Emotion Collider: Dual Hyperbolic Mirror Manifolds for Sentiment Recovery via Anti Emotion Reflection
Pith reviewed 2026-05-15 21:36 UTC · model grok-4.3
The pith
Hyperbolic hypergraphs with Poincare-ball embeddings recover multimodal emotions more accurately than Euclidean baselines, especially with missing or noisy data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
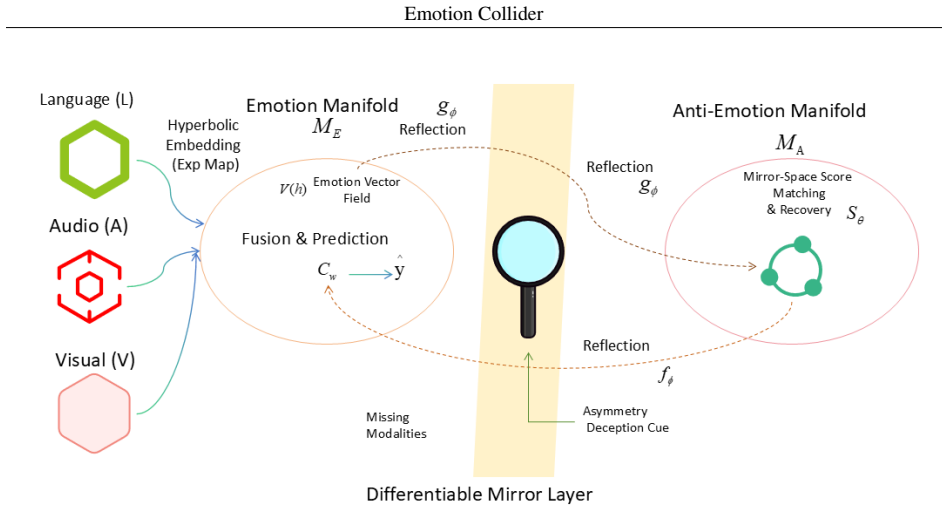
Emotion Collider represents modality hierarchies using Poincare-ball embeddings and performs fusion through a hypergraph mechanism that passes messages bidirectionally between nodes and hyperedges. To sharpen class separation, contrastive learning is formulated in hyperbolic space with decoupled radial and angular objectives. High-order semantic relations across time steps and modalities are preserved via adaptive hyperedge construction, producing robust representations that improve accuracy on multimodal emotion benchmarks particularly when modalities are partially available or contaminated by noise.
What carries the argument
Poincare-ball embeddings for hierarchical modality geometry combined with bidirectional hypergraph message passing and adaptive hyperedge construction for cross-modal fusion.
Load-bearing premise
That Poincare-ball embeddings plus bidirectional hypergraph message passing will preserve high-order semantic relations across time steps and modalities better than existing Euclidean or graph baselines.
What would settle it
A controlled experiment on a multimodal benchmark where one modality is progressively removed or replaced with Gaussian noise; if EC-Net accuracy falls to or below the Euclidean or graph baseline, the central claim is falsified.
Figures






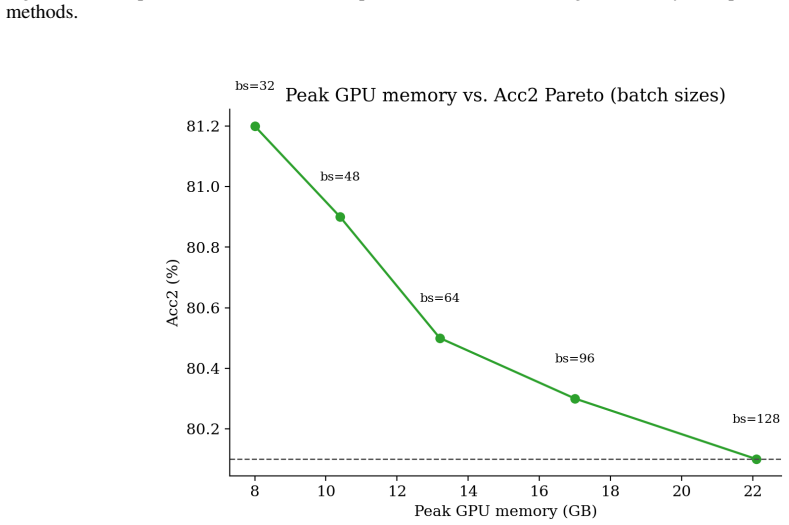

read the original abstract
Emotional expression underpins natural communication and effective human-computer interaction. We present Emotion Collider (EC-Net), a hyperbolic hypergraph framework for multimodal emotion and sentiment modeling. EC-Net represents modality hierarchies using Poincare-ball embeddings and performs fusion through a hypergraph mechanism that passes messages bidirectionally between nodes and hyperedges. To sharpen class separation, contrastive learning is formulated in hyperbolic space with decoupled radial and angular objectives. High-order semantic relations across time steps and modalities are preserved via adaptive hyperedge construction. Empirical results on standard multimodal emotion benchmarks show that EC-Net produces robust, semantically coherent representations and consistently improves accuracy, particularly when modalities are partially available or contaminated by noise. These findings indicate that explicit hierarchical geometry combined with hypergraph fusion is effective for resilient multimodal affect understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EC-Net, a hyperbolic hypergraph framework for multimodal emotion and sentiment modeling. Modality hierarchies are represented via Poincaré-ball embeddings; fusion occurs through bidirectional hypergraph message passing between nodes and hyperedges; contrastive learning is performed in hyperbolic space using decoupled radial and angular objectives; and adaptive hyperedge construction is used to preserve high-order semantic relations across time steps and modalities. The central empirical claim is that the resulting representations are robust and yield consistent accuracy gains on standard multimodal emotion benchmarks, especially under partial modality availability or noise.
Significance. If the claimed gains are reproducible and the architecture is shown to outperform strong Euclidean and graph baselines with proper controls, the work would demonstrate a concrete benefit of combining explicit hyperbolic hierarchy with hypergraph fusion for resilient multimodal affect modeling. This could inform future HCI systems that must operate with incomplete or noisy sensor streams.
major comments (1)
- Abstract: the central claim of consistent accuracy improvement 'particularly when modalities are partially available or contaminated by noise' is stated without any quantitative numbers, baseline names, or statistical significance tests. Because the soundness of the empirical support is load-bearing for the paper's contribution, the absence of even summary results prevents verification of whether the hyperbolic-hypergraph combination actually delivers the stated resilience.
minor comments (1)
- The title refers to 'Dual Hyperbolic Mirror Manifolds' and 'Anti Emotion Reflection' while the abstract describes EC-Net with Poincaré-ball embeddings and bidirectional hypergraph passing; the manuscript should clarify whether these are the same architecture or whether the title describes a distinct component.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment below and will revise the manuscript to improve the verifiability of our empirical claims.
read point-by-point responses
-
Referee: Abstract: the central claim of consistent accuracy improvement 'particularly when modalities are partially available or contaminated by noise' is stated without any quantitative numbers, baseline names, or statistical significance tests. Because the soundness of the empirical support is load-bearing for the paper's contribution, the absence of even summary results prevents verification of whether the hyperbolic-hypergraph combination actually delivers the stated resilience.
Authors: We agree that the abstract would be strengthened by including quantitative support for the central claim. In the revised manuscript, we will update the abstract to report specific accuracy improvements (e.g., gains on IEMOCAP and CMU-MOSEI under partial/noisy modality conditions), name the primary baselines, and reference statistical significance where available in the results. This change will make the empirical contribution immediately verifiable without altering the paper's technical content. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and architecture description introduce Poincare-ball embeddings for modality hierarchies, bidirectional hypergraph message passing for fusion, and hyperbolic contrastive learning with decoupled objectives. No equations, fitted parameters, or self-citations are shown that reduce any claimed prediction or result to the inputs by construction. The central claim of improved resilient multimodal affect understanding is tied to empirical results on standard benchmarks, which constitute external validation rather than internal circular reduction. The derivation remains self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EC-Net represents modality hierarchies using Poincaré-ball embeddings and performs fusion through a hypergraph mechanism... contrastive learning is formulated in hyperbolic space with decoupled radial and angular objectives.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Differentiable Mirror Layer... learnable involution (gϕ, fψ) with cycle loss and Riemannian importance re-weighting
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ringki Das and Thoudam Doren Singh. Multimodal sentiment analysis: a survey of methods, trends, and challenges.ACM Computing Surveys, 55(13s):1–38, 2023
work page 2023
-
[2]
Fen Liu, Jianfeng Chen, Weijie Tan, and Chang Cai. A multi-modal fusion method based on higher-order orthogonal iteration decomposition.Entropy, 23(10):1349, 2021
work page 2021
-
[3]
Sijie Mai, Ying Zeng, Shuangjia Zheng, and Haifeng Hu. Hybrid contrastive learning of tri-modal representation for multimodal sentiment analysis.IEEE Transactions on Affective Computing, 14(3):2276–2289, 2022
work page 2022
-
[4]
Hyperbolic diffusion embedding and distance for hierarchical representation learning
Ya-Wei Eileen Lin, Ronald R Coifman, Gal Mishne, and Ronen Talmon. Hyperbolic diffusion embedding and distance for hierarchical representation learning. InInternational Conference on Machine Learning, pages 21003–21025. PMLR, 2023
work page 2023
-
[5]
Jie Wang, Yan Yang, Keyu Liu, Zhuyang Xie, Fan Zhang, and Tianrui Li. Citenet: Cross-modal incongruity perception network for multimodal sentiment prediction.Knowledge-Based Systems, 295:111848, 2024
work page 2024
-
[6]
Keith April Araño, Carlotta Orsenigo, Mauricio Soto, and Carlo Vercellis. Multimodal sentiment and emotion recognition in hyperbolic space.Expert Systems with Applications, 184:115507, 2021
work page 2021
-
[7]
Label-aware hyperbolic embeddings for fine-grained emotion classification
Chih-Yao Chen, Tun Min Hung, Yi-Li Hsu, and Lun-Wei Ku. Label-aware hyperbolic embeddings for fine-grained emotion classification. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10947–10958, 2023
work page 2023
-
[8]
Deep Multimodal Learning with Missing Modality: A Survey
Renjie Wu, Hu Wang, Hsiang-Ting Chen, and Gustavo Carneiro. Deep multimodal learning with missing modality: A survey.arXiv preprint arXiv:2409.07825, 2024
work page internal anchor Pith review arXiv 2024
-
[9]
Missing modality robustness in semi-supervised multi-modal semantic segmentation
Harsh Maheshwari, Yen-Cheng Liu, and Zsolt Kira. Missing modality robustness in semi-supervised multi-modal semantic segmentation. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1020–1030, 2024
work page 2024
-
[10]
Yusheng Dai, Hang Chen, Jun Du, Ruoyu Wang, Shihao Chen, Haotian Wang, and Chin-Hui Lee. A study of dropout-induced modality bias on robustness to missing video frames for audio-visual speech recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27445–27455, 2024
work page 2024
-
[11]
Probing bert in hyperbolic spaces.arXiv preprint arXiv:2104.03869, 2021
Boli Chen, Yao Fu, Guangwei Xu, Pengjun Xie, Chuanqi Tan, Mosha Chen, and Liping Jing. Probing bert in hyperbolic spaces.arXiv preprint arXiv:2104.03869, 2021
-
[12]
Hype-han: Hyperbolic hierarchical attention network for semantic embedding
Chengkun Zhang and Junbin Gao. Hype-han: Hyperbolic hierarchical attention network for semantic embedding. InProceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, pages 3990–3996, 2021
work page 2021
-
[13]
YuKun Cao, Luobin Huang, and Yijia Tang. Petracker: Poincaré-based dual-strategy emotion tracker for emotion recognition in conversation.IEEE Transactions on Affective Computing, 2025
work page 2025
-
[14]
Yao Zheng, Guowei Chen, Wenchao Song, Yanchao Liu, and Pengzhou Zhang. Multimodal hyperbolic embedding and hyperbolic hypergraph fusion for emotion recognition in conversation. InProceedings of the 7th ACM International Conference on Multimedia in Asia, pages 1–8, 2025
work page 2025
-
[15]
Smil: Multimodal learning with severely missing modality
Mengmeng Ma, Jian Ren, Long Zhao, Sergey Tulyakov, Cathy Wu, and Xi Peng. Smil: Multimodal learning with severely missing modality. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 2302–2310, 2021. 17 Emotion Collider
work page 2021
-
[16]
Yunpeng Zhao, Cheng Chen, Qing You Pang, Quanzheng Li, Carol Tang, Beng-Ti Ang, and Yueming Jin. Dealing with all-stage missing modality: Towards a universal model with robust reconstruction and personalization.arXiv preprint arXiv:2406.01987, 2024
-
[17]
Jian Huang, Kun Jiang, Yuanyuan Pu, Zhengpeng Zhao, Qiuxia Yang, Jinjing Gu, and Dan Xu. Multimodal hypergraph network with contrastive learning for sentiment analysis.Neurocomputing, 627:129566, 2025
work page 2025
-
[18]
Xiaomei Zou, Taihao Li, and Shoukang Han. Microblog sentiment classification via a multilayer graph with social and semantic representations using hyperbolic learning.Information Sciences, page 122993, 2025
work page 2025
-
[19]
Vladimir Jacimovic and Marijan Markovic. Conformally natural families of probability distributions on hyperbolic disc with a view on geometric deep learning.arXiv preprint arXiv:2407.16733, 2024
-
[20]
Jaehyeong Jo and Sung Ju Hwang. Generative modeling on manifolds through mixture of riemannian diffusion processes.arXiv preprint arXiv:2310.07216, 2023
-
[21]
Hypformer: Exploring efficient transformer fully in hyperbolic space
Menglin Yang, Harshit Verma, Delvin Ce Zhang, Jiahong Liu, Irwin King, and Rex Ying. Hypformer: Exploring efficient transformer fully in hyperbolic space. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3770–3781, 2024
work page 2024
-
[22]
Hyperbolic vision transformers: Combining improvements in metric learning
Aleksandr Ermolov, Leyla Mirvakhabova, Valentin Khrulkov, Nicu Sebe, and Ivan Oseledets. Hyperbolic vision transformers: Combining improvements in metric learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7409–7419, 2022
work page 2022
-
[23]
Generalization error bound for hyperbolic ordinal embedding
Atsushi Suzuki, Atsushi Nitanda, Jing Wang, Linchuan Xu, Kenji Yamanishi, and Marc Cavazza. Generalization error bound for hyperbolic ordinal embedding. InInternational Conference on Machine Learning, pages 10011– 10021. PMLR, 2021
work page 2021
-
[24]
Rui Li, Chaozhuo Li, Yanming Shen, Zeyu Zhang, and Xu Chen. Generalizing knowledge graph embedding with universal orthogonal parameterization.arXiv preprint arXiv:2405.08540, 2024
-
[25]
Analyzing modality robustness in multimodal sentiment analysis.arXiv preprint arXiv:2205.15465, 2022
Devamanyu Hazarika, Yingting Li, Bo Cheng, Shuai Zhao, Roger Zimmermann, and Soujanya Poria. Analyzing modality robustness in multimodal sentiment analysis.arXiv preprint arXiv:2205.15465, 2022
-
[26]
Wasiq Khan, Keeley Crockett, James O’Shea, Abir Hussain, and Bilal M Khan. Deception in the eyes of deceiver: A computer vision and machine learning based automated deception detection.Expert Systems with Applications, 169:114341, 2021
work page 2021
-
[27]
Karsten Roth, Mark Ibrahim, Zeynep Akata, Pascal Vincent, and Diane Bouchacourt. Disentanglement of correlated factors via hausdorff factorized support.arXiv preprint arXiv:2210.07347, 2022
-
[28]
Daniella Horan, Eitan Richardson, and Yair Weiss. When is unsupervised disentanglement possible?Advances in Neural Information Processing Systems, 34:5150–5161, 2021
work page 2021
-
[29]
Guillermo Ortiz-Jimenez, Alessandro Favero, and Pascal Frossard. Task arithmetic in the tangent space: Improved editing of pre-trained models.Advances in Neural Information Processing Systems, 36:66727–66754, 2023
work page 2023
-
[30]
Set transformer: A framework for attention-based permutation-invariant neural networks
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee Whye Teh. Set transformer: A framework for attention-based permutation-invariant neural networks. InInternational conference on machine learning, pages 3744–3753. PMLR, 2019
work page 2019
-
[31]
Amir Zadeh, Rowan Zellers, Eli Pincus, and Louis-Philippe Morency. Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages.IEEE Intelligent Systems, 31(6):82–88, 2016
work page 2016
-
[32]
Memory fusion network for multi-view sequential learning
Amir Zadeh, Paul Pu Liang, Navonil Mazumder, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Memory fusion network for multi-view sequential learning. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[33]
Iemocap: Interactive emotional dyadic motion capture database
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N Chang, Sungbok Lee, and Shrikanth S Narayanan. Iemocap: Interactive emotional dyadic motion capture database. Language resources and evaluation, 42(4):335–359, 2008
work page 2008
-
[34]
Guimin Hu, Ting-En Lin, Yi Zhao, Guangming Lu, Yuchuan Wu, and Yongbin Li. Unimse: Towards unified multimodal sentiment analysis and emotion recognition.arXiv preprint arXiv:2211.11256, 2022. 18 Emotion Collider
-
[35]
Confede: Contrastive feature decomposition for multimodal sentiment analysis
Jiuding Yang, Yakun Yu, Di Niu, Weidong Guo, and Yu Xu. Confede: Contrastive feature decomposition for multimodal sentiment analysis. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7617–7630, 2023
work page 2023
-
[36]
Sijie Mai, Ying Zeng, and Haifeng Hu. Learning from the global view: Supervised contrastive learning of multimodal representation.Information Fusion, 100:101920, 2023
work page 2023
-
[37]
Zhuojia Wu, Qi Zhang, Duoqian Miao, Kun Yi, Wei Fan, and Liang Hu. Hydiscgan: A hybrid distributed cgan for audio-visual privacy preservation in multimodal sentiment analysis.arXiv preprint arXiv:2404.11938, 2024
-
[38]
Yang Yang, Xunde Dong, and Yupeng Qiang. Clgsi: a multimodal sentiment analysis framework based on contrastive learning guided by sentiment intensity. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 2099–2110, 2024
work page 2024
-
[39]
Dlf: Disentangled-language-focused multimodal sentiment analysis
Pan Wang, Qiang Zhou, Yawen Wu, Tianlong Chen, and Jingtong Hu. Dlf: Disentangled-language-focused multimodal sentiment analysis. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 21180–21188, 2025
work page 2025
-
[40]
Changqin Huang, Zhenheng Lin, Zhongmei Han, Qionghao Huang, Fan Jiang, and Xiaodi Huang. Pamoe-msa: polarity-aware mixture of experts network for multimodal sentiment analysis.International Journal of Multimedia Information Retrieval, 14(1):1–16, 2025
work page 2025
-
[41]
Msamba: Exploring multimodal sentiment analysis with state space models
Xilin He, Haijian Liang, Boyi Peng, Weicheng Xie, Muhammad Haris Khan, Siyang Song, and Zitong Yu. Msamba: Exploring multimodal sentiment analysis with state space models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 1309–1317, 2025
work page 2025
-
[42]
Two-stage finetuning of wav2vec 2.0 for speech emotion recognition with asr and gender pretraining
Yuan Gao, Chenhui Chu, and Tatsuya Kawahara. Two-stage finetuning of wav2vec 2.0 for speech emotion recognition with asr and gender pretraining. InProc. Interspeech, pages 3637–3641, 2023
work page 2023
-
[43]
Learning robust self-attention features for speech emotion recognition with label-adaptive mixup
Lei Kang, Lichao Zhang, and Dazhi Jiang. Learning robust self-attention features for speech emotion recognition with label-adaptive mixup. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
work page 2023
-
[44]
Improving speech emotion recognition with unsupervised speaking style transfer
Leyuan Qu, Wei Wang, Cornelius Weber, Pengcheng Yue, Taihao Li, and Stefan Wermter. Improving speech emotion recognition with unsupervised speaking style transfer. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 10101–10105. IEEE, 2024
work page 2024
-
[45]
Leveraging knowledge of modality experts for incomplete multimodal learning
Wenxin Xu, Hexin Jiang, and Xuefeng Liang. Leveraging knowledge of modality experts for incomplete multimodal learning. InProceedings of the 32nd ACM International Conference on Multimedia, pages 438–446, 2024
work page 2024
-
[46]
Lili Guo, Jie Li, Shifei Ding, and Jianwu Dang. Apin: Amplitude-and phase-aware interaction network for speech emotion recognition.Speech Communication, 169:103201, 2025
work page 2025
-
[47]
Yuanbo Fang, Xiaofen Xing, Zhaojie Chu, Yifeng Du, and Xiangmin Xu. Individual-aware attention modulation for unseen speaker emotion recognition.IEEE Transactions on Affective Computing, 2024
work page 2024
-
[48]
Gatem 2 former: Gated feature selection and expert modeling in multimodal emotion recognition
Weixiang Xu, Zhongren Dong, Runming Wang, Xinzhou Xu, and Zixing Zhang. Gatem 2 former: Gated feature selection and expert modeling in multimodal emotion recognition. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
work page 2025
-
[49]
Qifei Li, Yingming Gao, Yuhua Wen, Ziping Zhao, Ya Li, and Björn W Schuller. Seenet: A soft emotion expert and data augmentation method to enhance speech emotion recognition.IEEE Transactions on Affective Computing, 2025
work page 2025
-
[50]
Zheng Lian, Lan Chen, Licai Sun, Bin Liu, and Jianhua Tao. Gcnet: Graph completion network for incomplete multimodal learning in conversation.IEEE Transactions on pattern analysis and machine intelligence, 45(7): 8419–8432, 2023
work page 2023
-
[51]
Yuanzhi Wang, Yong Li, and Zhen Cui. Incomplete multimodality-diffused emotion recognition.Advances in Neural Information Processing Systems, 36:17117–17128, 2023
work page 2023
-
[52]
Haoyu Zhang, Wenbin Wang, and Tianshu Yu. Towards robust multimodal sentiment analysis with incomplete data.Advances in Neural Information Processing Systems, 37:55943–55974, 2024. 19 Emotion Collider
work page 2024
-
[53]
Enhanced experts with uncertainty- aware routing for multimodal sentiment analysis
Zixian Gao, Disen Hu, Xun Jiang, Huimin Lu, Heng Tao Shen, and Xing Xu. Enhanced experts with uncertainty- aware routing for multimodal sentiment analysis. InProceedings of the 32nd ACM International Conference on Multimedia, pages 9650–9659, 2024
work page 2024
-
[54]
Cider: Consensus-based image description evaluation
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evaluation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575, 2015. A Theoretical Details A.1 Radial scaling is an inter-curvature diffeomorphism Proposition.Let Bc1 ={x∈R n :∥x∥<1/ √c1} and Bc2 ={x∈R n :∥x∥<1...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.