Descent-Guided Policy Gradient for Scalable Cooperative Multi-Agent Learning
Pith reviewed 2026-05-15 19:56 UTC · model grok-4.3
The pith
Descent-Guided Policy Gradient augments MARL updates with analytical descent signals to cut estimator variance from linear in agent count to constant.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
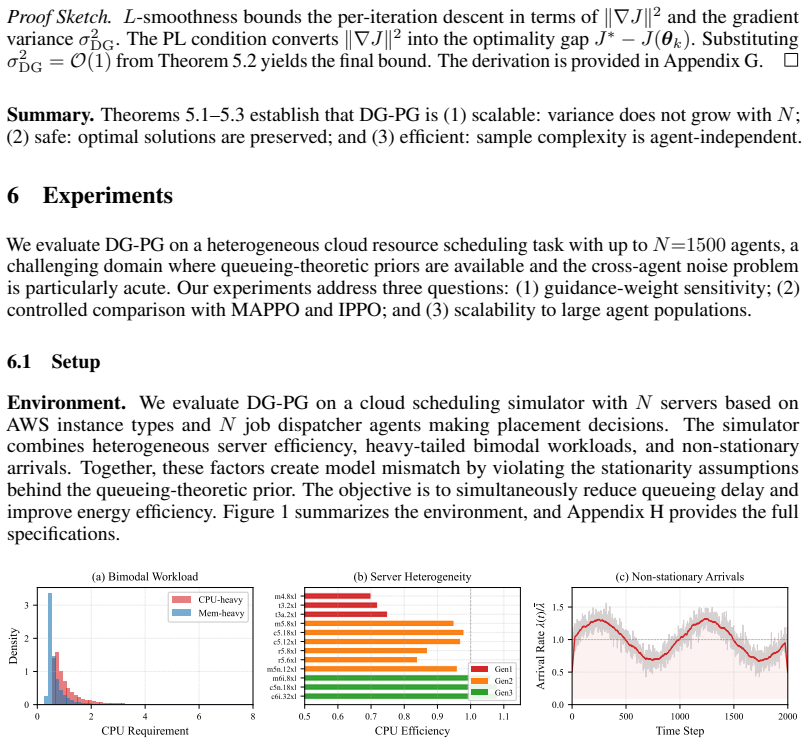
DG-PG augments the conventional policy-gradient update with a noise-free descent vector obtained from a differentiable analytical model that prescribes efficient system states. The construction is shown to reduce the variance of the policy-gradient estimator from O(N) to O(1), to leave the set of equilibria of the underlying cooperative game unchanged, and to deliver an agent-count-independent sample complexity of Õ(1/ε). In a heterogeneous cloud scheduling task the method reaches stable performance within 20 episodes on average even at 1500 agents, whereas MAPPO and IPPO under identical network architectures fail to converge.
What carries the argument
The descent-guided update that linearly combines the noisy shared-return policy gradient with a deterministic analytical descent direction while preserving the cooperative game's equilibrium set.
Load-bearing premise
Differentiable analytical models that prescribe efficient system states exist for the target domain and can be inserted into the gradient update without introducing bias or altering the game's equilibria.
What would settle it
An experiment that replaces the analytical model with a deliberately biased or non-differentiable surrogate and then measures whether the claimed O(1) variance bound and convergence still hold.
Figures



read the original abstract
Scaling cooperative multi-agent reinforcement learning (MARL) is fundamentally limited by cross-agent noise. When agents share a common reward, each agent's learning signal is computed from a shared return that depends on all agents, so the stochasticity of the other agents enters the signal as cross-agent noise that grows with $N$. Fortunately, many engineering systems, such as cloud computing and power systems, have differentiable analytical models that prescribe efficient system states, providing a new reference beyond noisy shared returns. In this work, we propose Descent-Guided Policy Gradient (DG-PG), a framework that augments policy-gradient updates with a noise-free descent signal derived from differentiable analytical models. We prove that DG-PG reduces policy-gradient estimator variance from $\mathcal{O}(N)$ to $\mathcal{O}(1)$, preserves the equilibria of the cooperative game, and achieves agent-independent sample complexity $\widetilde{\mathcal{O}} (1/\epsilon)$. On a heterogeneous cloud resource scheduling task with up to 1500 agents, DG-PG converges within 20 episodes on average, while MAPPO and IPPO fail to converge under identical architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Descent-Guided Policy Gradient (DG-PG) for cooperative multi-agent RL. It augments standard policy-gradient updates with a noise-free descent direction derived from differentiable analytical models of the underlying system (e.g., cloud schedulers). The central claims are three proofs: (i) the estimator variance drops from O(N) to O(1) because the analytical term removes cross-agent stochasticity, (ii) the fixed points of the augmented update coincide with the equilibria of the original cooperative game, and (iii) the sample complexity becomes agent-independent, Õ(1/ε). Empirically, on a heterogeneous cloud-resource scheduling task with up to 1500 agents, DG-PG reaches stable performance in roughly 20 episodes while MAPPO and IPPO fail to converge under identical network architectures.
Significance. If the three proofs hold and the required differentiable models can be supplied without bias, the method would remove the dominant scaling barrier in cooperative MARL for domains that already possess accurate analytical simulators. The empirical demonstration at N=1500 is unusually large and, if reproducible, would constitute a concrete advance over current centralized-training baselines.
major comments (4)
- [§3 (variance reduction proof)] The variance-reduction claim (abstract and §3) is load-bearing. The derivation must explicitly show that the analytical descent term is unbiased with respect to the shared-return gradient and that its variance is independent of N; any dependence on model accuracy or on the number of agents inside the analytical model must be stated.
- [§4 (equilibrium preservation)] Equilibrium preservation (abstract and §4) requires a precise statement that the augmented policy-gradient operator has exactly the same fixed points as the original cooperative-game operator. The proof should clarify whether this holds only for deterministic policies or also for stochastic policies.
- [§5 (sample-complexity theorem)] The sample-complexity result Õ(1/ε) independent of N rests on the assumption that the analytical model can be evaluated at cost independent of N. This assumption and its verification for the cloud-scheduling domain must be made explicit, including any Lipschitz or smoothness constants used in the analysis.
- [§6 (experiments)] In the 1500-agent experiments, the construction and integration of the differentiable analytical model are not described in sufficient detail to assess whether the reported convergence is due to the descent signal or to other implementation choices. An ablation that removes the descent term while keeping the same architecture is needed.
minor comments (3)
- [abstract and §5] Notation: the symbol Õ is used for sample complexity but never defined; please state the hidden logarithmic factors explicitly.
- [§6] Figure captions for the learning curves should report the number of random seeds and the precise definition of the performance metric (e.g., normalized makespan).
- [§2] The related-work section should cite recent variance-reduction techniques for MARL (e.g., value-decomposition or centralized critics) and contrast them with the analytical-descent approach.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the theoretical claims and empirical details. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3 (variance reduction proof)] The variance-reduction claim (abstract and §3) is load-bearing. The derivation must explicitly show that the analytical descent term is unbiased with respect to the shared-return gradient and that its variance is independent of N; any dependence on model accuracy or on the number of agents inside the analytical model must be stated.
Authors: We agree the variance reduction is central. In the revision we will expand §3 to explicitly prove that the analytical descent term is unbiased (its expectation equals the true shared-return gradient) and that the combined estimator variance is O(1) independent of N when the analytical model is fixed. We will also state the dependence on model accuracy, bounding residual variance by the model error term. revision: yes
-
Referee: [§4 (equilibrium preservation)] Equilibrium preservation (abstract and §4) requires a precise statement that the augmented policy-gradient operator has exactly the same fixed points as the original cooperative-game operator. The proof should clarify whether this holds only for deterministic policies or also for stochastic policies.
Authors: We will revise §4 to state precisely that the augmented operator shares exactly the same fixed points as the original cooperative-game operator. The proof will be extended to cover stochastic policies by working in the space of distributions over actions, showing that the analytical term vanishes at any equilibrium of the shared-return game. revision: yes
-
Referee: [§5 (sample-complexity theorem)] The sample-complexity result Õ(1/ε) independent of N rests on the assumption that the analytical model can be evaluated at cost independent of N. This assumption and its verification for the cloud-scheduling domain must be made explicit, including any Lipschitz or smoothness constants used in the analysis.
Authors: We will make the assumption explicit in §5: the analytical model operates on aggregate states and is evaluated at cost independent of N. For the cloud-scheduling domain we will verify this using the global optimizer's complexity and include the Lipschitz and smoothness constants employed in the Õ(1/ε) bound. revision: yes
-
Referee: [§6 (experiments)] In the 1500-agent experiments, the construction and integration of the differentiable analytical model are not described in sufficient detail to assess whether the reported convergence is due to the descent signal or to other implementation choices. An ablation that removes the descent term while keeping the same architecture is needed.
Authors: We will add a detailed subsection describing the construction of the differentiable analytical model (derived from the cloud scheduler's closed-form equations) and its gradient integration. We will also include the requested ablation that removes only the descent term while retaining identical architectures and hyperparameters. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation augments standard policy gradients with an additive descent signal drawn from external differentiable analytical models of the target system (e.g., cloud scheduling). The claimed variance reduction (O(N) to O(1)), equilibrium preservation, and sample-complexity bound are presented as consequences of this external correction term whose fixed points coincide with the original cooperative game. No equation or proof step is shown to reduce to a fitted parameter, a self-citation chain, or a renaming of the input; the analytical models are treated as independent domain knowledge rather than outputs of the method. The argument is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence of differentiable analytical models that prescribe efficient system states
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We augment the policy gradient with this guidance... ∇θi Jα ≜ (1−α)∇θi J − α ∇θi G where G≜E[d(xt,˜xt)] and d=½∥xt−˜xt∥²
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 5.2 (Agent-Independent Variance) ... min Var(ˆgi_DG)=O(1) independent of N
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alekh Agarwal, Sham M Kakade, Jason D Lee, and Gaurav Mahajan. On the theory of policy gradient methods: Optimality, approximation, and distribution shift.Journal of Machine Learning Research, 22(98):1–76, 2021
work page 2021
-
[2]
Dimitri Bertsekas and Robert Gallager.Data networks. Athena Scientific, 2021
work page 2021
-
[3]
Eli Cortez, Anand Bonde, Alexandre Muzio, Mark Russinovich, Marcus Fontoura, and Ricardo Bianchini. Resource central: Understanding and predicting workloads for improved resource management in large cloud platforms. InProceedings of the 26th Symposium on Operating Systems Principles, pages 153–167, 2017
work page 2017
-
[4]
Quasar: Resource-efficient and QoS-aware cluster management
Christina Delimitrou and Christos Kozyrakis. Quasar: Resource-efficient and QoS-aware cluster management. InProceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), pages 127–144, 2014
work page 2014
-
[5]
Samah El-Tantawy, Baher Abdulhai, and Hossam Abdelgawad. Multiagent reinforcement learn- ing for integrated network of adaptive traffic signal controllers (marlin-atsc): Methodology and large-scale application on downtown toronto.IEEE transactions on Intelligent transportation systems, 14(3):1140–1150, 2013
work page 2013
-
[6]
Counterfactual multi-agent policy gradients
Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[7]
Dominant resource fairness: Fair allocation of multiple resource types
Ali Ghodsi, Matei Zaharia, Benjamin Hindman, Andy Konwinski, Scott Shenker, and Ion Stoica. Dominant resource fairness: Fair allocation of multiple resource types. In8th USENIX symposium on networked systems design and implementation (NSDI 11), 2011
work page 2011
-
[8]
Residual reinforcement learning for robot control
Tobias Johannink, Shikhar Bahl, Ashvin Nair, Jianlan Luo, Avinash Kumar, Matthias Loskyll, Juan Aparicio Ojea, Eugen Solowjow, and Sergey Levine. Residual reinforcement learning for robot control. In2019 international conference on robotics and automation (ICRA), pages 6023–6029. IEEE, 2019
work page 2019
-
[9]
Linear convergence of gradient and proximal- gradient methods under the polyak-łojasiewicz condition
Hamed Karimi, Julie Nutini, and Mark Schmidt. Linear convergence of gradient and proximal- gradient methods under the polyak-łojasiewicz condition. InJoint European conference on machine learning and knowledge discovery in databases, pages 795–811. Springer, 2016
work page 2016
-
[10]
Frank P Kelly, Aman K Maulloo, and David Kim Hong Tan. Rate control for communication networks: shadow prices, proportional fairness and stability.Journal of the Operational Research society, 49(3):237–252, 1998
work page 1998
-
[11]
Jakub Grudzien Kuba, Muning Wen, Linghui Meng, Haifeng Zhang, David Mguni, Jun Wang, and Yaodong Yang. Settling the variance of multi-agent policy gradients.Advances in Neural Information Processing Systems, 34:13458–13470, 2021
work page 2021
-
[12]
Trust region policy optimisation in multi-agent reinforcement learning
Jakub Grudzien Kuba, Ruiqing Chen, Muning Wen, Ying Wen, Fanglei Sun, Jun Wang, and Yaodong Yang. Trust region policy optimisation in multi-agent reinforcement learning. In International Conference on Learning Representations, 2022
work page 2022
- [13]
-
[14]
Sergey Levine and Vladlen Koltun. Guided policy search. InInternational conference on machine learning, pages 1–9. PMLR, 2013
work page 2013
-
[15]
Learning scheduling algorithms for data processing clusters
Hongzi Mao, Malte Schwarzkopf, Shaileshh Bojja Venkatakrishnan, Zili Meng, and Mohammad Alizadeh. Learning scheduling algorithms for data processing clusters. InProceedings of the ACM Special Interest Group on Data Communication (SIGCOMM), pages 270–288, 2019
work page 2019
-
[16]
On the global con- vergence rates of softmax policy gradient methods
Jincheng Mei, Chenjun Xiao, Csaba Szepesvari, and Dale Schuurmans. On the global con- vergence rates of softmax policy gradient methods. InInternational Conference on Machine Learning, pages 6820–6829. PMLR, 2020. 10
work page 2020
-
[17]
Policy invariance under reward transfor- mations: Theory and application to reward shaping
Andrew Y Ng, Daishi Harada, and Stuart Russell. Policy invariance under reward transfor- mations: Theory and application to reward shaping. InInternational Conference on Machine Learning, pages 278–287, 1999
work page 1999
-
[18]
Frans A Oliehoek and Christopher Amato.A concise introduction to decentralized POMDPs. Springer, 2016
work page 2016
-
[19]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019
work page 2019
-
[20]
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning.Journal of Machine Learning Research, 21(178):1–51, 2020
work page 2020
-
[21]
Google cluster-usage traces: format+ schema.Google Inc., White Paper, 1:1–14, 2011
Charles Reiss, John Wilkes, and Joseph L Hellerstein. Google cluster-usage traces: format+ schema.Google Inc., White Paper, 1:1–14, 2011
work page 2011
-
[22]
Heterogeneity and dynamicity of clouds at scale: Google trace analysis
Charles Reiss, Alexey Tumanov, Gregory R Ganger, Randy H Katz, and Michael A Kozuch. Heterogeneity and dynamicity of clouds at scale: Google trace analysis. InProceedings of the third ACM symposium on cloud computing, pages 1–13, 2012
work page 2012
-
[23]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, et al. Value- decomposition networks for cooperative multi-agent learning.arXiv preprint arXiv:1706.05296, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient meth- ods for reinforcement learning with function approximation.Advances in neural information processing systems, 12, 1999
work page 1999
-
[25]
Qplex: Duplex dueling multi-agent q-learning
Jianhao Wang, Zhizhou Ren, Terry Liu, Yang Yu, and Chongjie Zhang. Qplex: Duplex dueling multi-agent q-learning. InInternational Conference on Learning Representations, 2021
work page 2021
-
[26]
John Glen Wardrop. Road paper. some theoretical aspects of road traffic research.Proceedings of the institution of civil engineers, 1(3):325–362, 1952
work page 1952
-
[27]
Optimal payoff functions for members of collectives
David H Wolpert and Kagan Tumer. Optimal payoff functions for members of collectives. Advances in Complex Systems, 4(02n03):265–279, 2001
work page 2001
-
[28]
Allen J Wood, Bruce F Wollenberg, and Gerald B Shebl´e.Power generation, operation, and control. John wiley & sons, 2013
work page 2013
-
[29]
Mean field multi-agent reinforcement learning
Yaodong Yang, Rui Luo, Minne Li, Ming Zhou, Weinan Zhang, and Jun Wang. Mean field multi-agent reinforcement learning. InInternational conference on machine learning, pages 5571–5580. PMLR, 2018
work page 2018
-
[30]
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games.Advances in neural information processing systems, 35:24611–24624, 2022. 11 A Comparison with Existing Methods Table 2 provides a systematic comparison of DG-PG with representative methods from major ...
work page 2022
-
[31]
No prior method achieves all five: •MAPPO / IPPO:O(N)variance⇒ O(N/ϵ)sample complexity
Every existing method sacrifices at least one critical property.For large-scale cooperative MARL, we identify five desirable properties: O(1) variance, O(1/ϵ) sample complexity, heteroge- neous policies, parallel updates, and zero extra learned components. No prior method achieves all five: •MAPPO / IPPO:O(N)variance⇒ O(N/ϵ)sample complexity. •HAPPO: sequ...
-
[32]
Leveraging analytical models without sacrificing optimality.All other methods in Table 2 are purely model-free, either imposing no assumptions at all (MAPPO, IPPO, HAPPO, COMA) or encoding structural constraints into the architecture (QMIX, VDN, Mean-Field). DG-PG is unique in leveraging anexternal analytical modelto reduce variance while remaining model-...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.