Recognition: 2 theorem links
· Lean TheoremThe Geometry of Multi-Task Grokking: Transverse Instability, Superposition, and Weight Decay Phase Structure
Pith reviewed 2026-05-15 20:36 UTC · model grok-4.3
The pith
Multi-task grokking builds a compact superposition subspace in parameter space where weight decay supplies compression pressure and excess parameters add geometric redundancy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
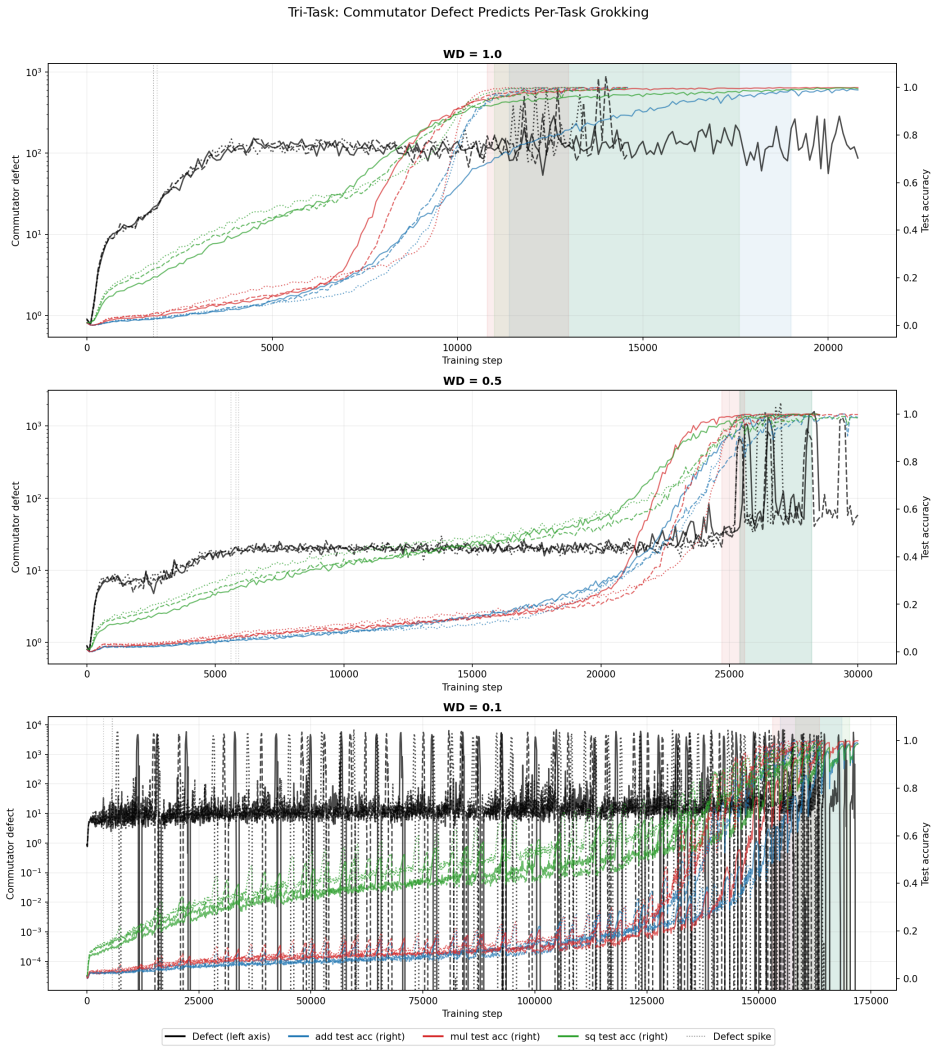
Multi-task grokking constructs a compact superposition subspace in parameter space, with weight decay acting as compression pressure and excess parameters supplying geometric redundancy in optimization pathways. The supporting observations are staggered grokking order, universal integrability on an invariant manifold, systematic weight-decay phase structure, holographic incompressibility of the final weights, and transverse fragility offset by redundancy.
What carries the argument
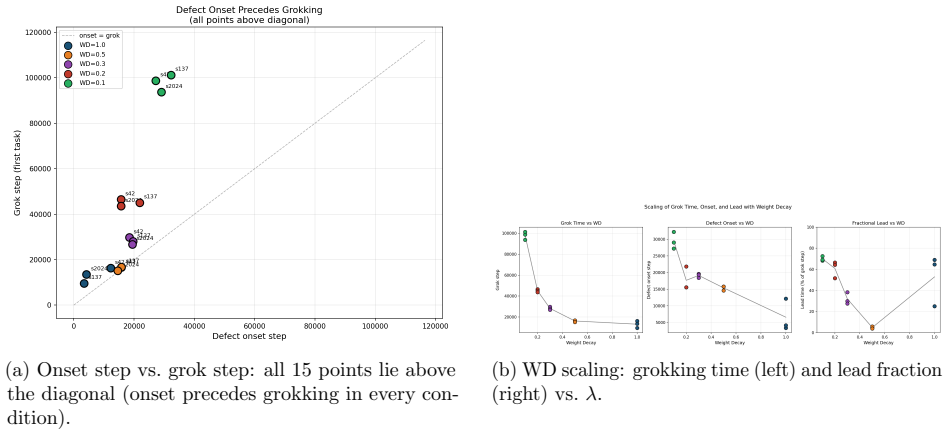
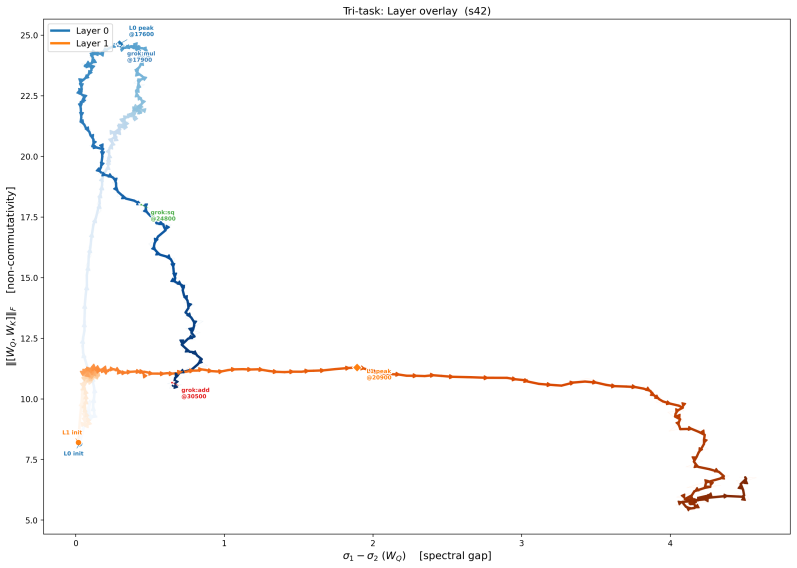
The low-dimensional execution manifold that confines all optimization trajectories together with the orthogonal commutator defects that reliably precede generalization.
If this is right
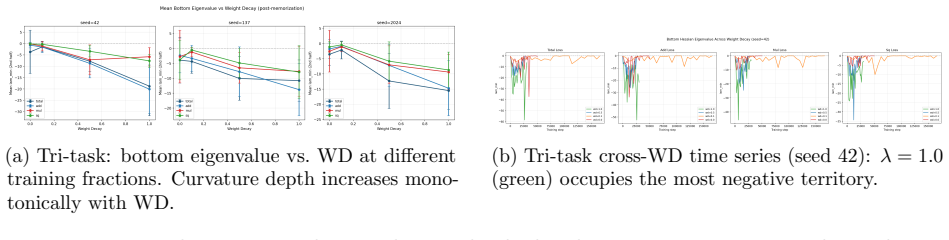
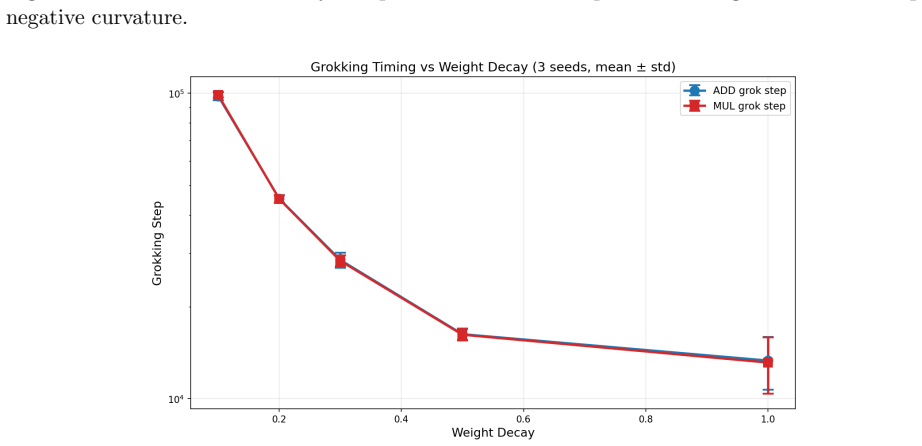
- Grokking timescale, curvature depth, and defect lead covary systematically with weight decay, producing distinct dynamical regimes.
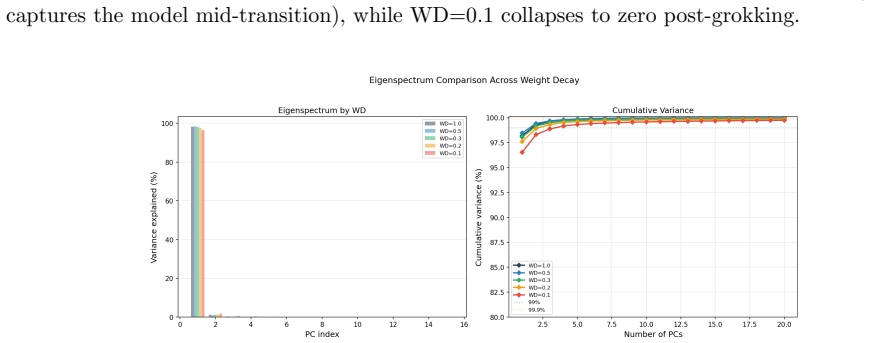
- Final solutions occupy only 4-8 principal trajectory directions yet are destroyed by SVD truncation, magnitude pruning, or uniform scaling.
- Removal of less than 10 percent of orthogonal gradient components eliminates grokking, although dual-task models show partial recovery.
- Multiplication generalizes before squaring, which precedes addition, with consistent delays across random seeds.
Where Pith is reading between the lines
- The redundancy supplied by excess parameters may confer robustness against transverse instabilities when the number of tasks increases.
- The observed staggered order could reflect algebraic complexity differences among the modular operations rather than model architecture alone.
- If the superposition subspace scales sublinearly with task count, multi-task training could remain parameter-efficient even for larger task sets.
Load-bearing premise
The low-dimensional execution manifold stays invariant during training and commutator defects always precede generalization in the modular tasks examined.
What would settle it
An experiment in which grokking occurs without any detectable commutator defects preceding it or in which the observed manifold dimensionality changes measurably during the transition.
Figures




























read the original abstract
Grokking -- the abrupt transition from memorization to generalization long after near-zero training loss -- has been studied mainly in single-task settings. We extend geometric analysis to multi-task modular arithmetic, training shared-trunk Transformers on dual-task (mod-add + mod-mul) and tri-task (mod-add + mod-mul + mod-sq) objectives across a systematic weight decay sweep. Five consistent phenomena emerge. (1) Staggered grokking order: multiplication generalizes first, followed by squaring, then addition, with consistent delays across seeds. (2) Universal integrability: optimization trajectories remain confined to an empirically invariant low-dimensional execution manifold; commutator defects orthogonal to this manifold reliably precede generalization. (3) Weight decay phase structure: grokking timescale, curvature depth, reconstruction threshold, and defect lead covary systematically with weight decay, revealing distinct dynamical regimes and a sharp no-decay failure mode. (4) Holographic incompressibility: final solutions occupy only 4--8 principal trajectory directions yet are distributed across full-rank weights and destroyed by minimal perturbations; SVD truncation, magnitude pruning, and uniform scaling all fail to preserve performance. (5) Transverse fragility and redundancy: removing less than 10% of orthogonal gradient components eliminates grokking, yet dual-task models exhibit partial recovery under extreme deletion, suggesting redundant center manifolds enabled by overparameterization. Together, these results support a dynamical picture in which multi-task grokking constructs a compact superposition subspace in parameter space, with weight decay acting as compression pressure and excess parameters supplying geometric redundancy in optimization pathways.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends single-task grokking analysis to multi-task modular arithmetic (mod-add + mod-mul, and + mod-sq) using shared-trunk Transformers. It reports five empirical phenomena across weight-decay sweeps: staggered generalization order, confinement to an invariant low-dimensional execution manifold with orthogonal commutator defects preceding generalization, systematic weight-decay phase structure in timescales and curvature, holographic incompressibility of final solutions (4-8 principal directions yet full-rank and fragile to perturbation), and transverse fragility with partial redundancy from overparameterization. These are interpreted as evidence for construction of a compact superposition subspace under weight-decay compression.
Significance. If the reported patterns are robust and the manifold invariance holds under controlled interventions, the work supplies a concrete geometric mechanism linking weight decay, parameter redundancy, and multi-task generalization. The phase-structure and holographic-incompressibility observations are particularly novel and could guide regularization design in overparameterized models.
major comments (2)
- [Abstract (2)] Abstract, phenomenon (2): the assertion that commutator defects 'reliably precede generalization' and support a mechanistic superposition-subspace picture rests on observational correlation across seeds and sweeps. No ablation, projection, or regularizer is described that selectively suppresses or amplifies these defects while holding other trajectory statistics fixed; without such tests the defects could be downstream consequences rather than load-bearing drivers of transverse instability.
- [Abstract (3),(5)] Abstract, phenomenon (3) and (5): the claimed 'universal integrability' and 'transverse fragility' require that the low-dimensional execution manifold remains invariant across the tested scales and tasks. The manuscript provides no quantitative test (e.g., distance to the manifold under controlled perturbations or across model widths) that would falsify invariance; the reported consistency across seeds is necessary but not sufficient for the geometric claim.
minor comments (2)
- [Abstract] The abstract and described results omit error bars, exact seed counts, precise hyperparameter ranges, and data-exclusion criteria; these details are needed to evaluate whether fitting choices affect the reported phase boundaries and defect-lead times.
- [Methods] Notation for 'commutator defects' and 'principal trajectory directions' is introduced without an explicit definition or reference to the underlying SVD or Lie-bracket construction; a short methods subsection would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications based on the presented evidence and indicate revisions where they strengthen the claims without misrepresenting the work.
read point-by-point responses
-
Referee: [Abstract (2)] Abstract, phenomenon (2): the assertion that commutator defects 'reliably precede generalization' and support a mechanistic superposition-subspace picture rests on observational correlation across seeds and sweeps. No ablation, projection, or regularizer is described that selectively suppresses or amplifies these defects while holding other trajectory statistics fixed; without such tests the defects could be downstream consequences rather than load-bearing drivers of transverse instability.
Authors: We agree that the evidence for commutator defects as load-bearing drivers is observational, drawn from consistent patterns across multiple random seeds and weight-decay sweeps in the multi-task setting. The manuscript shows these defects appearing orthogonally to the execution manifold prior to generalization in all tested configurations, supporting the superposition-subspace interpretation. However, we have not performed selective ablations or interventions that hold other statistics fixed. We will revise the abstract and add a discussion section explicitly characterizing the evidence as correlational while outlining targeted future ablation experiments to test causality. revision: partial
-
Referee: [Abstract (3),(5)] Abstract, phenomenon (3) and (5): the claimed 'universal integrability' and 'transverse fragility' require that the low-dimensional execution manifold remains invariant across the tested scales and tasks. The manuscript provides no quantitative test (e.g., distance to the manifold under controlled perturbations or across model widths) that would falsify invariance; the reported consistency across seeds is necessary but not sufficient for the geometric claim.
Authors: The referee is correct that invariance is supported by empirical consistency of trajectory confinement across seeds, tasks (dual- and tri-task), and scales rather than explicit falsification via perturbation distances or width variations. The full manuscript demonstrates this through PCA projections and manifold reconstruction metrics, but lacks quantitative tests such as measuring deviation under controlled perturbations. We will incorporate such quantitative invariance tests, including perturbation-based distance metrics and width-scaling experiments, into a revised version to provide stronger geometric validation. revision: yes
Circularity Check
No circularity: results are direct empirical observations from training runs
full rationale
The paper reports five consistent phenomena observed across training runs on shared-trunk Transformers for multi-task modular arithmetic, including staggered grokking order, confinement to an empirically invariant low-dimensional execution manifold, weight decay phase structure, holographic incompressibility, and transverse fragility. These are presented as patterns from systematic sweeps over seeds, tasks, and weight decay values, with no derivation chain, equations, or self-citations that reduce a claimed prediction or first-principles result to fitted inputs or prior author work by construction. The central dynamical picture is framed as supported by these observations rather than any tautological redefinition or imported uniqueness theorem.
Axiom & Free-Parameter Ledger
free parameters (1)
- weight decay coefficient
axioms (1)
- domain assumption Optimization trajectories remain confined to an empirically invariant low-dimensional execution manifold
invented entities (1)
-
compact superposition subspace
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
optimization trajectories remain confined to an empirically invariant low-dimensional execution manifold; commutator defects orthogonal to this manifold reliably precede generalization
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
weight decay acting as compression pressure and excess parameters supplying geometric redundancy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
The Lifecycle of the Spectral Edge: From Gradient Learning to Weight-Decay Compression
The spectral edge transitions from a gradient-driven functional direction before grokking to a perturbation-flat, ablation-critical compression axis at grokking, forming three universality classes predicted by a gap f...
-
Spectral Edge Dynamics Reveal Functional Modes of Learning
Spectral edge dynamics during grokking reveal task-dependent low-dimensional functional modes over inputs, such as Fourier modes for modular addition and cross-term decompositions for x squared plus y squared.
-
Spectral Edge Dynamics: An Analytical-Empirical Study of Phase Transitions in Neural Network Training
Spectral gaps in the Gram matrix of parameter updates control phase transitions such as grokking in neural network training.
-
Gradient-Direction Sensitivity Reveals Linear-Centroid Coupling Hidden by Optimizer Trajectories
Gradient-based SVD diagnostic uncovers hidden SED-LCH coupling in single and multitask settings and shows rank-3 subspace constraints speed up grokking by 2.3x.
Reference graph
Works this paper leans on
-
[1]
Xander Davies, Lauro Langosco, and David Krueger
URL https://transformer-circuits.pub/2023/monosemantic-features/index.html. Xander Davies, Lauro Langosco, and David Krueger. Unifying grokking and double descent.arXiv preprint arXiv:2303.06173,
-
[2]
Stanislav Fort and Stanislaw Jastrzebski
URL https://transformer-circuits.pub/2022/ toy_model/index.html. Stanislav Fort and Stanislaw Jastrzebski. Large scale structure of neural network loss landscapes. InAdvances in Neural Information Processing Systems, volume 32,
work page 2022
-
[3]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[4]
Grokking as the transition from lazy to rich training dynamics.arXiv preprint arXiv:2310.06110,
Tanishq Kumar, Blake Bordelon, Samuel J Gershman, and Cengiz Pehlevan. Grokking as the transition from lazy to rich training dynamics.arXiv preprint arXiv:2310.06110,
-
[5]
Measuring the intrinsic dimension of objective landscapes
Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objective landscapes. InInternational Conference on Learning Representations, 2018a. Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Goldstein. Visualizing the loss landscape of neural nets. InAdvances in Neural Information Processing Systems, vol...
-
[6]
32 Kaifeng Lyu, Jikai Jin, Zhiyuan Li, Simon S Du, Jason D Lee, and Wei Hu. Dichotomy of early and late phase implicit biases can provably induce grokking.arXiv preprint arXiv:2311.18817,
-
[7]
William Merrill, Nikolaos Tsilivis, and Aman Shukla. A tale of two circuits: Grokking as competition of sparse and dense subnetworks.arXiv preprint arXiv:2303.11873,
-
[9]
Neel Nanda, Lawrence Chan, Tom Liberum, Jess Smith, and Jacob Steinhardt
URLhttps://arxiv.org/abs/2602.01434. Neel Nanda, Lawrence Chan, Tom Liberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability.arXiv preprint arXiv:2301.05217,
-
[10]
Grokking: Generalization beyond overfitting on small algorithmic datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets. InICLR 2022 Workshop on MATH-AI,
work page 2022
-
[11]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
URLhttps://arxiv.org/abs/2201.02177. Vimal Thilak, Etai Littwin, Shuangfei Zhai, Omid Saremi, Roni Paiss, and Joshua Susskind. The slingshot mechanism: An empirical study of adaptive optimizers and the grokking phenomenon. arXiv preprint arXiv:2206.04817,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Explaining grokking through circuit efficiency.arXiv preprint arXiv:2309.02390,
Vikrant Varma, Rohin Shah, Zachary Kenton, J´ anos Kram´ ar, and Neel Nanda. Explaining grokking through circuit efficiency.arXiv preprint arXiv:2309.02390,
-
[13]
Early-Warning Signals of Grokking via Loss-Landscape Geometry
Yongzhong Xu. Early-warning signals of grokking via loss-landscape geometry.arXiv preprint arXiv:2602.16967, 2026a. URLhttps://arxiv.org/abs/2602.16967. Yongzhong Xu. Low-dimensional and transversely curved optimization dynamics in grokking.arXiv preprint arXiv:2602.16746, 2026b. URLhttps://arxiv.org/abs/2602.16746. Yongzhong Xu. Low-dimensional execution...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.