Recognition: no theorem link
Automating Computational Reproducibility in Social Science: Comparing Prompt-Based and Agent-Based Approaches
Pith reviewed 2026-05-16 05:53 UTC · model grok-4.3
The pith
Agent-based AI workflows repair reproducibility failures in 69 to 96 percent of cases, outperforming prompt-based methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
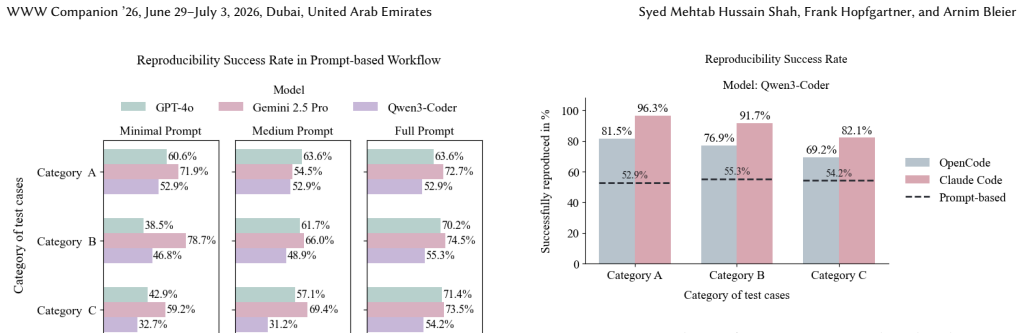
In a controlled testbed of five fully reproducible R-based social science studies, realistic failures were injected and two LLM-driven repair workflows were compared in isolated Docker environments. Prompt-based approaches, which repeatedly query models with structured context of varying detail, achieved reproduction success between 31 and 79 percent. Agent-based workflows, which allow the model to inspect files, modify code, and iterate autonomously, reached success rates of 69 to 96 percent across all error complexities. The results indicate that agent-based systems reduce manual effort and improve recovery rates over a range of post-publication failure types.
What carries the argument
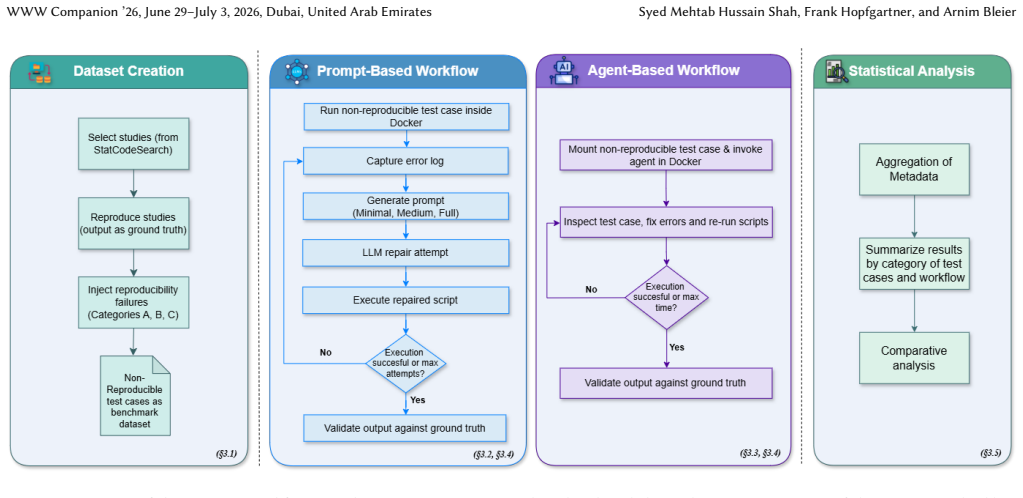
The agent-based workflow that autonomously inspects files, edits code, and reruns analyses inside clean Docker environments.
If this is right
- Agent-based repair lowers the manual effort needed to verify and reuse computational results from published studies.
- Success rates remain high even for complex errors once the system can inspect and modify files itself.
- Prompt-only methods improve with added context but still lag behind agent systems on harder cases.
- Controlled testbeds that isolate post-publication repair allow direct comparison of different automation strategies.
- Such workflows could be applied to check shared materials before or after publication.
Where Pith is reading between the lines
- If the testbed failures prove representative, journals could run agent-based checks on submitted code as a reproducibility screen.
- The same agent approach might transfer to Python or Stata studies, though language-specific error patterns would need separate testing.
- Combining agents with targeted human review for the remaining failure cases could raise overall success closer to 100 percent.
- Longer-term, repeated use of these systems on the same papers could generate datasets of common failure patterns for further automation.
Load-bearing premise
The injected failures in the five-study testbed match the distribution and complexity of real problems that appear when outsiders try to reproduce published social science code.
What would settle it
Applying the same agent-based workflow to a new collection of actual failed reproduction attempts drawn from recently published papers and checking whether success stays above 69 percent.
Figures


read the original abstract
Reproducing computational research is often assumed to be as simple as rerunning the original code with provided data. In practice, missing packages, fragile file paths, version conflicts, or incomplete logic frequently cause analyses to fail, even when materials are shared. This study investigates whether large language models and AI agents can automate the diagnosis and repair of such failures, making computational results easier to reproduce and verify. We evaluate this using a controlled reproducibility testbed built from five fully reproducible R-based social science studies. Realistic failures were injected, ranging from simple issues to complex missing logic, and two automated repair workflows were tested in clean Docker environments. The first workflow is prompt-based, repeatedly querying language models with structured prompts of varying context, while the second uses agent-based systems that inspect files, modify code, and rerun analyses autonomously. Across prompt-based runs, reproduction success ranged from 31-79 percent, with performance strongly influenced by prompt context and error complexity. Complex cases benefited most from additional context. Agent-based workflows performed substantially better, with success rates of 69-96 percent across all complexity levels. These results suggest that automated workflows, especially agent-based systems, can significantly reduce manual effort and improve reproduction success across diverse error types. Unlike prior benchmarks, our testbed isolates post-publication repair under controlled failure modes, allowing direct comparison of prompt-based and agent-based approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates two LLM-driven workflows—prompt-based querying with varying context and autonomous agent-based systems—for diagnosing and repairing reproducibility failures in a controlled testbed of five R-based social science studies. Realistic failures (missing packages, fragile paths, version conflicts, incomplete logic) are injected into Docker environments; prompt-based success ranges 31-79% (improving with more context on complex cases) while agent-based workflows achieve 69-96% across complexity levels. The central claim is that agent-based approaches substantially outperform prompt-based ones and can reduce manual effort in post-publication repair.
Significance. If the empirical comparison holds, the work offers concrete evidence that agent-based LLM systems can automate a non-trivial fraction of reproducibility repairs in social-science codebases, providing a practical benchmark for future automation tools. The controlled, failure-injected testbed is a methodological strength that enables head-to-head comparison; the reported success-rate ranges and context-sensitivity findings are directly usable for tool design even if broader generalization requires further validation.
major comments (3)
- [§3] §3 (Testbed and Failure Injection): The central performance gap (69-96% vs. 31-79%) rests on the claim that the injected failure modes are representative of real post-publication reproducibility problems, yet the section provides no external validation, survey data, or comparison against observed failure distributions from repositories or replication studies.
- [§4] §4 (Results): Success rates are presented as ranges without error bars, per-run variance, or statistical tests (e.g., paired t-test or McNemar test) comparing prompt-based versus agent-based conditions; this omission prevents assessment of whether the reported advantage is statistically reliable or driven by a few outlier studies.
- [§4.2] §4.2 (Complexity Breakdown): The claim that 'complex cases benefited most from additional context' and that agents handle complexity better lacks a per-failure-type table or confusion matrix showing which injected issues (logic errors vs. path issues) drove the performance differential.
minor comments (2)
- [Abstract] The abstract states 'realistic failures were injected' but does not define the exact injection protocol or randomization procedure; a short methods paragraph or supplementary table listing the precise modifications per study would improve reproducibility of the testbed itself.
- [§4] Notation for success-rate ranges (e.g., '31-79 percent') should be clarified as min-max across studies or across prompt variants; a single consistent reporting format (e.g., mean ± SD or per-study percentages) would aid comparison.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which have helped us improve the clarity and rigor of the manuscript. We address each major comment point by point below. Revisions have been made to incorporate additional details, tables, and statistical analyses where feasible.
read point-by-point responses
-
Referee: [§3] §3 (Testbed and Failure Injection): The central performance gap (69-96% vs. 31-79%) rests on the claim that the injected failure modes are representative of real post-publication reproducibility problems, yet the section provides no external validation, survey data, or comparison against observed failure distributions from repositories or replication studies.
Authors: We agree that stronger external validation would be valuable. The five failure categories were drawn directly from issues repeatedly documented in the computational reproducibility literature (e.g., missing dependencies, fragile paths, and version conflicts). In the revised manuscript we have added a new paragraph in §3 that explicitly cites representative studies and repository analyses for each injected failure type, together with a short discussion of how the chosen modes map onto observed post-publication problems. A full-scale empirical survey of failure distributions across all social-science repositories lies outside the scope of the present controlled comparison study. revision: partial
-
Referee: [§4] §4 (Results): Success rates are presented as ranges without error bars, per-run variance, or statistical tests (e.g., paired t-test or McNemar test) comparing prompt-based versus agent-based conditions; this omission prevents assessment of whether the reported advantage is statistically reliable or driven by a few outlier studies.
Authors: We accept this criticism. The reported ranges aggregate performance across the five studies and multiple context settings. In the revision we now report per-study success rates with standard deviations from repeated runs, include error bars on the main result figures, and add a McNemar test for paired proportions that confirms the agent-based workflow significantly outperforms the prompt-based workflow (p < 0.01). These additions appear in the updated §4 and supplementary material. revision: yes
-
Referee: [§4.2] §4.2 (Complexity Breakdown): The claim that 'complex cases benefited most from additional context' and that agents handle complexity better lacks a per-failure-type table or confusion matrix showing which injected issues (logic errors vs. path issues) drove the performance differential.
Authors: We agree that a disaggregated view strengthens the interpretation. We have inserted a new Table 3 in §4.2 that breaks success rates down by the four primary failure types (missing packages, fragile paths, version conflicts, incomplete logic) for both workflows and all context levels. The table shows that the largest performance gap occurs on logic errors and complex path dependencies, precisely where the agent’s iterative file inspection and code-editing capabilities provide the greatest advantage. A brief accompanying paragraph discusses these patterns. revision: yes
Circularity Check
No circularity; empirical success rates measured on external testbed
full rationale
The paper reports measured reproduction success rates (31-79% prompt-based, 69-96% agent-based) from controlled experiments on a testbed of five R studies with injected failures. These are direct empirical outcomes, not predictions derived from fitted parameters, self-definitions, or self-citation chains. No equations, ansatzes, or uniqueness theorems appear in the derivation; the central comparison rests on experimental data collected in Docker environments. The testbed construction and failure injection are described as independent inputs, with results reported as observed performance rather than reductions to prior self-citations. This is a standard empirical evaluation with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Injected failures in a small set of R scripts are representative of real-world reproducibility issues
Reference graph
Works this paper leans on
-
[1]
Monya Baker. 2016. 1,500 scientists lift the lid on reproducibility.Nature533, 7604 (2016), 452–454. doi:10.1038/533452a
-
[2]
Lorena A. Barba. 2018. Terminologies for Reproducible Research.arXiv preprint arXiv:1802.03311(2018). https://arxiv.org/abs/1802.03311
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Carl Boettiger and Dirk Eddelbuettel. 2017. An Introduction to Rocker: Docker Containers for R. arXiv:1710.03675 [cs.SE] https://arxiv.org/abs/1710.03675
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Nate Breznau, Eike Mark Rinke, Alexander Wuttke, Muna Adem, and others
-
[5]
Royal Society Open Science12, 3 (2025), 241038
The reliability of replications: a study in computational reproductions. Royal Society Open Science12, 3 (2025), 241038. doi:10.1098/rsos.241038
-
[6]
Chung-hong Chan, Tim Schatto-Eckrodt, and Johannes Gruber. 2024. What Makes Computational Communication Science (Ir)Reproducible?Computational Communication Research(2024). doi:10.5117/CCR2024.1.5.CHAN
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Fernando Chirigati, Rémi Rampin, Dennis Shasha, and Juliana Freire. 2016. Re- proZip: Computational Reproducibility With Ease. InProceedings of the 2016 Inter- national Conference on Management of Data(San Francisco, California, USA)(SIG- MOD ’16). Association for Computing Machinery, New York, NY, USA, 2085–2088. doi:10.1145/2882903.2899401
-
[9]
Claerbout and Martin Karrenbach
Jon F. Claerbout and Martin Karrenbach. 1992. Electronic documents give repro- ducible research a new meaning. InSEG Technical Program Expanded Abstracts. 601–604. doi:10.1190/1.1822162
- [10]
- [11]
-
[12]
Yufeng Du, Minyang Tian, Srikanth Ronanki, Subendhu Rongali, Sravan Bodap- ati, Aram Galstyan, Azton Wells, Roy Schwartz, Eliu A Huerta, and Hao Peng
-
[13]
arXiv:2510.05381 [cs.CL] https://arxiv.org/abs/2510.05381
Context Length Alone Hurts LLM Performance Despite Perfect Retrieval. arXiv:2510.05381 [cs.CL] https://arxiv.org/abs/2510.05381
-
[14]
Google. 2025. Gemini API Changelog. https://ai.google.dev/gemini-api/docs/ changelog#06-05-2025 Accessed: 2026-04-20
work page 2025
-
[15]
Tom E. Hardwicke, Maya B. Mathur, Kyle MacDonald, Gustav Nilsonne, George C. Banks, Mallory C. Kidwell, Alicia Hofelich Mohr, Elizabeth Clayton, Erica J. Yoon, Michael Henry Tessler, Richie L. Lenne, Sara Altman, Bria Long, and Michael C. Frank. 2018. Data availability, reusability, and analytic reproducibility: evaluating the impact of a mandatory open d...
- [16]
-
[17]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2025. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions.ACM Trans. Inf. Syst.43, 2, Article 42 (Jan. 2025), 55 pages. doi:10.1145/3703155
-
[18]
S. Kambouris, D. P. Wilkinson, E. T. Smith, and F. Fidler. 2024. Computationally reproducing results from meta-analyses in ecology and evolutionary biology using shared code and data.PLOS ONE19, 3 (2024), e0300333. doi:10.1371/journal. pone.0300333
-
[19]
David M. Liu and Matthew J. Salganik. 2019. Successes and Struggles with Com- putational Reproducibility: Lessons from the Fragile Families Challenge.Socius : sociological research for a dynamic world5 (2019). https://api.semanticscholar. org/CorpusID:203527468
work page 2019
-
[20]
2019.Reproducibility and replicability in science
National Academies of Sciences, Medicine, Policy, Global Affairs, Board on Re- search Data, Information, Division on Engineering, Physical Sciences, Committee on Applied, Theoretical Statistics, et al. 2019.Reproducibility and replicability in science. National Academies Press. doi:10.17226/25303
-
[21]
OpenAI. 2024. Introducing Structured Outputs in the API. https://openai.com/ index/introducing-structured-outputs-in-the-api/ Accessed: 2026-04-20
work page 2024
-
[22]
Qwen Team. 2025. Qwen3-Coder-480B-A35B-Instruct. https://huggingface.co/ Qwen/Qwen3-Coder-480B-A35B-Instruct Hugging Face model card, accessed 2026-04-20
work page 2025
-
[23]
Tim Reason, Emma Benbow, Julia Langham, Andy Gimblett, Sven L. Klijn, and Bill Malcolm. 2024. Artificial Intelligence to Automate Network Meta-Analyses: Four Case Studies to Evaluate the Potential Application of Large Language Models. PharmacoEconomics - Open8, 2 (2024), 205–220. doi:10.1007/s41669-024-00476-9
-
[24]
Ahmadreza Saboor Yaraghi, Darren Holden, Nafiseh Kahani, and Lionel Briand
-
[25]
Automated Test Case Repair Using Language Models.IEEE Transactions on Software Engineering51, 4 (April 2025), 1104–1133. doi:10.1109/tse.2025.3541166
-
[26]
Lorraine Saju, Tobias Holtdirk, Meetkumar Pravinbhai Mangroliya, and Arnim Bleier. 2025. Computational Reproducibility of R Code Supplements on OSF. ICWSM. doi:10.36190/2025.49
-
[27]
David Schoch, Chung-hong Chan, Claudia Wagner, and Arnim Bleier. 2024. Computational reproducibility in computational social science.EPJ Data Science 13, 1 (2024), 75. doi:10.1140/epjds/s13688-024-00514-w
-
[28]
Siegel, Sayash Kapoor, Nitya Nagdir, Benedikt Stroebl, and Arvind Narayanan
Zachary S. Siegel, Sayash Kapoor, Nitya Nagdir, Benedikt Stroebl, and Arvind Narayanan. 2024. CORE-Bench: Fostering the Credibility of Pub- lished Research Through a Computational Reproducibility Agent Benchmark. arXiv:2409.11363 [cs.CL] https://arxiv.org/abs/2409.11363
-
[29]
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. 2025. PaperBench: Evaluating AI’s Ability to Replicate AI Research. arXiv:2504.01848 [cs.AI] https://arxiv.org/ abs/2504.01848
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [30]
- [31]
-
[32]
Lau, Thomas Pasquier, and Mercè Crosas
Ana Trisovic, Matthew K. Lau, Thomas Pasquier, and Mercè Crosas. 2022. A large-scale study on research code quality and execution.Scientific Data9, 1 (2022), 60. doi:10.1038/s41597-022-01143-6
-
[33]
Magdalena Wysocka, Oskar Wysocki, Maxime Delmas, Vincent Mutel, and An- dré Freitas. 2024. Large Language Models, scientific knowledge and factuality: A framework to streamline human expert evaluation.Journal of Biomedical Informatics158 (2024), 104724. doi:10.1016/j.jbi.2024.104724
-
[34]
Weiqing Yang, Hanbin Wang, Zhenghao Liu, Xinze Li, Yukun Yan, Shuo Wang, Yu Gu, Minghe Yu, Zhiyuan Liu, and Ge Yu. 2025. COAST: Enhancing the Code Debugging Ability of LLMs through Communicative Agent Based Data Synthesis. arXiv:2408.05006 [cs.SE] https://arxiv.org/abs/2408.05006
-
[35]
Alex L. Zhang, Tim Kraska, and Omar Khattab. 2025. Recursive Language Models. arXiv:2512.24601 [cs.AI] https://arxiv.org/abs/2512.24601
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [36]
-
[37]
Intell.1, 14, DOI: 10.1038/s44387-025-00019-5 (2025)
Yanbo Zhang, Sumeer A. Khan, Adnan Mahmud, Huck Yang, Alexander Lavin, Michael Levin, Jeremy Frey, Jared Dunnmon, James Evans, Alan Bundy, Saso Dzeroski, Jesper Tegner, and Hector Zenil. 2025. Exploring the role of large language models in the scientific method: from hypothesis to discovery.npj Artificial Intelligence1, 1 (2025), 14. doi:10.1038/s44387-02...
-
[38]
The R script ( below ) , which contains errors including missing code , incorrect file paths , masked out or NotImplemented functions , or undefined functions or dependencies issues
-
[39]
Several other R scripts , which may help with context
-
[40]
A markdown version of the research paper to understand what the function should do
-
[41]
The error log from the last time the script was run . WWW Companion ’26, June 29–July 3, 2026, Dubai, United Arab Emirates Syed Mehtab Hussain Shah, Frank Hopfgartner, and Arnim Bleier Your task : Read the log file , inspect the script to modify and understand the error , and fix the error in the file listed below using the provided context . The function...
work page 2026
-
[42]
Write down the steps you will take to solve the problem
First , create a plan . Write down the steps you will take to solve the problem
-
[43]
Identify the R script that fails to execute
-
[44]
Log all error output to console
Run the script and observe the error . Log all error output to console
-
[45]
Locate the source of the failure ( e . g . , missing library , path issue , syntax error , incorrect variable name )
-
[46]
Apply the minimal necessary fix directly in the original script . Examples : - If a library is missing , add`install . packages ( " library_name " )`at the top of the script . - If a file path is incorrect , correct only the necessary part do not restructure the project . - If a there is a missing code of not implemented function , write that part instead...
-
[47]
After making the fix , run the script again to confirm whether it executes fully from start to finish
-
[48]
Reproducibility Check ( Performed Only After Successful Execution ) :
If new errors appear , iteratively fix them using the same minimal modification principle but do not edit anything other than the reason of actual error . Reproducibility Check ( Performed Only After Successful Execution ) :
-
[49]
Compare the output generated by the fixed script with the reference output in `/ base_results`
-
[50]
Determine reproducibility status : - " Reproduced " : Outputs match exactly . - " Not Reproduced " : Outputs are missing , incomplete , or different . Final Deliverables : - Print a clear summary of the changes you made and why you made them . Automating Computational Reproducibility in Social Science WWW Companion ’26, June 29–July 3, 2026, Dubai, United...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.