BabyMamba-HAR: Lightweight Selective State Space Models for Efficient Human Activity Recognition on Resource Constrained Devices
Pith reviewed 2026-05-21 13:18 UTC · model grok-4.3
The pith
Lightweight selective state space models achieve 86.5 percent average F1-score for human activity recognition using 27K parameters and 2.2M MACs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
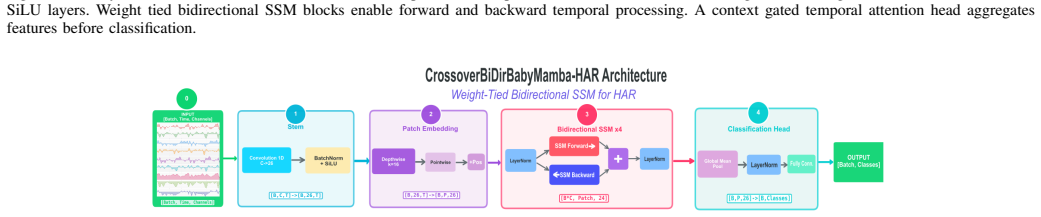
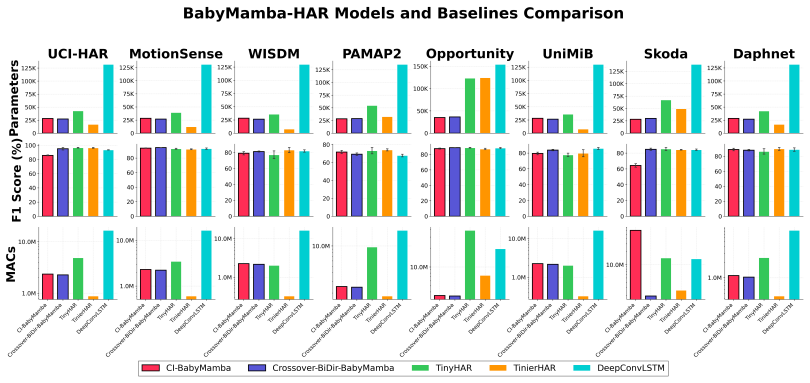
BabyMamba-HAR presents CI-BabyMamba-HAR and Crossover-BiDir-BabyMamba-HAR as compact selective state space model variants for human activity recognition. The designs include a channel-independent stem or an early-fusion stem, weight-tied bidirectional scanning, and gated temporal attention pooling. Crossover-BiDir-BabyMamba-HAR reaches an average 86.52 percent F1-score with 27K parameters and 2.21M MACs across eight benchmarks, matching TinyHAR accuracy while using 11 times fewer MACs on high-channel datasets. On Raspberry Pi Pico 2 and ESP32 the models run via a mixed-precision C++ runtime with lifetime-aware memory management that cuts peak memory from O(B times dmodel times L times dstate
What carries the argument
Weight-tied bidirectional scanning together with gated temporal attention pooling inside selective state space model layers, which supplies efficient forward-and-backward temporal modeling and focused aggregation at low parameter and compute cost.
If this is right
- The model matches prior accuracy on eight benchmarks while cutting MACs by a factor of eleven on high-channel sensor data.
- Both architectures achieve complete coverage of all eight datasets with greater than 99.2 percent parity to the original PyTorch versions on two common microcontrollers.
- Ablations demonstrate that bidirectional scanning and gated attention each raise F1-scores by as much as 8 to 9 percent.
- The memory strategy reduces peak usage to scale with batch size, model dimension, and state size instead of sequence length.
Where Pith is reading between the lines
- The same scanning and pooling choices could improve efficiency for other edge-device time-series tasks such as gesture detection or equipment monitoring.
- The channel-streaming execution pattern may support continuous real-time inference from live sensor feeds without storing full sequences.
- Further experiments on additional low-power chips would test whether the reported parity and latency hold beyond the two devices examined here.
- These lightweight SSM patterns could serve as baselines when comparing new sequence models for resource-constrained classification problems.
Load-bearing premise
The specific optimizations of weight-tied bidirectional scanning, gated temporal attention pooling, and the mixed-precision runtime with lifetime-aware memory allocation keep accuracy intact while fitting the memory and timing constraints of the tested microcontrollers.
What would settle it
Testing the trained models on a ninth human activity recognition dataset that uses different sensors or activities and checking whether average F1-score stays above 80 percent and microcontroller parity remains above 95 percent.
Figures



read the original abstract
Human activity recognition (HAR) on resource constrained devices requires high accuracy across diverse sensor setups. Selective state space models (SSMs) offer efficient linear time sequence processing, presenting a compelling alternative to attention mechanisms. However, their TinyML design space remains unexplored. This paper introduces BabyMamba-HAR, comprising two lightweight architectures: (1) CI-BabyMamba-HAR, utilizing a channel independent stem for noise robustness, and (2) Crossover-BiDir-BabyMamba-HAR, utilizing an early fusion stem for channel count independent complexity. Both integrate weight tied bidirectional scanning and gated temporal attention pooling. Across eight benchmarks, Crossover-BiDir-BabyMamba-HAR averages an 86.52% F1-score with 27K parameters and 2.21M MACs, matching TinyHAR (86.16%) while requiring 11x fewer MACs on high channel datasets. On-device deployment on the Raspberry Pi Pico 2 and ESP32 utilized a mixed precision C++ runtime (INT8 projections, float32 states). A fused computation strategy with lifetime aware memory management reduces peak memory footprint from O(B*dmodel*L*dstate) to O(B*dmodel*dstate), adapting to support weight-tied bidirectional and channel-streaming execution. Both architectures achieved full 8/8 dataset coverage with >99.2% PyTorch parity, whereas INT8 quantized TFLite baselines showed degraded coverage and parity (TinyHAR: 7/8 and 4/8 coverage at 60.4% and 88.6% parity, TinierHAR: 8/8 and 6/8 at 54.2% and 90.8%, DeepConvLSTM: 1/8 and 0/8 on Pico 2 and ESP32, respectively). Crossover-BiDir-BabyMamba-HAR averages 154.4 ms latency on ESP32 and 481.9 ms on Pico 2. Ablations confirm bidirectional scanning and gated attention improve F1-scores by up to 8.42% and 8.94%, respectively, establishing practical principles for TinyML SSM deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BabyMamba-HAR, two lightweight selective state space model (SSM) architectures for human activity recognition (HAR) on resource-constrained devices: CI-BabyMamba-HAR with a channel-independent stem and Crossover-BiDir-BabyMamba-HAR with an early-fusion stem. Both incorporate weight-tied bidirectional scanning and gated temporal attention pooling. The central claim is that Crossover-BiDir-BabyMamba-HAR achieves an average 86.52% F1-score across eight benchmarks with 27K parameters and 2.21M MACs, matching TinyHAR (86.16%) while using 11x fewer MACs on high-channel datasets; on-device deployments on Raspberry Pi Pico 2 and ESP32 yield >99.2% PyTorch parity with full 8/8 coverage, 154.4 ms latency on ESP32, and ablation gains up to 8.94% from the proposed components.
Significance. If the empirical results hold under statistical scrutiny, the work is significant for filling the unexplored TinyML design space for SSMs in sensor-based HAR. It supplies concrete efficiency metrics (parameter counts, MACs, latency), hardware-validated parity, and a memory optimization reducing peak footprint from O(B·d_model·L·d_state) to O(B·d_model·d_state), along with practical principles such as weight-tied bidirectional scanning. These elements offer actionable guidance for deploying linear-time sequence models on microcontrollers beyond the specific eight benchmarks tested.
major comments (2)
- [Abstract and experimental results] Abstract and results presentation: the average F1-score of 86.52%, the parity with TinyHAR at 86.16%, and the ablation improvements (up to 8.42% from bidirectional scanning and 8.94% from gated temporal attention pooling) are reported as single-run point estimates with no error bars, standard deviations, multi-seed averages, or statistical significance tests. This directly affects the load-bearing central claim that the architectures match prior work while establishing reliable TinyML SSM principles, as the absence of variance measures leaves open whether the reported gains and parity are reproducible across training runs or data splits.
- [Deployment and hardware results] On-device evaluation: the claims of >99.2% PyTorch parity, full 8/8 dataset coverage, and superiority over INT8 TFLite baselines (e.g., TinyHAR at 60.4% parity) rest on the specific mixed-precision C++ runtime and lifetime-aware memory management, yet no quantitative before/after memory measurements or failure-case analysis for the eight benchmarks are provided to confirm that the optimizations preserve accuracy without hidden trade-offs.
minor comments (2)
- [Architecture] The description of the channel-independent stem versus early-fusion stem would benefit from an explicit comparison table of complexity scaling with channel count to clarify the 'channel count independent complexity' claim.
- [Experimental setup] Training hyperparameters, exact data splits for the eight benchmarks, and optimizer details are referenced only at a high level; adding these to a reproducibility section or appendix would strengthen the manuscript without altering the core claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and have revised the manuscript to incorporate additional statistical reporting and quantitative hardware measurements where feasible.
read point-by-point responses
-
Referee: [Abstract and experimental results] Abstract and results presentation: the average F1-score of 86.52%, the parity with TinyHAR at 86.16%, and the ablation improvements (up to 8.42% from bidirectional scanning and 8.94% from gated temporal attention pooling) are reported as single-run point estimates with no error bars, standard deviations, multi-seed averages, or statistical significance tests. This directly affects the load-bearing central claim that the architectures match prior work while establishing reliable TinyML SSM principles, as the absence of variance measures leaves open whether the reported gains and parity are reproducible across training runs or data splits.
Authors: We agree that reporting single-run point estimates without variance measures limits the strength of the central claims regarding reproducibility. While single-run results are common in resource-intensive TinyML evaluations, we will revise the manuscript to include averages and standard deviations over five random seeds for the main F1-scores, parity metrics, and ablations on the eight benchmarks. We will also add a brief discussion of observed run-to-run variability. revision: yes
-
Referee: [Deployment and hardware results] On-device evaluation: the claims of >99.2% PyTorch parity, full 8/8 dataset coverage, and superiority over INT8 TFLite baselines (e.g., TinyHAR at 60.4% parity) rest on the specific mixed-precision C++ runtime and lifetime-aware memory management, yet no quantitative before/after memory measurements or failure-case analysis for the eight benchmarks are provided to confirm that the optimizations preserve accuracy without hidden trade-offs.
Authors: We acknowledge the value of explicit quantitative memory data and failure analysis. The current manuscript describes the asymptotic reduction in peak memory but does not report concrete before/after RAM measurements or per-benchmark failure cases. In the revised version we will add a table with measured peak memory usage (in KB) on ESP32 and Raspberry Pi Pico 2 for each of the eight datasets, both before and after the lifetime-aware optimization, along with notes on any accuracy trade-offs or deployment failures encountered. revision: yes
Circularity Check
No circularity: purely empirical architecture proposal and benchmark evaluation
full rationale
The paper proposes two new lightweight SSM-based architectures (CI-BabyMamba-HAR and Crossover-BiDir-BabyMamba-HAR) with specific design choices such as weight-tied bidirectional scanning and gated temporal attention pooling. All central claims consist of direct empirical measurements: average F1-scores on eight public benchmarks, parameter/MAC counts, ablation deltas, on-device latency, and PyTorch parity after custom C++ implementation. No derivation chain, first-principles equations, fitted parameters renamed as predictions, or self-citation load-bearing steps exist. Comparisons are to external baselines (TinyHAR, etc.) on standard datasets; ablations simply report observed accuracy changes from adding components. The work is self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The eight HAR benchmarks used are representative of real-world sensor data distributions and noise characteristics.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Crossover-BiDir-BabyMamba-HAR ... weight tied bidirectional scanning and gated temporal attention pooling ... O(L·dmodel·dstate) linear ... 8/8 dataset coverage
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
bidirectional scanning contributes up to 8.42% F1-score improvement
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-Time Sequence Modeling with Selective State Spaces,”arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Efficiently Modeling Long Sequences with Structured State Spaces,
A. Gu, K. Goel, and C. Ré, “Efficiently Modeling Long Sequences with Structured State Spaces,” inProc. Int. Conf. Learning Representations (ICLR), 2022
work page 2022
-
[3]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention Is All You Need,” inAdvances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[4]
F. J. Ordóñez and D. Roggen, “Deep Convolutional and LSTM Recur- rent Neural Networks for Multimodal Wearable Activity Recognition,” Sensors, vol. 16, no. 1, p. 115, 2016
work page 2016
-
[5]
TinyHAR: A Lightweight Deep Learning Model Designed for Human Activity Recognition,
Y . Zhou, H. Zhao, Y . Huang, T. Riedel, and M. Beigl, “TinyHAR: A Lightweight Deep Learning Model Designed for Human Activity Recognition,” inProc. ACM Int. Symp. Wearable Computers (ISWC), 2022, pp. 89–93
work page 2022
-
[6]
S. Bian, M. Liu, V . F. Rey, D. Geissler, and P. Lukowicz, "TinierHAR: Towards Ultra-Lightweight Deep Learning Models for Efficient Human Activity Recognition on Edge Devices," inProc. ACM Int. Symp. Wearable Computers (ISWC), 2025, pp. 163–169
work page 2025
-
[7]
Decoupled Weight Decay Regularization,
I. Loshchilov and F. Hutter, “Decoupled Weight Decay Regularization,” inProc. Int. Conf. Learning Representations (ICLR), 2019
work page 2019
-
[8]
A. C. Muhoza, E. Bergeret, C. Brdys, and F. Gary, “Power Consumption Reduction for IoT Devices Thanks to Edge-AI: Application to Human Activity Recognition,”Internet of Things, vol. 24, p. 100930, 2023
work page 2023
-
[9]
D. Geissler, D. Nshimyimana, V . F. Rey, S. Suh, B. Zhou, and P. Lukowicz, “Beyond Confusion: A Fine-grained Dialectical Examination of Human Activity Recognition Benchmark Datasets,”arXiv preprint arXiv:2412.09037, 2024
-
[10]
LHAR: Lightweight Human Activity Recognition on Knowledge Dis- tillation,
S. Deng, J. Chen, D. Teng, C. Yang, D. Chen, T. Jia, and H. Wang, “LHAR: Lightweight Human Activity Recognition on Knowledge Dis- tillation,”IEEE J. Biomed. Health Inform., 2023
work page 2023
-
[11]
W.-S. Lim, W. Seo, D.-W. Kim, and J. Lee, “Efficient Human Activity Recognition Using Lookup Table-Based Neural Architecture Search for Mobile Devices,”IEEE Access, vol. 11, pp. 71727–71738, 2023
work page 2023
-
[12]
Y . Zhou, T. King, H. Zhao, Y . Huang, T. Riedel, and M. Beigl, “MLP- HAR: Boosting Performance and Efficiency of HAR Models on Edge Devices with Purely Fully Connected Layers,” inProc. ACM Int. Symp. Wearable Computers (ISWC), 2024, pp. 133–139
work page 2024
-
[13]
Are Transformers a Useful Tool for Tiny Devices in Human Activity Recognition?,
E. Lattanzi, L. Calisti, and C. Contoli, “Are Transformers a Useful Tool for Tiny Devices in Human Activity Recognition?,” inProc. Int. Conf. Advances in Artificial Intelligence (ICAAI), 2024, pp. 339–344
work page 2024
-
[14]
Z. Hong, Z. Li, S. Zhong, W. Lyu, H. Wang, Y . Ding, T. He, and D. Zhang, “CrossHAR: Generalizing Cross-Dataset Human Activity Recognition via Hierarchical Self-Supervised Pretraining,”Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., vol. 8, no. 2, pp. 1–26, 2024
work page 2024
-
[15]
S. Li, T. Zhu, F. Duan, L. Chen, H. Ning, C. Nugent, and Y . Wan, “HARMamba: Efficient and Lightweight Wearable Sensor Human Activity Recognition Based on Bidirectional Mamba,”arXiv preprint arXiv:2403.20183, 2024
-
[16]
Deep, Convolutional, and Recurrent Models for Human Activity Recognition using Wearables
N. Y . Hammerla, S. Halloran, and T. Plötz, “Deep, Convolutional, and Recurrent Models for Human Activity Recognition Using Wearables,” arXiv preprint arXiv:1604.08880, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
On Attention Models for Human Activity Recognition,
V . S. Murahari and T. Plötz, “On Attention Models for Human Activity Recognition,” inProc. ACM Int. Symp. Wearable Computers (ISWC), 2018, pp. 100–103
work page 2018
-
[18]
A Public Domain Dataset for Human Activity Recognition Using Smartphones,
D. Anguita, A. Ghio, L. Oneto, X. Parra, and J. L. Reyes-Ortiz, “A Public Domain Dataset for Human Activity Recognition Using Smartphones,” inProc. European Symp. Artificial Neural Networks (ESANN), 2013
work page 2013
-
[19]
Mobile Sensor Data Anonymization,
M. Malekzadeh, R. G. Clegg, A. Cavallaro, and H. Haddadi, “Mobile Sensor Data Anonymization,” inProc. ACM/IEEE Int. Conf. Internet of Things Design and Implementation (IoTDI), 2019
work page 2019
-
[20]
Activity Recogni- tion Using Cell Phone Accelerometers,
J. R. Kwapisz, G. M. Weiss, and S. A. Moore, “Activity Recogni- tion Using Cell Phone Accelerometers,”ACM SIGKDD Explorations Newsletter, vol. 12, no. 2, pp. 74–82, 2011
work page 2011
-
[21]
Introducing a New Benchmarked Dataset for Activity Monitoring,
A. Reiss and D. Stricker, “Introducing a New Benchmarked Dataset for Activity Monitoring,” inProc. IEEE Int. Symp. Wearable Computers (ISWC), 2012, pp. 108–109
work page 2012
-
[22]
The Opportunity Challenge: A Benchmark Database for On-Body Sensor-Based Activity Recognition,
R. Chavarriaga, H. Sagha, A. Calatroni, S. T. Digumarti, G. Tröster, J. del R. Millán, and D. Roggen, “The Opportunity Challenge: A Benchmark Database for On-Body Sensor-Based Activity Recognition,” Pattern Recognition Letters, vol. 34, no. 15, pp. 2033–2042, 2013
work page 2033
-
[23]
UniMiB SHAR: A Dataset for Human Activity Recognition Using Acceleration Data from Smartphones,
D. Micucci, M. Mobilio, and P. Napoletano, “UniMiB SHAR: A Dataset for Human Activity Recognition Using Acceleration Data from Smartphones,”Applied Sciences, vol. 7, no. 10, p. 1101, 2017
work page 2017
-
[24]
Activity Recognition from On-Body Sensors: Accuracy- Power Trade-Off by Dynamic Sensor Selection,
P. Zappi, C. Lombriser, T. Stiefmeier, E. Farella, D. Roggen, L. Benini, and G. Tröster, “Activity Recognition from On-Body Sensors: Accuracy- Power Trade-Off by Dynamic Sensor Selection,” inProc. European Conf. Wireless Sensor Networks (EWSN), Springer, 2008, pp. 17–33
work page 2008
-
[25]
Wearable Assistant for Parkinson’s Disease Patients with the Freezing of Gait Symptom,
M. Bächlin, M. Plotnik, D. Roggen, I. Maidan, J. M. Hausdorff, N. Giladi, and G. Tröster, “Wearable Assistant for Parkinson’s Disease Patients with the Freezing of Gait Symptom,”IEEE Trans. Inf. Technol. Biomed., vol. 14, no. 2, pp. 436–446, 2010
work page 2010
-
[26]
Improv- ing Deep Learning for HAR with Shallow LSTMs,
M. Bock, A. Hölzemann, M. Moeller, and K. Van Laerhoven, “Improv- ing Deep Learning for HAR with Shallow LSTMs,” inProc. ACM Int. Symp. Wearable Computers (ISWC), 2021, pp. 7–12
work page 2021
-
[27]
A. Abedin, M. Ehsanpour, Q. Shi, H. Rezatofighi, and D. C. Ranasinghe, “Attend and Discriminate: Beyond the State-of-the-Art for Human Activity Recognition Using Wearable Sensors,”Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., vol. 5, no. 1, pp. 1–22, 2021
work page 2021
-
[28]
SelfHAR: Improving Human Activity Recognition Through Self-Training with Unlabeled Data,
C. I. Tang, I. Perez-Pozuelo, D. Spathis, S. Brage, N. Wareham, and C. Mascolo, “SelfHAR: Improving Human Activity Recognition Through Self-Training with Unlabeled Data,”arXiv preprint arXiv:2102.06073, 2021
-
[29]
Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances,
S. Zhang, Y . Li, S. Zhang, F. Shahabi, S. Xia, Y . Deng, and N. Alshurafa, “Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances,”Sensors, vol. 22, no. 4, p. 1476, 2022
work page 2022
-
[30]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.