Recognition: no theorem link
Simulation-Ready Cluttered Scene Estimation via Physics-aware Joint Shape and Pose Optimization
Pith reviewed 2026-05-15 20:13 UTC · model grok-4.3
The pith
A joint optimization framework recovers shapes and poses of multiple objects in cluttered scenes while enforcing physical validity for direct use in simulators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that by using a shape-differentiable contact model and deriving an efficient solver from the structured sparsity of the augmented Lagrangian Hessian, it is possible to jointly optimize the shapes and poses of multiple rigid objects under physical constraints, yielding physically valid and simulation-ready scene reconstructions from real-world observations.
What carries the argument
The shape-differentiable contact model, which enables gradient-based optimization over both object shapes and poses by providing differentiable contact forces and geometries.
Load-bearing premise
The shape-differentiable contact model must remain globally differentiable and the augmented Lagrangian solver must converge without getting stuck in local minima when optimizing shapes and poses together in multi-object contact scenarios.
What would settle it
A test scene with five or more objects where the optimization produces interpenetrating shapes or fails to converge to a physically stable configuration, or where the simulated behavior of the reconstructed scene does not match the observed real-world motion.
Figures












read the original abstract
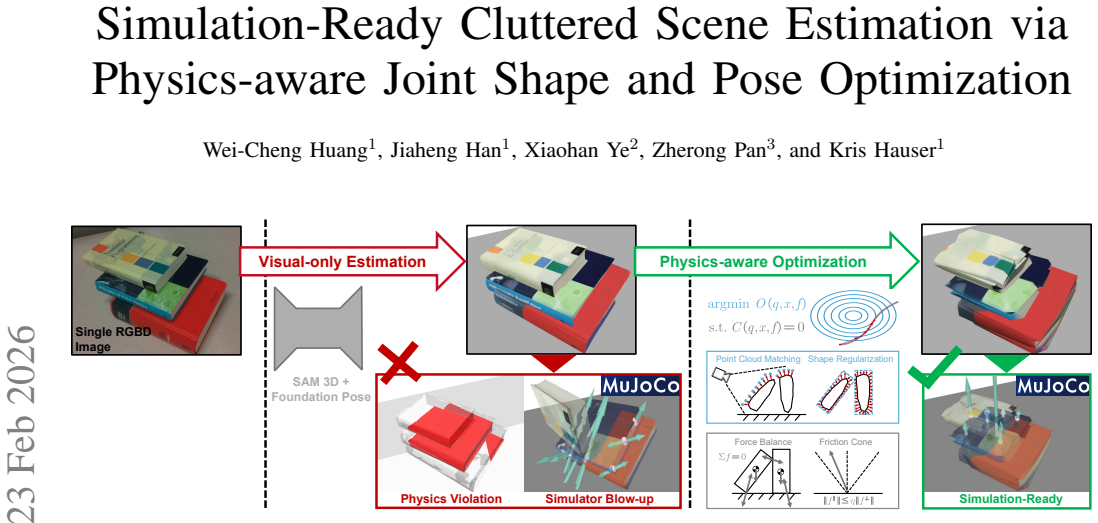
Estimating simulation-ready scenes from real-world observations is crucial for downstream planning and policy learning tasks. Regretfully, existing methods struggle in cluttered environments, often exhibiting prohibitive computational cost, poor robustness, and restricted generality when scaling to multiple interacting objects. We propose a unified optimization-based formulation for real-to-sim scene estimation that jointly recovers the shapes and poses of multiple rigid objects under physical constraints. Our method is built on two key technical innovations. First, we leverage the recently introduced shape-differentiable contact model, whose global differentiability permits joint optimization over object geometry and pose while modeling inter-object contacts. Second, we exploit the structured sparsity of the augmented Lagrangian Hessian to derive an efficient linear system solver whose computational cost scales favorably with scene complexity. Building on this formulation, we develop an end-to-end Simulation-ready Physics-Aware Reconstruction for Cluttered Scenes (SPARCS) pipeline, which integrates learning-based object initialization, physics-constrained joint shape-pose optimization, and differentiable texture refinement. Experiments on cluttered scenes with up to 5 objects and 22 convex hulls demonstrate that our approach robustly reconstructs physically valid, simulation-ready object shapes and poses. Project webpage: https://rory-weicheng.github.io/SPARCS/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SPARCS, a unified optimization pipeline for real-to-sim scene estimation that jointly recovers shapes and poses of multiple rigid objects under physical contact constraints. It builds on a shape-differentiable contact model and exploits structured sparsity in the augmented Lagrangian Hessian for an efficient linear solver. The pipeline combines learning-based initialization, physics-constrained joint optimization, and differentiable texture refinement. Experiments on cluttered scenes with up to 5 objects and 22 convex hulls are claimed to produce physically valid, simulation-ready reconstructions.
Significance. If the central claims hold under quantitative scrutiny, the work would advance robotics by enabling scalable, physics-consistent scene reconstruction from real observations, directly supporting downstream planning and policy learning. The combination of differentiable contact modeling with an efficient sparse solver addresses a practical bottleneck in multi-object optimization. The absence of metrics, baselines, and convergence validation in the current manuscript, however, limits assessment of whether these innovations deliver reliable gains over existing approaches.
major comments (2)
- [Experiments] Experiments section: The claim that the method 'robustly reconstructs physically valid, simulation-ready object shapes and poses' rests entirely on qualitative demonstrations for scenes with up to 5 objects. No quantitative metrics (pose error, penetration depth, contact violation volume, or success rate across random initializations), baseline comparisons, or ablation studies on augmented Lagrangian convergence (iteration counts, failure rates, sensitivity to initialization) are reported. This directly undermines evaluation of the central robustness claim in multi-contact settings.
- [Method] Optimization formulation (around the augmented Lagrangian solver): The manuscript assumes the shape-differentiable contact model remains globally differentiable and that the solver converges reliably without local minima when shapes and poses are optimized jointly. No empirical checks (gradient accuracy tests, penetration metrics over random seeds, or multi-contact failure analysis) are supplied to support this assumption for scenes with up to 22 convex hulls.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from a brief statement of the specific quantitative improvements (if any) over prior art, rather than relying solely on the qualitative claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the manuscript to incorporate additional quantitative evaluations and empirical validations as outlined.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The claim that the method 'robustly reconstructs physically valid, simulation-ready object shapes and poses' rests entirely on qualitative demonstrations for scenes with up to 5 objects. No quantitative metrics (pose error, penetration depth, contact violation volume, or success rate across random initializations), baseline comparisons, or ablation studies on augmented Lagrangian convergence (iteration counts, failure rates, sensitivity to initialization) are reported. This directly undermines evaluation of the central robustness claim in multi-contact settings.
Authors: We agree that quantitative metrics, baseline comparisons, and ablation studies are necessary to fully substantiate the robustness claims. The current experiments prioritize qualitative demonstrations to highlight the pipeline's ability to produce physically valid, simulation-ready reconstructions in cluttered multi-object scenes. In the revised manuscript, we will add quantitative metrics including pose errors, penetration depths, contact violation volumes, and success rates over random initializations. We will also include comparisons to relevant baselines and ablations on the augmented Lagrangian solver, reporting iteration counts, failure rates, and sensitivity to initialization. revision: yes
-
Referee: [Method] Optimization formulation (around the augmented Lagrangian solver): The manuscript assumes the shape-differentiable contact model remains globally differentiable and that the solver converges reliably without local minima when shapes and poses are optimized jointly. No empirical checks (gradient accuracy tests, penetration metrics over random seeds, or multi-contact failure analysis) are supplied to support this assumption for scenes with up to 22 convex hulls.
Authors: The shape-differentiable contact model is globally differentiable by construction, as established in the referenced prior work on which it builds. For the augmented Lagrangian solver, we will strengthen the manuscript by adding the requested empirical checks. In the revision, we will report gradient accuracy tests, penetration metrics across random seeds, and multi-contact failure analysis to validate reliable convergence in scenes with up to 22 convex hulls. revision: yes
Circularity Check
No significant circularity; formulation builds on external contact model and derives solver independently
full rationale
The paper introduces a joint shape-pose optimization pipeline (SPARCS) that leverages an externally introduced shape-differentiable contact model and exploits structured sparsity in the augmented Lagrangian Hessian to derive an efficient solver. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain. The central claim of robust reconstruction in cluttered scenes is supported by experiments rather than tautological predictions. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- optimization weights and contact stiffness
axioms (2)
- domain assumption Objects behave as rigid bodies whose geometry can be represented by convex hulls
- domain assumption The shape-differentiable contact model provides accurate gradients for simultaneous shape and pose updates
Reference graph
Works this paper leans on
-
[1]
Aditya Agarwal, Gaurav Singh, Bipasha Sen, Tom ´as Lozano-P´erez, and Leslie Pack Kaelbling. Scenecom- plete: Open-world 3d scene completion in cluttered real world environments for robot manipulation.IEEE Robotics and Automation Letters, 11(1):482–489, 2026
work page 2026
-
[2]
M. Aiger, D. Cohen-Or, and D. Levin. A global registra- tion method for 3d point clouds. InProceedings of the Fifth Eurographics Symposium on Geometry Processing, pages 211–220. Eurographics Association, 2008. doi: 10.2312/SGP/SGP08/211-220
-
[3]
Op- timal step nonrigid icp algorithms for surface registration
Brian Amberg, Sami Romdhani, and Thomas Vetter. Op- timal step nonrigid icp algorithms for surface registration. In2007 IEEE conference on computer vision and pattern recognition, pages 1–8. IEEE, 2007
work page 2007
-
[4]
Gen- eralizable 3d scene reconstruction via divide and conquer from a single view
Andreea Ardelean, Mert ¨Ozer, and Bernhard Egger. Gen- eralizable 3d scene reconstruction via divide and conquer from a single view. InInternational Conference on 3D Vision (3DV), 2025
work page 2025
-
[5]
Marco Attene. A lightweight approach to repairing digitized polygon meshes.The visual computer, 26(11): 1393–1406, 2010
work page 2010
-
[6]
Dominik Bauer, Timothy Patten, and Markus Vincze. Verefine: Integrating object pose verification with physics-guided iterative refinement.IEEE Robotics and Automation Letters, 5(3):4289–4296, 2020
work page 2020
-
[7]
Nonlinear programming.Journal of the Operational Research Society, 48(3):334–334, 1997
Dimitri P Bertsekas. Nonlinear programming.Journal of the Operational Research Society, 48(3):334–334, 1997
work page 1997
-
[8]
Bibit Bianchini, Minghan Zhu, Mengti Sun, Bowen Jiang, Camillo J. Taylor, and Michael Posa. Vysics: Object reconstruction under occlusion by fusing vision and contact-rich physics. InRobotics: Science and Systems (RSS), june 2025
work page 2025
-
[9]
Automatic registration for articulated shapes
Will Chang and Matthias Zwicker. Automatic registration for articulated shapes. InComputer Graphics F orum, volume 27, pages 1459–1468. Wiley Online Library, 2008
work page 2008
-
[10]
SAM 3D: 3Dfy Anything in Images
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
The trimmed iterative closest point algorithm
Dmitry Chetverikov, Dmitry Svirko, Dmitry Stepanov, and Pavel Krsek. The trimmed iterative closest point algorithm. In2002 International Conference on Pattern Recognition, volume 3, pages 545–548. IEEE, 2002
work page 2002
-
[12]
Poserbpf: A rao– blackwellized particle filter for 6-d object pose tracking
Xinke Deng, Arsalan Mousavian, Yu Xiang, Fei Xia, Timothy Bretl, and Dieter Fox. Poserbpf: A rao– blackwellized particle filter for 6-d object pose tracking. IEEE Transactions on Robotics, 37(5):1328–1342, 2021
work page 2021
-
[13]
Gill, Walter Murray, and Michael A
Philip E. Gill, Walter Murray, and Michael A. Saunders. SNOPT: An SQP algorithm for large-scale constrained optimization.SIAM Rev., 47:99–131, 2005
work page 2005
-
[14]
Springer Science & Business Media, 2011
Joachim Hilgert and Karl-Hermann Neeb.Structure and geometry of Lie groups. Springer Science & Business Media, 2011
work page 2011
-
[15]
Jerry Hsu, Nghia Truong, Cem Yuksel, and Kui Wu. A general two-stage initialization for sag-free deformable simulations.ACM Transactions on Graphics (Proceed- ings of SIGGRAPH 2022), 41(4):64:1–64:13, 07 2022. ISSN 0730-0301. doi: 10.1145/3528223.3530165
-
[16]
Midi: Multi-instance diffusion for single image to 3d scene generation
Zehuan Huang, Yuan-Chen Guo, Xingqiao An, Yunhan Yang, Yangguang Li, Zi-Xin Zou, Ding Liang, Xihui Liu, Yan-Pei Cao, and Lu Sheng. Midi: Multi-instance diffusion for single image to 3d scene generation. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 23646–23657, 2025
work page 2025
-
[17]
Differentiable rendering: A survey.arXiv preprint arXiv:2006.12057, 2020
Hiroharu Kato, Deniz Beker, Mihai Morariu, Takahiro Ando, Toru Matsuoka, Wadim Kehl, and Adrien Gaidon. Differentiable rendering: A survey.arXiv preprint arXiv:2006.12057, 2020
-
[18]
Samuli Laine, Janne Hellsten, Tero Karras, Yeongho Seol, Jaakko Lehtinen, and Timo Aila. Modular primi- tives for high-performance differentiable rendering.ACM Transactions on Graphics, 39(6), 2020
work page 2020
-
[19]
Manifold: Geometry library for topological robustness, 2025
Emmett Lalish and contributors. Manifold: Geometry library for topological robustness, 2025
work page 2025
-
[20]
Minchen Li, Zachary Ferguson, Teseo Schneider, Timo- thy Langlois, Denis Zorin, Daniele Panozzo, Chenfanfu Jiang, and Danny M. Kaufman. Incremental potential contact: Intersection- and inversion-free large deforma- tion dynamics.ACM Transactions on Graphics (SIG- GRAPH), 39(4), 2020. doi: 10.1145/3386569.3392425
-
[21]
Shichen Liu, Tianye Li, Weikai Chen, and Hao Li. Soft rasterizer: A differentiable renderer for image-based 3d reasoning.The IEEE International Conference on Computer Vision (ICCV), Oct 2019
work page 2019
-
[22]
Pingchuan Ma, Tao Du, Joshua B Tenenbaum, Woj- ciech Matusik, and Chuang Gan. RISP: Rendering- invariant state predictor with differentiable simulation and rendering for cross-domain parameter estimation. In International Conference on Learning Representations, 2021
work page 2021
-
[23]
Physpose: Refining 6d object poses with physical constraints.arXiv preprint arXiv:2503.23587, 2025
Martin Malenick `y, Martin C´ıfka, M´ed´eric Fourmy, Louis Montaut, Justin Carpentier, Josef Sivic, and Vladimir Petrik. Physpose: Refining 6d object poses with physical constraints.arXiv preprint arXiv:2503.23587, 2025
-
[24]
A review of differentiable simulators.IEEE Access, 2024
Rhys Newbury, Jack Collins, Kerry He, Jiahe Pan, In- gmar Posner, David Howard, and Akansel Cosgun. A review of differentiable simulators.IEEE Access, 2024
work page 2024
-
[25]
Junfeng Ni, Yixin Chen, Bohan Jing, Nan Jiang, Bin Wang, Bo Dai, Puhao Li, Yixin Zhu, Song-Chun Zhu, and Siyuan Huang. Phyrecon: Physically plausible neural scene reconstruction.Advances in Neural Information Processing Systems, 37:25747–25780, 2024
work page 2024
-
[26]
Jorge Nocedal and Stephen J Wright.Numerical opti- mization. Springer, 2006
work page 2006
-
[27]
Michael Posa, Cecilia Cantu, and Russ Tedrake. A direct method for trajectory optimization of rigid bodies through contact.The International Journal of Robotics Research, 33(1):69–81, 2014
work page 2014
-
[28]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Rong- hang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R ¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll ´ar, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:24...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Tyrrell Rockafellar.Convex analysis
R. Tyrrell Rockafellar.Convex analysis. Princeton Math- ematical Series. Princeton University Press, Princeton, N. J., 1970
work page 1970
-
[30]
Aleksandr Segal, Dirk Haehnel, and Sebastian Thrun. Generalized-icp. InRobotics: science and systems, vol- ume 2, page 435. Seattle, W A, 2009
work page 2009
-
[31]
Mikhail V Solodov. Global convergence of an sqp method without boundedness assumptions on any of the iterative sequences.Mathematical programming, 118(1): 1–12, 2009
work page 2009
-
[32]
Changkyu Song and Abdeslam Boularias. Inferring 3d shapes of unknown rigid objects in clutter through inverse physics reasoning.IEEE robotics and automation letters, 4(2):201–208, 2018
work page 2018
-
[33]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
work page 2012
-
[34]
Andreas W ¨achter and Laurence T. Biegler. On the implementation of a primal-dual interior point filter line- search algorithm for large-scale nonlinear programming. Mathematical Programming, 106(1):25–57, 2006
work page 2006
-
[35]
Xinyue Wei, Minghua Liu, Zhan Ling, and Hao Su. Approximate convex decomposition for 3d meshes with collision-aware concavity and tree search.ACM Trans- actions on Graphics (TOG), 41(4):1–18, 2022
work page 2022
-
[36]
Foundationpose: Unified 6d pose estimation and tracking of novel objects
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17868–17879, 2024
work page 2024
-
[37]
Holoscene: Simu- lation-ready interactive 3d worlds from a single video
Hongchi Xia, Chih-Hao Lin, Hao-Yu Hsu, Quentin Leboutet, Katelyn Gao, Michael Paulitsch, Benjamin Ummenhofer, and Shenlong Wang. Holoscene: Simu- lation-ready interactive 3d worlds from a single video. InThe Thirty-ninth Annual Conference on Neural Infor- mation Processing Systems, 2025
work page 2025
-
[38]
PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes
Yu Xiang, Tanner Schmidt, Venkatraman Narayanan, and Dieter Fox. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes.arXiv preprint arXiv:1711.00199, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
An End-to-End Differentiable Framework for Contact-Aware Robot Design
Jie Xu, Tao Chen, Lara Zlokapa, Michael Foshey, Woj- ciech Matusik, Shinjiro Sueda, and Pulkit Agrawal. An End-to-End Differentiable Framework for Contact-Aware Robot Design. InProceedings of Robotics: Science and Systems, Virtual, July 2021. doi: 10.15607/RSS.2021. XVII.008
-
[40]
Kaixin Yao, Longwen Zhang, Xinhao Yan, Yan Zeng, Qixuan Zhang, Lan Xu, Wei Yang, Jiayuan Gu, and Jingyi Yu. Cast: Component-aligned 3d scene reconstruc- tion from an rgb image.ACM Transactions on Graphics (TOG), 44(4):1–19, 2025
work page 2025
-
[41]
Sdrs: Shape-differentiable robot simulator
Xiaohan Ye, Xifeng Gao, Kui Wu, Zherong Pan, and Taku Komura. Sdrs: Shape-differentiable robot simulator. IEEE Transactions on Robotics, pages 1–20, 2025
work page 2025
-
[42]
Xiaohan Ye, Kui Wu, Zherong Pan, and Taku Komura. Efficient differentiable contact model with long-range influence.arXiv preprint arXiv:2509.20917, 2025
- [43]
-
[44]
Mengchao Zhang and Kris Hauser. Semi-infinite pro- gramming with complementarity constraints for pose op- timization with pervasive contact. In2021 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 6329–6335, 2021. doi: 10.1109/ICRA48506.2021. 9561609
-
[45]
Mengchao Zhang, Devesh K Jha, Arvind U Raghunathan, and Kris Hauser. Simultaneous trajectory optimization and contact selection for contact-rich manipulation with high-fidelity geometry.IEEE Transactions on Robotics, 41:2677–2690, 2025
work page 2025
-
[46]
Yifan Zhu, Tianyi Xiang, Aaron M Dollar, and Zherong Pan. One-shot real-to-sim via end-to-end differentiable simulation and rendering.IEEE Robotics and Automation Letters, 2025. APPENDIX In this appendix, we present the complete details of our methods, as well as several additional results. First in Ap- pendix A, we provide the complete detail of our ALM-...
work page 2025
-
[47]
Force equilibrium for objects: Cequi(z)≜¯C(z)=∇q ⎡⎢⎢⎢⎢⎣ Ψ(q, x)−∑ i≠i′ ∑ j,j′ ∑ k ⟨Xijk, f∥ ijk,i′j′⟩ ⎤⎥⎥⎥⎥⎦ =0,
-
[48]
Orthogonality: C iji′j′ orth (z)≜ ⎛ ⎜⎜ ⎝ ⋮ ⟨f⊥ ijk,i′j′, f ∥ ijk,i′j′⟩ ⋮ ⎞ ⎟⎟ ⎠ =0,
-
[49]
Friction cone: C iji′j′ cone (z)≜ ⎛ ⎜ ⎝ ⋮ ∥f∥ ijk,i′j′∥−η∥f⊥ ijk,i′j′∥ ⋮ ⎞ ⎟ ⎠ ≤0,
-
[50]
Tangential force equilibrium for separating plane: Ciji′j′ plane(z)≜⎛ ⎝ ∑kf∥ ijk,i′j′+∑k′f∥ i′j′k′,ij Tiji′j′[∑kXijk×f∥ ijk,i′j′+∑k′Xi′j′k′×f∥ i′j′k′,ij] ⎞ ⎠=0. Note that we redefine ¯CasC equi for more conveniently dis- tinguishing different types of constraints. We then compactly group the constraints as follows: Ceq(z)≜ ⎛ ⎜⎜ ⎝ Cequi(z) {Ciji′j′ orth (z...
-
[51]
Simulator Parameter Setting:For a complete list of simulator related parameters, we refer the readers to the official documentation. Here we explain the critical settings that differ from the default values: the simulatortimstep=10 −3, and theintegratoris set to “implicit” to enhance simulation stability for the cluttered scene. Moreover, MuJoCo’s contact...
-
[52]
The results of these scene estimators are using mesh-based object representation
Baseline Processing:For comparison, we simulate the scene estimated using various visual inference pipelines, in- cluding the SAM3D + FoundationPose pipeline and two baselines below. The results of these scene estimators are using mesh-based object representation. For each of the estimated rigid bodies in the scene, we replace their collision mesh by a hi...
-
[53]
Optimized Result Processing:We discuss details for loading results from our optimization result to MuJoCo. For each of the rigid bodies in the scene, it’s collision geometry is the unions of convex hulls extracted from the optimization resultx, while for visual geometry, we used the triangular mesh merged fromxusing Manifold3d Library [19] with the textur...
work page 1936
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.