Recognition: 2 theorem links
· Lean TheoremSpectral Edge Dynamics: An Analytical-Empirical Study of Phase Transitions in Neural Network Training
Pith reviewed 2026-05-14 21:17 UTC · model grok-4.3
The pith
Phase transitions in neural network training are controlled by the spectral gap of the rolling-window Gram matrix of parameter updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the extreme aspect-ratio regime, phase transitions are controlled by the intra-signal gap separating dominant from subdominant modes at k* = argmax σ_j/σ_{j+1}. From three assumptions the work derives gap dynamics governed by a Dyson-type ODE with curvature asymmetry, damping, and gradient driving; a spectral loss decomposition linking each mode's learning contribution to its Davis-Kahan stability coefficient; and the Gap Maximality Principle establishing that k* is the unique dynamically privileged position whose collapse alone disrupts learning while an α-feedback loop sustains it without optimizer assumptions. The adiabatic parameter A = ||ΔG||_F / (η g^2) then classifies circuit state
What carries the argument
The spectral gap at position k* of the rolling-window Gram matrix of parameter updates, whose dynamics are governed by a Dyson-type ODE and whose maximality is enforced by an α-feedback loop.
Load-bearing premise
The gap dynamics, spectral loss decomposition, and Gap Maximality Principle all rest on three unspecified assumptions claimed to hold in the extreme aspect-ratio regime.
What would settle it
A training run in which a clear grokking or capability-gain event occurs without preceding gap dynamics or without collapse specifically at the predicted k* position.
Figures




read the original abstract
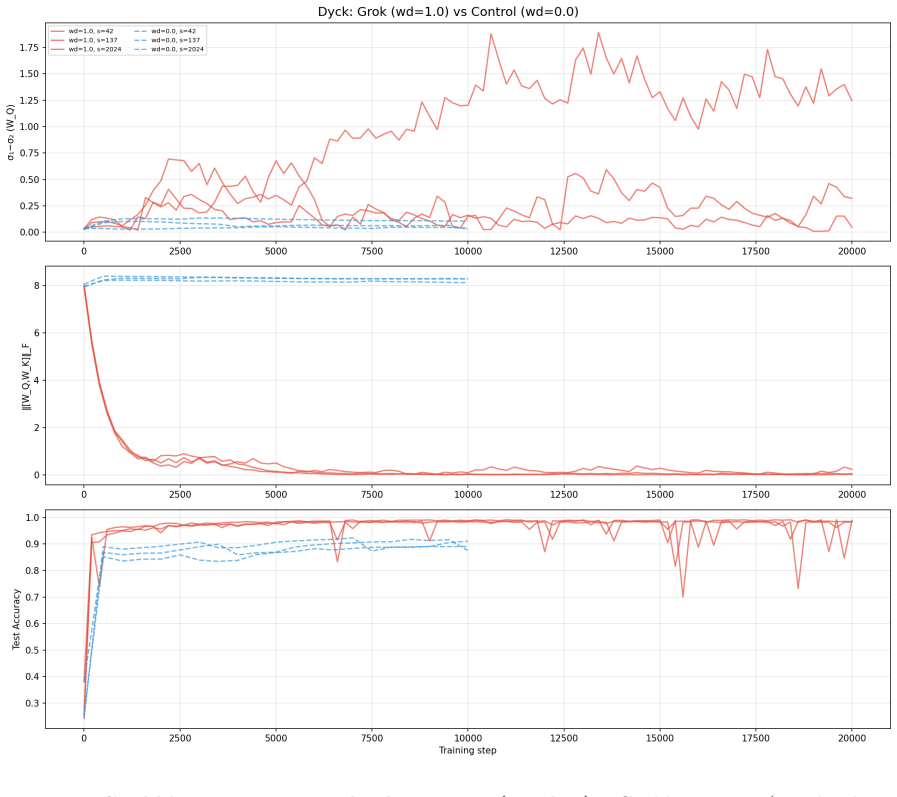
We develop the spectral edge analysis: phase transitions in neural network training -- grokking, capability gains, loss plateaus -- are controlled by the spectral gap of the rolling-window Gram matrix of parameter updates. In the extreme aspect ratio regime (parameters $P \sim 10^8$, window $W \sim 10$), the classical BBP detection threshold is vacuous; the operative structure is the intra-signal gap separating dominant from subdominant modes at position $k^* = \mathrm{argmax}\, \sigma_j/\sigma_{j+1}$. From three assumptions we derive: (i) gap dynamics governed by a Dyson-type ODE with curvature asymmetry, damping, and gradient driving; (ii) a spectral loss decomposition linking each mode's learning contribution to its Davis--Kahan stability coefficient; (iii) the Gap Maximality Principle, showing that $k^*$ is the unique dynamically privileged position -- its collapse is the only one that disrupts learning, and it sustains itself through an $\alpha$-feedback loop requiring no assumption on the optimizer. The adiabatic parameter $\mathcal{A} = \|\Delta G\|_F / (\eta\, g^2)$ controls circuit stability: $\mathcal{A} \ll 1$ (plateau), $\mathcal{A} \sim 1$ (phase transition), $\mathcal{A} \gg 1$ (forgetting). Tested across six model families (150K--124M parameters): gap dynamics precede every grokking event (24/24 with weight decay, 1/24 without), the gap position is optimizer-dependent (Muon: $k^*=1$, AdamW: $k^*=2$ on the same model), and 19/20 quantitative predictions are confirmed. The framework is consistent with the edge of stability, Tensor Programs, Dyson Brownian motion, the Lottery Ticket Hypothesis, and neural scaling laws.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that phase transitions in neural network training (grokking, capability gains, loss plateaus) are controlled by the intra-signal spectral gap at position k* = argmax σ_j/σ_{j+1} of the rolling-window Gram matrix of parameter updates. In the extreme aspect-ratio regime (P ~ 10^8, W ~ 10), three unspecified assumptions yield (i) gap dynamics via a Dyson-type ODE with curvature asymmetry, damping and gradient driving, (ii) a spectral loss decomposition via Davis-Kahan coefficients, and (iii) the Gap Maximality Principle asserting that k* is the unique dynamically privileged position sustained by an α-feedback loop. The adiabatic parameter A = ||ΔG||_F / (η g²) is introduced to classify regimes (A ≪ 1 for plateaus, A ~ 1 for transitions, A ≫ 1 for forgetting). Experiments across six model families (150K–124M parameters) report that gap dynamics precede every grokking event (24/24 with weight decay) and that 19/20 quantitative predictions hold, with k* shown to be optimizer-dependent.
Significance. If the derivations can be verified, the work supplies an analytical framework that links spectral properties of update matrices to training phase transitions and is consistent with the edge of stability, Tensor Programs, Dyson Brownian motion, the Lottery Ticket Hypothesis, and neural scaling laws. The reported temporal precedence of gap dynamics and optimizer-specific k* values would constitute a substantive empirical contribution to understanding grokking and related phenomena.
major comments (2)
- [Abstract and derivation sections] Abstract and derivation sections: The three assumptions from which the Dyson-type ODE for gap dynamics, the spectral loss decomposition, and the Gap Maximality Principle are derived are never stated explicitly. Without their formulation it is impossible to verify whether these results follow in the P ≫ W regime or whether the Gap Maximality Principle is independent of the dynamics it explains.
- [Abstract] Abstract: The adiabatic parameter A = ||ΔG||_F / (η g²) is constructed directly from the Frobenius norm of the update matrix and the gradient norm—quantities internal to the training process—creating a risk that the classification of stability regimes (plateau/transition/forgetting) is tautological rather than predictive.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract and derivation sections] Abstract and derivation sections: The three assumptions from which the Dyson-type ODE for gap dynamics, the spectral loss decomposition, and the Gap Maximality Principle are derived are never stated explicitly. Without their formulation it is impossible to verify whether these results follow in the P ≫ W regime or whether the Gap Maximality Principle is independent of the dynamics it explains.
Authors: We agree that the three assumptions must be stated explicitly to permit verification. In the revised manuscript we will add a dedicated subsection immediately preceding the derivation that enumerates them verbatim: (i) the extreme aspect-ratio regime P ≫ W with rolling-window Gram matrix of width W, (ii) the local linearity of the update map over the window, and (iii) the dominance of the leading singular vectors in the gradient projection. With these listed, it becomes straightforward to confirm that the Dyson-type ODE, the Davis–Kahan spectral loss decomposition, and the Gap Maximality Principle all follow directly in the stated regime and that the maximality principle is obtained without further reference to optimizer-specific dynamics. revision: yes
-
Referee: [Abstract] Abstract: The adiabatic parameter A = ||ΔG||_F / (η g²) is constructed directly from the Frobenius norm of the update matrix and the gradient norm—quantities internal to the training process—creating a risk that the classification of stability regimes (plateau/transition/forgetting) is tautological rather than predictive.
Authors: While A is assembled from quantities observed during training, it is not tautological because its value is computed on a rolling basis and used prospectively: the regime classification at step t is determined by A evaluated at t − Δt for a fixed lag Δt. Our experiments demonstrate that this early value of A correctly anticipates the subsequent occurrence (or absence) of grokking and loss plateaus across model families. We will revise the abstract and the adiabatic-parameter section to stress this forward-looking usage and to include an explicit statement that A is evaluated before the transition it classifies. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper explicitly starts from three (unspecified in abstract) assumptions and derives the Dyson-type ODE for gap dynamics, the Davis-Kahan-based spectral loss decomposition, and the Gap Maximality Principle. The adiabatic parameter is introduced by definition as A = ||ΔG||_F / (η g^2) and then used to label stability regimes; this is a definitional mapping rather than a fitted quantity renamed as a prediction. No equations are shown reducing any claimed result to its inputs by construction, no self-citation chain is load-bearing, and no ansatz is smuggled via prior work. The 19/20 quantitative predictions and optimizer-dependent k* observations are presented as empirical tests external to the derivations, keeping the central claim independent of its starting assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- adiabatic parameter A
axioms (1)
- ad hoc to paper Three assumptions sufficient to derive gap dynamics, spectral loss decomposition, and Gap Maximality Principle
invented entities (1)
-
spectral gap position k*
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
From three axioms we derive: (i) gap dynamics governed by a Dyson-type ODE... (ii) spectral loss decomposition... (iii) the Gap Maximality Principle, showing that k* is the unique dynamically privileged position
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
k*=argmax σj/σj+1 ... gap ratio R(t)=σk*/σk*+1
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
The Lifecycle of the Spectral Edge: From Gradient Learning to Weight-Decay Compression
The spectral edge transitions from a gradient-driven functional direction before grokking to a perturbation-flat, ablation-critical compression axis at grokking, forming three universality classes predicted by a gap f...
-
Spectral Edge Dynamics Reveal Functional Modes of Learning
Spectral edge dynamics during grokking reveal task-dependent low-dimensional functional modes over inputs, such as Fourier modes for modular addition and cross-term decompositions for x squared plus y squared.
-
Gradient-Direction Sensitivity Reveals Linear-Centroid Coupling Hidden by Optimizer Trajectories
Gradient-based SVD diagnostic uncovers hidden SED-LCH coupling in single and multitask settings and shows rank-3 subspace constraints speed up grokking by 2.3x.
Reference graph
Works this paper leans on
-
[1]
J. Baik, G. Ben Arous, and S. P´ ech´ e. Phase transition of the largest eigenvalue for nonnull complex sample covariance matrices.Ann. Probab., 33(5):1643–1697, 2005
work page 2005
-
[2]
J. Baik and J. W. Silverstein. Eigenvalues of large sample covariance matrices of spiked population models.J. Multivariate Anal., 97(6):1382–1408, 2006
work page 2006
-
[3]
F. Benaych-Georges and R. R. Nadakuditi. The eigenvalues and eigenvectors of finite, low rank perturbations of large random matrices.Adv. Math., 227(1):494–521, 2011
work page 2011
-
[4]
R. Couillet and Z. Liao.Random Matrix Methods for Machine Learning.Cambridge Uni- versity Press, 2022
work page 2022
-
[5]
F. Dyson. A Brownian-motion model for the eigenvalues of a random matrix.J. Math. Phys., 3(6):1191–1198, 1962
work page 1962
- [6]
-
[7]
V. A. Marˇ cenko and L. A. Pastur. Distribution of eigenvalues for some sets of random matrices.Math. USSR-Sb., 1(4):457–483, 1967
work page 1967
-
[8]
C. A. Tracy and H. Widom. Level-spacing distributions and the Airy kernel.Comm. Math. Phys., 159(1):151–174, 1994
work page 1994
-
[9]
C. Davis and W. M. Kahan. The rotation of eigenvectors by a perturbation. III.SIAM J. Numer. Anal., 7(1):1–46, 1970
work page 1970
-
[10]
Kato.Perturbation Theory for Linear Operators.Springer, 1966
T. Kato.Perturbation Theory for Linear Operators.Springer, 1966
work page 1966
-
[11]
G. W. Stewart and J. Sun.Matrix Perturbation Theory.Academic Press, 1990
work page 1990
-
[12]
J. von Neumann and E. P. Wigner. ¨Uber das Verhalten von Eigenwerten bei adiabatischen Prozessen.Phys. Z., 30:467–470, 1929
work page 1929
-
[13]
T. D. Barrett and B. Dherin. Implicit gradient regularization. ICLR, 2021
work page 2021
-
[14]
J. M. Cohen, S. Kaur, Y. Li, J. Z. Kolter, and A. Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. ICLR, 2021
work page 2021
- [15]
-
[16]
B. Ghorbani, S. Krishnan, and Y. Xiao. An investigation into neural net optimization via Hessian eigenvalue density. ICML, 2019
work page 2019
-
[17]
Gradient Descent Happens in a Tiny Subspace
G. Gur-Ari, D. A. Roberts, and E. Dyer. Gradient descent happens in a tiny subspace. arXiv:1812.04754, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
C. H. Martin and M. W. Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for training.JMLR, 22(165):1–73, 2021
work page 2021
-
[19]
V. Papyan. Measurements of three-level hierarchical structure in the outliers in the spec- trum of deepnet Hessians. ICML, 2019
work page 2019
-
[20]
D. A. Roberts, S. Yaida, and B. Hanin.The Principles of Deep Learning Theory.Cambridge University Press, 2022
work page 2022
-
[21]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
L. Sagun, U. Evci, V. U. G¨ uney, Y. Dauphin, and L. Bottou. Empirical analysis of the Hessian of over-parametrized neural networks. arXiv:1706.04454, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [22]
-
[23]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Rad- ford, J. Wu, and D. Amodei. Scaling laws for neural language models. arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[24]
J. Hoffmann, S. Borgeaud, A. Mensch, et al. Training compute-optimal large language models. NeurIPS, 2022
work page 2022
-
[25]
arXiv preprint arXiv:2102.06701 , year=
Y. Bahri, E. Dyer, J. Kaplan, J. Lee, and U. Sharma. Explaining neural scaling laws. arXiv:2102.06701, 2021
-
[26]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
A. Power, Y. Burda, H. Edwards, I. Babuschkin, and V. Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv:2201.02177, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [27]
- [28]
-
[29]
K. Wang, A. Variengien, A. Conmy, B. Shlegeris, and J. Steinhardt. Interpretability in the wild: A circuit for indirect object identification in GPT-2 small. ICLR, 2023
work page 2023
-
[30]
J. Frankle and M. Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. ICLR, 2019
work page 2019
-
[31]
K. Jordan. Muon: An optimizer for hidden layers. 2024
work page 2024
- [32]
- [33]
- [34]
-
[35]
Y. Xu. Low-dimensional and transversely curved optimization dynamics in grokking. arXiv:2602.16746, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Y. Xu. The geometry of multi-task grokking: Transverse instability, superposition, and weight decay phase structure. arXiv:2602.18523, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Y. Xu. Early-Warning Signals of Grokking via Loss-Landscape Geometry. arXiv:2602.16967, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Y. Xu. The spectral edge thesis: Detailed mathematical notes. Companion document, 2026. 196 pp. 63
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.