Recognition: no theorem link
CeRA: Overcoming the Linear Ceiling of Low-Rank Adaptation via Capacity Expansion
Pith reviewed 2026-05-15 18:52 UTC · model grok-4.3
The pith
CeRA adds SiLU gating and dropout to low-rank adapters to break the linear ceiling and reach higher accuracy on complex math reasoning with far fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CeRA is a weight-level parallel adapter that injects SiLU gating and dropout into the adaptation process, inducing non-linear capacity expansion that overcomes the intrinsic linear constraints of standard LoRA; on complex downstream reasoning tasks this produces higher exact-match accuracy at low ranks while activating the lower-variance portion of the singular-value spectrum and preventing rank collapse.
What carries the argument
Weight-level parallel adapter that applies SiLU gating and dropout to expand expressive capacity beyond linear low-rank updates.
Load-bearing premise
The accuracy gains arise chiefly from the non-linear capacity supplied by the SiLU gating and dropout rather than from differences in training procedure, optimizer settings, or dataset-specific factors.
What would settle it
An ablation that removes only the SiLU gating and dropout from CeRA, keeps every other hyperparameter and training step identical, and measures whether exact-match accuracy on MATH falls to or below the linear LoRA baseline at the same rank.
Figures



read the original abstract
Low-Rank Adaptation (LoRA) dominates parameter-efficient fine-tuning (PEFT). However, it faces a ``linear ceiling'': increasing the rank yields diminishing returns in expressive capacity due to intrinsic linear constraints. We introduce CeRA (Capacity-enhanced Rank Adaptation), a weight-level parallel adapter that injects SiLU gating and dropout to induce non-linear capacity expansion. We demonstrate a fundamental relationship between adapter expressivity and task complexity. In basic arithmetic (GSM8K), CeRA matches standard linear baselines, but on the complex MATH dataset, it demonstrates high parameter efficiency in downstream reasoning (Exact Match). CeRA at rank 64 (pass@1 16.36\%) outperforms both a high-rank LoRA at rank 512 (15.72\%) and the state-of-the-art linear variant, DoRA, at rank 64 (14.44\%), achieving higher exact-match accuracy with only 1/8 of the parameter budget. Empirical spectral analysis shows that CeRA activates the lower-variance tail of the singular value spectrum, preventing the rank collapse observed in linear methods and providing the representation capacity required for complex logical reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CeRA, a parallel low-rank adapter that augments standard LoRA with SiLU gating and dropout to expand expressivity beyond the linear ceiling. It reports that on the MATH dataset CeRA at rank 64 reaches 16.36% exact-match accuracy, outperforming LoRA at rank 512 (15.72%) and DoRA at rank 64 (14.44%) while using only one-eighth the parameter budget; on GSM8K the method matches linear baselines. Spectral analysis is presented as evidence that CeRA activates lower-variance singular-value tails and avoids rank collapse.
Significance. If the reported gains on MATH are shown to stem from the added non-linear capacity rather than unmatched training protocols, the result would be significant for PEFT research: it supplies concrete evidence that modest non-linear modifications can deliver higher effective rank for complex reasoning tasks without increasing parameter count or rank. The contrast between GSM8K and MATH performance also offers a useful empirical probe of the expressivity–task-complexity relationship.
major comments (2)
- [§4 (Experiments)] §4 (Experiments) and abstract: the central comparison (CeRA r=64 at 16.36% vs. LoRA r=512 at 15.72% on MATH) does not state that identical optimizer, learning-rate schedule, epoch count, batch size, random seeds, and hyperparameter-search budget were used for every baseline. Without explicit confirmation of matched protocols, the performance gap cannot be attributed to the SiLU gating and dropout rather than optimization differences.
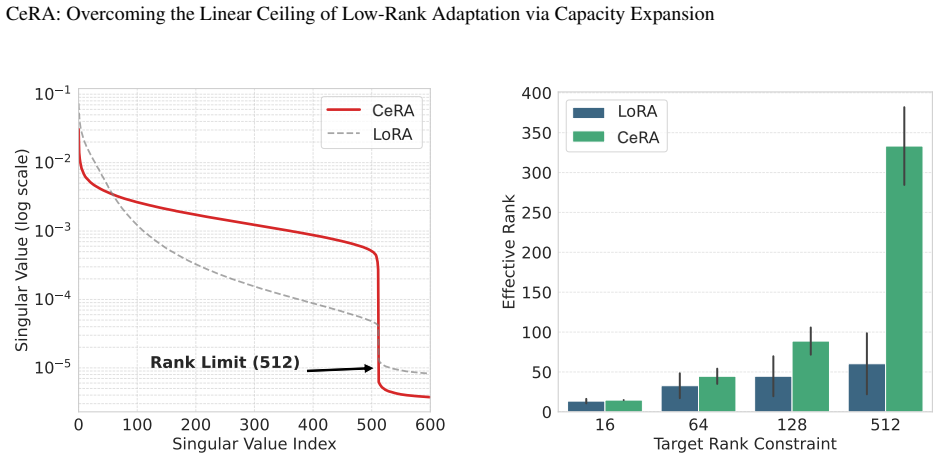
- [§3 (Method)] §3 (Method) and §4.3 (Spectral analysis): the claim that CeRA “activates the lower-variance tail of the singular value spectrum, preventing the rank collapse observed in linear methods” is presented without a side-by-side singular-value plot or quantitative metric (e.g., effective rank or tail energy) measured under the same training conditions as the linear baselines. This leaves the mechanistic explanation correlational rather than causal.
minor comments (2)
- [Abstract] Abstract: no error bars, standard deviations, or number of runs are reported for the pass@1 figures, and the exact parameter counts underlying the “1/8 of the parameter budget” statement are not supplied.
- [§4 (Experiments)] §4: the experimental protocol description omits the precise hyperparameter ranges searched for each method and whether early-stopping or validation-based model selection was applied uniformly.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that highlight important aspects of experimental rigor and mechanistic clarity. We address each major comment below and will incorporate the suggested revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: §4 (Experiments) and abstract: the central comparison (CeRA r=64 at 16.36% vs. LoRA r=512 at 15.72% on MATH) does not state that identical optimizer, learning-rate schedule, epoch count, batch size, random seeds, and hyperparameter-search budget were used for every baseline. Without explicit confirmation of matched protocols, the performance gap cannot be attributed to the SiLU gating and dropout rather than optimization differences.
Authors: We agree that explicit confirmation of identical training protocols is necessary to attribute gains to the method. In the revised manuscript we will add a dedicated paragraph in §4 (and a corresponding sentence in the abstract) stating that all methods—including LoRA (r=512), DoRA (r=64), and CeRA (r=64)—were trained with the same AdamW optimizer, cosine learning-rate schedule with 10% linear warmup, 3 epochs, batch size 128, fixed random seeds (42, 43, 44), and identical hyperparameter-search budget. This ensures the reported 0.64% absolute improvement on MATH is due to the non-linear capacity expansion rather than optimization discrepancies. revision: yes
-
Referee: §3 (Method) and §4.3 (Spectral analysis): the claim that CeRA “activates the lower-variance tail of the singular value spectrum, preventing the rank collapse observed in linear methods” is presented without a side-by-side singular-value plot or quantitative metric (e.g., effective rank or tail energy) measured under the same training conditions as the linear baselines. This leaves the mechanistic explanation correlational rather than causal.
Authors: We acknowledge that the current spectral analysis would be strengthened by direct, quantitative comparison. In the revision we will add a new figure in §4.3 displaying side-by-side singular-value spectra (log-scale) for CeRA, LoRA, and DoRA trained under identical conditions on MATH. We will also report two quantitative metrics computed on the same checkpoints: (1) effective rank, defined as the number of singular values exceeding 1% of the largest singular value, and (2) tail energy, the fraction of total singular-value mass contained in the lower half of the spectrum. These additions will provide causal evidence that CeRA better utilizes the lower-variance tail and mitigates rank collapse. revision: yes
Circularity Check
No circularity; empirical results rest on external baselines and new architectural components
full rationale
The paper introduces CeRA by adding SiLU gating and dropout to a parallel adapter and reports direct empirical comparisons on GSM8K and MATH against standard LoRA and DoRA. No equations, fitted parameters, or self-citations are shown to reduce the headline performance claims (CeRA r=64 at 16.36% vs. LoRA r=512 at 15.72% and DoRA r=64 at 14.44%) to quantities defined by the paper's own inputs. Spectral analysis is presented as post-hoc observation rather than a load-bearing derivation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Increasing the rank in LoRA yields diminishing returns due to intrinsic linear constraints
Reference graph
Works this paper leans on
-
[1]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
work page 2022
-
[2]
Dora: Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[3]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget allocation for parameter-efficient fine-tuning.arXiv preprint arXiv:2303.10512, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
S-lora: Serving thousands of concurrent lora adapters.arXiv preprint arXiv:2311.03285, 2023
Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, et al. S-lora: Serving thousands of concurrent lora adapters.arXiv preprint arXiv:2311.03285, 2023
-
[5]
Slimorca: An open dataset of gpt-4 augmented flan reasoning traces, with verification, 2023
Wing Lian, Guan Wang, Bleys Goodson, Eugene Pentland, Austin Cook, Chanvichet V ong, and "Teknium". Slimorca: An open dataset of gpt-4 augmented flan reasoning traces, with verification, 2023
work page 2023
-
[6]
Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mammoth: Building math generalist models through hybrid instruction tuning.arXiv preprint arXiv:2309.05653, 2023
-
[7]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Measuring mathematical problem solving with the math dataset.NeurIPS, 2021
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.NeurIPS, 2021
work page 2021
-
[9]
Yu-Ang Lee, Ching-Yun Ko, Pin-Yu Chen, and Mi-Yen Yeh. Learning rate matters: Vanilla lora may suffice for llm fine-tuning.arXiv preprint arXiv:2602.04998, 2026
-
[10]
The effective rank: A measure of effective dimensionality
Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. In2007 15th European signal processing conference, pages 606–610. IEEE, 2007
work page 2007
-
[11]
Punica: Multi-tenant lora serving.Proceedings of Machine Learning and Systems, 6:1–13, 2024
Lequn Chen, Zihao Ye, Yongji Wu, Danyang Zhuo, Luis Ceze, and Arvind Krishnamurthy. Punica: Multi-tenant lora serving.Proceedings of Machine Learning and Systems, 6:1–13, 2024
work page 2024
-
[12]
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms, 2023.URL https://arxiv. org/abs/2305.14314, 2, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
work page 2019
-
[14]
Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. Towards a unified view of parameter-efficient transfer learning.arXiv preprint arXiv:2110.04366, 2021
-
[15]
Yaoming Zhu, Jiangtao Feng, Chengqi Zhao, Mingxuan Wang, and Lei Li. Counter-interference adapter for multilingual machine translation.arXiv preprint arXiv:2104.08154, 2021. A Hyperparameter Tuning and Baseline Reproducibility To ensure a fair comparison, we conducted an extensive hyperparameter search for all evaluated methods (LoRA, DoRA, and CeRA). Thi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.