimensional educational data with higher utility than one-shot methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying adaptive private synthesis iteratively across sharing cycles, CAPS produces synthetic versions of real educational data that retain greater analytical utility than a single one-shot generation, as measured in evaluations on authentic high-dimensional datasets, thereby enabling continual secondary use for learning analytics while respecting privacy constraints.
What carries the argument
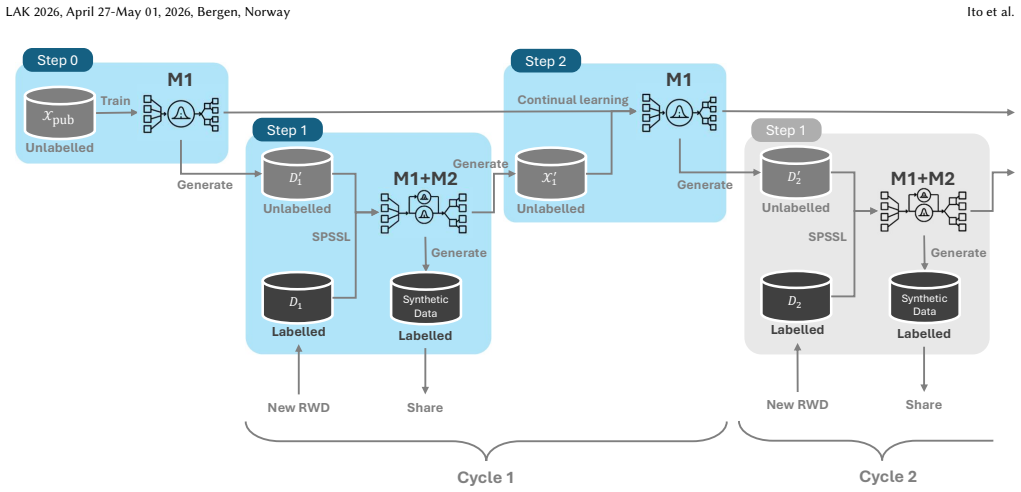
Cyclic Adaptive Private Synthesis (CAPS) framework, which performs iterative refinement of differentially private synthetic data releases to accommodate repeated sharing needs in educational practice.
If this is right
- Allows continual data sharing that supports open science and design-based research in learning analytics.
- Delivers higher utility than one-shot synthesis when evaluated on real educational RWD.
- Opens pathways for repeated private access while maintaining differential privacy guarantees.
- Surfaces specific challenges in high-dimensional small-sample settings that require further refinement.
Where Pith is reading between the lines
- The cyclic approach could be tested on other small-sample sensitive domains such as clinical records.
- Cycle count and adaptation rules might be tuned to keep cumulative privacy expenditure low.
- Performance gains may vary with dataset dimensionality, suggesting targeted experiments on different educational collections.
Load-bearing premise
Iterative adaptation across cycles can preserve analytical utility without accumulating excessive privacy loss or adding new biases in small high-dimensional educational datasets.
What would settle it
Showing that utility scores on the actual RWD case study drop below the one-shot baseline after several CAPS cycles or that the total privacy budget exceeds the target bound.
Figures


read the original abstract
The rapid adoption of digital technologies has greatly increased the volume of real-world data (RWD) in education. While these data offer significant opportunities for advancing learning analytics (LA), secondary use for research is constrained by privacy concerns. Differentially private synthetic data generation is regarded as the gold-standard approach to sharing sensitive data, yet studies on the private synthesis of educational data remain very scarce and rely predominantly on large, low-dimensional open datasets. Educational RWD, however, are typically high-dimensional and small in sample size, leaving the potential of private synthesis underexplored. Moreover, because educational practice is inherently iterative, data sharing is continual rather than one-off, making a traditional one-shot synthesis approach suboptimal. To address these challenges, we propose the Cyclic Adaptive Private Synthesis (CAPS) framework and evaluate it on authentic RWD. By iteratively sharing RWD, CAPS not only fosters open science, but also offers rich opportunities of design-based research (DBR), thereby amplifying the impact of LA. Our case study using actual RWD demonstrates that CAPS outperforms a one-shot baseline while highlighting challenges that warrant further investigation. Overall, this work offers a crucial first step towards privacy-preserving sharing of educational RWD and expands the possibilities for open science and DBR in LA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Cyclic Adaptive Private Synthesis (CAPS) framework for generating differentially private synthetic data from high-dimensional, small-sample educational real-world data (RWD) through iterative cycles rather than one-shot synthesis. It evaluates CAPS on authentic RWD in a case study, claiming superior performance over a one-shot baseline while enabling ongoing data sharing for open science and design-based research in learning analytics.
Significance. If the outperformance claim holds under rigorous privacy composition and bias controls, the work would fill a notable gap in differentially private synthesis for small-n, high-d educational datasets, where one-shot methods are known to be suboptimal. The emphasis on iterative adaptation aligns with the cyclical nature of educational practice and could support reproducible LA research, but the absence of quantitative evaluation details in the provided text limits assessment of its practical impact.
major comments (3)
- [Abstract] Abstract and evaluation description: the central claim that CAPS 'outperforms a one-shot baseline' on authentic RWD is unsupported by any reported metrics, sample sizes, dimensionality, error bars, or statistical tests, rendering the case-study result unverifiable and load-bearing for the paper's contribution.
- [§3 (CAPS Framework)] Framework description: no explicit analysis of privacy budget composition across adaptive cycles (e.g., per-cycle ε allocation or total (ε,δ) via advanced composition theorems) is provided, which is required to substantiate that iterative adaptation does not drive noise levels that collapse utility or introduce selection bias in the high-dimensional, low-sample regime.
- [§4 (Case Study)] Case study: the weakest assumption—that iterative adaptation preserves utility without excessive cumulative privacy loss or new biases—is not addressed via post-adaptation diagnostics such as distribution-shift metrics or subpopulation fairness checks, leaving open the possibility that observed gains are artifacts of baseline under-budgeting.
minor comments (2)
- [§2] Notation for privacy parameters and cycle indices should be defined consistently at first use to avoid ambiguity in the iterative setting.
- [Abstract] The abstract mentions 'challenges that warrant further investigation' but does not enumerate them; a brief list would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which highlight important areas for strengthening the manuscript. We address each major comment point by point below, indicating the revisions we will make to improve clarity, rigor, and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the central claim that CAPS 'outperforms a one-shot baseline' on authentic RWD is unsupported by any reported metrics, sample sizes, dimensionality, error bars, or statistical tests, rendering the case-study result unverifiable and load-bearing for the paper's contribution.
Authors: We agree that the abstract should provide sufficient quantitative context to support the central claim. While the case study in Section 4 reports specific metrics (including utility improvements on downstream tasks, dataset sample size, dimensionality of the educational RWD, and comparisons with error bars), these details are not summarized in the abstract. We will revise the abstract to include key quantitative highlights, such as the observed performance gains, sample size, dimensionality, and reference to statistical comparisons, ensuring the claim is verifiable from the abstract alone. revision: yes
-
Referee: [§3 (CAPS Framework)] Framework description: no explicit analysis of privacy budget composition across adaptive cycles (e.g., per-cycle ε allocation or total (ε,δ) via advanced composition theorems) is provided, which is required to substantiate that iterative adaptation does not drive noise levels that collapse utility or introduce selection bias in the high-dimensional, low-sample regime.
Authors: This is a valid observation. The current description of the CAPS framework outlines the iterative process but lacks a formal privacy composition analysis. In the revised manuscript, we will add a dedicated subsection to Section 3 that specifies per-cycle ε allocation, applies advanced composition theorems (such as the moments accountant) to derive the total (ε, δ) guarantee, and discusses implications for noise levels and potential selection bias in the small-n, high-d regime. This will substantiate that the iterative approach maintains acceptable privacy loss without collapsing utility. revision: yes
-
Referee: [§4 (Case Study)] Case study: the weakest assumption—that iterative adaptation preserves utility without excessive cumulative privacy loss or new biases—is not addressed via post-adaptation diagnostics such as distribution-shift metrics or subpopulation fairness checks, leaving open the possibility that observed gains are artifacts of baseline under-budgeting.
Authors: We acknowledge that additional diagnostics are needed to strengthen the case study. We will expand Section 4 to include post-adaptation analyses, such as distribution-shift metrics (e.g., KL divergence or Wasserstein distance between original and synthetic distributions across cycles) and subpopulation fairness checks (e.g., performance parity across demographic groups in the educational data). We will also explicitly compare the total privacy budgets allocated to CAPS versus the one-shot baseline to address concerns about under-budgeting. These additions will help confirm that the observed gains stem from the cyclic adaptation rather than artifacts. revision: yes
Circularity Check
CAPS framework proposed as novel iterative mechanism and evaluated on real RWD without reduction to fitted inputs or self-referential definitions
full rationale
The paper introduces the Cyclic Adaptive Private Synthesis (CAPS) framework to address limitations of one-shot differentially private synthesis for high-dimensional, small-sample educational RWD. The central claim rests on a case-study demonstration that CAPS outperforms a one-shot baseline. No load-bearing equations, parameter fits, or derivations are described that reduce the outperformance result to the inputs by construction (e.g., no per-cycle epsilon allocation or composition theorem is fitted from the same data and then re-labeled as a prediction). The framework is presented as a new proposal rather than derived from prior self-cited results; external DP composition and synthesis techniques are referenced only as background. The derivation chain is therefore self-contained as an engineering proposal plus empirical evaluation, with no self-definitional, fitted-input, or uniqueness-imported circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Cyclic Adaptive Private Synthesis (CAPS) framework... SPSSL... generative replay... compounding bias effect
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
iteratively sharing RWD... pre-training M1 on surrogate public data
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, 308–318. doi:10.1145/2976749.2978318
-
[2]
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: A Next-generation Hyperparameter Optimization Frame- work. InProceedings of the 25th ACM SIGKDD International Conference on Knowl- edge Discovery & Data Mining. ACM, 2623–2631. doi:10.1145/3292500.3330701
-
[3]
Noga Alon, Raef Bassily, and Shay Moran. 2019. Limits of Private Learning with Access to Public Data. InAdvances in Neural Information Processing Systems, H Wallach, H Larochelle, A Beygelzimer, F d'Alché-Buc, E Fox, and R Garnett (Eds.), Vol. 32. Curran Associates, Inc. https://proceedings.neurips.cc/paper_ files/paper/2019/file/9a6a1aaafe73c572b7374828b...
work page 2019
-
[4]
Ryan S Baker, Stephen Hutt, Christopher A Brooks, Namrata Srivastava, and Caitlin Mills. 2024. Open science and Educational Data Mining: Which practices matter most?. InProceedings of the 17th International Conference on Educational Data Mining. International Educational Data Mining Society, 279–287. doi:10. 5281/ZENODO.12729816
work page 2024
-
[5]
Sasha Barab. 2014. Design-based research: A methodological toolkit for engineer- ing change. InThe Cambridge Handbook of the Learning Sciences, R Keith Sawyer (Ed.). Cambridge University Press, 151–170. doi:10.1017/cbo9781139519526.011
-
[6]
Shai Ben-David, Alex Bie, Clément L Canonne, Gautam Kamath, and Vikrant Singhal. 2023. Private Distribution Learning with Public Data: The View from Sample Compression. InAdvances in Neural Information Processing Systems, A Oh, T Naumann, A Globerson, K Saenko, M Hardt, and S Levine (Eds.), Vol. 36. Curran Associates, Inc., 7184–7215. https://proceedings....
-
[7]
James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. 2011. Algorithms for Hyper-Parameter Optimization. InAdvances in Neural Information Processing Systems, J Shawe-Taylor, R Zemel, P Bartlett, F Pereira, and K Q Weinberger (Eds.), Vol. 24. Curran Associates, Inc. https://proceedings.neurips.cc/paper_ files/paper/2011/file/86e8f7ab32cfd12577bc26...
work page 2011
-
[8]
Ann L Brown. 1992. Design Experiments: Theoretical and Methodological Chal- lenges in Creating Complex Interventions in Classroom Settings.Journal of the Learning Sciences2, 2 (1992), 141–178. doi:10.1207/s15327809jls0202_2
-
[9]
Mark Bun, Marco Gaboardi, Marcel Neunhoeffer, and Wanrong Zhang. 2024. Continual release of differentially private synthetic data from longitudinal data collections.Proceedings of the ACM on management of data2, 2 (2024), 1–26. doi:10.1145/3651595
-
[10]
Christopher P Burgess, Irina Higgins, Arka Pal, Loic Matthey, Nick Watters, Guil- laume Desjardins, and Alexander Lerchner. 2018. Understanding disentangling in𝛽-VAE. arXiv:1804.03599 [stat.ML] http://arxiv.org/abs/1804.03599
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Allan Collins. 1992. Toward a design science of education. InNew Directions in Educational Technology. Springer Berlin Heidelberg, 15–22. doi:10.1007/978-3- 642-77750-9_2
- [12]
- [13]
-
[14]
Jinshuo Dong, Aaron Roth, and Weijie J Su. 2022. Gaussian differential privacy. Journal of the Royal Statistical Society. Series B, Statistical methodology84, 1 (2022), 3–37. doi:10.1111/rssb.12454
-
[15]
Cynthia Dwork, Krishnaram Kenthapadi, Frank McSherry, Ilya Mironov, and Moni Naor. 2006. Our data, ourselves: Privacy via distributed noise generation. In Advances in Cryptology - EUROCRYPT 2006. Springer Berlin Heidelberg, 486–503. doi:10.1007/11761679_29
-
[16]
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. 2006. Cali- brating Noise to Sensitivity in Private Data Analysis. InTheory of Cryptography (Lecture Notes in Computer Science), Shai Halevi and Tal Rabin (Eds.). Springer, 265–284. doi:10.1007/11681878_14
-
[17]
Cynthia Dwork and Aaron Roth. 2014. The Algorithmic Foundations of Differen- tial Privacy.Foundations and trends in theoretical computer science9, 3–4 (2014), 211–407. doi:10.1561/0400000042
-
[18]
Robert M French. 1999. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences3, 4 (1999), 128–135. doi:10.1016/s1364-6613(99)01294-2
-
[19]
Hao Fu, Chunyuan Li, Xiaodong Liu, Jianfeng Gao, Asli Celikyilmaz, and Lawrence Carin. 2019. Cyclical Annealing Schedule: A Simple Approach to Mitigating KL Vanishing. InProceedings of the 2019 Conference of the North Amer- ican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Bu...
-
[20]
Andrea Gadotti, Luc Rocher, Florimond Houssiau, Ana-Maria Creţu, and Yves- Alexandre de Montjoye. 2024. Anonymization: The imperfect science of using data while preserving privacy.Science advances10, 29 (2024), eadn7053. doi:10. 1126/sciadv.adn7053
work page 2024
-
[21]
Arun Ganesh, Mahdi Haghifam, Milad Nasr, Sewoong Oh, Thomas Steinke, Om Thakkar, Abhradeep Guha Thakurta, and Lun Wang. 2023. Why Is Public Pretraining Necessary for Private Model Training?. InInternational Conference on Machine Learning. PMLR, 10611–10627. https://proceedings.mlr.press/v202/ ganesh23a.html
work page 2023
- [22]
-
[23]
Mehmet Emre Gursoy, Ali Inan, Mehmet Ercan Nergiz, and Yucel Saygin. 2017. Privacy-preserving learning analytics: Challenges and techniques.IEEE transac- tions on learning technologies10, 1 (2017), 68–81. doi:10.1109/tlt.2016.2607747
-
[24]
Trung Ha and Tran Khanh Dang. 2025. Evaluating membership inference vul- nerabilities in variational autoencoders with differential privacy. In2025 19th International Conference on Ubiquitous Information Management and Communi- cation (IMCOM). IEEE, 1–6. doi:10.1109/imcom64595.2025.10857552
-
[25]
Aaron Haim, Stacy Shaw, and Neil Heffernan. 2023. How to open science: A principle and reproducibility review of the learning analytics and knowledge Cyclic Adaptive Private Synthesis for Sharing Real-World Data in Education LAK 2026, April 27-May 01, 2026, Bergen, Norway conference. InLAK23: 13th International Learning Analytics and Knowledge Con- ferenc...
- [26]
-
[27]
John Heine, Erin E E Fowler, Anders Berglund, Michael J Schell, and Steven Es- chrich. 2023. Techniques to produce and evaluate realistic multivariate synthetic data.Scientific reports13, 1 (2023), 12266. doi:10.1038/s41598-023-38832-0
-
[28]
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. 2017. beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In International Conference on Learning Representations. https://openreview.net/ forum?id=Sy2fzU9gl
work page 2017
- [29]
-
[30]
Matthew D Hoffman and Matthew J Johnson. 2016. ELBO surgery: yet another way to carve up the variational evidence lower bound. InThe Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016)
work page 2016
-
[31]
Rachel Hong, Jevan Hutson, William Agnew, Imaad Huda, Tadayoshi Kohno, and Jamie Morgenstern. 2025. A common pool of privacy problems: Legal and technical lessons from a large-scale web-scraped machine learning dataset. arXiv:2506.17185 [cs.CR] http://arxiv.org/abs/2506.17185
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Chia-Yu Hsu, Izumi Horikoshi, Huiyong Li, Rwitajit Majumdar, and Hiroaki Ogata. 2024. Designing data-informed support for building learning habits in the Japanese K12 context.Research and Practice in Technology Enhanced Learning20 (2024), 014. doi:10.58459/rptel.2025.20014
-
[33]
Chia-Yu Hsu, Izumi Horikoshi, Huiyong Li, Rwitajit Majumdar, and Hiroaki Ogata
-
[34]
Springer Nature Switzerland, 168–178
Evaluating productivity of learning habits using math learning logs: Do K12 learners manage their time effectively? InLecture Notes in Computer Science. Springer Nature Switzerland, 168–178. doi:10.1007/978-3-031-72315-5_12
-
[35]
Chia-Yu Hsu, Mandukhai Otgonbaatar, Izumi Horikoshi, Huiyong Li, Rwitajit Majumdar, and Hiroaki Ogata. 2023. Chronotypes of Learning Habits in Weekly Math Learning of Junior High School. InProceedings of the 31stInternational Conference on Computers in Education, Shih J.-L., Kashihara A., Chen W., Chen W., Ogata H., Baker R., Chang B., Dianati S., Madathi...
work page 2023
-
[36]
Anika Kabir, Chandan Tankala, and Daniel Lowd. 2025. On the Practicality of Differential Privacy for Knowledge Tracing. InProceedings of the 18th Interna- tional Conference on Educational Data Mining. International Educational Data Mining Society, 619–624. doi:10.5281/zenodo.15870248
-
[37]
Georgios Kaissis, Stefan Kolek, Borja Balle, Jamie Hayes, and Daniel Rueckert
-
[38]
Beyond the calibration point: Mechanism comparison in differential pri- vacy. InProceedings of the 41st International Conference on Machine Learning, Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp (Eds.), Vol. 235. PMLR, 22840–22860. https://proceedings.mlr.press/v235/kaissis24a.html
-
[39]
Kadir Kesgin. 2025. FairSYN-Edu a diffusion-based model for fair and private educational data synthesis.Discover education4, 1 (2025), 1–18. doi:10.1007/ s44217-025-00743-9
work page 2025
-
[40]
Diederik P Kingma and Jimmy Ba. 2015. Adam: A method for stochastic opti- mization. In3rd International Conference on Learning Representations (ICLR 2015). https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[41]
Diederik P Kingma, Danilo J Rezende, Shakir Mohamed, and Max Welling
-
[42]
Semi-supervised Learning with Deep Generative Models. InAd- vances in Neural Information Processing Systems, Z Ghahramani, M Welling, C Cortes, N Lawrence, and K Q Weinberger (Eds.), Vol. 27. Curran As- sociates, Inc. https://proceedings.neurips.cc/paper_files/paper/2014/file/ 6d42b1217a6996997ead5a8398c1f944-Paper.pdf
work page 2014
-
[43]
Diederik P Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes. In 2nd International Conference on Learning Representations (ICLR 2014)
work page 2014
-
[44]
Hiroyuki Kuromiya, Taro Nakanishi, Izumi Horikoshi, Rwitajit Majumdar, and Hiroaki Ogata. 2023. Supporting reflective teaching workflow with real-world data and learning analytics.Information and Technology in Education and Learning 3, 1 (2023), Reg–p003–Reg–p003. doi:10.12937/itel.3.1.reg.p003
-
[45]
Huiyong Li, Rwitajit Majumdar, Mei-Rong Alice Chen, and Hiroaki Ogata. 2021. Goal-oriented active learning (GOAL) system to promote reading engagement, self-directed learning behavior, and motivation in extensive reading.Computers & education171, 104239 (2021), 104239. doi:10.1016/j.compedu.2021.104239
-
[46]
Xiaomin Li, Vangelis Metsis, Huangyingrui Wang, and Anne Hee Hiong Ngu
-
[47]
InLecture Notes in Computer Science
TTS-GAN: A transformer-based time-series generative adversarial network. InLecture Notes in Computer Science. Springer International Publishing, 133–143. doi:10.1007/978-3-031-09342-5_13
-
[48]
Qinyi Liu, Oscar Deho, Farhad Vadiee, Mohammad Khalil, Srecko Joksimovic, and George Siemens. 2025. Can synthetic data be fair and private? A comparative study of synthetic data generation and fairness algorithms. InProceedings of the 15th International Learning Analytics and Knowledge Conference. ACM, 591–600. doi:10.1145/3706468.3706546
-
[49]
Qinyi Liu and Mohammad Khalil. 2023. Understanding privacy and data pro- tection issues in learning analytics using a systematic review.British Journal of Educational Technology: Journal of the Council for Educational Technology54, 6 (2023), 1715–1747. doi:10.1111/bjet.13388
-
[50]
Qinyi Liu, Ronas Shakya, Jelena Jovanovic, Mohammad Khalil, and Javier de la Hoz-Ruiz. 2025. Ensuring privacy through synthetic data generation in education. British Journal of Educational Technology56, 3 (2025), 1053–1073. doi:10.1111/ bjet.13576
work page 2025
-
[51]
Qinyi Liu, Ronas Shakya, Mohammad Khalil, and Jelena Jovanovic. 2025. Advanc- ing privacy in learning analytics using differential privacy. InProceedings of the 15th International Learning Analytics and Knowledge Conference. ACM, 181–191. doi:10.1145/3706468.3706493
-
[52]
Rajiv Mahajan. 2015. Real world data: Additional source for making clinical decisions.International journal of applied & basic medical research5, 2 (2015), 82. doi:10.4103/2229-516X.157148
-
[53]
Mohammad Sultan Mahmud, Joshua Zhexue Huang, and Xianghua Fu. 2020. Variational autoencoder-based dimensionality reduction for high-dimensional small-sample data classification.International journal of computational intelligence and applications19, 01 (2020), 2050002. doi:10.1142/s1469026820500029
-
[54]
Ilya Mironov. 2017. Rényi Differential Privacy. In2017 IEEE 30th Computer Security Foundations Symposium (CSF). IEEE, 263–275. doi:10.1109/csf.2017.11
-
[55]
Mehrnoush Mohammadi, Elham Tajik, Roberto Martinez-Maldonado, Shazia Sadiq, Wojtek Tomaszewski, and Hassan Khosravi. 2025. Artificial intelligence in multimodal learning analytics: A systematic literature review.Computers and Education: Artificial Intelligence8, 100426 (2025), 100426. doi:10.1016/j.caeai.2025. 100426
-
[56]
Ngoc Buu Cat Nguyen and Thashmee Karunaratne. 2024. Learning analytics with small datasets–state of the art and beyond.Education sciences14, 6 (2024),
work page 2024
-
[57]
doi:10.3390/educsci14060608
-
[58]
Hiroaki Ogata, Chengjiu Yin, Misato Oi, Fumiya Okubo, Atsushi Shimada, Ken- taro Kojima, and Masanori Yamada. 2015. E-book-based learning analytics in university education. InProceedings of the 23rd International Conference on Com- puters in Education. 401–406. https://library.apsce.net/index.php/ICCE/article/ view/3233
work page 2015
-
[59]
Koki Okumura, Kento Nishioka, Kento Koike, Izumi Horikoshi, and Hiroaki Ogata. 2026. Causal discovery for automated real-world educational evidence extraction.Research and Practice in Technology Enhanced Learning21 (2026), 020. doi:10.58459/rptel.2026.21020
-
[60]
Kun Ouyang, Reza Shokri, David S Rosenblum, and Wenzhuo Yang. 2018. A non- parametric generative model for human trajectories. InProceedings of the Twenty- Seventh International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization. doi:10.24963/ijcai.2018/530
-
[61]
Lisa Pilgram, Fida Kamal Dankar, Jörg Drechsler, Mark Elliot, Josep Domingo- Ferrer, Paul Francis, Murat Kantarcioglu, Linglong Kong, Bradley Malin, Krishna- murty Muralidhar, Puja Myles, Fabian Prasser, Jean Louis Raisaro, Chao Yan, and Khaled El Emam. 2025. A consensus privacy metrics framework for synthetic data. Patterns (New York, N.Y.)101320 (2025),...
- [62]
-
[63]
Ivan Podsevalov, Alexei Podsevalov, and Vladimir Korkhov. 2022. Differential privacy for statistical data of educational institutions. InComputational Science and Its Applications – ICCSA 2022 Workshops. Springer International Publishing, 603–615. doi:10.1007/978-3-031-10542-5_41
-
[64]
Natalia Ponomareva, Hussein Hazimeh, Alex Kurakin, Zheng Xu, Carson Denison, H Brendan McMahan, Sergei Vassilvitskii, Steve Chien, and Abhradeep Guha Thakurta. 2023. How to DP-fy ML: A practical guide to machine Learning with differential privacy.The journal of artificial intelligence research77 (2023), 1113–1201. doi:10.1613/jair.1.14649
-
[65]
Ossi Räisä, Boris Van Breugel, and Mihaela Van Der Schaar. 2025. Position: All Current Generative Fidelity and Diversity Metrics are Flawed. InProceedings of the 42nd International Conference on Machine Learning, Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu (Eds.), Vol. 267. PML...
work page 2025
-
[66]
Peter Reimann. 2016. Connecting learning analytics with learning research: the role of design-based research.Learning Research and Practice2, 2 (2016), 130–142. doi:10.1080/23735082.2016.1210198
-
[67]
Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. 2014. Stochas- tic Backpropagation and Approximate Inference in Deep Generative Models. InInternational Conference on Machine Learning. PMLR, 1278–1286. https: //proceedings.mlr.press/v32/rezende14.html
work page 2014
-
[68]
Gina Ricker, Mathew Koziarski, and Alyssa Walters. 2020. Student clickstream data: Does time of day matter?Journal of Online Learning Research6, 2 (2020), 155–170. https://eric.ed.gov/?id=EJ1273645 LAK 2026, April 27-May 01, 2026, Bergen, Norway Ito et al
work page 2020
-
[69]
Lucas Rosenblatt, Bernease Herman, Anastasia Holovenko, Wonkwon Lee, Joshua Loftus, Elizabeth McKinnie, Taras Rumezhak, Andrii Stadnik, Bill Howe, and Julia Stoyanovich. 2023. Epistemic parity: Reproducibility as an evaluation metric for differential privacy.Proceedings of the VLDB Endowment International Conference on Very Large Data Bases16, 11 (2023), ...
-
[70]
Mohammed Saqr, Hibiki Ito, and Sonsoles López-Pernas. 2026. Individualized an- alytics: Within-person and idiographic analysis. InAdvanced Learning Analytics Methods. Springer Nature Switzerland, 471–491. doi:10.1007/978-3-031-95365- 1_18
-
[71]
Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. 2017. Continual Learn- ing with Deep Generative Replay. InAdvances in Neural Information Processing Systems, I Guyon, U Von Luxburg, S Bengio, H Wallach, R Fergus, S Vishwanathan, and R Garnett (Eds.), Vol. 30. Curran Associates, Inc. https://proceedings.neurips. cc/paper_files/paper/2017/file/0efbe98...
work page 2017
-
[72]
Mina Shirvani Boroujeni and Pierre Dillenbourg. 2019. Discovery and temporal analysis of MOOC study patterns.Journal of learning analytics6, 1 (2019), 16–33. doi:10.18608/jla.2019.61.2
-
[73]
Michael Stenger, Robert Leppich, Ian Foster, Samuel Kounev, and André Bauer
-
[74]
doi:10.1186/s40537-024-00924-7
Evaluation is key: a survey on evaluation measures for synthetic time series.Journal of big data11, 1 (2024), 1–56. doi:10.1186/s40537-024-00924-7
-
[75]
Marlon Tobaben, Aliaksandra Shysheya, J Bronskill, Andrew J Paverd, Shruti Tople, Santiago Zanella Béguelin, Richard E Turner, and Antti Honkela. 2023. On the efficacy of differentially private few-shot image classification.Transactions on Machine Learning Research(2023). https://openreview.net/pdf?id=hFsr59Imzm
work page 2023
-
[76]
Florian Tramèr and Dan Boneh. 2021. Differentially Private Learning Needs Better Features (or Much More Data). In9th International Conference on Learning Representations (ICLER 2021). https://openreview.net/forum?id=YTWGvpFOQD-
work page 2021
-
[77]
Florian Tramèr, Gautam Kamath, and Nicholas Carlini. 2024. Position: Con- siderations for Differentially Private Learning with Large-Scale Public Pre- training. InInternational Conference on Machine Learning. PMLR, 48453–48467. https://proceedings.mlr.press/v235/tramer24a.html
work page 2024
-
[78]
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. 2017. Neural Discrete Representation Learning. InAdvances in Neural Information Processing Systems, I Guyon, U Von Luxburg, S Bengio, H Wallach, R Fergus, S Vishwanathan, and R Garnett (Eds.), Vol. 30. Curran Associates, Inc. https://proceedings.neurips. cc/paper_files/paper/2017/file/7a98af17e63a0...
work page 2017
-
[79]
Olga Viberg, Chantal Mutimukwe, and Åke Grönlund. 2022. Privacy in LA research: Understanding the field to improve the practice.Journal of learning analytics9, 3 (2022), 1–14. doi:10.18608/jla.2022.7751
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.