Recognition: no theorem link
SnareNet: Flexible Repair Layers for Neural Networks with Hard Constraints
Pith reviewed 2026-05-16 03:30 UTC · model grok-4.3
The pith
SnareNet introduces a repair layer that navigates the range space of constraints plus adaptive relaxation training to enforce hard non-convex constraints on neural network outputs more reliably than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SnareNet is the first to enforce non-convex constraints at medium-to-high precision robustly across instances while attaining improved objective quality on optimization learning and trajectory planning benchmarks.
Load-bearing premise
That a differentiable repair operation exists in the constraint map's range space for arbitrary input-dependent constraints and that adaptive relaxation can be tuned to reach strict feasibility without degrading final solution quality.
Figures
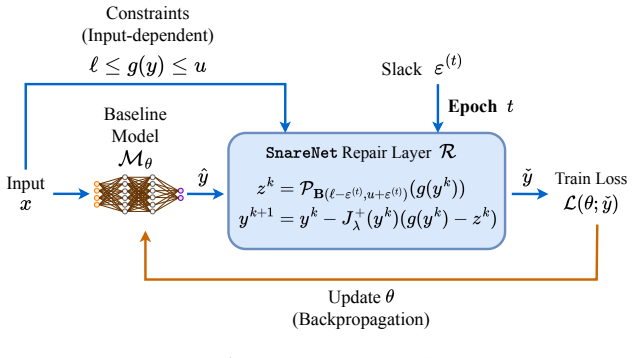


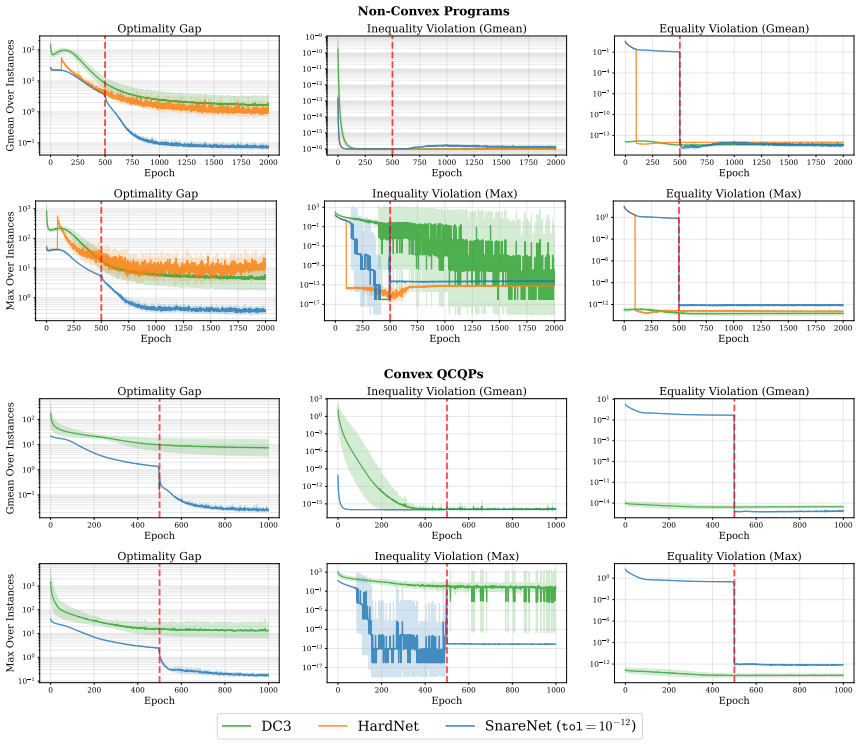



read the original abstract
Neural networks are increasingly used as fast surrogate models across various domains, but unconstrained predictions can violate physical, operational, or safety requirements. We propose SnareNet, a feasibility-controlled architecture to learn mappings whose outputs must satisfy input-dependent constraints. SnareNet appends a differentiable repair layer that navigates in the constraint map's range space, steering iterates toward feasibility and producing a repaired output that satisfies constraints to a user-specified tolerance. We stabilize end-to-end training by adaptive relaxation, a new training paradigm that snares the neural network at initialization and shrinks it into the feasible set, enabling early exploration and strict feasibility later in training. On optimization learning and trajectory planning benchmarks, SnareNet consistently attains improved objective quality while satisfying constraints more reliably than prior work, and it is the first to enforce non-convex constraints at medium-to-high precision robustly across instances.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A differentiable repair operation exists that can steer iterates to feasibility inside the range space of the constraint map for the target class of input-dependent constraints.
- domain assumption Adaptive relaxation can be scheduled so that early loose constraints permit exploration while later strict constraints guarantee feasibility without harming final objective quality.
Reference graph
Works this paper leans on
-
[1]
Aaron D Ames, Xiangru Xu, Jessy W Grizzle, and Paulo Tabuada. Control barrier function based quadratic programs for safety critical systems.IEEE Transactions on Automatic Control, 62(8):3861–3876, 2016
work page 2016
-
[2]
Control Barrier Functions: Theory and Applications
Aaron D. Ames, Samuel Coogan, Magnus Egerstedt, Gennaro Notomista, Koushil Sreenath, and Paulo Tabuada. Control barrier functions: Theory and applications, 2019. URL https: //arxiv.org/abs/1903.11199
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
Optnet: Differentiable optimization as a layer in neural networks
Brandon Amos and J Zico Kolter. Optnet: Differentiable optimization as a layer in neural networks. InInternational conference on machine learning, pages 136–145. PMLR, 2017
work page 2017
-
[4]
Deep learning for computational biology.Molecular systems biology, 12(7):878, 2016
Christof Angermueller, Tanel P¨ arnamaa, Leopold Parts, and Oliver Stegle. Deep learning for computational biology.Molecular systems biology, 12(7):878, 2016
work page 2016
-
[5]
Tom Beucler, Michael Pritchard, Stephan Rasp, Jordan Ott, Pierre Baldi, and Pierre Gentine. Enforcing analytic constraints in neural networks emulating physical systems.Physical Review Letters, 126(9), March 2021. ISSN 1079-7114. doi: 10.1103/physrevlett.126.098302. URL http://dx.doi.org/10.1103/PhysRevLett.126.098302
-
[6]
Boris Bonev, Thorsten Kurth, Ankur Mahesh, Mauro Bisson, Jean Kossaifi, Karthik Kashinath, Anima Anandkumar, William D Collins, Michael S Pritchard, and Alexander Keller. Fourcastnet 12 3: A geometric approach to probabilistic machine-learning weather forecasting at scale.arXiv preprint arXiv:2507.12144, 2025
-
[7]
Hao Chen, Gonzalo E. Constante Flores, and Can Li. Physics-informed neural networks with hard linear equality constraints, 2024. URLhttps://arxiv.org/abs/2402.07251
-
[8]
Siyuan Chen, Minghao Guo, Caoliwen Wang, Anka He Chen, Yikun Zhang, Jingjing Chai, Yin Yang, Wojciech Matusik, and Peter Yichen Chen. Physically valid biomolecular interaction modeling with gauss-seidel projection.arXiv preprint arXiv:2510.08946, 2025
-
[9]
Alp Dener, Marco Andres Miller, Randy Michael Churchill, Todd Munson, and Choong-Seock Chang. Training neural networks under physical constraints using a stochastic augmented lagrangian approach, 2020. URLhttps://arxiv.org/abs/2009.07330
-
[10]
Dc3: A learning method for optimization with hard constraints.arXiv preprint arXiv:2104.12225, 2021
Priya L Donti, David Rolnick, and J Zico Kolter. Dc3: A learning method for optimization with hard constraints.arXiv preprint arXiv:2104.12225, 2021
-
[11]
Physics-informed Autoencoders for Lyapunov-stable Fluid Flow Prediction
N. Benjamin Erichson, Michael Muehlebach, and Michael W. Mahoney. Physics-informed autoencoders for lyapunov-stable fluid flow prediction, 2019. URL https://arxiv.org/abs/ 1905.10866
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[12]
Homogeneous linear inequality con- straints for neural network activations, 2020
Thomas Frerix, Matthias Nießner, and Daniel Cremers. Homogeneous linear inequality con- straints for neural network activations, 2020. URLhttps://arxiv.org/abs/1902.01785
-
[13]
Rafael G´ omez-Bombarelli, Jennifer N Wei, David Duvenaud, Jos´ e Miguel Hern´ andez-Lobato, Benjam´ ın S´ anchez-Lengeling, Dennis Sheberla, Jorge Aguilera-Iparraguirre, Timothy D Hirzel, Ryan P Adams, and Al´ an Aspuru-Guzik. Automatic chemical design using a data-driven continuous representation of molecules.ACS central science, 4(2):268–276, 2018
work page 2018
-
[14]
Sorin Grigorescu, Bogdan Trasnea, Tiberiu Cocias, and Gigel Macesanu. A survey of deep learning techniques for autonomous driving.Journal of field robotics, 37(3):362–386, 2020
work page 2020
-
[15]
Panagiotis D Grontas, Antonio Terpin, Efe C Balta, Raffaello D’Andrea, and John Lygeros. Pinet: Optimizing hard-constrained neural networks with orthogonal projection layers.arXiv preprint arXiv:2508.10480, 2025
-
[16]
Gurobi Optimizer Reference Manual, 2024
Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual, 2024. URL https://www. gurobi.com
work page 2024
-
[17]
Ashfaq Iftakher, Rahul Golder, Bimol Nath Roy, and MM Faruque Hasan. Physics-informed neural networks with hard nonlinear equality and inequality constraints.Computers & Chemical Engineering, page 109418, 2025
work page 2025
-
[18]
Highly accurate protein structure prediction with alphafold.nature, 596(7873):583–589, 2021
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin ˇZ´ ıdek, Anna Potapenko, et al. Highly accurate protein structure prediction with alphafold.nature, 596(7873):583–589, 2021
work page 2021
-
[19]
Constrained-cnn losses for weakly supervised segmentation.Medical Image Analysis, 54:88–99, May 2019
Hoel Kervadec, Jose Dolz, Meng Tang, Eric Granger, Yuri Boykov, and Ismail Ben Ayed. Constrained-cnn losses for weakly supervised segmentation.Medical Image Analysis, 54:88–99, May 2019. ISSN 1361-8415. doi: 10.1016/j.media.2019.02.009. URL http://dx.doi.org/10. 1016/j.media.2019.02.009
-
[20]
Constrained deep networks: Lagrangian optimization via log-barrier extensions
Hoel Kervadec, Jose Dolz, Jing Yuan, Christian Desrosiers, Eric Granger, and Ismail Ben Ayed. Constrained deep networks: Lagrangian optimization via log-barrier extensions. In2022 30th European Signal Processing Conference (EUSIPCO), page 962–966. IEEE, August 2022. doi: 10. 23919/eusipco55093.2022.9909927. URL http://dx.doi.org/10.23919/EUSIPCO55093.2022...
-
[21]
Dmitrii Kochkov, Jamie A Smith, Ayya Alieva, Qing Wang, Michael P Brenner, and Stephan Hoyer. Machine learning–accelerated computational fluid dynamics.Proceedings of the National Academy of Sciences, 118(21):e2101784118, 2021
work page 2021
-
[22]
Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421, 2023
Remi Lam, Alvaro Sanchez-Gonzalez, Matthew Willson, Peter Wirnsberger, Meire Fortunato, Ferran Alet, Suman Ravuri, Timo Ewalds, Zach Eaton-Rosen, Weihua Hu, et al. Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421, 2023
work page 2023
-
[23]
Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. End-to-end training of deep visuomotor policies.Journal of Machine Learning Research, 17(39):1–40, 2016
work page 2016
-
[24]
Meiyi Li, Soheil Kolouri, and Javad Mohammadi. Learning to solve optimization problems with hard linear constraints.IEEE Access, 11:59995–60004, 2023
work page 2023
-
[25]
Zongyi Li, Hongkai Zheng, Nikola Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Azizzadenesheli, and Anima Anandkumar. Physics-informed neural operator for learning partial differential equations.ACM/IMS Journal of Data Science, 1(3):1–27, 2024
work page 2024
-
[26]
Enming Liang, Minghua Chen, and Steven H. Low. Homeomorphic projection to ensure neural-network solution feasibility for constrained optimization.Journal of Machine Learning Research, 25(329):1–55, 2024. URLhttp://jmlr.org/papers/v25/23-1577.html
work page 2024
-
[27]
Lu Lu, Raphael Pestourie, Wenjie Yao, Zhicheng Wang, Francesc Verdugo, and Steven G Johnson. Physics-informed neural networks with hard constraints for inverse design.SIAM Journal on Scientific Computing, 43(6):B1105–B1132, 2021
work page 2021
-
[28]
Youngjae Min and Navid Azizan. Hardnet: Hard-constrained neural networks with universal approximation guarantees.arXiv preprint arXiv:2410.10807, 2024
-
[29]
Imposing Hard Constraints on Deep Networks: Promises and Limitations
Pablo M´ arquez-Neila, Mathieu Salzmann, and Pascal Fua. Imposing hard constraints on deep networks: Promises and limitations, 2017. URLhttps://arxiv.org/abs/1706.02025
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Hoang T Nguyen and Priya L Donti. Fsnet: Feasibility-seeking neural network for constrained optimization with guarantees.arXiv preprint arXiv:2506.00362, 2025
-
[31]
Deepopf: deep neural networks for optimal power flow
Xiang Pan. Deepopf: deep neural networks for optimal power flow. InProceedings of the 8th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, pages 250–251, 2021
work page 2021
-
[32]
Constrained differential optimization
John Platt and Alan Barr. Constrained differential optimization. InNeural information processing systems, 1987
work page 1987
-
[33]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019
work page 2019
-
[34]
Challenges in training pinns: A loss landscape perspective.arXiv preprint arXiv:2402.01868, 2024
Pratik Rathore, Weimu Lei, Zachary Frangella, Lu Lu, and Madeleine Udell. Challenges in training pinns: A loss landscape perspective.arXiv preprint arXiv:2402.01868, 2024
-
[35]
A collision cone approach for control barrier functions, 2024
Manan Tayal, Bhavya Giri Goswami, Karthik Rajgopal, Rajpal Singh, Tejas Rao, Jishnu Keshavan, Pushpak Jagtap, and Shishir Kolathaya. A collision cone approach for control barrier functions, 2024. URLhttps://arxiv.org/abs/2403.07043
-
[36]
RAYEN: Imposition of Hard Convex Constraints on Neural Networks
Jesus Tordesillas, Jonathan P. How, and Marco Hutter. Rayen: Imposition of hard convex constraints on neural networks, 2023. URLhttps://arxiv.org/abs/2307.08336
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Optimization learning.arXiv preprint arXiv:2501.03443, 2025
Pascal Van Hentenryck. Optimization learning.arXiv preprint arXiv:2501.03443, 2025. 14
-
[38]
Information theoretic mpc for model-based reinforcement learning
Grady Williams, Nolan Wagener, Brian Goldfain, Paul Drews, James M Rehg, Byron Boots, and Evangelos A Theodorou. Information theoretic mpc for model-based reinforcement learning. In2017 IEEE international conference on robotics and automation (ICRA), pages 1714–1721. IEEE, 2017
work page 2017
-
[39]
Moleculenet: a benchmark for molecular machine learning.Chemical science, 9(2):513–530, 2018
Zhenqin Wu, Bharath Ramsundar, Evan N Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S Pappu, Karl Leswing, and Vijay Pande. Moleculenet: a benchmark for molecular machine learning.Chemical science, 9(2):513–530, 2018
work page 2018
-
[40]
A Semantic Loss Function for Deep Learning with Symbolic Knowledge
Jingyi Xu, Zilu Zhang, Tal Friedman, Yitao Liang, and Guy Van den Broeck. A semantic loss function for deep learning with symbolic knowledge, 2018. URL https://arxiv.org/abs/ 1711.11157
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Shengwei Zhang and AG Constantinides. Lagrange programming neural networks.IEEE Transactions on Circuits and Systems II: Analog and Digital Signal Processing, 39(7):441–452, 1992. A Related Literature Penalty Methods.Early approaches to enforcing constraints in neural networks add penalty terms to the loss function [ 29]. These methods augment the origina...
work page 1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.