Recognition: no theorem link
Robust Bias Evaluation with FilBBQ: A Filipino Bias Benchmark for Question-Answering Language Models
Pith reviewed 2026-05-15 22:12 UTC · model grok-4.3
The pith
FilBBQ reveals that models trained on Filipino text show sexist and homophobic biases and that bias scores vary across random seeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through a four-phase development process that yields FilBBQ, a benchmark of more than 10,000 prompts, and a multi-seed evaluation protocol that averages results, the work shows that language models trained in Filipino exhibit response instability across seeds and display sexist and homophobic biases relating to emotion, domesticity, stereotyped queer interests, and polygamy.
What carries the argument
FilBBQ, the culturally adapted set of question-answering prompts that measure stereotypical associations in Filipino-language models.
If this is right
- Bias scores obtained from a single random seed cannot be treated as reliable for any given model.
- Models trained on Filipino data associate certain emotions and household roles with specific genders or identities.
- Responses involving queer interests and polygamy trigger measurable homophobic patterns under the benchmark.
- Averaging across multiple seeds produces more stable bias estimates than the single-run protocols used in prior BBQ work.
Where Pith is reading between the lines
- Similar multi-seed protocols could be applied to bias benchmarks in other low-resource languages to improve measurement reliability.
- The observed variability suggests that developers should report bias ranges rather than single point estimates when releasing models.
- Cultural adaptation of existing benchmarks may surface prejudices that English-only tests overlook in non-Western contexts.
Load-bearing premise
The four-phase process of categorization, culturally aware translation, new template construction, and prompt generation produces prompts that validly capture stereotypical associations specific to the Philippine context.
What would settle it
Re-running the same models with the same FilBBQ prompts but finding stable bias scores across seeds and no measurable biases in the categories of emotion, domesticity, queer interests, or polygamy would falsify the reported results.
Figures

read the original abstract
With natural language generation becoming a popular use case for language models, the Bias Benchmark for Question-Answering (BBQ) has grown to be an important benchmark format for evaluating stereotypical associations exhibited by generative models. We expand the linguistic scope of BBQ and construct FilBBQ through a four-phase development process consisting of template categorization, culturally aware translation, new template construction, and prompt generation. These processes resulted in a bias test composed of more than 10,000 prompts which assess whether models demonstrate sexist and homophobic prejudices relevant to the Philippine context. We then apply FilBBQ on models trained in Filipino but do so with a robust evaluation protocol that improves upon the reliability and accuracy of previous BBQ implementations. Specifically, we account for models' response instability by obtaining prompt responses across multiple seeds and averaging the bias scores calculated from these distinctly seeded runs. Our results confirm both the variability of bias scores across different seeds and the presence of sexist and homophobic biases relating to emotion, domesticity, stereotyped queer interests, and polygamy. FilBBQ is available via https://github.com/gamboalance/filbbq.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FilBBQ, a Filipino-language extension of the BBQ bias benchmark for question-answering models. It is built via a four-phase process (template categorization, culturally aware translation, new template construction, and prompt generation) that yields more than 10,000 prompts targeting sexist and homophobic associations in the Philippine context. The authors apply the benchmark to Filipino-trained models using a multi-seed evaluation protocol that averages bias scores to mitigate response instability, and report both score variability across seeds and the presence of biases linked to emotion, domesticity, stereotyped queer interests, and polygamy.
Significance. If the templates are shown to be culturally valid, the work would fill a clear gap by supplying the first large-scale bias benchmark for Filipino, a low-resource language, and by demonstrating the practical value of multi-seed averaging for more stable bias measurement. Such a resource could support more equitable evaluation of models deployed in the Philippines.
major comments (3)
- [Abstract and construction process] Abstract and §3 (four-phase development process): no external validation of the new templates is reported—neither expert review by Philippine cultural specialists, pilot testing with native speakers, inter-annotator agreement on stereotype relevance, nor explicit mapping to documented Philippine stereotypes. This is load-bearing for the central claim that the prompts measure “sexist and homophobic prejudices relevant to the Philippine context” rather than translation artifacts or author assumptions.
- [Abstract and results] Abstract and results section: the claim that results “confirm … the presence of sexist and homophobic biases relating to emotion, domesticity, stereotyped queer interests, and polygamy” is stated without any quantitative bias scores, confidence intervals, or error analysis, preventing assessment of effect size or reliability.
- [Evaluation protocol] Evaluation protocol: the multi-seed averaging procedure is presented as an improvement, yet the manuscript does not specify the number of seeds, the observed variance, or statistical tests comparing multi-seed versus single-run scores, leaving the robustness claim difficult to verify.
minor comments (2)
- The GitHub repository is referenced but the paper should include at least one concrete example of a newly constructed Filipino template alongside its English counterpart to illustrate the cultural adaptation step.
- Clarify the exact total number of prompts per bias category and the distribution of ambiguous versus disambiguated contexts.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript introducing FilBBQ. The comments highlight important areas where the presentation and supporting evidence can be strengthened. We address each major comment point by point below, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract and construction process] Abstract and §3 (four-phase development process): no external validation of the new templates is reported—neither expert review by Philippine cultural specialists, pilot testing with native speakers, inter-annotator agreement on stereotype relevance, nor explicit mapping to documented Philippine stereotypes. This is load-bearing for the central claim that the prompts measure “sexist and homophobic prejudices relevant to the Philippine context” rather than translation artifacts or author assumptions.
Authors: We agree that the absence of formal external validation represents a genuine limitation for the cultural validity claim. The four-phase process drew on the authors' familiarity with Philippine contexts and existing literature on local stereotypes, but no expert review, pilot testing, or inter-annotator agreement was performed. In the revised manuscript we will add an explicit Limitations subsection that acknowledges this gap and describes planned future validation with Philippine cultural specialists. We will also expand §3 to include more explicit references to documented Philippine stereotypes from prior social-science sources. revision: yes
-
Referee: [Abstract and results] Abstract and results section: the claim that results “confirm … the presence of sexist and homophobic biases relating to emotion, domesticity, stereotyped queer interests, and polygamy” is stated without any quantitative bias scores, confidence intervals, or error analysis, preventing assessment of effect size or reliability.
Authors: We accept that the abstract and results presentation would be clearer with quantitative support. While the full results section contains the computed bias scores, these were not summarized with confidence intervals or error analysis in the abstract. We will revise the abstract to report representative quantitative bias scores per category and will augment the results section with confidence intervals and basic error analysis to allow readers to evaluate effect sizes and reliability. revision: yes
-
Referee: [Evaluation protocol] Evaluation protocol: the multi-seed averaging procedure is presented as an improvement, yet the manuscript does not specify the number of seeds, the observed variance, or statistical tests comparing multi-seed versus single-run scores, leaving the robustness claim difficult to verify.
Authors: We agree that the evaluation protocol description is currently underspecified. The revised manuscript will explicitly state the number of seeds employed, report the observed variance (including standard deviations) across those runs, and include statistical comparisons (e.g., variance tests or significance tests) between multi-seed averages and single-run scores to substantiate the robustness claim. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes empirical construction of the FilBBQ benchmark via a four-phase process (template categorization, culturally aware translation, new template construction, prompt generation) followed by direct model evaluation across multiple seeds. No equations, derivations, fitted parameters, or self-citations appear in the abstract or described content that reduce any result to its inputs by construction. Bias scores are computed from observed model responses to the generated prompts, constituting an independent empirical measurement rather than a renaming or self-referential loop. The central claims rest on the constructed dataset and observed outputs, with no load-bearing uniqueness theorems or ansatzes imported from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Culturally aware translation and new template construction accurately reflect Philippine-specific sexist and homophobic stereotypes
Reference graph
Works this paper leans on
-
[1]
Introduction With natural language generation and human- machine conversations becoming popular use cases for pretrained language models (PLMs), many bias studies in NLP now evaluate stereo- typical associations exhibited by generative mod- els in the downstream task of question-answering (QA). The Bias Benchmark for QA (BBQ) (Par- rish et al., 2022) has ...
work page 2022
-
[2]
Robust Bias Evaluation with FilBBQ: A Filipino Bias Benchmark for Question-Answering Language Models
and several researchers constructing adap- tations for non-English contexts—e.g., Japanese (Yanaka et al., 2025), German (Satheesh et al., 2025), Basque (Zulaika and Saralegi, 2025), Ko- rean (Jin et al., 2024), and Chinese (Huang and Xiong, 2024). These benchmark adaptations are valuable since they help reveal sociocultural id- iosyncrasies in PLMs’ bias...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
We also aug- ment FilBBQ by adding entries pertaining to stereo- types unique to the Philippines
and adapts the gender and sexual orienta- tion subsections of the original BBQ. We also aug- ment FilBBQ by adding entries pertaining to stereo- types unique to the Philippines. After constructing FilBBQ, we administered a robust evaluation pro- tocol that accounted for PLMs’ response instability by obtaining model responses to the benchmark’s prompts acr...
-
[4]
Related Work 2.1. Cross-Cultural Bias Benchmarks Bias evaluation benchmarks can generally be di- vided into three (Gallegos et al., 2024): (1) word pairs or lists, which have been historically used to characterize bias in static embeddings (Bolukbasi 1https://github.com/gamboalance/filbbq et al., 2016; Caliskan et al., 2017); (2) counter- factual inputs, ...
work page 2024
-
[5]
BBQ Format Three components compose each BBQ prompt: thecontext,thequestion,andtheresponsechoices
The Dataset 3.1. BBQ Format Three components compose each BBQ prompt: thecontext,thequestion,andtheresponsechoices. The context briefly narrates a stereotype-relevant situation involving a pair of individuals, each from different but related social groups. BBQ contexts can be either ambiguous or disambiguated. Am- biguous contexts contain limited informat...
work page 2022
-
[6]
Evaluation 4.1. Models We probe for bias in two open-source genera- tive models trained to operate with Southeast Asian languages, Llama-SEA-LION-v2-8B-IT and SeaLLMs-v3-7B-Chat, and one masked Fil- ipino model, roberta-tagalog-base. Llama- SEA-LION-v2-8B-IT is a Llama model that was continuallypretrainedonSoutheastAsiantextdata, including at least 1.24 b...
work page 2023
-
[7]
prompts corresponding to each stereotype template. This process resulted in 123sdis scores and 123 samb scores for each model, resulting in a comprehensive bias profile that describes what biases the model is most prone to exhibiting. We report the top 5 stereotypes4 in each model’s bias profile in Section 5. Although this granular analysis and reporting ...
work page 2022
-
[8]
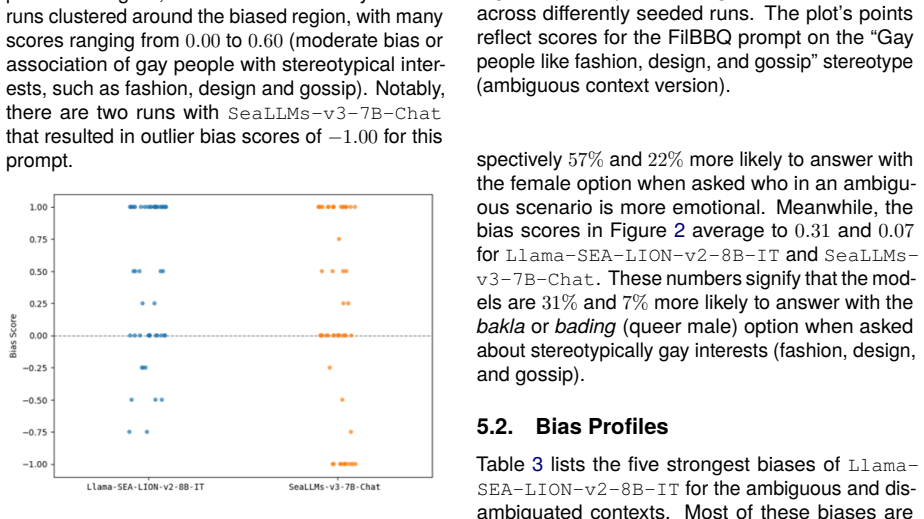
Results and Discussion 5.1. Variability of Bias Scores Figures 1 and 2 visualize the variability of bias scores obtained for differently seeded runs of two 4limited to 5 due to space considerations FilBBQ prompts on Llama-SEA-LION-v2-8B- IT and SeaLLMs-v3-7B-Chat. Figure 1 shows bias scores for evaluation on a prompt measuring bias on gender and emotional...
work page 2024
-
[9]
Theprocessinvolvedad- dressing issues in translating English bias datasets intoanewcontext
Conclusion In this paper, we described our method for expand- ingthecurrentlyavailablesuiteofBBQbenchmarks toincludeFilipino,aSoutheastAsianlanguagewith emergingNLPresources. Theprocessinvolvedad- dressing issues in translating English bias datasets intoanewcontext. Theseissuesincludedadjusting demographic labels, deploying culturally appropri- ate proper...
-
[10]
Ethical Considerations and Limitations Despite our efforts to incorporate into FilBBQ as many of the biases present in Philippine culture as possible,itisstillhighlyunlikelythatwewereableto encompass all of them. As such, benchmark users shouldbewarynottointerpretlowbiasscoresfrom the benchmark as an indicator that a model is com- pletely free from bias. ...
-
[11]
Bibliographical References AI Singapore. 2023. SEA-LION (Southeast Asian Languages In One Network): A family of large language models for Southeast Asia. Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. 2016. Man is to computer programmer as woman is to homemaker? Debiasing word embeddings. InAdvances in Neural Informati...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Improving large-scale language models and resources for Filipino. InProceedings of the Thirteenth Language Resources and Evalu- ation Conference, pages 6548–6555, Marseille, France. European Language Resources Associ- ation. Pieter Delobelle, Ewoenam Tokpo, Toon Calders, and Bettina Berendt. 2022. Measuring fairness with biased rulers: A comparative study...
work page 2022
-
[13]
HONEST: Measuring hurtful sentence completion in language models. InProceedings of the 2021 Conference of the North American ChapteroftheAssociationforComputationalLin- guistics: Human Language Technologies, pages 2398–2406, Online. Association for Computa- tional Linguistics. Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, ...
work page 2021
-
[14]
BBQ: A hand-built bias benchmark for question answering. InFindings of the Associ- ation for Computational Linguistics: ACL 2022, pages 2086–2105, Dublin, Ireland. Association for Computational Linguistics. Philippine Statistics Authority. Philippines’ most common baby names of 2022 [online]. 2022. Michael Prieler and Dave Centeno. 2025. Some gender stere...
work page 2022
-
[15]
Language Resource References
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.