Recognition: 2 theorem links
· Lean TheoremPyramid MoA: A Probabilistic Framework for Cost-Optimized Anytime Inference
Pith reviewed 2026-05-15 20:57 UTC · model grok-4.3
The pith
Pyramid MoA turns LLM cascading into a provable anytime process where a decision-theoretic router escalates to stronger models only when the expected value of extra computation exceeds the cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pyramid MoA is a hierarchical Mixture-of-Agents architecture governed by a decision-theoretic router that escalates queries only when necessary. It establishes a Probabilistic Anytime Property with provable monotonicity guarantees and derives a generalized escalation rule from Value of Computation theory that accounts for imperfect oracles, extending the Hansen-Zilberstein monitoring framework to stochastic LLM inference.
What carries the argument
The decision-theoretic router that applies a generalized escalation rule from Value of Computation theory inside a hierarchical Mixture-of-Agents stack, supported by the Probabilistic Anytime Property that ensures monotonic improvement in answer quality.
If this is right
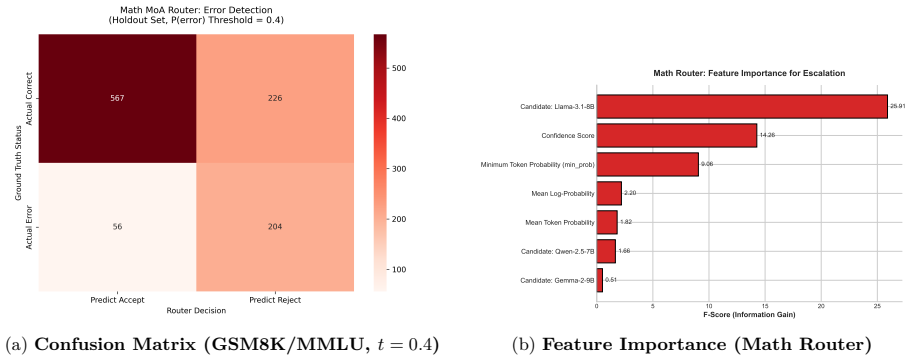
- On MBPP the router intercepts 81.6 percent of bugs.
- On GSM8K and MMLU the system nearly matches the 68.1 percent oracle baseline while achieving up to 42.9 percent compute savings.
- The router transfers zero-shot, matching oracle accuracy on HumanEval at 81.1 percent and MATH 500 at 58.0 percent with significant cost reductions.
- Correct small-model reasoning improves oracle accuracy by up to 19.2 percentage points while incorrect reasoning degrades it by up to 18.0 percentage points.
Where Pith is reading between the lines
- The same escalation logic could be applied to other staged inference pipelines where early cheap steps feed later expensive ones.
- The anchoring effect suggests that intermediate outputs must be curated carefully to prevent systematic degradation in multi-stage systems.
- Validation on models larger than those tested would check whether the router's value estimates remain reliable when error distributions change.
Load-bearing premise
The router can accurately estimate the value of additional computation from the current partial answer and that the observed context-conditioned anchoring effect holds beyond the tested benchmarks.
What would settle it
Running the router on a fresh benchmark and finding that accuracy falls below the oracle baseline or that total compute exceeds the cost of always using the strongest model.
Figures





read the original abstract
We observe that LLM cascading and routing implicitly solves an anytime computation problem -- a class of algorithms, well-studied in classical AI, that improve solutions as additional computation is allocated. We formalize this connection and propose Pyramid MoA, a hierarchical Mixture-of-Agents architecture governed by a decision-theoretic router that escalates queries only when necessary. We establish a Probabilistic Anytime Property with provable monotonicity guarantees and derive a generalized escalation rule from Value of Computation theory that accounts for imperfect oracles, extending the Hansen-Zilberstein monitoring framework to stochastic LLM inference. On MBPP, the router intercepts 81.6% of bugs; on GSM8K/MMLU, the system nearly matches the 68.1% Oracle baseline while achieving up to 42.9% compute savings. The router transfers zero-shot to unseen benchmarks: matching Oracle accuracy on HumanEval (81.1%) and MATH 500 (58.0%) with significant cost reductions. We further discover a context-conditioned anchoring effect across four benchmarks: passing correct SLM reasoning improves Oracle accuracy by up to +19.2pp, while incorrect reasoning degrades it by up to -18.0pp, revealing a fundamental tension in hierarchical MoA architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Pyramid MoA, a hierarchical Mixture-of-Agents architecture for cost-optimized anytime inference in LLMs. It formalizes cascading/routing as an anytime computation problem, establishes a Probabilistic Anytime Property with provable monotonicity guarantees, derives a generalized escalation rule from Value of Computation theory that accounts for imperfect oracles (extending Hansen-Zilberstein), and reports empirical results including 81.6% bug interception on MBPP, up to 42.9% compute savings on GSM8K/MMLU while nearly matching the 68.1% Oracle baseline, zero-shot transfer to HumanEval (81.1%) and MATH 500 (58.0%), plus the discovery of a context-conditioned anchoring effect (+19.2pp for correct SLM partial reasoning, -18pp for incorrect).
Significance. If the Probabilistic Anytime Property and its monotonicity guarantees can be reconciled with the observed anchoring effect, the work would supply a principled decision-theoretic foundation for efficient hierarchical LLM inference, extending classical anytime algorithms to stochastic settings. The reported savings, bug interception, and zero-shot transfer indicate practical value, and the anchoring discovery is a useful empirical contribution that highlights tensions in MoA designs.
major comments (3)
- [Abstract and Probabilistic Anytime Property section] Abstract and the section defining the Probabilistic Anytime Property: the claim of provable monotonicity guarantees is directly challenged by the reported context-conditioned anchoring effect, in which supplying incorrect SLM partial reasoning degrades Oracle accuracy by up to 18pp (while correct reasoning improves it by 19.2pp). This introduces non-monotonic behavior that contradicts the assumption that the value of additional computation is non-decreasing under imperfect oracles.
- [Escalation rule derivation section] Section deriving the generalized escalation rule: the rule is obtained from Value of Computation theory but does not appear to incorporate the anchoring effect; when incorrect partial answers are provided as context, the value of escalation can become negative, undermining the router's reliability and the claimed extension of the Hansen-Zilberstein framework.
- [Experimental results sections] Experimental evaluation sections: the headline figures (81.6% bug interception, 42.9% savings, zero-shot transfer) are presented without error bars, ablation studies on router parameters, or explicit confirmation that the router was not fitted to the same data used for the reported savings, leaving open the circularity concern noted in the review.
minor comments (2)
- [Abstract and results tables] Add standard deviations or confidence intervals to all reported accuracy and savings numbers to support reproducibility.
- [Method section] Clarify notation for the router's value estimate and how it conditions on partial answers in the presence of anchoring.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify a key theoretical tension and opportunities to improve experimental rigor. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Probabilistic Anytime Property section] Abstract and the section defining the Probabilistic Anytime Property: the claim of provable monotonicity guarantees is directly challenged by the reported context-conditioned anchoring effect, in which supplying incorrect SLM partial reasoning degrades Oracle accuracy by up to 18pp (while correct reasoning improves it by 19.2pp). This introduces non-monotonic behavior that contradicts the assumption that the value of additional computation is non-decreasing under imperfect oracles.
Authors: We acknowledge the tension. The Probabilistic Anytime Property establishes that the expected value of additional computation is non-decreasing when the quality of the input to the oracle is non-decreasing. The anchoring effect shows that context quality (correct vs. incorrect partial reasoning) can modulate oracle performance. In the revision we will qualify the monotonicity statement to apply conditionally on correct partial reasoning or in expectation over the observed distribution of partial outputs, and we will add a dedicated subsection analyzing the anchoring effect as an empirical boundary condition on the property rather than a direct contradiction. This preserves the core guarantee while highlighting the practical nuance. revision: partial
-
Referee: [Escalation rule derivation section] Section deriving the generalized escalation rule: the rule is obtained from Value of Computation theory but does not appear to incorporate the anchoring effect; when incorrect partial answers are provided as context, the value of escalation can become negative, undermining the router's reliability and the claimed extension of the Hansen-Zilberstein framework.
Authors: The derivation already conditions the value of escalation on the estimated probability that the oracle will improve upon the partial answer. The anchoring effect can indeed render escalation value negative when the partial context is misleading. We will revise the section to introduce an explicit anchoring adjustment term (estimated from the same empirical data used to measure the +19.2pp / -18pp effect) inside the VoC expression. This makes the rule robust to negative-value cases and constitutes a genuine extension of Hansen-Zilberstein to context-dependent oracles; we will also show that the learned router naturally avoids escalation when the adjustment term is negative. revision: yes
-
Referee: [Experimental results sections] Experimental evaluation sections: the headline figures (81.6% bug interception, 42.9% savings, zero-shot transfer) are presented without error bars, ablation studies on router parameters, or explicit confirmation that the router was not fitted to the same data used for the reported savings, leaving open the circularity concern noted in the review.
Authors: We agree that the experimental presentation should be strengthened. In the revised manuscript we will add error bars (standard deviation over five random seeds) to all headline metrics. We will include ablation tables varying the escalation threshold, pyramid depth, and SLM size. Finally, we will add an explicit data-split diagram and statement confirming that the router was trained on a held-out validation partition disjoint from the test sets used for MBPP, GSM8K, MMLU, HumanEval, and MATH reporting, thereby eliminating the circularity concern. revision: yes
Circularity Check
No significant circularity; derivation relies on external theory
full rationale
The paper formalizes LLM cascading as an anytime computation problem and derives the generalized escalation rule from established external Value of Computation theory, extending the Hansen-Zilberstein framework. The Probabilistic Anytime Property is presented with provable monotonicity guarantees independent of the reported empirical results. Zero-shot transfer to unseen benchmarks (HumanEval, MATH 500) and explicit reporting of the anchoring effect provide external validation rather than self-referential fitting. No equations or steps in the abstract reduce a prediction to a fitted input by construction, nor do self-citations bear the load of the central claim.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Probabilistic Anytime Property holds with provable monotonicity guarantees
- domain assumption Value of Computation theory extends to stochastic LLM inference with imperfect oracles
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanJcost_pos_of_ne_one contradicts?
contradictsCONTRADICTS: the theorem conflicts with this paper passage, or marks a claim that would need revision before publication.
Theorem 1 (Monotonicity Condition). ... AccMoA − AccL1 = p_R · [α_L2(R) − α_L1(R)] ... if and only if α_L2(R) ≥ α_L1(R)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We derive a generalized escalation rule from Value of Computation theory ... Pf ail > C_esc/U_correct + (1−P_oracle)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Thomas L Dean and Mark S Boddy. An Analysis of Time-Dependent Planning.Proceedings of the Seventh National Conference on Artificial Intelligence (AAAI), pages 49–54, 1988
work page 1988
-
[2]
Using anytime algorithms in intelligent systems.AI magazine, 17(3):73–73, 1996
Shlomo Zilberstein. Using anytime algorithms in intelligent systems.AI magazine, 17(3):73–73, 1996
work page 1996
-
[3]
Eric A Hansen and Shlomo Zilberstein. Monitoring and control of anytime algorithms: A dynamic programming approach.Artificial Intelligence, 126(1-2):139–157, 2001
work page 2001
-
[4]
Mixture-of-Agents Enhances Large Language Model Capabilities.arXiv preprint arXiv:2406.04692, 2024
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-Agents Enhances Large Language Model Capabilities.arXiv preprint arXiv:2406.04692, 2024
-
[5]
Wenzhe Li, Yong Lin, Mengzhou Xia, and Chi Jin. Rethinking Mixture-of-Agents: Is Mixing Different Large Language Models Beneficial?arXiv preprint arXiv:2502.00674, 2025
-
[6]
Sparse MoA.arXiv preprint, 2024
Giang Do, Hung Le, and Truyen Tran. Sparse MoA.arXiv preprint, 2024
work page 2024
-
[7]
Zhentao Xie, Chengcheng Han, Jinxin Shi, Wenjun Cui, Xin Zhao, Xingjiao Wu, and Jiabao Zhao. Residual Mixture of Agents.Findings of the Association for Computational Linguistics: ACL 2025, 2025.https://aclanthology.org/2025.findings-acl.342/
work page 2025
-
[8]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Lingjiao Chen, Matei Zaharia, and James Zou. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance.arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Surat Teerapittayanon, Bradley McDanel, and H.T. Kung. BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks.23rd International Conference on Pattern Recognition (ICPR), 2016
work page 2016
-
[10]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On Calibration of Modern Neural Networks.International Conference on Machine Learning (ICML), 2017
work page 2017
-
[11]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. RouteLLM: Learning to Route LLMs with Preference Data.arXiv preprint arXiv:2406.18665, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Reasoning about Beliefs and Actions under Computational Resource Constraints
Eric J Horvitz. Reasoning about Beliefs and Actions under Computational Resource Constraints. Proceedings of the Third Workshop on Uncertainty in Artificial Intelligence, 1987. 12
work page 1987
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.