Recognition: 1 theorem link
· Lean TheoremMultiModalPFN: Extending Prior-Data Fitted Networks for Multimodal Tabular Learning
Pith reviewed 2026-05-15 20:08 UTC · model grok-4.3
The pith
MMPFN extends TabPFN to handle images and text with tabular data through embedding projectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
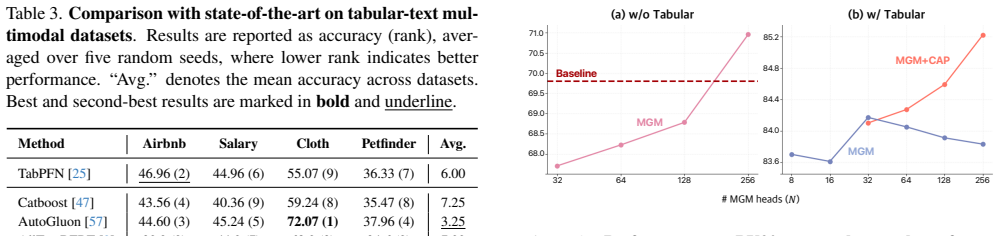
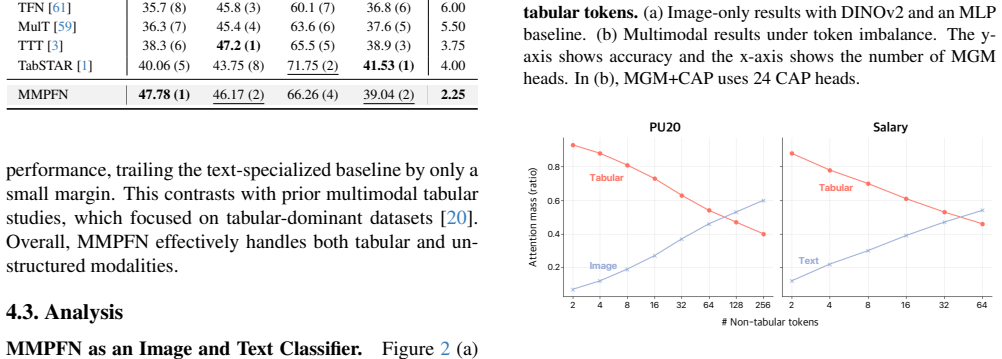
The Multi-Modal Prior-data Fitted Network (MMPFN) extends TabPFN to handle tabular and non-tabular modalities in a unified manner through per-modality encoders, modality projectors, and pre-trained foundation models. The modality projectors transform non-tabular embeddings into tabular-compatible tokens. A multi-head gated MLP and a cross-attention pooler are introduced to extract richer context from non-tabular inputs while mitigating attention imbalance. Experiments on medical and general-purpose multimodal datasets show consistent outperformance over state-of-the-art methods and effective use of non-tabular modalities alongside tabular features.
What carries the argument
The modality projectors that bridge non-tabular and tabular data by transforming embeddings into compatible tokens using a multi-head gated MLP and cross-attention pooler.
If this is right
- Multimodal data from healthcare and marketing can be processed more effectively in a single model.
- Non-tabular modalities are exploited to enhance predictions without separate processing streams.
- The framework provides a scalable way to extend prior-data fitted networks to heterogeneous inputs.
- Attention imbalance common in multimodal setups is addressed through the pooler design.
Where Pith is reading between the lines
- Extensions to other modalities could follow similar projection strategies for broader foundation model use.
- Comparisons with other multimodal architectures might show efficiency gains from the tabular token approach.
- Applications in new domains like autonomous systems combining sensor data and images could be explored.
Load-bearing premise
The modality projectors and the multi-head gated MLP plus cross-attention pooler can reliably convert non-tabular embeddings into tabular-compatible tokens without substantial information loss or attention imbalance.
What would settle it
Running MMPFN on a multimodal dataset and finding its performance no better than or worse than competitive methods, or detecting high information loss via embedding similarity measures before and after projection.
Figures



read the original abstract
Recently, TabPFN has gained attention as a foundation model for tabular data. However, it struggles to integrate heterogeneous modalities such as images and text, which are common in domains like healthcare and marketing, thereby limiting its applicability. To address this, we present the Multi-Modal Prior-data Fitted Network (MMPFN), which extends TabPFN to handle tabular and non-tabular modalities in a unified manner. MMPFN comprises per-modality encoders, modality projectors, and pre-trained foundation models. The modality projectors serve as the critical bridge, transforming non-tabular embeddings into tabular-compatible tokens for unified processing. To this end, we introduce a multi-head gated MLP and a cross-attention pooler that extract richer context from non-tabular inputs while mitigates attention imbalance issue in multimodal learning. Extensive experiments on medical and general-purpose multimodal datasets demonstrate that MMPFN consistently outperforms competitive state-of-the-art methods and effectively exploits non-tabular modalities alongside tabular features. These results highlight the promise of extending prior-data fitted networks to the multimodal setting, offering a scalable and effective framework for heterogeneous data learning. The source code is available at https://github.com/too-z/MultiModalPFN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MultiModalPFN (MMPFN), an extension of TabPFN for multimodal tabular learning. It adds per-modality encoders and modality projectors (a multi-head gated MLP combined with a cross-attention pooler) that map non-tabular embeddings from images and text into tabular-compatible tokens, enabling unified processing within the prior-data fitted network framework. Experiments on medical and general-purpose multimodal datasets are reported to show consistent outperformance over competitive state-of-the-art baselines while addressing attention imbalance.
Significance. If the empirical results hold under rigorous verification, the work is significant because it provides a practical, scalable route to extend prior-data fitted networks to heterogeneous multimodal settings that arise in healthcare and marketing. The release of source code supports reproducibility and allows independent validation of the modality projectors' effectiveness.
major comments (2)
- [§4] §4 (Experiments): the central claim of consistent outperformance over SOTA baselines is load-bearing for the paper's contribution, yet the manuscript does not report the number of independent runs, dataset sizes, or statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values); without these, the reliability of the reported gains cannot be assessed.
- [§3.2] §3.2 (Modality Projectors): the description of the cross-attention pooler states that it mitigates attention imbalance, but no quantitative ablation isolates its contribution versus the multi-head gated MLP alone; this is needed to confirm that the design choice is responsible for the observed gains rather than other factors.
minor comments (2)
- The abstract would be strengthened by naming the specific baselines, key metrics (e.g., accuracy, AUC), and number of datasets used.
- [Figure 1] Figure 1 (architecture diagram): ensure all components of the modality projectors are explicitly labeled and that the flow from non-tabular embeddings to tabular tokens is visually unambiguous.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our work. We address each of the major comments point by point below. We have made revisions to the manuscript to incorporate additional experimental details and ablations as suggested, which we believe strengthen the paper.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the central claim of consistent outperformance over SOTA baselines is load-bearing for the paper's contribution, yet the manuscript does not report the number of independent runs, dataset sizes, or statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values); without these, the reliability of the reported gains cannot be assessed.
Authors: We agree with the referee that providing the number of independent runs, dataset sizes, and statistical significance is essential for validating the empirical claims. In the revised version, we have added a new table summarizing dataset statistics including sizes, specified that all results are averaged over 5 independent runs with different random seeds, and included p-values from paired t-tests comparing MMPFN to baselines in the main results tables (Section 4). These additions confirm the statistical significance of the observed improvements. revision: yes
-
Referee: [§3.2] §3.2 (Modality Projectors): the description of the cross-attention pooler states that it mitigates attention imbalance, but no quantitative ablation isolates its contribution versus the multi-head gated MLP alone; this is needed to confirm that the design choice is responsible for the observed gains rather than other factors.
Authors: We acknowledge that an ablation study isolating the cross-attention pooler would provide stronger evidence for its specific contribution. We have performed this ablation and added the results to Section 3.2 and the supplementary material. The ablation shows that adding the cross-attention pooler to the multi-head gated MLP yields an average improvement of 2.3% in AUC across the medical datasets, supporting its role in addressing attention imbalance. We have also included visualizations of attention weights to further illustrate the effect. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript describes an empirical architecture extension of TabPFN via modality projectors (multi-head gated MLP and cross-attention pooler) and reports performance on external multimodal datasets. No equations, derivations, or predictions are presented that reduce by construction to fitted inputs or self-citations. Central claims rest on experimental comparisons to SOTA baselines and released code, which constitute independent external benchmarks. Minor self-citations to TabPFN are not load-bearing for the new multimodal components.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The modality projectors serve as the critical bridge, transforming non-tabular embeddings into tabular-compatible tokens... we introduce a multi-head gated MLP and a cross-attention pooler that extract richer context from non-tabular inputs while mitigates attention imbalance issue
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
TabPFN-3: Technical Report
TabPFN-3 delivers state-of-the-art tabular prediction performance on benchmarks up to 1M rows, is up to 20x faster than prior versions, and introduces test-time scaling that beats non-TabPFN models by hundreds of Elo points.
Reference graph
Works this paper leans on
-
[1]
Tabstar: A foundation tabular model with semantically target-aware rep- resentations
Alan Arazi, Eilam Shapira, and Roi Reichart. Tabstar: A foundation tabular model with semantically target-aware rep- resentations. InNeurIPS, 2025. 6
work page 2025
-
[2]
Scarf: Self-supervised contrastive learning using random feature corruption
Dara Bahri, Heinrich Jiang, Yi Tay, and Donald Metzler. Scarf: Self-supervised contrastive learning using random feature corruption. InICLR, 2022. 1
work page 2022
-
[3]
Revisiting multimodal transformers for tabular data with text fields
Thomas Bonnier. Revisiting multimodal transformers for tabular data with text fields. InFindings of ACL, pages 1481– 1500, 2024. 2, 4, 5, 6
work page 2024
-
[4]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M3-embedding: Multi- linguality, multi-functionality, multi-granularity text embed- dings through self-knowledge distillation. InFindings of ACL, pages 2318–2335, Bangkok, Thailand, 2024. ACL. 2
work page 2024
-
[5]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InACM SIGKDD Int. Conf. Knowl. Discov. Data Min., pages 785–794, 2016. 1
work page 2016
-
[6]
Uniter: Universal image-text representation learning
Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. Uniter: Universal image-text representation learning. InECCV, pages 104–120, 2020. 2
work page 2020
-
[7]
Kevin Clark, Minh-Thang Luong, Quoc V . Le, and Christo- pher D. Manning. ELECTRA: Pre-training text encoders as discriminators rather than generators. InICLR, 2020. 2, 4, 6, 3
work page 2020
-
[8]
Can Cui, Haichun Yang, Yaohong Wang, Shilin Zhao, Zuhayr Asad, Lori A Coburn, Keith T Wilson, Bennett A Landman, and Yuankai Huo. Deep multimodal fusion of im- age and non-image data in disease diagnosis and prognosis: a review.Progress in Biomedical Engineering, 5(2):022001,
-
[9]
Ronnie Das, Wasim Ahmed, Kshitij Sharma, Mariann Hardey, Yogesh K Dwivedi, Ziqi Zhang, Chrysostomos Apostolidis, and Raffaele Filieri. Towards the development of an explainable e-commerce fake review index: An at- tribute analytics approach.European Journal of Operational Research, 317(2):382–400, 2024. 1
work page 2024
-
[10]
Language modeling with gated convolutional net- works
Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional net- works. InICML, pages 933–941, 2017. 4
work page 2017
-
[11]
Aaron Defazio, Xingyu Yang, Ahmed Khaled, Konstantin Mishchenko, Harsh Mehta, and Ashok Cutkosky. The road less scheduled. InNeurIPS, pages 9974–10007, 2024. 4
work page 2024
-
[12]
An image is worth 16x16 words: Trans- formers for image recognition at scale
Alexey Dosovitskiy. An image is worth 16x16 words: Trans- formers for image recognition at scale. InICLR, 2021. 4
work page 2021
-
[13]
Tip: Tabular-image pre- training for multimodal classification with incomplete data
Siyi Du, Shaoming Zheng, Yinsong Wang, Wenjia Bai, De- clan P O’Regan, and Chen Qin. Tip: Tabular-image pre- training for multimodal classification with incomplete data. InECCV, pages 478–496, 2024. 2, 5, 7, 8, 4
work page 2024
-
[14]
Siyi Du, Xinzhe Luo, Declan P O’Regan, and Chen Qin. Stil: Semi-supervised tabular-image learning for comprehensive task-relevant information exploration in multimodal classifi- cation. InCVPR, pages 15549–15559, 2025. 2, 7, 4
work page 2025
-
[15]
Sayna Ebrahimi, Sercan O Arik, Yihe Dong, and Tomas Pfis- ter. Lanistr: Multimodal learning from structured and un- structured data.arXiv preprint arXiv:2305.16556, 2023. 2
-
[16]
Eva: Exploring the limits of masked visual representa- tion learning at scale
Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. Eva: Exploring the limits of masked visual representa- tion learning at scale. InCVPR, pages 19358–19369, 2023. 2
work page 2023
-
[17]
Eva-02: A visual representation for neon genesis.Image and Vision Computing, 149:105171,
Yuxin Fang, Quan Sun, Xinggang Wang, Tiejun Huang, Xin- long Wang, and Yue Cao. Eva-02: A visual representation for neon genesis.Image and Vision Computing, 149:105171,
-
[18]
A kernel two-sample test.The journal of machine learning research, 13(1):723– 773, 2012
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bern- hard Sch¨olkopf, and Alexander Smola. A kernel two-sample test.The journal of machine learning research, 13(1):723– 773, 2012. 1
work page 2012
-
[19]
A package for learning on tabular and text data with transformers
Ken Gu and Akshay Budhkar. A package for learning on tabular and text data with transformers. InProceedings of the Third Workshop on Multimodal Artificial Intelligence, pages 69–73, 2021. 2
work page 2021
-
[20]
Best of both worlds: Multimodal contrastive learning with tabular and imaging data
Paul Hager, Martin J Menten, and Daniel Rueckert. Best of both worlds: Multimodal contrastive learning with tabular and imaging data. InCVPR, pages 23924–23935, 2023. 1, 2, 5, 6, 4
work page 2023
-
[21]
Deberta: Decoding-enhanced bert with disentangled attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. Deberta: Decoding-enhanced bert with disentangled attention. InICLR, 2021. 2, 4
work page 2021
-
[22]
Pengcheng He, Jianfeng Gao, and Weizhu Chen. De- BERTav3: Improving deBERTa using ELECTRA-style pre- training with gradient-disentangled embedding sharing. In ICLR, 2023. 2
work page 2023
-
[23]
Tabllm: Few- shot classification of tabular data with large language mod- els
Stefan Hegselmann, Alejandro Buendia, Hunter Lang, Mon- ica Agrawal, Xiaoyi Jiang, and David Sontag. Tabllm: Few- shot classification of tabular data with large language mod- els. InAISTATS, pages 5549–5581, 2023. 2
work page 2023
-
[24]
Healnet: multimodal fusion for heterogeneous biomed- ical data
Konstantin Hemker, Nikola Simidjievski, and Mateja Jam- nik. Healnet: multimodal fusion for heterogeneous biomed- ical data. InNeurIPS, 2024. 2, 5
work page 2024
-
[25]
Tabpfn: A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel M ¨uller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second. InICLR, 2023. 1, 2, 5, 6
work page 2023
-
[26]
Accurate predictions on small data with a tabular foundation model.Nature, 637 (8045):319–326, 2025
Noah Hollmann, Samuel M ¨uller, Lennart Purucker, Ar- jun Krishnakumar, Max K ¨orfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637 (8045):319–326, 2025. 1, 2, 4, 5
work page 2025
-
[27]
Shih-Cheng Huang, Anuj Pareek, Saeed Seyyedi, Imon Banerjee, and Matthew P Lungren. Fusion of medical imag- ing and electronic health records using deep learning: a sys- tematic review and implementation guidelines.NPJ digital medicine, 3(1):136, 2020. 1
work page 2020
-
[28]
Tabular insights, visual impacts: transferring expertise from tables to images
Jun-Peng Jiang, Han-Jia Ye, Leye Wang, Yang Yang, Yuan Jiang, and De-Chuan Zhan. Tabular insights, visual impacts: transferring expertise from tables to images. InICML, 2024. 4
work page 2024
-
[29]
Multimodal tabular reasoning with privileged structured information
Jun-Peng Jiang, Yu Xia, Hai-Long Sun, Shiyin Lu, Qing- Guo Chen, Weihua Luo, Kaifu Zhang, De-Chuan Zhan, and Han-Jia Ye. Multimodal tabular reasoning with privileged structured information. InNeurIPS, 2025. 2
work page 2025
-
[30]
Melbourne airbnb open data.kaggle.com/ datasets / tylerx / melbourne - airbnb - open - data, 2018
Kaggle. Melbourne airbnb open data.kaggle.com/ datasets / tylerx / melbourne - airbnb - open - data, 2018. Accessed: September 24, 2025. 2, 4, 5
work page 2018
-
[31]
Women’s e-commerce clothing reviews
Kaggle. Women’s e-commerce clothing reviews. kaggle . com / datasets / nicapotato / womens - ecommerce- clothing- reviews, 2019. Accessed: September 24, 2025. 5
work page 2019
-
[32]
Kaggle. Petfinder.my adoption prediction.https : //www.kaggle.com/competitions/petfinder- adoption- prediction, 2019. Accessed: September 24, 2025. 5
work page 2019
-
[33]
Predict the data scientist’s salary in india.kaggle
Kaggle. Predict the data scientist’s salary in india.kaggle. com / datasets / ankitkalauni / predict - the - data-scientists-salary-in-india, 2021. Ac- cessed: September 24, 2025. 2, 5
work page 2021
-
[34]
Light- gbm: A highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Light- gbm: A highly efficient gradient boosting decision tree. In NeurIPS, 2017. 1
work page 2017
-
[35]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InICML, pages 19730–19742, 2023. 2
work page 2023
-
[36]
VisualBERT: A Simple and Performant Baseline for Vision and Language
Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. Visualbert: A simple and perfor- mant baseline for vision and language.arXiv preprint arXiv:1908.03557, 2019. 2
work page internal anchor Pith review arXiv 1908
-
[37]
Tab2Text - a framework for deep learning with tabular data
Tong Lin, Jason Yan, David Jurgens, and Sabina J Tomkins. Tab2Text - a framework for deep learning with tabular data. InFindings of EMNLP, pages 12925–12935, 2024. 2
work page 2024
-
[38]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, pages 34892–34916,
-
[39]
Deep transfer learning with joint adaptation net- works
Mingsheng Long, Han Zhu, Jianmin Wang, and Michael I Jordan. Deep transfer learning with joint adaptation net- works. InICML, pages 2208–2217, 2017. 2
work page 2017
-
[40]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019. 5
work page 2019
-
[41]
Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks
Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. InNeurIPS, 2019. 2
work page 2019
-
[42]
Jiaqi Luo, Yuan Yuan, and Shixin Xu. Time: Tabpfn- integrated multimodal engine for robust tabular-image learn- ing.arXiv preprint arXiv:2506.00813, 2025. 2, 5
-
[43]
Towards benchmarking foundation models for tabular data with text
Martin Mr ´az, Breenda Das, Anshul Gupta, Lennart Purucker, and Frank Hutter. Towards benchmarking foundation models for tabular data with text. InICML Workshop, 2025. 4
work page 2025
-
[44]
DINOv2: Learning robust visual features without su- pervision.Trans
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without su- pervision.Trans. Mach. Learn. Res., 2024. 2, 4, 6, 3
work page 2024
-
[45]
Andre GC Pacheco, Gustavo R Lima, Amanda S Salo- mao, Breno Krohling, Igor P Biral, Gabriel G De Angelo, F´abio CR Alves Jr, Jos ´e GM Esgario, Alana C Simora, Pe- dro BC Castro, et al. Pad-ufes-20: A skin lesion dataset composed of patient data and clinical images collected from smartphones.Data in Brief, 32:106221, 2020. 2, 4, 5
work page 2020
-
[46]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Du- moulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InAAAI, 2018. 2, 7, 8
work page 2018
-
[47]
Catboost: Un- biased boosting with categorical features
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Dorogush, and Andrey Gulin. Catboost: Un- biased boosting with categorical features. InNeurIPS, 2018. 1, 5, 6
work page 2018
-
[48]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, pages 8748–8763, 2021. 2
work page 2021
-
[49]
R. Sawyer-Lee, F. Gimenez, A. Hoogi, and D. Rubin. Cu- rated breast imaging subset of digital database for screening mammography (cbis-ddsm). The Cancer Imaging Archive,
-
[50]
J ¨org Schilcher, Alva Nilsson, Oliver Andlid, and Anders Eklund. Fusion of electronic health records and radio- graphic images for a multimodal deep learning prediction model of atypical femur fractures.Computers in Biology and Medicine, 168:107704, 2024. 1
work page 2024
-
[51]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Gowthami Somepalli, Micah Goldblum, Avi Schwarzschild, C Bayan Bruss, and Tom Goldstein. Saint: Improved neural networks for tabular data via row attention and contrastive pre-training.arXiv preprint arXiv:2106.01342, 2021. 1
-
[53]
Vl-bert: Pre-training of generic visual- linguistic representations
Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, and Jifeng Dai. Vl-bert: Pre-training of generic visual- linguistic representations. InICLR, 2020. 2
work page 2020
-
[54]
Mul- timodal temporal fusion transformers are good product de- mand forecasters.IEEE Trans
Maarten Sukel, Stevan Rudinac, and Marcel Worring. Mul- timodal temporal fusion transformers are good product de- mand forecasters.IEEE Trans. Multimedia, 31(2):48–60,
-
[55]
Chi Sun, Xipeng Qiu, Yige Xu, and Xuanjing Huang. How to fine-tune bert for text classification? InChina national con- ference on Chinese computational linguistics, pages 194– 206, 2019. 6
work page 2019
-
[56]
LXMERT: Learning cross- modality encoder representations from transformers
Hao Tan and Mohit Bansal. LXMERT: Learning cross- modality encoder representations from transformers. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP), pages 5100–5111, 2019. 2
work page 2019
-
[57]
Autogluon-multimodal (automm): Supercharging multimodal automl with foundation models
Zhiqiang Tang, Haoyang Fang, Su Zhou, Taojiannan Yang, Zihan Zhong, Cuixiong Hu, Katrin Kirchhoff, and George Karypis. Autogluon-multimodal (automm): Supercharging multimodal automl with foundation models. InICAML, pages 15/1–35, 2024. 2, 4, 5, 6
work page 2024
-
[58]
Zhiqiang Tang, Zihan Zhong, Tong He, and Gerald Fried- land. Bag of tricks for multimodal automl with image, text, and tabular data.arXiv preprint arXiv:2412.16243, 2024. 2, 4
-
[59]
Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov
Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J. Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. Multimodal transformer for unaligned multimodal language sequences. InACL, 2019. 5, 6
work page 2019
-
[60]
Benjamin Warner, Antoine Chaffin, Benjamin Clavi ´e, Orion Weller, Oskar Hallstr ¨om, Said Taghadouini, Alexis Gal- lagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Grif- fin Thomas Adams, Jeremy Howard, and Iacopo Poli. Smarter, better, faster, longer: A modern bidirectional en- coder for fast, memory efficient, and long context finetuning and inference. ...
-
[61]
Association for Computational Linguistics. 2
-
[62]
Tensor fusion network for mul- timodal sentiment analysis
Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Tensor fusion network for mul- timodal sentiment analysis. InEMNLP, pages 1103–1114,
-
[63]
Deep mul- timodal data fusion.ACM Comput
Fei Zhao, Chengcui Zhang, and Baocheng Geng. Deep mul- timodal data fusion.ACM Comput. Surv., 56(9):1–36, 2024. 1
work page 2024
-
[64]
ibot: Image bert pre-training with online tokenizer
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. ibot: Image bert pre-training with online tokenizer. InICLR, 2022. 2
work page 2022
-
[65]
Xuran Zhu. Cross-modal domain adaptation in brain disease diagnosis: Maximum mean discrepancy-based convolutional neural networks. InInt. Conf. Commun., Inf. Syst. Comput. Eng., pages 1515–1519, 2024. 1 MultiModalPFN: Extending Prior-Data Fitted Networks for Multimodal Tabular Learning Supplementary Material S1. Additional Analysis Attention Imbalance.Fig...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.