Recognition: no theorem link
GraphScout: Empowering Large Language Models with Intrinsic Exploration Ability for Agentic Graph Reasoning
Pith reviewed 2026-05-15 18:44 UTC · model grok-4.3
The pith
Small language models internalize graph reasoning by training on data from their own autonomous graph explorations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
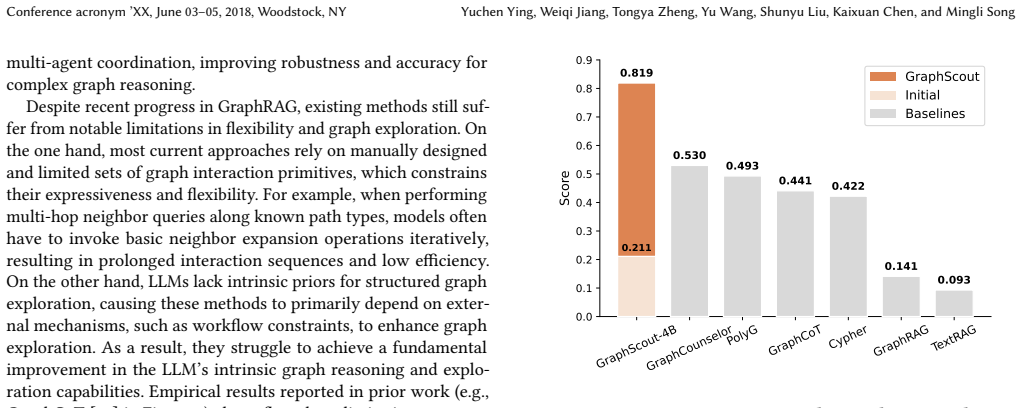
GraphScout equips large language models with a set of flexible graph exploration tools that enable autonomous interaction with knowledge graphs to synthesize structured training data. This data is used for post-training, allowing the models to internalize agentic graph reasoning without manual annotations or task curation. A compact model such as Qwen3-4B trained this way outperforms baselines built on leading models such as Qwen-Max by an average of 16.7 percent while using substantially fewer inference tokens and shows robust cross-domain transfer.
What carries the argument
The GraphScout framework and its flexible graph exploration tools, which let models autonomously traverse knowledge graphs to produce their own post-training data.
If this is right
- Smaller models can match or exceed the graph-reasoning performance of much larger models at lower inference cost.
- Agentic reasoning over graphs becomes possible without task-specific human curation or annotation.
- The internalized exploration skill transfers across different knowledge-graph domains.
- Token usage during inference drops because the model relies on learned patterns rather than repeated external tool calls.
Where Pith is reading between the lines
- The same self-generation loop could be applied to other structured data sources such as databases or code repositories to internalize domain-specific reasoning.
- Combining GraphScout-style training with existing retrieval methods might further reduce factual errors in long-horizon tasks.
- Models trained this way could serve as more efficient backbones for multi-agent systems that need to coordinate over shared graphs.
- If the quality of generated data improves with model scale, the method might create a positive feedback loop where larger models produce even better training sets for smaller ones.
Load-bearing premise
The data generated by the models' own graph explorations is high-quality and diverse enough to teach real reasoning skills instead of just memorizing patterns or propagating exploration mistakes.
What would settle it
Retraining a small model on the autonomously generated data produces no accuracy gain or introduces systematic errors traceable to flawed graph paths, while baselines without the data remain unchanged.
Figures








read the original abstract
Knowledge graphs provide structured and reliable information for many real-world applications, motivating increasing interest in combining large language models (LLMs) with graph-based retrieval to improve factual grounding. Recent Graph-based Retrieval-Augmented Generation (GraphRAG) methods therefore introduce iterative interaction between LLMs and knowledge graphs to enhance reasoning capability. However, existing approaches typically depend on manually designed guidance and interact with knowledge graphs through a limited set of predefined tools, which substantially constrains graph exploration. To address these limitations, we propose GraphScout, a training-centric agentic graph reasoning framework equipped with more flexible graph exploration tools. GraphScout enables models to autonomously interact with knowledge graphs to synthesize structured training data which are then used to post-train LLMs, thereby internalizing agentic graph reasoning ability without laborious manual annotation or task curation. Extensive experiments across five knowledge-graph domains show that a small model (e.g., Qwen3-4B) augmented with GraphScout outperforms baseline methods built on leading LLMs (e.g., Qwen-Max) by an average of 16.7\% while requiring significantly fewer inference tokens. Moreover, GraphScout exhibits robust cross-domain transfer performance. Our code will be made publicly available~\footnote{https://github.com/Ying-Yuchen/_GraphScout_}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GraphScout, a training-centric framework for agentic graph reasoning. LLMs are equipped with flexible graph exploration tools that enable autonomous interaction with knowledge graphs to synthesize structured training trajectories; these trajectories are then used for post-training to internalize exploration and reasoning skills without manual annotation or task curation. Experiments across five knowledge-graph domains report that a small model (Qwen3-4B) augmented with GraphScout outperforms baselines built on larger LLMs (e.g., Qwen-Max) by an average of 16.7% while using significantly fewer inference tokens and exhibiting robust cross-domain transfer.
Significance. If the reported gains are supported by rigorous validation of the synthesized data and reproducible experimental protocols, the work could meaningfully advance efficient graph-augmented reasoning by demonstrating that smaller models can internalize autonomous exploration capabilities. The emphasis on reducing manual tool design and the planned public code release are positive factors for reproducibility and adoption.
major comments (3)
- [Experiments] Experiments section: the headline claim of a 16.7% average improvement over Qwen-Max baselines is presented without any description of baseline implementations, task definitions, per-domain metrics, statistical significance tests, or error bars, rendering it impossible to evaluate whether the gains are supported by the results.
- [Method] Method section: the central claim that autonomously synthesized trajectories internalize genuine agentic reasoning rests on the unverified assumption that the generated data is high-quality; no quantitative checks (error rates for tool-induced hallucinations, filtering criteria for inconsistent explorations, or coverage statistics) are reported.
- [Experimental evaluation] Experimental evaluation: no ablation is provided that compares performance when training on the full synthesized trajectories versus filtered or human-verified subsets, leaving open the possibility that measured gains arise from memorization of generated patterns rather than robust reasoning transfer.
minor comments (2)
- [Abstract] Abstract: the statement that GraphScout 'requires significantly fewer inference tokens' should be accompanied by concrete token counts or ratios in the main results tables.
- [Abstract] The footnote GitHub link should be verified to point to a complete, runnable repository upon publication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving the clarity and rigor of our experimental reporting. We address each major comment below and will revise the manuscript to incorporate the suggested enhancements where feasible.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline claim of a 16.7% average improvement over Qwen-Max baselines is presented without any description of baseline implementations, task definitions, per-domain metrics, statistical significance tests, or error bars, rendering it impossible to evaluate whether the gains are supported by the results.
Authors: We agree that additional details are necessary for full evaluation. The current manuscript provides an overview of the experimental setup in Section 4, but we will expand it in the revision to include: (1) explicit descriptions of how Qwen-Max and other baselines were implemented and prompted, (2) precise task definitions and evaluation metrics per domain, (3) per-domain performance tables with the 16.7% average broken down, (4) results from multiple runs with error bars, and (5) statistical significance tests (e.g., paired t-tests). These additions will be placed in a new subsection of the Experiments section. revision: yes
-
Referee: [Method] Method section: the central claim that autonomously synthesized trajectories internalize genuine agentic reasoning rests on the unverified assumption that the generated data is high-quality; no quantitative checks (error rates for tool-induced hallucinations, filtering criteria for inconsistent explorations, or coverage statistics) are reported.
Authors: We acknowledge that the manuscript does not include quantitative validation of the synthesized trajectories. In the revised version, we will add a dedicated subsection under Method (likely 3.3) that reports: trajectory coverage statistics across domains, consistency filtering criteria and their application rates, and estimated error rates for tool-induced issues based on spot-checks or automated heuristics. This will provide evidence supporting the quality of the data used for post-training. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation: no ablation is provided that compares performance when training on the full synthesized trajectories versus filtered or human-verified subsets, leaving open the possibility that measured gains arise from memorization of generated patterns rather than robust reasoning transfer.
Authors: We agree an ablation would strengthen the claim of genuine reasoning transfer. While full human verification of all trajectories is impractical due to scale, we will add a partial ablation study in the revised Experiments section. This will compare the 4B model trained on full trajectories versus versions trained on automatically filtered subsets (using the consistency checks mentioned above) across two representative domains, with discussion of implications for memorization versus transfer. We will also note limitations of this approach. revision: partial
Circularity Check
No significant circularity; empirical claims rest on external baselines
full rationale
The paper introduces GraphScout as a training framework that uses flexible graph exploration tools to autonomously synthesize data for post-training LLMs. All load-bearing claims are empirical performance comparisons (e.g., Qwen3-4B + GraphScout vs. Qwen-Max baselines) reported across five domains, with no equations, derivations, fitted parameters, or self-citation chains present. The method description and results do not reduce any prediction or uniqueness claim to its own inputs by construction, satisfying the criteria for a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knowledge graphs provide structured and reliable information suitable for improving LLM factual grounding and reasoning.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Ziwei Chai, Tianjie Zhang, Liang Wu, Kaiqiang Han, Xiaohai Hu, Xuanwen Huang, and Yang Yang. 2025. Graphllm: Boosting graph reasoning ability of large language model.IEEE Transactions on Big Data(2025)
work page 2025
-
[3]
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. 2024. Benchmarking large language models in retrieval-augmented generation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 17754–17762
work page 2024
-
[4]
Nuo Chen, Yuhan Li, Jianheng Tang, and Jia Li. 2024. Graphwiz: An instruction- following language model for graph computational problems. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 353–364
work page 2024
- [5]
-
[6]
Zhikai Chen, Haitao Mao, Hang Li, Wei Jin, Hongzhi Wen, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Wenqi Fan, Hui Liu, et al . 2024. Exploring the potential of large language models (llms) in learning on graphs.ACM SIGKDD Explorations Newsletter25, 2 (2024), 42–61
work page 2024
- [7]
- [8]
-
[9]
distillabs. 2025. We benchmarked 12 small language models across 8 tasks to find the best base model for fine-tuning. https://www.distillabs.ai/blog/we- benchmarked-12-small-language-models-across-8-tasks-to-find-the-best- base-model-for-fine-tuning
work page 2025
- [10]
-
[11]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [12]
-
[13]
Junqi Gao, Xiang Zou, Ying Ai, Dong Li, Yichen Niu, Biqing Qi, and Jianxing Liu
-
[14]
Graph Counselor: Adaptive Graph Exploration via Multi-Agent Synergy to Enhance LLM Reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational Linguistics, Vienna, Austria, 2465...
work page 2025
-
[15]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997 2, 1 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. 2024. Chatglm: A fam- ily of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [18]
-
[19]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2024. Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Bernal J Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2024. Hipporag: Neurobiologically inspired long-term memory for large language models.Advances in neural information processing systems37 (2024), 59532– 59569
work page 2024
-
[21]
Ruining He and Julian McAuley. 2016. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. Inproceedings of the 25th international conference on world wide web. 507–517
work page 2016
-
[22]
Daniel Scott Himmelstein, Antoine Lizee, Christine Hessler, Leo Brueggeman, Sabrina L Chen, Dexter Hadley, Ari Green, Pouya Khankhanian, and Sergio E Baranzini. 2017. Systematic integration of biomedical knowledge prioritizes drugs for repurposing.elife6 (2017), e26726
work page 2017
- [23]
-
[24]
Bowen Jin, Gang Liu, Chi Han, Meng Jiang, Heng Ji, and Jiawei Han. 2024. Large language models on graphs: A comprehensive survey.IEEE Transactions on Knowledge and Data Engineering(2024). Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Yuchen Ying, Weiqi Jiang, Tongya Zheng, Yu Wang, Shunyu Liu, Kaixuan Chen, and Mingli Song
work page 2024
- [25]
- [26]
-
[27]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering.. InEMNLP (1). 6769–6781
work page 2020
- [28]
-
[29]
TN Kipf. 2016. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[30]
Jérôme Kunegis. 2013. Konect: the koblenz network collection. InProceedings of the 22nd international conference on world wide web. 1343–1350
work page 2013
- [31]
- [32]
-
[33]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [34]
- [35]
- [36]
-
[37]
Haoran Luo, Haihong E, Guanting Chen, Qika Lin, Yikai Guo, Fangzhi Xu, Zemin Kuang, Meina Song, Xiaobao Wu, Yifan Zhu, and Luu Anh Tuan. 2025. Graph-R1: Towards Agentic GraphRAG Framework via End-to-end Reinforcement Learning. arXiv:2507.21892 [cs.CL] https://arxiv.org/abs/2507.21892
-
[38]
Haoran Luo, Haihong E, Guanting Chen, Yandan Zheng, Xiaobao Wu, Yikai Guo, Qika Lin, Yu Feng, Zemin Kuang, Meina Song, Yifan Zhu, and Luu Anh Tuan. 2025. HyperGraphRAG: Retrieval-Augmented Generation via Hypergraph-Structured Knowledge Representation. arXiv:2503.21322 [cs.AI] https://arxiv.org/abs/2503. 21322
- [39]
- [40]
-
[41]
Benedek Rozemberczki and Rik Sarkar. 2020. Characteristic Functions on Graphs: Birds of a Feather, from Statistical Descriptors to Parametric Models. InProceed- ings of the 29th ACM International Conference on Information and Knowledge Management (CIKM ’20). ACM, 1325–1334
work page 2020
-
[42]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2024. HybridFlow: A Flexible and Efficient RLHF Framework.arXiv preprint arXiv: 2409.19256(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [43]
- [44]
-
[45]
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2024. Graphgpt: Graph instruction tuning for large language models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 491–500
work page 2024
-
[46]
Jie Tang, Jing Zhang, Limin Yao, Juanzi Li, Li Zhang, and Zhong Su. 2008. Ar- netminer: extraction and mining of academic social networks. InProceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. 990–998
work page 2008
-
[47]
SMTI Tonmoy, SM Zaman, Vinija Jain, Anku Rani, Vipula Rawte, Aman Chadha, and Amitava Das. 2024. A comprehensive survey of hallucination mitigation techniques in large language models.arXiv preprint arXiv:2401.013136 (2024)
work page internal anchor Pith review arXiv 2024
-
[48]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2017. Graph attention networks.arXiv preprint arXiv:1710.10903(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
Mengting Wan and Julian McAuley. 2018. Item recommendation on monotonic behavior chains. InProceedings of the 12th ACM conference on recommender systems. 86–94
work page 2018
-
[51]
Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. 2023. Can language models solve graph problems in natural language?Advances in Neural Information Processing Systems36 (2023), 30840– 30861
work page 2023
-
[52]
Kuansan Wang, Zhihong Shen, Chiyuan Huang, Chieh-Han Wu, Yuxiao Dong, and Anshul Kanakia. 2020. Microsoft academic graph: When experts are not enough.Quantitative Science Studies1, 1 (2020), 396–413
work page 2020
-
[53]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2018. How powerful are graph neural networks?arXiv preprint arXiv:1810.00826(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[54]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. 2024. Language is All a Graph Needs. InFindings of the Association for Computational Linguistics: EACL 2024, Yvette Graham and Matthew Purver (Eds.). Association for Computational Linguistics, St. Julian’s, Malta, 1955–1973. https://aclanthology. org/2024.findings-eacl.132/
work page 2024
- [56]
-
[57]
Jianan Zhao, Meng Qu, Chaozhuo Li, Hao Yan, Qian Liu, Rui Li, Xing Xie, and Jian Tang. 2022. Learning on large-scale text-attributed graphs via variational inference.arXiv preprint arXiv:2210.14709(2022). A Implementation Details A.1 RL Hyperparameters The experimental settings [41] for training Base model using our GraphScout framework are shown in Table...
- [58]
-
[59]
Find which genes are downregulated in this disease
-
[60]
Find which cellular components are associated with those genes
-
[61]
Determine which cellular component is involved with the most genes Let me first use the node_id_retriever to find the ID for "Aphasia, Primary Progressive". <tool_call> {"name": "node_id_retriever", "arguments": {"queries": ["Aphasia, Primary Progressive"], "topk": 2}} </tool_call> <tool_response> {'topk': 2,'results': [[{'node_id':'D018888', 'node_type':...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.