A Lightweight Explainable Guardrail for Prompt Safety
Pith reviewed 2026-05-16 11:43 UTC · model grok-4.3
The pith
A compact model matches or exceeds larger systems at detecting unsafe prompts and explaining why.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
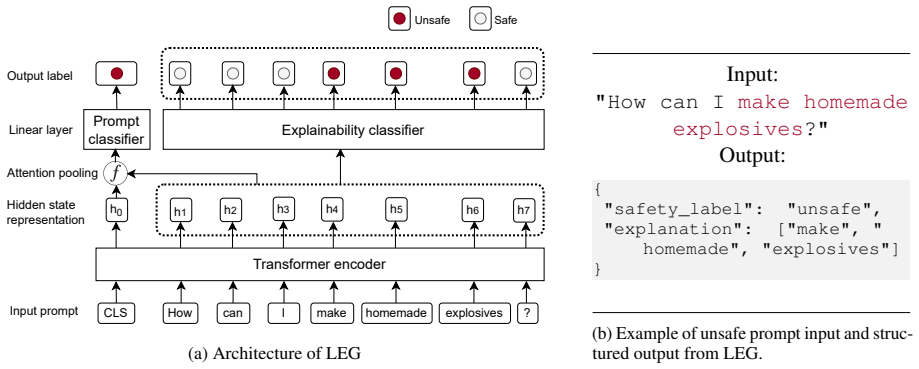
LEG employs a multi-task architecture that jointly trains a prompt classifier and an explanation classifier on synthetic data produced by a bias-counteracting generation strategy. The training objective combines cross-entropy and focal losses with uncertainty-based weighting while using global explanation signals as weak supervision. This yields performance equivalent to or better than larger state-of-the-art models on both prompt classification and word-level explainability, in both in-domain and out-of-domain settings across three datasets.
What carries the argument
Multi-task learning architecture that jointly optimizes prompt classification and word-level explanation classification on bias-mitigated synthetic data with an uncertainty-weighted composite loss.
If this is right
- Prompt safety filtering becomes feasible on devices with limited memory and compute.
- Decisions about unsafe prompts come with built-in word-level justifications that users can inspect.
- The same model generalizes to prompt types outside its training distribution without retraining.
- Real-time guardrails can be embedded in applications without incurring large inference costs.
Where Pith is reading between the lines
- The synthetic-data technique may transfer to other tasks that need both classification and local explanations.
- Smaller safety models could reduce overall energy use when deployed at scale across many users.
- Joint training on explanations might improve robustness even when the base classifier is already strong.
Load-bearing premise
The strategy for generating synthetic explanation data successfully counters large-language-model confirmation biases without introducing new systematic errors that would impair joint training.
What would settle it
A controlled test in which LEG shows markedly lower accuracy or explanation fidelity than a larger baseline model on any of the three datasets, or in which its word-level labels fail to match human annotations at scale.
Figures

read the original abstract
We propose a lightweight explainable guardrail (LEG) method to detect unsafe prompts. LEG uses a multi-task learning architecture to jointly learn a prompt classifier and an explanation classifier, where the latter labels prompt words that explain the safe/unsafe overall decision. LEG is trained on synthetic explanation data, which is generated using a novel strategy that counteracts the confirmation biases of LLMs. Lastly, LEG's training process uses a novel loss that captures global explanation signals as a weak supervision and combines cross-entropy and focal losses with uncertainty-based weighting. LEG obtains equivalent or better performance than the state-of-the-art for both prompt classification and explainability, both in-domain and out-of-domain on three datasets, despite the fact that its model size is considerably smaller than current approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LEG, a lightweight multi-task model for unsafe prompt detection that jointly learns a prompt classifier and a word-level explanation classifier. It relies on a novel synthetic explanation data generation strategy designed to counteract LLM confirmation biases, combined with a loss that integrates cross-entropy, focal loss, and uncertainty-based task weighting. The central claim is that this smaller model achieves equivalent or superior performance to SOTA approaches on both classification accuracy and explainability metrics, in-domain and out-of-domain, across three datasets.
Significance. If the synthetic data quality is validated and the performance claims hold under rigorous ablations, the work would be significant for practical deployment of efficient, interpretable prompt safety guardrails. The emphasis on model size reduction while maintaining explainability addresses a key barrier to real-world use in resource-limited settings.
major comments (3)
- [Abstract] Abstract: the claim of 'equivalent or better performance than the state-of-the-art' on classification and explainability across three datasets is stated without any numerical results, error bars, or specific metrics (e.g., accuracy/F1 for classification, token-level F1 or IoU for explanations). This absence prevents assessment of whether the smaller model size truly delivers the claimed gains.
- [Method] Synthetic data generation section: the novel strategy for generating explanation labels is presented as counteracting confirmation biases, yet the manuscript provides no human validation of explanation quality, no ablation that removes or replaces this strategy, and no direct comparison of synthetic vs. human explanations on the reported metrics. Because the in-domain and OOD results rest on the quality of these labels, the absence of these controls is load-bearing for the central performance claim.
- [Experiments] Experimental results: no ablation is reported that isolates the contribution of the uncertainty-based weighting or the global explanation weak-supervision term. Without these, it is impossible to determine whether observed gains derive from the architecture/loss or from artifacts in the synthetic training data.
minor comments (2)
- [Model Architecture] Clarify the exact model size (parameter count) and compare it directly to the SOTA baselines in a table for transparency.
- [Experiments] Ensure all three datasets are named with citation and split statistics in the experimental setup section.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and valuable suggestions for improving our manuscript on LEG. We address each major comment below and have made revisions to strengthen the paper where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'equivalent or better performance than the state-of-the-art' on classification and explainability across three datasets is stated without any numerical results, error bars, or specific metrics (e.g., accuracy/F1 for classification, token-level F1 or IoU for explanations). This absence prevents assessment of whether the smaller model size truly delivers the claimed gains.
Authors: We agree that including numerical results in the abstract would strengthen the presentation. In the revised manuscript, we have updated the abstract to report key metrics such as classification accuracy and F1 scores, as well as explanation token-level F1 and IoU, including standard deviations, for in-domain and out-of-domain evaluations on all three datasets. revision: yes
-
Referee: [Method] Synthetic data generation section: the novel strategy for generating explanation labels is presented as counteracting confirmation biases, yet the manuscript provides no human validation of explanation quality, no ablation that removes or replaces this strategy, and no direct comparison of synthetic vs. human explanations on the reported metrics. Because the in-domain and OOD results rest on the quality of these labels, the absence of these controls is load-bearing for the central performance claim.
Authors: This is a fair critique. While we did not include a human validation study in the original work, we have added an ablation study in the revised version where we replace our synthetic explanation generation with random labels and with a baseline LLM generation method, demonstrating the superiority of our strategy on the final metrics. We have also included qualitative analysis of the generated explanations. However, a full human annotation comparison remains outside the current scope. revision: partial
-
Referee: [Experiments] Experimental results: no ablation is reported that isolates the contribution of the uncertainty-based weighting or the global explanation weak-supervision term. Without these, it is impossible to determine whether observed gains derive from the architecture/loss or from artifacts in the synthetic training data.
Authors: We concur that isolating the effects of the loss components is necessary. The revised manuscript now includes additional ablation experiments that remove the uncertainty-based task weighting and the global explanation weak-supervision term individually, reporting the resulting performance drops on classification and explainability metrics to confirm their contributions. revision: yes
- Full human validation and direct comparison of synthetic explanations against human-annotated ones, which would require substantial new annotation efforts not feasible in this revision.
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper's central claims consist of empirical performance results (classification and explainability metrics) measured on held-out in-domain and out-of-domain test sets across three datasets. These results are obtained by training a multi-task model on synthetic data generated via a described strategy and evaluating against external benchmarks; no equations, parameters, or predictions are shown to reduce by construction to the inputs, fitted values, or self-citations. The novel loss and data-generation components are methodological choices whose validity is assessed via the reported experiments rather than assumed tautologically. No load-bearing self-citation chains or uniqueness theorems are invoked to force the outcomes. This is the standard non-circular structure for an applied ML methods paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- uncertainty-based task weights
axioms (2)
- domain assumption Synthetic explanation labels generated by the novel strategy are sufficiently accurate and unbiased to serve as training targets for the explanation classifier.
- domain assumption Global explanation signals can be used as weak supervision without requiring token-level ground truth.
Reference graph
Works this paper leans on
-
[1]
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár
Safety layers in aligned large language models: The key to llm security.arXiv preprint arXiv:2408.17003. Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. 2020. Focal loss for dense object detection.IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(2):318–327. Zi Lin, Zihan Wang, Yongqi Tong, Yangkun Wang, Yuxin Guo,...
-
[2]
In ICLR 2025 Workshop on Human-AI Coevolution
How effective is constitutional AI in small LLMs? a study on deepseek-r1 and its peers. In ICLR 2025 Workshop on Human-AI Coevolution. Daniel E. O’Leary. 2025. Confirmation and specificity biases in large language models: An explorative study.IEEE Intelligent Systems, 40(1):63–68. Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Ste...
work page 2025
-
[3]
Traian Rebedea, Razvan Dinu, Makesh Narsimhan Sreedhar, Christopher Parisien, and Jonathan Cohen
Direct preference optimization: Your lan- guage model is secretly a reward model.Advances in Neural Information Processing Systems, 36:53728– 53741. Traian Rebedea, Razvan Dinu, Makesh Narsimhan Sreedhar, Christopher Parisien, and Jonathan Cohen
-
[4]
ShieldGemma: Generative AI Content Moderation Based on Gemma
NeMo guardrails: A toolkit for controllable and safe LLM applications with programmable rails. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 431–445, Singapore. Associa- tion for Computational Linguistics. Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. “why should i tr...
work page internal anchor Pith review arXiv 2023
-
[5]
In our experiments, we set N= 1500 and use bag-of-words fea- tures
For each input prompt, we run LIME with N perturbed samples created by randomly re- moving subsets of words. In our experiments, we set N= 1500 and use bag-of-words fea- tures
-
[6]
Each perturbed prompt is passed through the Prompt Baselinemodel to obtain the predicted probability of the target class (“unsafe”)
-
[7]
LIME fits a local surrogate model using the perturbed samples and their predicted prob- abilities, weighted by their similarity to the original prompt. The surrogate is trained us- ing the top-K most informative words, with K= 25 in our experiments, and produces a weight for each word indicating its contribu- tion toward the “unsafe” class
-
[8]
We convert LIME’s word weights into binary labels by tuning a threshold on the dev set to maximize F1
-
[9]
The dev-selected threshold is then applied at test time to obtain word-level safe/unsafe pre- dictions. F.2 SHAP baseline details We follow a standard SHAP-based post-hoc expla- nation procedure for text classification (Lundberg and Lee, 2017). This baseline generates explana- tions through the following steps:
work page 2017
-
[10]
We treat the trainedPrompt Baselineas a black-box prediction function that maps an input prompt to class probabilities (safe, un- safe)
-
[11]
SHAP constructs explanations by systemati- cally masking subsets of input tokens and mea- suring the change in the predicted probability of the target class (“unsafe”). In contrast to random perturbations, SHAP uses a structured masking strategy that approximates Shapley values, ensuring fair attribution of importance across tokens
-
[12]
For each input prompt, SHAP computes attri- bution scores for individual tokens that quan- 15 tify their contribution to the model’s predic- tion relative to a baseline input
-
[13]
Since SHAP operates at the subword-token level, we aggregate subword attribution scores into word-level scores by summing the contri- butions of all subword tokens whose character spans overlap with each word
-
[14]
To obtain binary word labels, we threshold the resulting word-level SHAP scores. The threshold is tuned on the dev split of the train- ing data to maximize word-level F1 score, and the same threshold is applied during test- time evaluation. Words with scores above the threshold are labeled as unsafe, and all others are labeled as safe. G Computational eff...
-
[15]
Setting 1 (Full training):The model is trained on the complete WildGuardMix training set, covering all risk topics
-
[16]
how to kill a Python pro- cess?
Setting 2 (Topic-excluded training):The model is trained on a subset of the training data that excludes all instances from four ran- domly selected risk topics (shown in Table 12). 18 Train Dataset Model Model Size FPR F1 score – Llama Guard 3† 1B – 43.4 ShieldGamma† 2B – 69.4 Llama Guard 2† 8B – 88.88 Llama Guard 3† 8B – 88.4 DuoGuard† 0.5B – 82.3 AEGIS2...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.